配置
YAML 配置格式通过一系列示例输入(即“测试用例”)运行每个提示,并检查它们是否满足要求(即“断言”)。
断言是_可选的_。许多人通过手动审查输出获得价值,而 Web UI 有助于促进这一点。
示例
假设我们正在构建一个进行语言翻译的应用。此配置通过 GPT-3.5 和 Gemini 运行每个提示,替换 language 和 input 变量:
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- vertex:gemini-pro
tests:
- vars:
language: French
input: Hello world
- vars:
language: German
input: How's it going?
有关设置提示文件的更多信息,请参阅 输入和输出文件。
运行 promptfoo eval 通过此配置将生成一个_矩阵视图_,您可以使用它来评估 GPT 与 Gemini。
使用断言验证输出
接下来,让我们添加一个断言。这将自动拒绝任何不包含 JSON 的输出:
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- vertex:gemini-pro
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-json
- vars:
language: German
input: How's it going?
我们可以创建额外的测试。让我们添加一些其他 类型的断言。对于单个测试用例,使用断言数组以确保满足所有条件。
在此示例中,javascript 断言针对 LLM 输出运行 Javascript。similar 断言使用嵌入检查语义相似性:
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- vertex:gemini-pro
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-json
- type: javascript
value: output.toLowerCase().includes('bonjour')
- vars:
language: German
input: How's it going?
assert:
- type: similar
value: was geht
threshold: 0.6 # 余弦相似度
要了解更多关于断言的信息,请参阅配置 预期输出 的文档。
从单独的文件导入提供者
providers 配置属性可以指向文件列表。例如:
providers:
- file://path/to/provider1.yaml
- file://path/to/provider2.json
提供者文件如下所示:
id: openai:gpt-4o-mini
label: Foo bar
config:
temperature: 0.9
从单独的文件导入测试
tests 配置属性接受文件或目录路径列表。例如:
prompts: file://prompts.txt
providers: openai:gpt-4o-mini
# 加载并运行匹配这些文件路径的所有测试用例
tests:
# 您可以提供一个确切的文件路径
- file://tests/tests2.yaml
# 或通配符(通配符)
- file://tests/*
# 混合匹配实际测试用例
- vars:
var1: foo
var2: bar
单个字符串也是有效的:
tests: tests/*
或路径列表:
tests:
- 'tests/accuracy'
- 'tests/creativity'
- 'tests/hallucination'
我们还支持从 本地文件 和 Google Sheets 导入 CSV 数据集。
从单独的文件导入变量
vars 属性可以指向文件或目录。例如:
tests:
- vars: file://path/to/vars*.yaml
您还可以通过使用 file:// 前缀从文件加载单个变量。例如:
tests:
- vars:
var1: some value...
var2: another value...
var3: file://path/to/var3.txt
支持 Javascript 和 Python 变量文件。例如:
tests:
- vars:
context: file://fetch_from_vector_database.py
这在测试 Pinecone、Chroma、Milvus 等向量数据库时很有用。
Javascript ��变量
要动态加载来自 JavaScript 文件的变量,请在 YAML 配置中使用 file:// 前缀,指向导出函数的 JavaScript 文件。
tests:
- vars:
context: file://path/to/dynamicVarGenerator.js
dynamicVarGenerator.js 接收 varName、prompt 和 otherVars 作为参数,您可以使用这些参数根据测试上下文查询数据库或任何其他内容:
module.exports = function (varName, prompt, otherVars) {
// 根据 varName 返回值的示例逻辑
if (varName === 'context') {
return {
output: `已处理 ${otherVars.input} 用于提示: ${prompt}`,
};
}
return {
output: '默认值',
};
// 处理潜在错误
// return { error: '错误信息' }
};
这个 JavaScript 文件根据提供的上下文处理输入变量并返回一个动态值。
Python 变量
对于 Python,方法类似。定义一个包含 get_var 函数的 Python 脚本来生成变量的值。该函数应接受 var_name、prompt 和 other_vars。
tests:
- vars:
context: file://fetch_dynamic_context.py
fetch_dynamic_context.py:
def get_var(var_name: str, prompt: str, other_vars: Dict[str, str]) -> Dict[str, str]:
# 注意:必须返回一个包含 'output' 键或 'error' 键的字典。
# 示例逻辑以动态生��成变量内容
if var_name == 'context':
return {
'output': f"Context for {other_vars['input']} in prompt: {prompt}"
}
return {'output': 'default context'}
# 处理潜在错误
# return { 'error': '错误信息' }
避免重复
默认测试用例
使用 defaultTest 为所有测试设置属性。
在此示例中,我们使用 llm-rubric 断言来确保 LLM 不将自己描述为 AI。此检查适用于所有测试用例:
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- vertex:gemini-pro
defaultTest:
assert:
- type: llm-rubric
value: does not describe self as an AI, model, or chatbot
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-json
- type: javascript
value: output.toLowerCase().includes('bonjour')
- vars:
language: German
input: How's it going?
assert:
- type: similar
value: was geht
threshold: 0.6
你也可以使用 defaultTest 来覆盖每个测试使用的模型。这对于 模型评级的评估 非常有用:
defaultTest:
options:
provider: openai:gpt-4o-mini-0613
YAML 引用
promptfoo 配置支持 JSON 模式 引用,这些引用定义了可重用的块。
使用 $ref 键来重用断言,而不必多次完全定义它们。以下是一个示例:
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- vertex:gemini-pro
tests:
- vars:
language: French
input: Hello world
assert:
- $ref: '#/assertionTemplates/startsUpperCase'
- vars:
language: German
input: How's it going?
assert:
- $ref: '#/assertionTemplates/noAIreference'
- $ref: '#/assertionTemplates/startsUpperCase'
assertionTemplates:
noAIreference:
type: llm-rubric
value: does not describe self as an AI, model, or chatbot
startsUpperCase:
type: javascript
value: output[0] === output[0].toUpperCase()
提供者配置中的 tools 和 functions 值不会被解引用。这是因为它们是独立的 JSON 模式,可能包含自己的内部引用。
单个测试用例中的多个变量
测试中的 vars 映射也支持数组值。如果值是数组,测试用例将运行每个值的组合。
例如:
prompts: file://prompts.txt
providers:
- openai:gpt-4o-mini
- openai:gpt-4
tests:
- vars:
language:
- French
- German
- Spanish
input:
- 'Hello world'
- 'Good morning'
- 'How are you?'
assert:
- type: similar
value: 'Hello world'
threshold: 0.8
评估每个 language x input 组合:
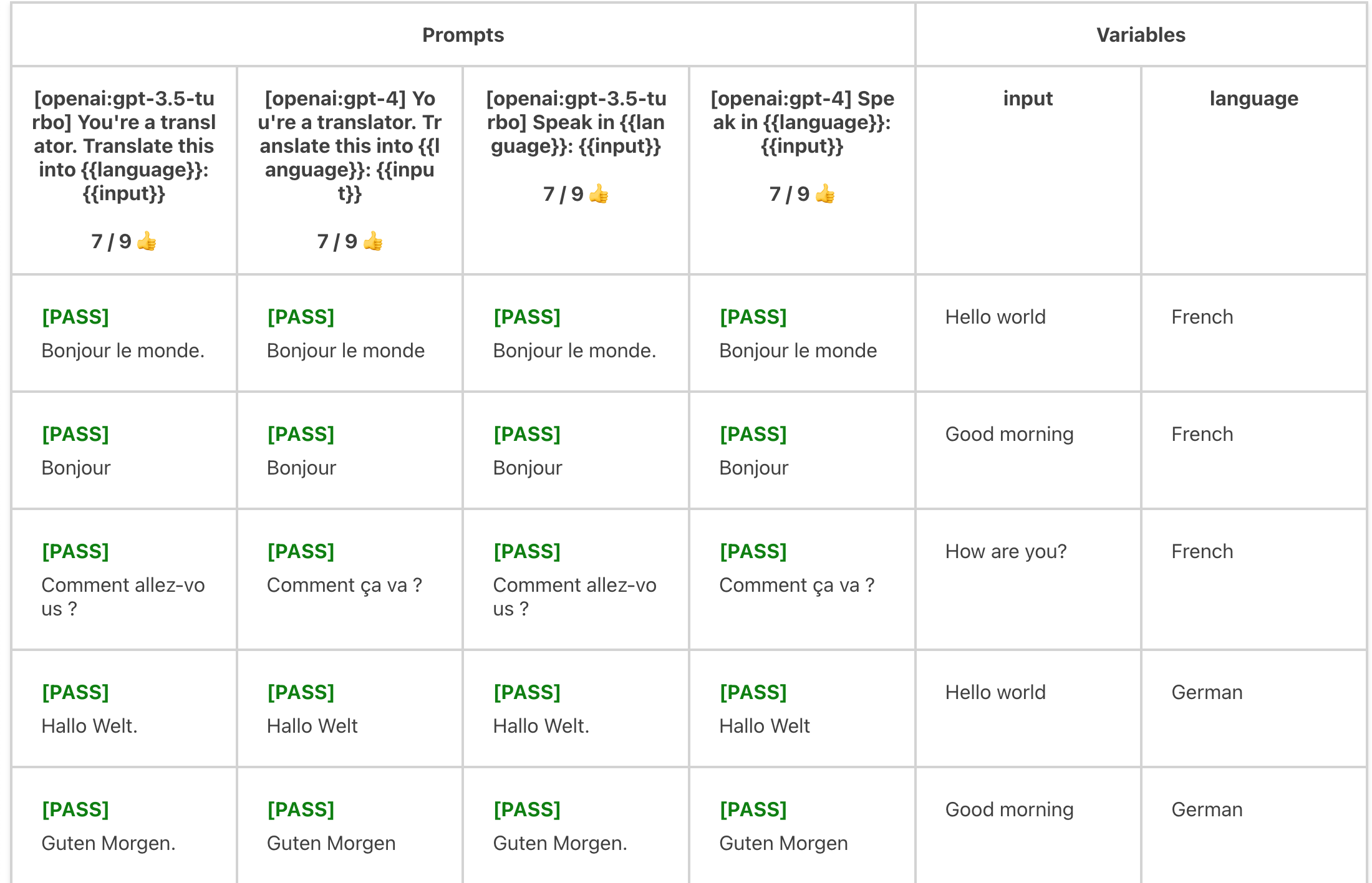
变量也可以从通配符文件路径导入。它们会自动扩展为数组。例如:
- vars:
language:
- French
- German
- Spanish
input: file://path/to/inputs/*.txt
使用 Nunjucks 模板
使用 Nunjucks 模板来对提示模板进行额外控制,包括循环、条件等。
操作对象
在上面的示例中,vars 值是字符串。但 vars 可以是任何 JSON 或 YAML 实体,包括嵌套对象。你可以在提示中操作这些对象,这些对象是 nunjucks 模板:
promptfooconfig.yaml:
tests:
- vars:
user_profile:
name: John Doe
interests:
- reading
- gaming
- hiking
recent_activity:
type: reading
details:
title: 'The Great Gatsby'
author: 'F. Scott Fitzgerald'
prompt.txt:
用户资料:
- 姓名: {{ user_profile.name }}
- 兴趣: {{ user_profile.interests | join(', ') }}
- 最近活动: {{ recent_activity.type }} 关于 "{{ recent_activity.details.title }}" 作者 {{ recent_activity.details.author }}
基于以上用户资料,生成一个个性化的阅读推荐列表,包括与 "{{ recent_activity.details.title }}" 相似的书籍,并符合用户的兴趣。
这里还有一个例子。考虑这个测试用例,它列出了一些用户和助手消息,采用与OpenAI兼容的格式:
tests:
- vars:
previous_messages:
- role: user
content: hello world
- role: assistant
content: how are you?
- role: user
content: great, thanks
相应的 prompt.txt 文件简单地通过使用 dump 过滤器将 previous_messages 对象转换为JSON字符串:
{{ previous_messages | dump }}
运行 promptfoo eval -p prompt.txt -c path_to.yaml 将使用以下提示调用Chat Completion API:
[
{
"role": "user",
"content": "hello world"
},
{
"role": "assistant",
"content": "how are you?"
},
{
"role": "user",
"content": "great, thanks"
}
]
转义JSON字符串
如果提示是有效的JSON,当它们包含在字符串中时,nunjucks变量会自动转义:
tests:
- vars:
system_message: >
This multiline "system message" with quotes...
Is automatically escaped in JSON prompts!
{
"role": "system",
"content": "{{ system_message }}"
}
你也可以使用nunjucks的 dump 过滤器手动转义字符串。如果你的提示不是有效的JSON,例如如果你使用nunjucks语法,这是必要的:
{
"role": {% if 'admin' in message %} "system" {% else %} "user" {% endif %},
"content": {{ message | dump }}
}
变量组合
变量可以引用其他变量:
prompts:
- 'Write a {{item}}'
tests:
- vars:
item: 'tweet about {{topic}}'
topic: 'bananas'
- vars:
item: 'instagram about {{topic}}'
topic: 'theoretical quantum physics in alternate dimensions'
访问环境变量
你可以在模板中使用 env 全局访问环境变量:
tests:
- vars:
headline: 'Articles about {{ env.TOPIC }}'
工具和函数
promptfoo支持OpenAI和Anthropic模型的工具使用和函数调用,以及其他提供商特定的配置,如温度和令牌数量。有关定义函数和工具的更多信息,请参阅 OpenAI提供商文档 和 Anthropic提供商文档。
转换输出
转换可以在提供商级别和测试用例中应用。应用顺序为:
- 提供商转换(总是首先应用)
- 默认测试转换(如果在
defaultTest中指定) - 单个测试用例转换(如果存在,则覆盖
defaultTest转换)
请注意,在测试用例级别只应用一个转换——要么来自 defaultTest,要么来自单个测试用例,而不是两者都应用。
TestCase.options.transform 字段是一个JavaScript代码片段,它在通过测试断言运行之前修改LLM输出。
它是一个接受字符串输出和上下文对象的函数:
transformFn: (output: string, context: {
prompt: {
// 如果分配了提示的ID
id?: string;
// 测试用例中提供的原始提示,没有{{variable}}替换。
raw?: string;
// 发送到LLM API和断言的提示。
display?: string;
};
vars?: Record<string, any>;
}) => void;
如果你需要在运行评估之前以某种方式转换或清理LLM输出,这很有用。
例如:
# ...
tests:
- vars:
language: French
body: Hello world
options:
transform: output.toUpperCase()
# ...
或多行:
# ...
tests:
- vars:
language: French
body: Hello world
options:
transform: |
output = output.replace(context.vars.language, 'foo');
const words = output.split(' ').filter(x => !!x);
return JSON.stringify(words);
# ...
它也可以在断言中工作,这对于从JSON中提取值很有用:
tests:
- vars:
# ...
assert:
- type: equals
value: 'foo'
transform: output.category # 从输出json中选择'category'键
使用 defaultTest 将转换选项应用于测试套件中的每个测试用例。
从单独的文件中转换
转换函数可以从外部JavaScript或Python文件执行。你可以选择指定要使用的函数名称。
对于JavaScript:
defaultTest:
options:
transform: file://transform.js:customTransform
module.exports = {
customTransform: (output, context) => {
// context.vars, context.prompt
return output.toUpperCase();
},
};
对于Python:
defaultTest:
options:
transform: file://transform.py
def get_transform(output, context):
# context['vars'], context['prompt']
return output.upper()
如果没有为Python文件指定函数名称,它默认使用get_transform。要使用自定义的Python函数,请在文件路径中指定它:
transform: file://transform.py:custom_python_transform
转换输入变量
您还可以使用transformVars选项在变量用于提示之前对其进�行转换。当您需要预处理数据或从外部源加载内容时,此功能非常有用。
transformVars函数应返回一个包含转换后的变量名称和值的对象。这些转换后的变量会添加到vars对象中,并可以覆盖现有键。例如:
prompts:
- '用{{topic_length}}个词总结以下文本:{{file_content}}'
defaultTest:
options:
transformVars: |
return {
uppercase_topic: vars.topic.toUpperCase(),
topic_length: vars.topic.length,
file_content: fs.readFileSync(vars.file_path, 'utf-8')
};
tests:
- vars:
topic: '气候变化'
file_path: './data/climate_article.txt'
assert:
- type: contains
value: '{{uppercase_topic}}'
转换函数也可以在单个��测试用例中指定。
tests:
- vars:
url: 'https://example.com/image.png'
options:
transformVars: |
return { ...vars, image_markdown: `` }
从单独的文件中输入转换
对于更复杂的转换,您可以使用外部文件进行transformVars:
defaultTest:
options:
transformVars: file://transformVars.js:customTransformVars
const fs = require('fs');
module.exports = {
customTransformVars: (vars, context) => {
try {
return {
uppercase_topic: vars.topic.toUpperCase(),
topic_length: vars.topic.length,
file_content: fs.readFileSync(vars.file_path, 'utf-8'),
};
} catch (error) {
console.error('Error in transformVars:', error);
return {
error: 'Failed to transform variables',
};
}
},
};
您也可以在Python中定义转换。
defaultTest:
options:
transformVars: file://transform_vars.py
import os
def get_transform(vars, context):
with open(vars['file_path'], 'r') as file:
file_content = file.read()
return {
'uppercase_topic': vars['topic'].upper(),
'topic_length': len(vars['topic']),
'file_content': file_content,
'word_count': len(file_content.split())
}
配置结构和组织
有关配置结构的详细信息,请参阅配置参考。
如果您有多组测试,将它们拆分为多个配置文件会有所帮助。使用--config或-c参数来运行每个单独的配置:
promptfoo eval -c usecase1.yaml
和
promptfoo eval -c usecase2.yaml
您可以同时运行多个配置,这将把它们合并为一个单独的评估。例如:
promptfoo eval -c my_configs/*
或
promptfoo eval -c config1.yaml -c config2.yaml -c config3.yaml
从CSV加载测试
YAML很好,但有些组织为了便于协作,将他们的LLM测试保存在电子表格中。promptfoo支持一种特殊的CSV文件格式。
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- vertex:gemini-pro
tests: file://tests.csv
promptfoo还内置了从Google Sheet拉取测试用例的能力。最简单的入门方法是设置表格对“任何有链接的人”可见。例如:
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- vertex:gemini-pro
tests: https://docs.google.com/spreadsheets/d/1eqFnv1vzkPvS7zG-mYsqNDwOzvSaiIAsKB3zKg9H18c/edit?usp=sharing
这里有一个完整示例。
有关如何设置promptfoo以访问私有电子表格的详细信息,请参阅Google Sheets集成。