归纳链接预测
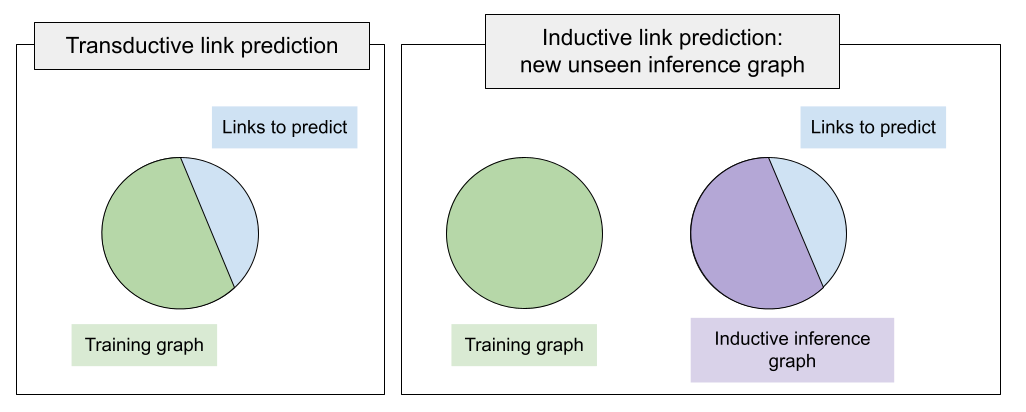
多年来,PyKEEN和其他KGE库中的标准训练设置意味着训练图包括我们将进行推理(验证、测试或自定义预测)的所有实体。也就是说,要预测的缺失链接连接了训练图中已经见过的实体。这种链接预测设置被称为转导设置。
如果在推理时我们有新的、未见过的实体,并且想要预测这些未见实体之间的链接,该怎么办? 这种情况在归纳框架下得到了统一。 在上图中展示的差异,归纳设置的主要区别在于,在推理时我们有一个新的图(称为归纳推理图),并且链接预测是针对这个新的未见实体的推理图执行的。
事实上,根据[ali2021]的分类,存在几种归纳设置的变体:
推理图与训练图完全断开(不相交),也称为完全归纳设置。 因此,实体之间的链接预测模式是未见过的到未见过的。
推理图扩展了训练图,将新节点连接到已见图,即半归纳设置。 当我们预测新添加节点之间的链接时,链接预测模式可以是未见-到-未见, 或者当我们预测已知节点与新到达节点之间的链接时,可以是未见-到-已见 / 已见-到-未见。
PyKEEN 支持归纳链接预测,提供接口来组织数据集,构建未见实体的表示,并在其上应用任何现有的交互函数。最重要的是,关系集必须在训练时被看到。也就是说,推理时看到的关系必须是训练时关系的一个子集,因为我们将学习这些关系的表示以转移到未见图中。
组织数据集
构建归纳数据集的基本类是 pykeen.datasets.inductive.InductiveDataset。
它应该包含超过3个三元组工厂,即在完全归纳设置中,预计至少有4个三元组工厂(transductive_training、inductive_inference、inductive_validation、inductive_test)。
transductive_training 是具有实体索引 (0..N) 的图,我们将在此图上训练模型,
inductive_inference 是在推理时出现的新图,包含新实体(索引 (0..K))。
请注意,transductive_training 和 inductive_inference 中的实体数量不同。
inductive_validation 和 inductive_test 与 inductive_inference 共享实体,
但不与 transductive_training 共享。这样,我们告知模型我们是在针对归纳推理图而不是训练图进行链接预测。
PyKEEN 支持由 [teru2020] 引入的 12 个完全归纳的数据集,其中训练和归纳推理图是分离的。每个知识图谱家族,InductiveFB15k237、InductiveWN18RR 和 InductiveNELL,都有 4 个版本,这些版本根据训练和推理图的大小以及实体和关系的总数而变化。确保所有推理图的关系集是其训练图的子集。
特征化未见实体
在训练图上训练实体嵌入是没有意义的,因为这些嵌入在推理时无法使用。 相反,我们需要一些通用的特征化机制,能够构建已见和未见实体的表示。 在PyKEEN中,根据节点描述的可用性,至少存在两种这样的机制。
NodePiece
在最基本的情况下,未见的实体到达时没有任何特征或描述。
我们使用pykeen.nn.representation.NodePieceRepresentation来应对这种情况 -
由于训练和推理时的关系集是相同的,NodePiece表示将通过一组相关关系类型对每个实体进行标记。
出于计算原因,inductive_inference实体的NodePiece表示(在推理时可见)也可以预先计算。
目前,PyKEEN 提供了两种归纳式 NodePiece 实现:
* pykeen.models.inductive.InductiveNodePiece - 基础版本;
* pykeen.models.inductive.InductiveNodePieceGNN - 除了标记化和可学习的哈希编码器外,此版本还在从词汇表构建节点表示后,在 inductive_inference 图上执行消息传递。默认情况下,消息传递是通过 2 层 CompGCN 执行的。
NodePiece的归纳版本在关系tokens的词汇表上训练一个编码器,这些词汇表在推理时可以轻松重复使用。这样,我们可以获得未见实体的表示。InductiveNodePiece和InductiveNodePieceGNN可以与PyKEEN中的任何交互函数配对,其中关系向量的维度与最终节点向量的维度相同。可以通过自定义关系表示模块的初始化来集成替代的交互。
让我们使用InductiveFB15k237数据集之一创建一个基本的InductiveNodePiece:
from pykeen.datasets.inductive.ilp_teru import InductiveFB15k237
from pykeen.models.inductive import InductiveNodePiece
from pykeen.losses import NSSALoss
dataset = InductiveFB15k237(version="v1", create_inverse_triples=True)
model = InductiveNodePiece(
triples_factory=dataset.transductive_training, # training factory, used to tokenize training nodes
inference_factory=dataset.inductive_inference, # inference factory, used to tokenize inference nodes
num_tokens=12, # length of a node hash - how many unique relations per node will be used
aggregation="mlp", # aggregation function, defaults to an MLP, can be any PyTorch function
loss=NSSALoss(margin=15), # dummy loss
random_seed=42,
)
创建消息传递版本的NodePiece几乎是一样的:
from pykeen.datasets.inductive.ilp_teru import InductiveFB15k237
from pykeen.models.inductive import InductiveNodePieceGNN
from pykeen.losses import NSSALoss
dataset = InductiveFB15k237(version="v1", create_inverse_triples=True)
model = InductiveNodePieceGNN(
triples_factory=dataset.transductive_training, # training factory, will be also used for a GNN
inference_factory=dataset.inductive_inference, # inference factory, will be used for a GNN
num_tokens=12, # length of a node hash - how many unique relations per node will be used
aggregation="mlp", # aggregation function, defaults to an MLP, can be any PyTorch function
loss=NSSALoss(margin=15), # dummy loss
random_seed=42,
gnn_encoder=None, # defaults to a 2-layer CompGCN with DistMult composition function
)
请注意,此版本具有gnn_encoder参数 - 将其保持为None将调用默认的2层CompGCN。
您可以在此处传递任何返回更新后的实体和关系矩阵的关系GNN,因为评分函数将使用它们来对三元组进行排名。有关更多详细信息,请参见pykeen.models.inductive.InductiveNodePieceGNN。
基于标签的Transformer表示
如果实体描述可用,通用特征化机制可以是通过pykeen.nn.representation.LabelBasedTransformerRepresentation访问的语言模型。在训练和推理时,通过将它们的文本描述传递到预训练的语言模型后,可以获得固定大小的实体向量。
这是正在进行的工作,目前尚不可用。
训练与评估
通常,归纳模型的训练和评估使用相似的接口: sLCWA 和 LCWA 训练循环,以及 RankBasedEvaluator。 归纳接口的重要新增内容是 mode 参数。当设置为 mode=”training” 时, 归纳模型必须调用训练图的表示,当设置为 mode=validation 或 mode=testing 时,模型必须调用推理图的表示。 在来自 [teru2020] 的完全归纳(不相交)数据集的情况下,验证和测试时的推理图是相同的。
默认情况下,您可以使用标准的PyKEEN训练循环pykeen.training.SLCWATrainingLoop和
pykeen.training.LCWATrainingLoop与新的mode参数。同样,您可以使用
标准评估器pykeen.evaluation.rank_based_evaluator.RankBasedEvaluator与mode
参数来评估整个推理图上的验证/测试三元组。
此外,[teru2020] 的原始工作使用了一种受限的评估协议,每个验证/测试三元组仅针对50个随机负样本进行排名。PyKEEN 使用 pykeen.evaluation.rank_based_evaluator.SampledRankBasedEvaluator 实现了这一协议。
让我们创建一个训练循环和验证/测试评估器:
from pykeen.datasets.inductive.ilp_teru import InductiveFB15k237
from pykeen.training import SLCWATrainingLoop
from pykeen.evaluation.rank_based_evaluator import SampledRankBasedEvaluator
from pykeen.losses import NSSALoss
dataset = InductiveFB15k237(version="v1", create_inverse_triples=True)
model = ... # model init here, one of InductiveNodePiece
optimizer = ... # some optimizer
training_loop = SLCWATrainingLoop(
triples_factory=dataset.transductive_training, # training triples
model=model,
optimizer=optimizer,
mode="training", # necessary to specify for the inductive mode - training has its own set of nodes
)
valid_evaluator = SampledRankBasedEvaluator(
mode="validation", # necessary to specify for the inductive mode - this will use inference nodes
evaluation_factory=dataset.inductive_validation, # validation triples to predict
additional_filter_triples=dataset.inductive_inference.mapped_triples, # filter out true inference triples
)
test_evaluator = SampledRankBasedEvaluator(
mode="testing", # necessary to specify for the inductive mode - this will use inference nodes
evaluation_factory=dataset.inductive_testing, # test triples to predict
additional_filter_triples=dataset.inductive_inference.mapped_triples, # filter out true inference triples
)
完全归纳LP示例
一个在InductiveFB15k237 (v1)上训练InductiveNodePieceGNN的最小工作示例,使用sLCWA模式,每个正样本有32个负样本,使用NSSALoss和SampledEvaluator,看起来像这样:
from pykeen.datasets.inductive.ilp_teru import InductiveFB15k237
from pykeen.models.inductive import InductiveNodePieceGNN
from pykeen.training import SLCWATrainingLoop
from pykeen.evaluation.rank_based_evaluator import SampledRankBasedEvaluator
from pykeen.stoppers import EarlyStopper
from pykeen.losses import NSSALoss
from torch.optim import Adam
dataset = InductiveFB15k237(version="v1", create_inverse_triples=True)
model = InductiveNodePieceGNN(
triples_factory=dataset.transductive_training, # training factory, will be also used for a GNN
inference_factory=dataset.inductive_inference, # inference factory, will be used for a GNN
num_tokens=12, # length of a node hash - how many unique relations per node will be used
aggregation="mlp", # aggregation function, defaults to an MLP, can be any PyTorch function
loss=NSSALoss(margin=15), # dummy loss
random_seed=42,
gnn_encoder=None, # defaults to a 2-layer CompGCN with DistMult composition function
)
optimizer = Adam(params=model.parameters(), lr=0.0005)
training_loop = SLCWATrainingLoop(
triples_factory=dataset.transductive_training, # training triples
model=model,
optimizer=optimizer,
negative_sampler_kwargs=dict(num_negs_per_pos=32),
mode="training", # necessary to specify for the inductive mode - training has its own set of nodes
)
# Validation and Test evaluators use a restricted protocol ranking against 50 random negatives
valid_evaluator = SampledRankBasedEvaluator(
mode="validation", # necessary to specify for the inductive mode - this will use inference nodes
evaluation_factory=dataset.inductive_validation, # validation triples to predict
additional_filter_triples=dataset.inductive_inference.mapped_triples, # filter out true inference triples
)
# According to the original code
# https://github.com/kkteru/grail/blob/2a3dffa719518e7e6250e355a2fb37cd932de91e/test_ranking.py#L526-L529
# test filtering uses only the inductive_inference split and does not include inductive_validation triples
# If you use the full RankBasedEvaluator, both inductive_inference and inductive_validation triples
# must be added to the additional_filter_triples
test_evaluator = SampledRankBasedEvaluator(
mode="testing", # necessary to specify for the inductive mode - this will use inference nodes
evaluation_factory=dataset.inductive_testing, # test triples to predict
additional_filter_triples=dataset.inductive_inference.mapped_triples, # filter out true inference triples
)
early_stopper = EarlyStopper(
model=model,
training_triples_factory=dataset.inductive_inference,
evaluation_triples_factory=dataset.inductive_validation,
frequency=1,
patience=100000, # for test reasons, turn it off
result_tracker=None,
evaluation_batch_size=256,
evaluator=valid_evaluator,
)
# Training starts here
training_loop.train(
triples_factory=dataset.transductive_training,
stopper=early_stopper,
num_epochs=100,
)
# Test evaluation
result = test_evaluator.evaluate(
model=model,
mapped_triples=dataset.inductive_testing.mapped_triples,
additional_filter_triples=dataset.inductive_inference.mapped_triples,
batch_size=256,
)
# print final results
print(result.to_flat_dict())