并行
一个简单高效的工具,用于在所有可用CPU上并行化Pandas操作。

pandarallel 是一个简单而高效的工具,用于在所有可用的CPU上并行化Pandas操作。
只需一行代码更改,这使得任何Pandas用户都可以利用他的多核计算机,而pandas只使用一个核心。
pandarallel 还提供了不错的进度条(可在Notebook和终端上使用),以便大致了解剩余的计算量。
| 没有并行化 |  |
|---|---|
| 通过并行化 |  |
特点
pandarallel 当前实现以下 pandas API:
| 没有并行化 | 有并行化 |
|---|---|
df.apply(func) |
df.parallel_apply(func) |
df.applymap(func) |
df.parallel_applymap(func) |
df.groupby(args).apply(func) |
df.groupby(args).parallel_apply(func) |
df.groupby(args1).col_name.rolling(args2).apply(func) |
df.groupby(args1).col_name.rolling(args2).parallel_apply(func) |
df.groupby(args1).col_name.expanding(args2).apply(func) |
df.groupby(args1).col_name.expanding(args2).parallel_apply(func) |
series.map(func) |
series.parallel_map(func) |
series.apply(func) |
series.parallel_apply(func) |
series.rolling(args).apply(func) |
series.rolling(args).parallel_apply(func) |
要求
在 Linux 和 macOS 上,没有特殊要求。
在 Windows 上,由于多进程系统(spawn),您发送给 pandarallel 的函数必须是 自包含 的,并且不应依赖于外部资源。
示例:
✅ 在Mac和Linux上有效 - ❌ 在Windows上禁止
import math
def func(x):
# Here, `math` is defined outside `func`. `func` is not self contained.
return math.sin(x.a**2) + math.sin(x.b**2)
✅ 在任何地方有效
def func(x):
# Here, `math` is defined inside `func`. `func` is self contained.
import math
return math.sin(x.a**2) + math.sin(x.b**2)
警告
并行化是有成本的(实例化新进程,通过共享内存发送数据,...),因此只有当需要并行化的计算量足够大时,并行化才是高效的。对于非常少量的数据,使用并行化并不总是值得的。
警告
显示进度条是有成本的,可能会稍微增加计算时间。
示例
每个可用的 pandas API 的示例可用:
- 对于 Mac & Linux
- 对于 Windows
基准测试
以下是一些示例,包括使用和不使用Pandaral·lel的比较基准。
用于此基准测试的计算机:
- 操作系统: Linux Ubuntu 16.04
- 硬件: Intel Core i7 @ 3.40 GHz - 4 核心
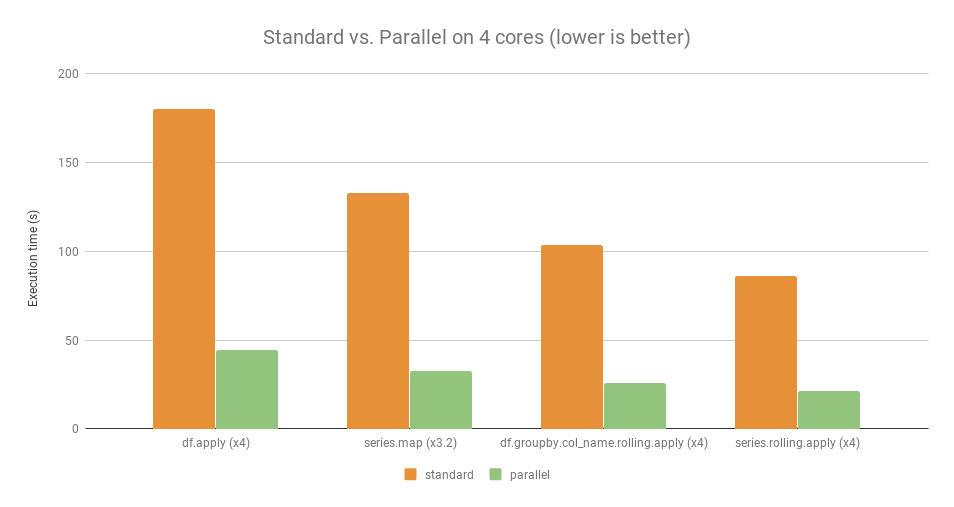
对于那些给定的示例,并行操作的运行速度大约是标准操作的4倍(除了series.map,它的运行速度仅快3.2倍)。
我何时应该使用 pandas、pandarallel 或 pyspark?
根据 pandas 文档:
pandas是一个快速、强大、灵活且易于使用的开源数据分析和操作工具,建立在 Python 编程语言之上。
主要的 pandas 缺点是它只使用你电脑的一个核心,即使有多个核心可用。
pandarallel 通过使用计算机的所有核心来绕过这个限制。
但是,作为回报,pandarallel 需要标准 pandas 操作通常使用的两倍内存。
==> pandarallel 如果您的数据无法放入内存中,则不应使用
pandas。在这种情况下,spark(及其python层pyspark)将是合适的。
spark 的主要缺点是 spark API 对用户来说不如 pandas API 方便(尽管这在改善),而且你还需要在你的计算机上安装一个 JVM(Java 虚拟机)。
然而,使用 spark 你可以:
- 处理比您内存大得多的数据
- 使用
spark集群,将计算分布到多个节点上。