页面#
表示文档页面的类。页面对象是通过 Document.load_page() 创建的,或者等效地,通过索引文档,例如 doc[n] - 它没有独立的构造函数。
文档与其页面之间存在父子关系。如果文档被关闭或删除,所有存在的页面对象(以及它们各自的子对象)将变得不可用(“孤立”):如果正在使用页面属性或方法,将引发异常。
出于方便,几个页面方法都有一个文档对应。在本章结束时,您将找到一个摘要。
注意
在本章中,我们多次使用术语 坐标。至少对其有基本的理解并感到对坐标部分感到舒适是非常重要的。
修改页面#
仅对于PDF文档,可以更改页面属性以及添加或更改页面内容。
简而言之,您可以使用 PyMuPDF 做以下事情:
修改页面旋转和页面的可见部分(“裁剪框”)。
插入图像、其他PDF页面、文本和简单的几何对象。
添加注释和表单字段。
注意
方法需要坐标(点、矩形)以将内容放置在所需位置。请注意,这些坐标 必须始终 相对于 未旋转 的页面提供(自 v1.17.0 起)。反之亦然:除了 Page.rect 和 Page.bound()(在页面旋转时 反映),所有方法和属性返回的坐标均与未旋转的页面相关。
因此,例如 Page.get_image_bbox() 返回的值,如果您执行 Page.set_rotation() 则不会改变。对于 Page.get_text() 返回的坐标、注释矩形等情况也是如此。如果您想找出一个对象在 旋转坐标 中的位置,请将坐标乘以 Page.rotation_matrix。还有它的逆, Page.derotation_matrix,当与其他阅读器接口时可以使用,这些阅读器在这方面的行为可能会有所不同。
注意
如果您在页面上添加或更新注释、链接或表单字段,并且在此之后立即需要使用它们(即不离开页面),您应该在引用这些新添加或更新的项目之前,使用Document.reload_page()重新加载页面。
一般建议重新加载页面 - 尽管在所有情况下并不严格要求。然而,与MuPDF相比,一些注释和小部件类型在PyMuPDF中具有扩展功能。未来可能还会添加更多这些扩展。
重新加载页面确保您的所有更改已完全应用于PDF结构,因此您可以安全地创建Pixmap或成功遍历注释、链接和表单字段。
方法 / 属性 |
简短描述 |
|---|---|
仅限PDF:添加插入符号注释 |
|
仅限PDF: 添加圆形注释 |
|
仅限PDF:添加文件附件注释 |
|
仅限PDF:添加文本注释 |
|
仅限PDF:添加“高亮”注释 |
|
仅限PDF:添加墨迹注释 |
|
仅限PDF:添加线条注释 |
|
仅限PDF:添加多边形注释 |
|
仅限PDF:添加多行注释 |
|
仅限PDF:添加矩形注释 |
|
仅限PDF:添加一个删除注释 |
|
仅限PDF:添加一个“波浪”注释 |
|
仅限PDF:添加“橡皮章”注释 |
|
仅限PDF:添加“删除线”注释 |
|
仅限PDF:添加评论 |
|
仅限PDF:添加“下划线”注释 |
|
仅限PDF:添加PDF表单字段 |
|
仅限PDF:注释(和小部件)名称的列表 |
|
仅限PDF:注释(和小部件)交叉引用的列表 |
|
返回页面上的注释生成器 |
|
仅限PDF:处理页面的遮盖信息 |
|
页面的矩形 |
|
仅限PDF:矢量图形的边界框 |
|
仅限PDF:删除注释 |
|
仅限PDF:删除图像 |
|
仅限PDF:删除链接 |
|
仅限PDF:删除一个小部件/字段 |
|
仅限PDF:绘制立方Bezier曲线 |
|
仅限PDF:绘制一个圆 |
|
仅限PDF:绘制特殊的贝塞尔曲线 |
|
仅限PDF:绘制一条线 |
|
仅限PDF:绘制椭圆 |
|
仅限PDF:连接一系列点 |
|
仅限PDF:绘制一个四边形 |
|
仅限PDF:绘制一个矩形 |
|
仅限PDF:绘制圆形扇形 |
|
仅限PDF:画一条波浪线 |
|
仅限PDF:绘制锯齿状线 |
|
在页面上定位表格 |
|
获取页面上的矢量图形 |
|
仅限PDF:获取引用字体的列表 |
|
仅限于PDF:获取嵌入图像的边界框和矩阵 |
|
获取所有使用的图像的元信息列表 |
|
仅限PDF: |
|
仅限PDF:获取引用图像的列表 |
|
仅限PDF:返回页面的标签 |
|
获取所有链接 |
|
创建一个栅格格式的页面图像 |
|
创建SVG格式的页面图像 |
|
提取页面的文本 |
|
提取矩形内包含的文本 |
|
为该页面创建一个带有OCR的文本页 |
|
为页面创建一个文本页面 |
|
仅限PDF:获取引用的xobjects列表 |
|
仅限PDF:为页面插入一个字体 |
|
仅限PDF:插入图像 |
|
仅限PDF:插入链接 |
|
仅限PDF:插入文本 |
|
仅限PDF:在矩形中插入html文本 |
|
仅限PDF:插入文本框 |
|
返回页面上的链接生成器 |
|
仅限PDF:加载特定的注释 |
|
仅限PDF:加载特定字段 |
|
返回页面上的第一个链接 |
|
仅限PDF: 创建一个新的 Shape |
|
仅限PDF:将页面旋转设置为0 |
|
仅限 PDF:替换图像 |
|
搜索字符串 |
|
仅限PDF:修改 |
|
仅限PDF:修改 |
|
仅限PDF:修改 |
|
仅限PDF:修改 |
|
仅限PDF:设置页面旋转 |
|
仅限PDF:修改 |
|
仅限PDF:显示PDF页面图像 |
|
仅限PDF:修改链接 |
|
返回页面上字段的生成器 |
|
写入一个或多个 TextWriter 对象 |
|
剪裁框的 |
|
页面的 |
|
页面的 |
|
页面的 |
|
页面的 |
|
仅限PDF:获取未旋转页面空间中的坐标 |
|
页面上的第一个 Annot |
|
页面上的第一个 链接 |
|
页面上的第一个小部件(表单字段) |
|
媒介框的右下角点 |
|
页面的 |
|
页码 |
|
拥有文档对象 |
|
页面的矩形 |
|
仅限PDF:获取旋转页面空间中的坐标 |
|
仅限PDF:页面旋转 |
|
仅限PDF:在PDF和MuPDF空间之间转换 |
|
仅限PDF:页面 |
类 API
- class Page#
- bound()#
确定页面的矩形。与属性
Page.rect相同。对于 PDF 文档,这 通常 也与mediabox和cropbox重合,但并不总是。例如,如果页面被旋转,则这个方法将反映这一变化 – 然而Page.cropbox将不会改变。- Return type:
- add_caret_annot(point)#
仅限PDF:添加插入符号图标。插入符号注解是一个视觉符号,通常用于表示页面上文本编辑的存在。
- Parameters:
point (point_like) – 包含MuPDF提供图标的20 x 20矩形的左上角点。
- Return type:
- Returns:
创建的注释。边框颜色蓝色 = (0, 0, 1),不支持填充颜色。

显示/隐藏历史
v1.16.0 中的新功能
- add_text_annot(point, text, icon='Note')#
仅限PDF:添加一个带有附带文本的评论图标(“便签”)。只有图标是可见的,附带文本是隐藏的,可以通过将鼠标悬停在符号上来在许多PDF查看器中可视化。
- add_freetext_annot(rect, text, fontsize=12, fontname='helv', border_color=None, text_color=0, fill_color=1, rotate=0, align=TEXT_ALIGN_LEFT)#
仅限PDF:在给定的矩形中添加文本。
- Parameters:
rect (rect_like) – 文字应插入的矩形。文本将在框的宽度处自动换行。未适合框的行将不可见。
文本 (str) – 该文本。可以包含任何混合的拉丁字母、希腊字母、西里尔字母、中文、日文和韩文字符。所需的字体会自动确定。(v1.17.0 新增)
fontsize (float) – 字体大小
fontsize。默认值为 12。fontname (str) – 字体名称。默认是“Helv”。 接受的替代选项有“Cour”、“TiRo”、“ZaDb”和“Symb”。 名称可以缩写为前两个字符,比如“Co”代表“Cour”。 也接受小写字母。 粗体或斜体变体的字体不被接受(在v1.16.0中更改)。 用户贡献的脚本提供了绕过此限制的方法 – 请参见章节 使用按钮和JavaScript 中的 常见问题解答。 现在实际使用的字体是按字符水平确定的,所有必需的字体(或子字体)会自动包含。 因此,您几乎不需要关心此参数并让其默认为值(除非您坚持为非CJK文本部分使用衬线字体)。 (v1.17.0中新加入)
text_color (sequence,float) – 文本颜色。默认是黑色。 (v1.16.0中的新特性)
fill_color (sequence,float) – 填充颜色。默认为白色。 (在 v1.16.0 中新增)
text_color – 文本颜色。默认是黑色。
border_color (sequence,float) – 边框颜色。默认值是
None。 (在 v1.19.6 中新增加)对齐 (整数) – 文本对齐方式,取值为 TEXT_ALIGN_LEFT、TEXT_ALIGN_CENTER、TEXT_ALIGN_RIGHT - 不支持两端对齐。 (版本1.17.0中新增加)
rotate (int) – 文本方向。接受的值为 0, 90, 270,无效条目将被设置为零。
- Return type:
- Returns:
创建的注释。颜色属性 只能通过
Annot.update()的特殊参数进行更改。在这里,您还可以设置与文本颜色不同的边框颜色。
显示/隐藏历史
在v1.19.6中更改:添加边框颜色参数
- add_file_annot(pos, buffer, filename, ufilename=None, desc=None, icon='PushPin')#
仅支持PDF:在指定位置添加一个带有“PushPin”图标的文件附件注释。
- Parameters:
pos (point_like) – 包含MuPDF提供的“PushPin”图标的18x18矩形的左上角点。
buffer (bytes,bytearray,BytesIO) –
要存储的数据(实际文件内容、任何数据等)。
在 v1.14.13 中更改:io.BytesIO 现在也被支持。
filename (str) – 要与数据关联的文件名。
ufilename (str) – 文件名的可选PDF Unicode版本。默认为文件名。
desc (str) – 文件的可选描述。默认为文件名。
图标 (str) – 选择“PushPin”(默认)、“Graph”、“Paperclip”、“Tag”中的一个作为附加数据的视觉符号 [4]. (在v1.16.0中新增)
- Return type:
- Returns:
创建的注释。 线条颜色黄色 = (1, 1, 0),不支持填充颜色。
- add_ink_annot(list)#
仅限PDF: 添加一个“手绘”涂鸦注释。
- Parameters:
list (sequence) – 一个包含一个或多个列表的列表,每个列表包含
point_like项目。这些子列表中的每个项目被解释为一个 Point,通过这个点绘制连接线。因此,单独的子列表代表单独的绘图线。- Return type:
- Returns:
默认外观中创建的注释为黑色 =(0, 0, 0),线宽为1。不支持填充颜色。
- add_line_annot(p1, p2)#
仅限PDF:添加行注释。
- Parameters:
p1 (point_like) – 线的起始点。
p2 (point_like) – 线的终点。
- Return type:
- Returns:
创建的注释。它的线条(描边)颜色为红色 = (1, 0, 0),线宽为1。没有填充颜色支持。注释矩形会自动创建以包含两个点,每个点周围有一个半径为 3 * 线宽的圆,以便为任何线条结束符号留出空间。
- add_rect_annot(rect)#
- add_circle_annot(rect)#
仅限PDF:添加矩形或圆形注释。
- Parameters:
rect (rect_like) – 画圆或矩形的矩形,必须是有限的且不为空。如果矩形不是等边的,则绘制一个椭圆。
- Return type:
- Returns:
创建的注释。它以红色线条(笔画)绘制,线宽为1,支持填充颜色。
编辑#
- add_redact_annot(quad, text=None, fontname=None, fontsize=11, align=TEXT_ALIGN_LEFT, fill=(1, 1, 1), text_color=(0, 0, 0), cross_out=True)#
仅限PDF:添加一个隐藏标注。隐藏标注标识要从文档中删除的内容。添加该标注是两个步骤中的第一个。它清楚地显示了在随后的步骤中将要删除的内容,
Page.apply_redactions()。- Parameters:
quad (quad_like,rect_like) – 指定要移除的(矩形)区域,该区域始终等于注释矩形。这可以是一个
rect_like或quad_like对象。如果指定了 quad,则采用包围矩形。文本 (str) – 在应用编辑后放置于矩形中的文本(因此移除旧内容)。 (v1.16.12的新功能)
fontname (str) –
在给定text时使用的字体,否则忽略。适用相同的规则,如
Page.insert_textbox()– 这是方法Page.apply_redactions()内部调用的。替换文本将垂直居中,如果这是CJK或PDF Base 14 Fonts之一。(在v1.16.12中新增)注意
对于页面的现有字体,使用其引用名称作为fontname(这是
Page.get_fonts()中条目的item[4])。对于新的,非内置字体,如下进行:
page.insert_text(point, # 任何地方,但在所有涂抹矩形之外 "something", # 一些非空字符串 fontname="newname", # 新的,未使用的引用名称 fontfile="...", # 所需的字体文件 render_mode=3, # 使文本不可见 ) page.add_redact_annot(..., fontname="newname")
字体大小 (浮点数) – 用于替换文本的
fontsize。如果文本太大,无法适应,将进行多次插入尝试,逐渐将fontsize降至不低于 4。如果此时文本仍然无法适应,则不会进行任何文本插入。(在 v1.16.12 中新增)align (int) – 替换文本的水平对齐方式。请参见
insert_textbox()获取可用值。如果使用PDF内置字体(CJK或 PDF Base 14 Fonts),则垂直对齐大致为居中。(v1.16.12 新增)fill (sequence) – 矩形的填充颜色 在应用 涂黑后。默认值为 white = (1, 1, 1),如果指定
None也会采用这个值。要完全抑制填充颜色,请指定False。在这种情况下,矩形保持透明。(v1.16.12 中的新功能)text_color (sequence) – 替换文本的颜色。默认值为 black = (0, 0, 0)。 (v1.16.12 中新增)
cross_out (bool) – 在注释矩形上添加两条对角线。 (新版本 v1.17.2)
- Return type:
- Returns:
创建的注释。其标准外观看起来像一个红色矩形(没有填充颜色),可选地显示两条对角线。现在可以通过
Annot.update()设置和应用颜色、线宽、虚线、透明度和混合模式,和其他注释一样。(在v1.17.2中更改)

显示/隐藏历史
v1.16.11中的新增内容
- apply_redactions(images=PDF_REDACT_IMAGE_PIXELS | 2, graphics=PDF_REDACT_LINE_ART_REMOVE_IF_TOUCHED | 2, text=PDF_REDACT_TEXT_REMOVE | 0)#
仅限PDF: 移除页面上任何遮蔽矩形包含的所有内容。
此方法应用并删除页面上的所有遮盖信息。
- Parameters:
图像 (整型) – 如何处理重叠的图像。默认值 (2) 会屏蔽重叠的像素。
PDF_REDACT_IMAGE_NONE | 0忽略,PDF_REDACT_IMAGE_REMOVE | 1完全移除与任何编辑注释重叠的图像。选项PDF_REDACT_IMAGE_REMOVE_UNLESS_INVISIBLE | 3仅移除实际上可见的图像。graphics (int) – 如何修正重叠的矢量图形(也称为“线条艺术”或“图纸”)。默认值(2)会移除任何重叠的矢量图形。
PDF_REDACT_LINE_ART_NONE | 0忽略,而PDF_REDACT_LINE_ART_REMOVE_IF_COVERED | 1会移除完全包含在修订注释中的图形。移除线条艺术时,请注意 描边 矢量图形(即类型 “s” 或 “sf”)的 包装矩形更大,可能超出预期:首先,路径的线宽至少需要在每个方向上增加50%才能真正包含所有绘图。如果提供了所谓的“斜接限制”(参见 PDF 规范的第121页),则放大值为miter * width / 2。所以,当一切使用默认值(宽度 = 1,斜接 = 10)时,修订矩形在每个方向上至少应大于5个点。text (int) – 是否删除重叠文本。默认值
PDF_REDACT_TEXT_REMOVE | 0会移除所有边界框与任何编辑矩形重叠的字符。这符合编辑注释的原始法律/数据保护意图。然而,其他使用案例可能需要在编辑矢量图形或图像时保留文本。这可以通过设置text=True|PDF_REDACT_TEXT_NONE | 1来实现。这不符合 编辑注释的数据保护意图。这样做风险自负。
- Returns:
True如果至少处理了一个红action注释,False否则。
注意
包含在删除矩形中的文本将被物理上从页面中移除(假设
Document.save()使用了合适的垃圾选项),并且将不再出现在例如文本提取或其他任何地方。所有删除注释也将被移除。其他注释不受影响。所有重叠的链接将被移除。如果链接的矩形覆盖了文本,则仅重叠的文本部分会被移除。类似地,链接矩形覆盖的图像也适用此规则。
图像的重叠部分将在默认选项
PDF_REDACT_IMAGE_PIXELS中被屏蔽(在 v1.18.0 中更改)。选项 0 不会触及任何图像,而选项 1 将移除任何重叠的图像。对于选项
images=PDF_REDACT_IMAGE_REMOVE,仅此页面的 对图像的引用 被移除 - 并不一定是图像本身。只有当图像完全不再被引用时(假设有合适的垃圾收集选项),图像才会完全从文件中移除。对于选项
images=PDF_REDACT_IMAGE_PIXELS,将创建一个新的PNG格式图像,页面将用它替代原始图像。原始图像在此过程中不会被删除或替换,因此其他页面仍可能显示原始图像。此外,当前新的、修改过的PNG图像是以未压缩方式存储的。在选择合适的垃圾回收方法和保存时的压缩选项时,请牢记这些方面。文本删除是通过字符进行的:如果字符的边界框与一个修订矩形有非空重叠,则该字符将被删除(在MuPDF v1.17中更改)。根据字体属性和/或所选择的行高,可能会删除不想要的文本部分。在文本搜索之前使用
Tools.set_small_glyph_heights(),并传递一个True参数可能有助于防止这种情况。涂黑是一种简单的方法,用于替换PDF中的单个词或直接将其移除。使用某种文本提取或搜索方法定位到词“秘密”,并插入涂黑,将“xxxxxx”作为每个出现的替换文本。
如果替换的内容比原始内容长,请谨慎处理——这可能导致外观尴尬、换行或根本没有新文本。
由于多种原因,新文本可能不会像旧文本那样精确地定位在同一行——特别是当替换的字体不是CJK或PDF Base 14 Fonts时。
显示/隐藏历史
v1.16.11中的新增内容
在 v1.16.12 中更改:之前的 mark 参数已被删除。相应的矩形被填充为每个删减注释的单独 fill 颜色。如果注释中给出了 text,则调用
insert_textbox()来插入它,使用与删减一起提供的参数。在v1.18.0中更改:添加了处理与遮盖区域重叠的图像的选项。
在 v1.23.27 中更改:添加了移除图形的选项。
在 v1.24.2 中更改:添加选项
keep_text以保持文本不变。
- add_polyline_annot(points)#
- add_polygon_annot(points)#
仅限PDF:添加一个由连接给定点的线组成的注释。一个 多边形 的第一个和最后一个点会自动连接,而 折线 则不会。 矩形 会自动创建为包含这些点的最小矩形,每个点周围都有一个半径为3(= 3 * 线宽)的圆圈。以下显示了一个已被修改颜色和线条结束的‘折线’。
- Parameters:
points (list) – 一个
point_like对象的列表。- Return type:
- Returns:
创建的注释。它用黑色线条绘制,线宽为1,没有填充颜色,但支持填充颜色。使用Annot的方法进行任何更改,以达到类似这样的效果:

- add_underline_annot(quads=None, start=None, stop=None, clip=None)#
- add_strikeout_annot(quads=None, start=None, stop=None, clip=None)#
- add_squiggly_annot(quads=None, start=None, stop=None, clip=None)#
- add_highlight_annot(quads=None, start=None, stop=None, clip=None)#
仅限PDF:这些注释通常用于标记文本,这些文本之前以某种方式被找到(例如通过
Page.search_for())。但这不是必须的:你可以自由地“标记”任何内容。标准(仅描边 - 不支持填充颜色)颜色按注释类型选择: 黄色 用于高亮, 红色 用于删除线, 绿色 用于下划线, 品红色 用于波浪下划线。
这四种方法将参数转换为Quad对象的列表。然后计算注释矩形以包含所有这些四边形。
注意
search_for()返回一个包含 Rect 或 Quad 对象的列表。这样的列表可以直接作为这些注释类型的参数使用,并将为搜索字符串的所有出现提供 一个共同的注释:>>> # prefer quads=True in text searching for annotations! >>> quads = page.search_for("pymupdf", quads=True) >>> page.add_highlight_annot(quads)
注意
显然,文本标记注释需要知道要标记区域的顶部、底部、左侧和右侧。如果参数是四元组,这些信息通过四个点的顺序给出。相比之下,矩形提供的信息少得多——这通过如下事实得以说明:可以用矩形的四个角构造出24种不同的四元组,4! = 24。
因此,我们强烈建议使用
quads选项进行文本搜索,以确保注释的正确性。类似的考虑适用于使用Page.get_text()的“dict” / “rawdict”选项提取的文本跨度标记。有关如何在这种情况下计算四边形的更多详细信息,请参见常见问题解答的“如何标记非水平文本”部分。- Parameters:
quads (rect_like,quad_like,list,tuple) – 位置 - 矩形或四边形 - 要标记的。 (在 v1.14.20 中更改) 列表或元组必须由
rect_like或quad_like项(甚至两者的混合)组成。 每个项目必须是有限的、凸的且不为空(如适用)。 将此参数设置为None如果您想使用以下参数 (在 v1.16.14 中更改)。 反之亦然:如果不是None,其余参数必须是None。开始 (point_like) – 在这个点开始文本标记。默认为clip的左上角。如果
quads为None,则必须提供。 (在v1.16.14中新增)stop (point_like) – 在此点停止文本标记。默认为clip的右下角。如果
quads为None,必须使用此选项。 (在v1.16.14中新增加)clip (rect_like) – 仅考虑与该区域相交的文本行。默认为页面矩形。仅在提供
start和stop时使用。(在 v1.16.14 中新增)
- Return type:
标注 或
None(在 v1.16.14 中更改)。- Returns:
创建的注释。如果 quads 是一个空列表,不创建注释 (在 v1.16.14 中更改)。
注意
您可以使用参数 start、stop 和 clip 来突出显示 start 和 stop 之间的连续行(从 v1.16.14 开始)。 使用 clip 进一步减少所选行的边界框,从而处理例如多列页面。以下在具有三列文本的页面上的多行高亮显示是通过指定两个红点并相应设置 clip 创建的。

- cluster_drawings(clip=None, drawings=None, x_tolerance=3, y_tolerance=3)#
基于几何邻近的聚类矢量图形(同义词为线条艺术或图形)。该方法遍历
Page.get_drawings()的输出,并连接那些path["rect"]之间距离比某些容差值(在参数中给出)更近的路径。结果是一个矩形列表,每个矩形包裹着诸如表格(带有网格线)、饼图、条形图等内容。- Parameters:
clip (rect_like) – 只考虑在此区域内的路径。默认是整个页面。
drawings (list) – (可选)提供之前生成的
Page.get_drawings()输出。如果None,该方法将执行该方法。x_tolerance (float) – 容差值
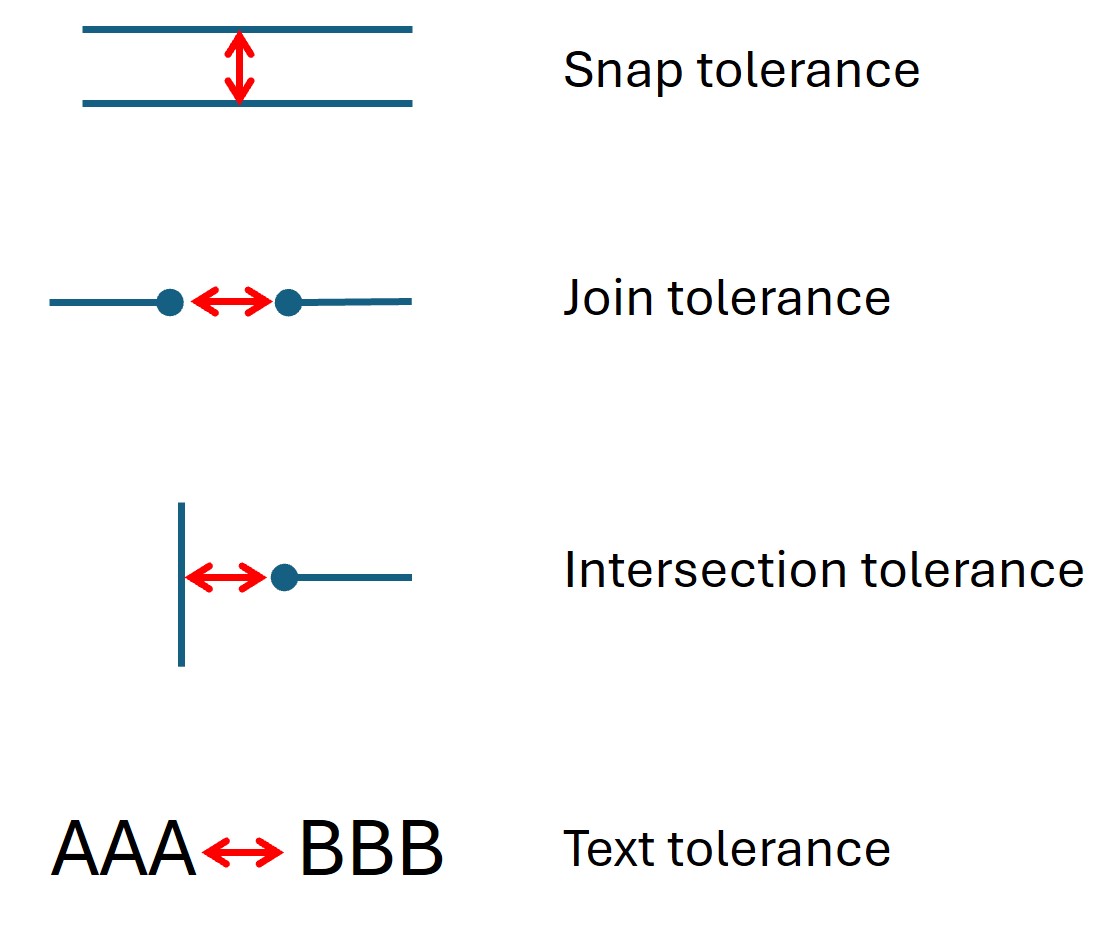
- find_tables(clip=None, strategy=None, vertical_strategy=None, horizontal_strategy=None, vertical_lines=None, horizontal_lines=None, snap_tolerance=None, snap_x_tolerance=None, snap_y_tolerance=None, join_tolerance=None, join_x_tolerance=None, join_y_tolerance=None, edge_min_length=3, min_words_vertical=3, min_words_horizontal=1, intersection_tolerance=None, intersection_x_tolerance=None, intersection_y_tolerance=None, text_tolerance=None, text_x_tolerance=None, text_y_tolerance=None, add_lines=None)#
在页面上查找表格并返回一个包含相关信息的对象。通常情况下,许多参数的默认值就足够了。仅在边缘情况下才需要进行调整。
- Parameters:
clip (rect_like) – 指定页面矩形内要考虑的区域,忽略其余部分。默认是整个页面。
strategy (str) –
请求一个 表格检测 策略。有效值为“lines”,“lines_strict”和“text”。
默认值为 “lines”,它使用页面上的所有矢量图形来检测网格线。
策略 “lines_strict” 忽略无边框矩形的矢量图形。有时单个文本片段有背景颜色,可能导致出现错误的列或行。该策略会忽略这些,从而增加检测精度。
如果指定 “text”,文本位置将被用来生成“虚拟”列和/或行边界。使用
min_words_*请求考虑其坐标的单词数量。使用参数
vertical_strategy和horizontal_strategy代替 以获得对维度的更细粒度处理。horizontal_lines (sequence[floats]) – 行的y坐标。如果提供,将不会尝试识别其他表行。这会影响表的检测。
vertical_lines (sequence[floats]) – 列的 x 坐标。如果提供,将不会尝试识别其他表列。这会影响表的检测。
min_words_vertical (int) – 适用于垂直策略选项“文本”:至少必须有这么多单词 совпадать才能建立 虚拟列 边界。
min_words_horizontal (int) – 适用于横向策略选项 “text”:必须有至少这么多单词重合才能建立虚拟行边界。
snap_tolerance (float) – 任意两条水平线的 y 值之间的差异不超过此值将被 合并 为一条。因此对于竖直线也是如此。默认值为 3。可以使用
snap_x_tolerance和snap_y_tolerance为各个维度指定不同的值。join_tolerance (float) – 任何两条线条将被连接为一条,如果它们的起点和终点的差异不超过该值(以点为单位)。默认值为3。可以使用
join_x_tolerance和join_y_tolerance为各个维度指定不同的值。edge_min_length (float) – 如果一条线的长度不超过该值(点),则忽略该线。默认值为3。
intersection_tolerance (float) – 当将线条合并为单元格边框时,正交线条必须在该值(点)范围内才能被视为相交。默认值为3。可以使用
intersection_x_tolerance和intersection_y_tolerance为尺寸指定单独的值。text_tolerance (float) – 字符只能在它们的距离不大于此值(点)时组合成单词。默认值为3。除了这个值,可以使用
text_x_tolerance和text_y_tolerance为不同维度指定单独的值。add_lines (tuple,list) – 指定一组“线”(即
point_like对象的配对)作为 附加的、“虚拟”的矢量图形。这些线可能有助于表格和/或单元格检测,否则不会影响检测策略。特别地,与参数horizontal_lines和vertical_lines相比,它们不会以其他方式阻止检测行或列。这些线将在连接、吸附、相交、最小长度和在clip矩形内的包含性方面被视为“真实”的矢量图形。类似地,与任何坐标轴不平行的线将被忽略。
- Returns:
a
TableFinderobject that has the following significant attributes:cells: a list of all bboxes on the page, that have been identified as table cells (across all tables). Each cell is arect_liketuple(x0, y0, x1, y1)of coordinates orNone.tables: a list ofTableobjects. This is[]if the page has no tables. Single tables can be found as items of this list. But theTableFinderobject itself is also a sequence of its tables. This means that iftabsis aTableFinderobject, then table “n” is delivered bytabs.tables[n]as well as by the shortertabs[n].The
Tableobject has the following attributes:bbox: the bounding box of the table as a tuple(x0, y0, x1, y1).cells: bounding boxes of the table’s cells (list of tuples). A cell may also beNone.extract(): this method returns the text content of each table cell as a list of list of strings.to_markdown(): this method returns the table as a string in markdown format (compatible to Github). Supporting viewers can render the string as a table. This output is optimized for small token sizes, which is especially beneficial for LLM/RAG feeds. Pandas DataFrames (see methodto_pandas()below) offer an equivalent markdown table output which however is better readable for the human eye.to_pandas(): this method returns the table as a pandas DataFrame. DataFrames are very versatile objects allowing a plethora of table manipulation methods and outputs to almost 20 well-known formats, among them Excel files, CSV, JSON, markdown-formatted tables and more.DataFrame.to_markdown()generates a Github-compatible markdown format optimized for human readability. This method however requires the package tabulate to be installed in addition to pandas itself.header: aTableHeaderobject containing header information of the table.col_count: an integer containing the number of table columns.row_count: an integer containing the number of table rows.rows: a list ofTableRowobjects containing two attributes,bboxis the boundary box of the row, andcellsis a list of table cells contained in this row.
The
TableHeaderobject has the following attributes:bbox: the bounding box of the header.cells: a list of bounding boxes containing the name of the respective column.names: a list of strings containing the text of each of the cell bboxes. They represent the column names – which are used when exporting the table to pandas DataFrames, markdown, etc.external: a bool indicating whether the header bbox is outside the table body (True) or not. Table headers are never identified by theTableFinderlogic. Therefore, ifexternalis true, then the header cells are not part of any cell identified byTableFinder. Ifexternal == False, then the first table row is the header.
Please have a look at these Jupyter notebooks, which cover standard situations like multiple tables on one page or joining table fragments across multiple pages.
Caution
The lifetime of the
TableFinderobject, as well as that of all its tables equals the lifetime of the page. If the page object is deleted or reassigned, all tables are no longer valid.The only way to keep table content beyond the page’s availability is to extract it via methods
Table.to_markdown(),Table.to_pandas()or a copy ofTable.extract()(e.g.Table.extract()[:]).Note
Once a table has been extracted to a Pandas DataFrame with
to_pandas()it is easy to convert to other file types with the Pandas API:
显示/隐藏历史
1.23.0 版本的新特性
在版本 1.23.19 中变更:新增参数
add_lines。
重要
还有pdf2docx extract tables method,如果您愿意,它可以进行表格提取。
- add_stamp_annot(rect, stamp=0)#
仅限PDF:添加“橡皮图章”般的注释,例如指示文档的预期用途(“草稿”、“保密”等)。
- Parameters:
rect (rect_like) – 放置注释的矩形区域。
stamp (int) – 邮票文本的ID号码。可用的邮票见 Stamp Annotation Icons。
注意
印章的文本及其边框线将会自动调整大小,并在给定的矩形中水平和垂直居中。
Annot.rect被自动计算以适应给定的 width,并且通常会小于该参数。选择的字体是“Times Bold”,文本将为大写。
外观可以通过使用
Annot.set_opacity()和设置“stroke”颜色(不支持“fill”颜色)进行更改。这可以用来创建水印图像:在临时 PDF 页面上创建一个透明度值较低的印章注释,使用 alpha=True(并可能还要旋转它)制作一个像素图,丢弃临时 PDF 页面,然后使用该像素图与
insert_image()用于你的目标 PDF。

- add_widget(widget)#
仅限PDF:在页面上添加一个PDF表单字段(“小部件”)。这还将PDF转换为表单PDF。由于小部件可用的选项种类繁多,我们开发了一个新类 Widget,它包含可能的PDF字段属性。它必须用于表单字段的创建和更新。
- delete_annot(annot)#
移除现在将包括任何绑定的‘Popup’或响应注释及相关对象(在v1.16.6中更改)。
仅限PDF:从页面中删除注释并返回下一个。
- delete_widget(widget)#
仅限PDF:从页面中删除字段并返回下一个。
显示/隐藏历史
(新的在 v1.18.4)
- delete_link(linkdict)#
仅限PDF:从页面中删除指定的链接。参数必须是 原始项 的
get_links(),请参阅 get_links() 条目说明。这样做的原因是字典的 “xref” 键,它标识要删除的PDF对象。- Parameters:
linkdict (dict) – 要删除的链接。
- insert_link(linkdict)#
仅限PDF:在此页面插入一个新链接。该参数必须是由
get_links()提供的格式的字典,见 get_links() 条目说明。- Parameters:
linkdict (dict) – 要插入的链接。
- update_link(linkdict)#
仅限PDF:修改指定的链接。参数必须是
get_links()的(修改过的)原始项目,请参阅get_links() 条目的描述。这样做的原因是字典的“xref”键,它标识要更改的PDF对象。- Parameters:
linkdict (dict) – 要修改的链接。
警告
如果更新/插入一个 URI 链接 (
"kind": LINK_URI), 请确保为"uri"键的值以一个具有区别性的字符串开始,例如"http://","https://","file://","ftp://","mailto:"等。否则——根据你的浏览器或其他“消费者”软件——意外的默认假设可能会导致不必要的行为。
- get_label()#
仅限PDF:返回页面的标签。
- Return type:
字符串
- Returns:
像“vii”这样的标签字符串用于罗马数字,或者如果未定义则为“”。
显示/隐藏历史
v1.18.6 中的新功能
- get_links()#
检索页面的所有链接。
- Return type:
列表
- Returns:
一个字典的列表。有关字典条目的描述,请参阅 get_links() 条目的描述。如果您打算更改页面的链接,请始终使用此方法或
Page.links()方法。
- links(kinds=None)#
返回一个生成器,遍历页面的链接。结果等于
Page.get_links()的条目。- Parameters:
kinds (sequence) – 一系列整数,用于选择一个或多个链接类型。默认是所有链接。示例:kinds=(pymupdf.LINK_GOTO,) 仅会返回内部链接。
- Return type:
生成器
- Returns:
每次迭代的
Page.get_links()的条目。
显示/隐藏历史
v1.16.4中的新功能
- annots(types=None)#
返回一个生成器,生成页面的注释。
- Parameters:
types (sequence) – 一系列整数,用于选择一个或多个注释类型。默认是所有注释。示例:
types=(pymupdf.PDF_ANNOT_FREETEXT, pymupdf.PDF_ANNOT_TEXT)将仅返回‘FreeText’和‘Text’注释。- Return type:
生成器
- Returns:
每次迭代的注释。
注意
你不能安全地从这个生成器中更新注释。这是因为大多数注释更新需要通过
page = doc.reload_page(page)重新加载页面。为了绕过这个限制,首先制作注释的xref编号列表,然后迭代这些编号:在 [4]: xrefs = [annot.xref for annot 在 page.annots(types=[...])] 在 [5]: for xref 在 xrefs: ...: annot = page.load_annot(xref) ...: annot.update() ...: page = doc.reload_page(page) 在 [6]:
显示/隐藏历史
v1.16.4中的新功能
- widgets(types=None)#
返回一个生成器,用于页面的表单字段。
- Parameters:
types (sequence) – 一串整数,用于选择一个或多个小部件类型。默认是所有表单字段。示例:
types=(pymupdf.PDF_WIDGET_TYPE_TEXT,)将只返回‘文本’字段。- Return type:
生成器
- Returns:
每次迭代一个 Widget。
显示/隐藏历史
v1.16.4中的新功能
- write_text(rect=None, writers=None, overlay=True, color=None, opacity=None, keep_proportion=True, rotate=0, oc=0)#
仅限PDF:将一个或多个 TextWriter 对象的文本写入页面。
- Parameters:
rect (rect_like) – 文本放置的位置。如果省略,则使用文本写入者的矩形并集。
writers (sequence) – 一个不为空的元组 / 列表,包含 TextWriter 对象或者一个单独的 TextWriter。
不透明度 (浮点数) – 设置透明度,覆盖文本写入器中的相应值。
color (sequ) – 设置文本颜色,覆盖文本写入器中的相应值。
覆盖 (布尔值) – 将文本放置在前景或背景中。
keep_proportion (bool) – 维护纵横比。
rotate (float) – 将文本旋转一个任意角度.
注意
参数 overlay, keep_proportion, rotate 和 oc 的含义与
Page.show_pdf_page()中相同。显示/隐藏历史
v1.16.18中的新功能
- insert_text(point, text, *, fontsize=11, fontname='helv', fontfile=None, idx=0, color=None, fill=None, render_mode=0, border_width=1, encoding=TEXT_ENCODING_LATIN, rotate=0, morph=None, stroke_opacity=1, fill_opacity=1, overlay=True, oc=0)#
仅限PDF:在
point_likepoint开始插入文本行。请参见Shape.insert_text()。显示/隐藏历史
在v1.18.4中更改
- insert_textbox(rect, buffer, *, fontsize=11, fontname='helv', fontfile=None, idx=0, color=None, fill=None, render_mode=0, border_width=1, encoding=TEXT_ENCODING_LATIN, expandtabs=8, align=TEXT_ALIGN_LEFT, charwidths=None, rotate=0, morph=None, stroke_opacity=1, fill_opacity=1, oc=0, overlay=True)#
仅限PDF:将文本插入指定的
rect_like矩形。参见Shape.insert_textbox()。显示/隐藏历史
在 v1.18.4 中更改
- insert_htmlbox(rect, text, *, css=None, scale_low=0, archive=None, rotate=0, oc=0, opacity=1, overlay=True)#
仅限PDF: 将文本插入指定的矩形。该方法与
Page.insert_textbox()和TextWriter.fill_textbox()方法有相似之处,但更为强大. 这是通过让Story对象进行所有必要的处理实现的。参数
text可以是一个字符串,如同其他方法一样。但它将被 解释为HTML源代码,因此也可以包含HTML语言元素——包括样式。css参数可用于传递额外的样式指令。自动换行在单词边界处生成。“软连字符”字符
""(或) 可以用来导致连字符,因此也可能导致换行。然而,强制换行只能通过 HTML 标签\n会被忽略,并将被视为一个空格。通过这种方法可以实现以下目标:
样式效果,如粗体、斜体、文本颜色、文本对齐、字体大小或字体切换。
文本可能包括任意语言 - 包括从右到左的语言。
像德瓦那加里和亚洲其他几种脚本具有高度复杂的连字系统,其中两个或多个unicode组合在一起生成一个字形。该故事使用软件包HarfBuzz来处理这些问题并产生正确的输出。
还可以通过 HTML 标签
Page.insert_image()。HTML 表格(标签
当存在时,链接会自动生成。
如果内容不适合矩形,开发者有两种选择:
要么 只被告知这一点(并接受一个无操作,就像其他文本框插入方法一样),
或 (
scale_low=0- 默认值) 缩小内容直到它适合为止。
- Parameters:
rect (rect_like) – 页面上的矩形,用于接收文本。
文本 (str,故事) – 要写入的文本。可以包含纯文本和带有样式指令的HTML标签的混合。或者,可以指定一个故事对象(在这种情况下,将省略内部故事生成步骤)。故事必须已经生成并包含所有必要的样式和归档信息。
css (str) – 可选字符串,包含额外的CSS指令。如果
text是一个故事,则此参数被忽略。scale_low (float) – 如果必要,将内容缩小直到适合目标矩形。这设置了缩小的限制。默认值为0,没有限制。值为1表示不允许缩小。值例如0.2表示最大缩小80%。
archive (Archive) – 一个指向查找图像或非标准字体位置的档案对象。如果
text指的是图像或非标准字体,则该参数是必需的。如果text是一个故事,则忽略此参数。rotate (int) –
值之一为 0、90、180、270。根据这个值,文本将被填充:
0: 从左上到右下。
90: 从左下到右上。
180: 从右下到左上。
270: 从右上到左下。

oc (int) – 一个
OCG/OCMD的 xref 或 0。有关详细信息,请参阅Page.show_pdf_page()。不透明度 (浮点数) – 设置内容的填充和描边不透明度。只有
0 <= 不透明度 < 1的值会被考虑。叠加 (布尔值) – 将文本放在其他内容前面。有关详细信息,请参阅
Page.show_pdf_page()。
- Returns:
一个浮点数元组
(spare_height, scale).spare_height: 如果内容未能适配则为 -1,其他情况为 >= 0。它是未使用(仍然可用)矩形条纹的高度。仅在 scale = 1(没有缩小)时为正值。scale: 缩小因子,0 < scale <= 1.
请参考本节食谱中的示例: 如何用 HTML 文本填充一个框。
显示/隐藏历史
新功能在 v1.23.8;仅重新基准。
v1.23.9 新增:
opacity参数。
绘图方法
- draw_line(p1, p2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:从 p1 到 p2 画一条线 (
point_likes)。请参见Shape.draw_line()。显示/隐藏历史
在 v1.18.4 中更改
- draw_zigzag(p1, p2, breadth=2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:从 p1 到 p2 绘制一条锯齿形的线 (
point_likes)。请参见Shape.draw_zigzag()。显示/隐藏历史
在 v1.18.4 中更改
- draw_squiggle(p1, p2, breadth=2, color=(0,), width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:从 p1 到 p2 绘制一条波浪线(波状,起伏的线) (
point_likes)。请参阅Shape.draw_squiggle()。显示/隐藏历史
在 v1.18.4 中更改
- draw_circle(center, radius, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:在 中心 (
point_like) 周围画一个半径为 半径 的圆。见Shape.draw_circle().显示/隐藏历史
在 v1.18.4 中更改
- draw_oval(quad, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:在给定的
rect_like或quad_like内绘制一个椭圆(椭圆形)。请参见Shape.draw_oval()。显示/隐藏历史
在 v1.18.4 中更改
- draw_sector(center, point, angle, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, fullSector=True, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:绘制一个圆形扇形, optionally 将弧连接到圆心(像一片饼)。请参见
Shape.draw_sector()。显示/隐藏历史
在 v1.18.4 中更改
- draw_polyline(points, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:绘制由一系列
point_like定义的多个连接线。请参见Shape.draw_polyline()。显示/隐藏历史
在 v1.18.4 中更改
- draw_bezier(p1, p2, p3, p4, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:绘制从 p1 到 p4 的三次贝塞尔曲线,控制点为 p2 和 p3 (均为
point_like)。参见Shape.draw_bezier()。显示/隐藏历史
在 v1.18.4 中更改
- draw_curve(p1, p2, p3, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, closePath=False, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
PDF 仅适用:这是 draw_bezier() 的一个特例。请参见
Shape.draw_curve()。显示/隐藏历史
在 v1.18.4 中更改
- draw_rect(rect, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, radius=None, oc=0)#
仅限PDF: 绘制一个矩形。见
Shape.draw_rect()。显示/隐藏历史
在 v1.18.4 中更改
在 v1.22.0 中更改:添加了参数 radius。
- draw_quad(quad, color=(0,), fill=None, width=1, dashes=None, lineCap=0, lineJoin=0, overlay=True, morph=None, stroke_opacity=1, fill_opacity=1, oc=0)#
仅限PDF:绘制一个四边形。请参见
Shape.draw_quad()。显示/隐藏历史
在 v1.18.4 中更改
- insert_font(fontname='helv', fontfile=None, fontbuffer=None, set_simple=False, encoding=TEXT_ENCODING_LATIN)#
仅限PDF:添加一个新字体以供文本输出方法使用,并返回其
xref。如果文件中尚不存在,则将添加字体定义。支持内置的Base14_Fonts和通过 “保留的” 字体名称的CJK字体。字体也可以作为文件路径或包含字体文件图像的内存区域提供。- Parameters:
fontname (str) –
在该页面输出文本时对此字体的引用名称。一般来说,这里你有“自由”选择(但请参阅 Adobe PDF References,第 16 页,第 7.3.5 节,以获取关于构建合法 PDF 名称的正式描述)。但是,如果它与
Base14_Fonts中的某个字体或某个 CJK 字体匹配,则 fontfile 和 fontbuffer 将被忽略。换句话说,你不能通过 fontfile / fontbuffer 插入字体,同时给它一个保留的 fontname。
注意
保留的 fontname 可以以任意大小写的混合形式指定,并且仍然可以匹配正确的内置字体定义:字体名称 “helv”、“Helv”、“HELV”、“Helvetica”等都指向相同的字体定义 “Helvetica”。但是从 Page 的角度来看,这些是 不同的引用。在页面上使用同一字体的不同 encoding 变体(拉丁文、希腊文、西里尔文)时,你可以利用这个事实。
fontfile (str) – 字体文件的路径。如果使用,则 fontname 必须是 不同于所有保留名称。
fontbuffer (字节/字节数组) – 字体文件的内存映像。如果使用,fontname 必须是 与所有保留名称不同。该参数通常与
Font.buffer一起使用,用于通过 Font 支持/可用的字体。set_simple (int) – 仅适用于 fontfile / fontbuffer 情况:强制将其视为“简单”字体,即仅使用字符编码高达 255 的字体。
编码 (整数) – 仅适用于
Base14_Fonts的“Helvetica”、“Courier”和“Times”字体集。选择可用编码之一拉丁文 (0)、西里尔文 (2) 或希腊文 (1)。仅对“符号”和“ZapfDingBats”使用默认值 (0 = 拉丁文)。
- Rytpe:
整型
- Returns:
已安装字体的
xref。
注意
内置字体不会导致字体文件的包含。因此,生成的PDF文件将保持较小的体积。然而,您的PDF查看器软件负责生成适当的外观——而且确实存在差异,这取决于它们是否以及如何做到这一点。这对于CJK字体尤其如此。但在某些情况下,Symbol和ZapfDingbats的处理也不正确。以下是字体名称及其相应安装的基本字体名称:
基本-14 字体 [1]
字体名称
已安装的基本字体
评论
helv
赫尔维提卡
正常
heit
赫尔维蒂卡-斜体
斜体
hebo
Helvetica-Bold
粗体
河 北京
Helvetica-BoldOblique
粗斜体
课程
快递
正常
coit
Courier-斜体
斜体
cobo
Courier-Bold
粗体
cobi
Courier-BoldOblique
粗斜体
射击
罗马字体
正常
标题
斜体字
斜体
tibo
Times-Bold
粗体
提比
Times-BoldItalic
粗斜体
符号
符号
zadb
扎普夫丁巴茨
CJK 字体 [2] (中国、日本、韩国)
字体名称
已安装的基本字体
评论
中国-s
黑体
简体中文
中国-ss
宋
简体中文(衬线)
中国-t
方体
传统中文
中国-ts
明
传统中文(衬线体)
日本
哥特式
日语
日本-s
明朝
日文(衬线体)
韩国
Dotum
韩语
韩国-标准
巴唐
韩文字体(衬线)
- insert_image(rect, *, alpha=-1, filename=None, height=0, keep_proportion=True, mask=None, oc=0, overlay=True, pixmap=None, rotate=0, stream=None, width=0, xref=0)#
仅限PDF:在给定的矩形内放置图像。该图像可能已经存在于PDF中,或来自于pixmap、文件或内存区域。
- Parameters:
rect (rect_like) – 图片放置的位置。必须是有限的且不能为空。
alpha (int) – 已废弃并被忽略。
filename (str) – 图像文件的名称(MuPDF支持的所有格式 – 见 支持的输入图像格式)。
高度 (整型) –
keep_proportion (bool) – 维护图像的宽高比。
mask (bytes,bytearray,io.BytesIO) – 内存中的图像 – 用作基础图像的图像掩码(alpha值)。 当指定时,基础图像必须作为文件名或流提供 – 并且不能是已经具有掩码的图像。
oc (int) – (
xref) 使图像的可见性依赖于此OCG或OCMD。在多次插入的第一次之后被忽略。该属性与生成的 PDF 图像对象一起存储,因此 控制图像在整个 PDF 中的可见性。覆盖 – 参见 常见参数。
pixmap (Pixmap) – 一个包含图像的位图。
rotate (int) – 旋转图像。 必须是90度的整数倍。 正值向逆时针方向旋转。 如果你需要按任意角度旋转, 考虑将图像转换为PDF (
Document.convert_to_pdf()) 然后使用Page.show_pdf_page()替代。stream (bytes,bytearray,io.BytesIO) – 内存中的图像(MuPDF 支持的所有格式 – 请参见 支持的输入图像格式)。
宽度 (整型) –
xref (int) – 已在 PDF 中存在的图像的
xref。如果给出,参数filename、 Pixmap、stream、alpha和mask将被忽略。页面将简单地接收到对现有图像的引用。
- Returns:
这个例子在文档的每一页上都放置相同的图像:
>>> doc = pymupdf.open(...) >>> rect = pymupdf.Rect(0, 0, 50, 50) # put thumbnail in upper left corner >>> img = open("some.jpg", "rb").read() # an image file >>> img_xref = 0 # first execution embeds the image >>> for page in doc: img_xref = page.insert_image(rect, stream=img, xref=img_xref, 2nd time reuses existing image ) >>> doc.save(...)
注意
该方法检测多次插入相同图像(如上面的例子),并且只会在第一次执行时存储其数据。这种情况即使在使用默认的
xref=0时也是如此(尽管性能较差)。该方法无法检测在打开文件之前,是否同一图像已经是文件的一部分。
您可以使用此方法为页面提供背景或前景图像,例如版权或水印。请记住,如果将水印放在前景中,则需要透明图像 …
图像可以以未压缩的方式插入,例如,如果使用Pixmap或图像具有alpha通道。因此,考虑在保存文件时使用
deflate=True。此外,还有控制图像大小的方法——即使透明度也会影响。查看如何将图像添加到PDF页面。图像以其原始质量级别存储在PDF中。这 可能远比您显示所需的要好。考虑在插入之前减少图像大小 – 例如,通过使用 pixmap选项,然后缩小或缩放它 (参见 Pixmap 章节)。PIL方法
Image.thumbnail()也可以用于此目的。文件大小的节省可能非常 显著。在多个页面上显示相同图像的另一种有效方法是另一种方法:
show_pdf_page()。请参考Document.convert_to_pdf()了解如何获取可用于该方法的中间PDF。
显示/隐藏历史
在v1.14.1中更改:默认情况下,图像保持其纵横比。
在 v1.14.11 中更改:添加了参数
keep_proportion,rotate。在 v1.14.13 中更改:
图像现在始终被放置在居中的位置,即图像和矩形的中心是相等的。
新增对
stream作为io.BytesIO的支持。
在 v1.17.6 中更改:插入矩形不再需要与页面的
Page.cropbox[5] 具有非空交集。在v1.18.1中更改:添加了
mask参数。在 v1.18.3 中更改:添加了
oc参数。在 v1.18.13 中更改:
在 v1.19.3 中更改:弃用并忽略
alpha参数。
- replace_image(xref, filename=None, pixmap=None, stream=None)#
用另一个图像替换xref中的图像。
参数
filename, Pixmap,stream的含义与Page.insert_image()中相同,尤其必须提供其中的一个。这是一种 全局替换: 新图像将在文件中显示旧图像的所有位置。
该方法主要出于技术目的。典型用途包括用更小的版本替换大图像,例如使用较低分辨率、灰度而不是彩色等,或更改透明度。
显示/隐藏历史
v1.21.0 中的新功能
- delete_image(xref)#
删除xref处的图像。这有点误导:实际上,图像被上面的
Page.replace_image()替换为一个小的透明Pixmap。然而,视觉效果是等效的。- Parameters:
xref (int) – 图像的
xref。
这是一个 全局替换: 图片将在文件中旧的展示位置消失。
如果你通过像
Page.get_images()、Page.get_image_info()或Page.get_text()这样的方式检查/提取页面的图片,替换的“虚拟”图片将被检测为如下(45, 47, 1, 1, 8, 'DeviceGray', '', 'Im1', 'FlateDecode'),并且似乎“覆盖”了页面上的相同边界框。显示/隐藏历史
v1.21.0 中的新功能
- get_text(option, *, clip=None, flags=None, textpage=None, sort=False, delimiters=None)#
检索页面的内容,支持多种格式。根据
flags的值,这可能包括文本、图像和其他几种对象类型。该方法是多个 TextPage 方法的封装,通过选择输出选项opt来实现,具体如下:“text” –
TextPage.extractTEXT(), 默认。始终只包括 文本。“blocks” –
TextPage.extractBLOCKS()。包括文本并可能包括图像元信息。“words” –
TextPage.extractWORDS(). 始终包含 仅文本。“html” –
TextPage.extractHTML(). 可能包含文本和图像。“xhtml” –
TextPage.extractXHTML(). 可能包括文本和图像。“xml” –
TextPage.extractXML(). 始终包含 仅文本。“dict” –
TextPage.extractDICT(). 可能包括文本和图像。“json” –
TextPage.extractJSON()。可能包含文本和图像。“rawdict” –
TextPage.extractRAWDICT()。可能包括文本和图像。“rawjson” –
TextPage.extractRAWJSON(). 可能包含文本和图片。
- Parameters:
opt (str) – 一个表示请求格式的字符串,上述格式之一。支持大小写混合。如果拼写错误,默认为“text”选项。
clip (矩形) – 将提取限制在此矩形内。如果
None(默认),则提取页面的可见部分。任何未完全包含在clip中的内容(文本、图像)将被完全省略。要完全避免裁剪,请使用clip=pymupdf.INFINITE_RECT()。只有这样,提取才会包含所有项目。此参数对“html”、“xhtml”和“xml”选项没有影响。flags (int) – 指示位,用于控制是否包含图像或文本应如何处理与空格和
ligatures相关的内容。有关可用指示符,请参阅 文本提取标志,有关默认设置,请参阅 文本提取标志默认值。 (v1.16.2 新增)textpage – 使用先前创建的 TextPage。这显著减少了执行时间非常显著:超过50%并且最高可达95%,具体取决于提取选项。如果指定,则忽略‘flags’和‘clip’参数,因为它们是textpage专有的属性。如果省略,将创建一个新的临时textpage。
sort (bool) – 通过纵向,然后横向坐标对输出进行排序。在许多情况下,这应该足以生成“自然”的阅读顺序。对 (X)HTML 和 XML 没有影响。对于选项“blocks”,“dict”,“json”,“rawdict”,“rawjson”,排序通过相应块的 bbox 的坐标
(y1, x0)进行。对于选项“words”和“text”,文本行被完全重新合成,以遵循文档中的阅读顺序和外观 – 这甚至在某种程度上建立了原始布局。分隔符 (字符串) – 使用这些字符作为 附加的 单词分隔符,与“单词”输出选项一起使用(否则将被忽略)。默认情况下,所有空格(包括不换行空格
0xA0)表示单词的开始和结束。现在您可以指定更多的字符。比如,默认会将"john.doe@outlook.com"作为 一个 单词返回。如果您指定delimiters="@.",则会返回 四个 单词"john","doe","outlook","com"。其他可能的用法包括忽略标点字符delimiters=string.punctuation。 “单词”字符串将不包含任何分隔字符。 (v1.23.5 新增)
- Return type:
字符串, 列表, 字典
- Returns:
页面的内容可以是字符串、列表或字典。有关详细信息,请参考相应的 TextPage 方法。
注意
您可以将此方法用作文档转换工具,将任何支持的文档类型转换为文本、HTML、XHTML或XML文档之一。
通过clip参数包含文本是按字符级别决定的:当一个字符的边界框包含在
clip中时,它就成为输出的一部分。这偏离了用于编辑注释的算法:如果一个字符的边界框与任何编辑注释相交,它将被移除。
显示/隐藏历史
在 v1.19.0 中更改:添加了 TextPage 参数
在 v1.19.1 版本中更改:添加了
sort参数在 v1.19.6 中更改:为每个方法定义默认标志添加了新的常量。
在v1.23.5中更改:添加了
delimiters参数在v1.24.11中更改:将
sort_True对“文本”和“单词”的效果更改为更 closely 跟随自然阅读顺序。
- get_textbox(rect, textpage=None)#
检索矩形中包含的文本。
- Parameters:
rect (矩形类) – 矩形类。
textpage – 一个 TextPage 供使用。如果省略,将创建一个新的临时文本页。
- Returns:
一个必要时带有换行符的字符串。它基于专用代码(在 v1.19.0 中更改)。一个典型的用法是检查
Page.search_for()的结果:>>> rl = page.search_for("currency:") >>> page.get_textbox(rl[0]) 'Currency:' >>>
显示/隐藏历史
v1.17.7中的新功能
在 v1.19.0 中更改:添加 TextPage 参数
- get_textpage(clip=None, flags=3)#
为页面创建一个 TextPage。
- Parameters:
flags (int) – 控制可用于后续文本提取和搜索的内容的指示位 – 请参见
Page.get_text()的参数。clip (矩形区域) – 将提取的文本限制在该区域内。(在 v1.17.7 中新增)
- Returns:
显示/隐藏历史
v1.16.5 中的新功能
在 v1.17.7 中更改:引入了
clip参数。
- get_textpage_ocr(flags=3, language='eng', dpi=72, full=False, tessdata=None)#
光学字符识别 (OCR) 技术可用于提取文档中以光栅图像格式呈现的文本数据。使用此方法对页面进行OCR以提取文本。
此方法返回一个 TextPage,该页面包含OCR文本。如果使用此方法,MuPDF将调用Tesseract-OCR。否则,这就是一个普通的 TextPage 对象。
- Parameters:
flags (int) – 指示位,控制可用于后续测试提取和搜索的内容 – 请参阅
Page.get_text()的参数。语言 (str) – 预期的语言。 如果预期有多种语言,请使用“+”分隔的值,例如“eng+spa”表示英语和西班牙语。
dpi (int) – 所需的分辨率,以每英寸的点数为单位。影响识别质量(和执行时间)。
full (bool) – 是否对整页进行OCR,或者只对显示的图像进行OCR。
tessdata (str) – Tesseract语言支持文件夹的名称
tessdata。如果省略,则此信息必须作为环境变量TESSDATA_PREFIX存在。可以通过函数get_tessdata()确定。
注意
此方法不支持剪辑参数 - OCR将始终针对整个页面矩形进行处理。
- Returns:
a TextPage。执行可能比
Page.get_textpage()要长得多。对于完整页面的OCR,所有文本 将使用 Tesseract 的“GlyphlessFont”字体。在部分OCR的情况下,普通文本将保持其属性,只有来自图像的文本将使用GlyphlessFont。
显示/隐藏历史
在 v.1.19.0 中的新功能
在 v1.19.1 中更改:支持对一个页面的完整和部分 OCR 处理。
- get_drawings(extended=False)#
返回页面的矢量图形。这些是绘制线条、矩形、四边形或曲线的指令,包括颜色、透明度、线宽和虚线等属性。替代术语是“线条艺术”和“绘图”。
- Returns:
一个字典的列表。每个字典项包含一个或多个共同的单描画命令:它们具有相同的属性(颜色、虚线等)。在PDF中,这被称为“路径”,所以我们在这里采用了这个名称,但该方法适用于所有文档类型。
用于填充、描边和填充-描边路径的路径字典已设计为与类 Shape 兼容。以下是主要键:
键
值
closePath
与Shape中的参数相同。
颜色
边框颜色(参见 形状)。
虚线
虚线规格(请参见 形状)。
even_odd
填充区域重叠的颜色 - 与Shape中的参数相同。
填充
填充颜色 (见 形状).
项目
绘制命令的列表:线条、矩形、四边形或曲线。
lineCap
数字3元组,使用其最大值输出,与 Shape 一起使用。
lineJoin
与Shape中的参数相同。
填充不透明度
填充颜色透明度(见 形状)。 (v1.18.17 新增)
stroke_opacity
边框颜色透明度(见 形状)。 (在 v1.18.17 中新增)
矩形
此路径覆盖的页面区域。仅供参考。
图层
适用的可选内容组名称。(在v1.22.0中新添加)
级别
如果
extended=True,则为层级级别。(新特性,v1.22.0)序号
构建页面外观时的命令号。(v1.19.0中新功能)
类型
此路径的类型。(v1.18.17 新增)
宽度
描边线宽度。 (见 形状).
关键
"opacity"已被新的键"fill_opacity"和"stroke_opacity"取代。这现在与Shape.finish()的相应参数兼容。 (在 v1.18.17 中更改)对于组或剪辑以外的路径,键
"type"采用以下值之一:“f” – 这是一条 仅填充 路径。只有与此操作相关的键值才有意义,不适用的键值的值为
None:"color","lineCap","lineJoin","width","closePath","dashes",应被忽略。“s” – 这是一个 仅限描边 路径。与之前类似,关键
"fill"具有值None。“fs” – 这是一个执行组合 填充 和 描边 操作的路径。
path["items"]中的每个项都是以下之一:("l", p1, p2)- 从 p1 到 p2 的一条线 (Point 对象).("c", p1, p2, p3, p4)- 立方 Bézier 曲线 从 p1 到 p4(p2 和 p3 是控制点)。所有对象都是类型 Point。("re", rect, orientation)- 一个 Rect。现在可以检测到同一路径内的多个矩形(在 v1.18.17 中更改)。整数orientation是 1 或 -1,表示封闭区域是向左旋转(1 = 逆时针)或向右 [7](在 v1.19.2 中更改)。("qu", quad)- 一个 Quad。检测到实际上代表一个 Quad 的3或4条连续行。(在v1.19.2中更改:)。(在v1.18.17中新增加)
使用类 Shape,您应该能够在一个单独的(PDF)页面上高保真地重现原始图纸,在正常的、不过于复杂的情况下。请参阅以下关于限制的说明。编码草稿可以在 如何提取图纸 中找到。
指定
extended=True会显著改变输出。最重要的是,出现了新的字典类型:“clip”和“group”。所有路径现在将组织在一个由新的整数键“level”编码的层次结构中,代表层级。每个组或剪辑会建立一个新的层级,这适用于所有后续路径具有 更大 level 值。(v1.22.0 新增)任何路径的级别值小于其前任的路径将结束(至少)先前层级的范围。与前一个剪辑具有相同级别的“剪辑”路径将结束该剪辑的范围。群组也是如此。这最好通过一个例子来解释:
+------+------+--------+------+--------+ | line | lvl0 | lvl1 | lvl2 | lvl3 | +------+------+--------+------+--------+ | 0 | clip | | | | | 1 | | fill | | | | 2 | | group | | | | 3 | | | clip | | | 4 | | | | stroke | | 5 | | | fill | | ends scope of clip in line 3 | 6 | | stroke | | | ends scope of group in line 2 | 7 | | clip | | | | 8 | fill | | | | ends scope of line 0 +------+------+--------+------+--------+
第0行的剪辑适用于包含第7行的行。第2行的组适用于第3到第5行,第3行的剪辑仅适用于第4行。
第4行中的“stroke”受第2行中的“group”和第3行中的“clip”的控制(而后者又是第0行clip的一个子集)。
“clip” 字典。它的值(最重要的是 “scissor”)保持有效/适用,只要后续字典具有更大的 “level” 值。
键
值
closePath
与“stroke”或“fill”字典中的相同
偶数_奇数
与“描边”或“填充”字典中的相同
项目
与“笔划”或“填充”字典中的相同
矩形
与“描边”或“填充”字典中的相同
图层
与“描边”或“填充”字典中的相同
级别
与“描边”或“填充”字典中的相同
剪刀
剪辑矩形
类型
“clip”
“group” 字典。只要后续字典具有更大的 “level” 值,其值保持有效(适用)。任何具有相等或更低级别的字典将结束此组。
键
值
矩形
与“描边”或“填充”字典中的相同
图层
与“描边”或“填充”字典中的相同
级别
与“笔画”或“填充”字典中的相同
孤立的
(bool) 这个组是否是孤立的
击倒
(bool) 是否是“击倒组”
混合模式
混合模式的名称,默认是“正常”
不透明度
范围[0, 1]内的浮点值。
类型
“group”
注意
该方法基于
Page.get_cdrawings()的输出——这要快得多,但处理它的输出需要更多的注意。显示/隐藏历史
v1.18.0 新功能
在 v1.18.17 中更改
在 v1.19.0 中更改:添加 “seqno” 键,移除 “clippings” 键
在 v1.19.1 中更改:“color” / “fill” 键现在始终是 RGB 元组或
None。这解决了由奇特颜色空间引起的问题。在 v1.19.2 中更改:为“re”项目覆盖的区域的 “方向” 添加指示器。
在 v1.22.0 中更改:添加新键
"layer",它包含路径的可选内容组的名称(或None)。在 v1.22.0 中更改:添加参数
extended以返回裁剪和组路径。
- get_cdrawings(extended=False)#
提取页面上的矢量图形。除了以下技术差异,功能上等同于
Page.get_drawings(),但速度快得多:每种路径类型只包含相关的键,例如,描边路径没有
"fill"颜色键。请参阅方法Page.get_drawings()中的注释。坐标以
point_like、rect_like和quad_like元组 的形式给出 - 而非以 Point、Rect、Quad 对象的形式。
如果性能是一个问题,请考虑使用此方法:与1.18.17之前的版本相比,您应该会看到更短的响应时间。我们看到需要2秒的页面,现在使用此方法仅需200毫秒。
显示/隐藏历史
v1.18.17 新特性
在 v1.19.0 中更改:移除了 “clippings” 键,添加了 “seqno” 键。
在 v1.19.1 中更改:始终生成 RGB 颜色元组。
在v1.22.0中更改:添加了新的键
"layer",该键包含路径的可选内容组的名称(或None)。在 v1.22.0 中更改:添加参数
extended以返回剪辑路径。
- get_fonts(full=False)#
仅限PDF:返回页面引用的字体列表。
Document.get_page_fonts()的包装。
- get_images(full=False)#
仅适用于PDF:返回页面引用的图像列表。
Document.get_page_images()的封装。
- get_image_info(hashes=False, xrefs=False)#
返回一个包含所有页面显示图像的元信息字典的列表。这适用于所有文档类型。
- Parameters:
hashes (bool) – 计算每个遇到的图像的 MD5 哈希码,这可以识别图像重复。 这将把键
"digest"添加到输出中,其值是一个 16 字节的bytes对象。 (v1.18.13 新增)xrefs (bool) – 仅适用于PDF。 尝试为每个图像找到
xref。意味着hashes=True。向字典添加"xref"键。如果未找到,则值为0,这意味着该图像是“内联”的或其xref因某种原因无法检测到。请注意,此选项的响应时间较长,因为MD5哈希码将为每个具有xref的图像计算至少两次。(新版本 v1.18.13)
- Return type:
列表[字典]
- Returns:
一个字典列表。这包括在页面上显示的正是那些图像的信息——包括“内嵌图像”。字典布局与
page.get_text("dict")中的图像块布局相似。与通过
Page.get_text()包含的图像不同,图像二进制内容不会通过此方法加载,这大幅减少了内存使用。另一个不同之处在于,图像检测不限制于页面的可见部分或任何clip参数:方法Page.get_text()只会提取完全包含在提供的clip中的图像。键
值
number
块编号 (
int)bbox
页面上的图像边界框,
rect_likewidth
原始图像宽度 (
int)height
原始图像高度 (
int)cs-name
颜色空间名称 (
str)colorspace
colorspace.n (
int)xres
x方向的分辨率 (
int)yres
y方向的分辨率 (
int)bpc
每个组件的位数 (
int)size
图像占用的存储空间 (
int)digest
MD5 哈希码 (
bytes),如果hashes为真xref
图像
xref或0,如果xrefs为真transform
将图像矩形转换为边界框的矩阵,
matrix_likehas-mask
图像是否透明并具有遮罩 (
bool)相同图像的多个出现总是会被报告。您可以通过比较它们的
digest值来检测重复项。
显示/隐藏历史
在 v1.18.11 中的新功能
在 v1.18.13 中更改:添加了图像 MD5 哈希计算和
xref搜索。
- get_xobjects()#
仅限PDF:返回页面引用的Form XObjects列表。封装了
Document.get_page_xobjects()。
- get_image_rects(item, transform=False)#
仅限PDF:返回嵌入图像的边界框和转换矩阵。这是
Page.get_image_bbox()的改进版本,具有以下不同之处:对图像的调用方式没有限制(通过页面或其 Form XObjects 之一)。结果总是完整和正确的。
结果是一个 Rect 或者 (Rect, Matrix) 对象的列表 – 取决于 transform。每个列表项代表页面上图像的一个位置。多个出现可能无法通过
Page.get_image_bbox()检测到。该方法调用
Page.get_image_info(),参数为xrefs=True,因此响应时间明显比Page.get_image_bbox()更长。
- Parameters:
项 (列表,字符串,整数) – 列表的一个项目
Page.get_images(),或者 such 项目的引用 名称 条目 (item[7]),或者图像xref。transform (bool) – 还会返回用于将图像矩形转换为页面上 bbox 的矩阵。如果为 true,则返回元组
(bbox, matrix)。
- Return type:
列表
- Returns:
每个图像在页面上的边界框和相应的变换矩阵。如果该项目不在页面上,则返回一个空列表
[]。
显示/隐藏历史
v1.18.13中的新功能
- get_image_bbox(item, transform=False)#
仅限PDF:返回嵌入图像的边界框和变换矩阵。
- Parameters:
item (list,str) – 列表
Page.get_images()中一个项,指定了full=True,或者该项的引用name条目,即item[-3](或item[7])。transform (bool) – 返回用于将图像矩形转换为页面上的 bbox 的矩阵(在 v1.18.11 中新增)。默认值只是 bbox。如果为真,则返回一个元组
(bbox, matrix)。
- Return type:
- Returns:
图像的边界框 - 可选的还包括它的变换矩阵。
显示/隐藏历史记录
(在 v1.16.7 中更改):如果页面实际上不显示此图像,现在返回一个无限的矩形。在早期版本中,会抛出异常。形式上无效的参数仍会引发异常。
(在 v1.17.0 中更改):仅考虑页面直接引用的图像。这意味着在嵌入的 PDF 页面中出现的图像被忽略,并且会抛出异常。
(在 v1.18.5 中更改):删除了在 v1.17.0 中引入的限制:可以指定页面图像列表中的任何项目。
(在 v1.18.11 中更改):部分恢复了一个限制:仅考虑那些被页面直接引用或被页面直接引用的表单 XObject 引用的图像。
(在 v1.18.11 中更改):可选的还可以将变换矩阵与 bbox 一起作为元组
(bbox, transform)返回。
注意
请注意,
Page.get_images()可能包含“无效”的条目,即页面不显示的图像。这不是错误,而是PDF创建者的意图。在这种情况下,不会引发异常,但会返回一个无限的矩形。您可以通过在此方法之前执行Page.clean_contents()来避免这种情况的发生。图像的“变换矩阵”被定义为矩阵,对于这个表达式
bbox / transform == pymupdf.Rect(0, 0, 1, 1)为真,在这里查找详细信息: 图像变换矩阵。
显示/隐藏历史
在 v1.18.11 中更改:返回图像转换矩阵
- get_svg_image(matrix=pymupdf.Identity, text_as_path=True)#
从页面创建一个SVG图像。目前只支持全页面图像。
- Parameters:
矩阵 (类似矩阵) – 一个矩阵,默认为 单位矩阵。
text_as_path (bool) – – 控制文本的表示方式。
True以一系列基本绘制命令输出每个字符,这会导致在浏览器中更精确的文本显示,但对于面向文本的页面,输出会 大得多。 对于False,显示质量依赖于当前系统中引用字体的存在。 对于缺失的字体,互联网浏览器将退回到某些默认值 – 导致外观不佳。 如果您想解析SVG的文本,请选择False。 (v1.17.5中的新功能)
- Returns:
一个包含图像的UTF-8编码字符串。由于SVG具有XML语法,因此可以保存在文本文件中,标准扩展名是
.svg.注意
在PDF的情况下,您可以通过在使用该方法之前修改页面的CropBox来绕过“仅全页面图像”限制。
- get_pixmap(*, matrix=pymupdf.Identity, dpi=None, colorspace=pymupdf.csRGB, clip=None, alpha=False, annots=True)#
从页面创建一个位图。这可能是创建一个 Pixmap 最常用的方法。
所有参数都是 仅限关键字。
- Parameters:
矩阵 (类矩阵) – 默认值为 单位阵.
dpi (int) – 所需的 x 和 y 方向的分辨率。如果不是
None,则忽略"matrix"参数。(在 v1.19.2 中新增)colorspace (str 或 Colorspace) – 所需的色彩空间,可以是“GRAY”、“RGB”或“CMYK”(不区分大小写)。或者指定一个 Colorspace,即,预定义的之一:
csGRAY、csRGB或csCMYK。clip (irect_like) – 限制渲染到该区域与页面矩形的交集。
alpha (bool) –
是否添加alpha通道。如果您不需要透明度,请始终使用默认值
False。这将节省大量内存(在RGB的情况下为25% … 并且位图通常是 大的!),还会节省处理时间。还要注意图像渲染方式的 重要区别:使用True时,位图的采样区域会预先清除为 0x00。这导致页面空白处出现 透明 区域。使用False时,位图的采样会预先清除为 0xff。这导致页面没有内容时显示 白色。显示/隐藏历史记录
- 在v1.14.17中更改
默认alpha值现在为
False。使用 alpha=True 生成

使用 alpha=False 生成
annots (bool) – (在版本 1.16.0 中新增) 是否也渲染注释或抑制它们。您可以单独为注释创建像素图。
- Return type:
- Returns:
页面的位图。为了精确控制生成的图像,最重要的参数是 matrix。例如,您可以通过使用 Matrix(xzoom, yzoom) 来增加或减少图像分辨率。如果 zoom > 1,您将获得更高的分辨率:zoom=2 将使该方向上的像素数量翻倍,从而生成一个大 2 倍的图像。非正值将水平或垂直翻转。同样,矩阵还可以让您旋转或剪切,您可以通过,例如矩阵乘法来组合效果。请参见 Matrix 部分以了解更多信息。
注意
如果
alpha=True,则位图将具有 “预乘” 像素。要了解一些背景,例如,可以在 这里 查找“预乘 alpha”。该方法将尊重任何页面旋转,并且不会超过
clip和Page.cropbox的交集。如果您需要页面的 mediabox(如果这是一个不同的矩形),可以使用以下代码段来实现:In [1]: import pymupdf In [2]: doc=pymupdf.open("demo1.pdf") In [3]: page=doc[0] In [4]: rotation = page.rotation In [5]: cropbox = page.cropbox In [6]: page.set_cropbox(page.mediabox) In [7]: page.set_rotation(0) In [8]: pix = page.get_pixmap() In [9]: page.set_cropbox(cropbox) In [10]: if rotation != 0: ...: page.set_rotation(rotation) ...: In [11]:
显示/隐藏历史
在 v1.19.2 中更改:添加了对参数 dpi 的支持。
- annot_names()#
仅限PDF:返回注释、小部件和链接名称的列表。 从技术上讲,这些是页面的/Annots数组中找到的每个PDF对象的/NM值。
- Return type:
列表
显示/隐藏历史
v1.16.10的新特性
- annot_xrefs()#
仅限PDF:返回一个包含注释、控件和链接的
xref编号的列表——技术上来说是页面的/Annots数组中找到的所有条目。- Return type:
列表
- Returns:
项目列表 (xref, type) 其中 type 是注释类型。使用该类型区分链接、字段和注释,请参见 注释类型。
显示/隐藏历史
v1.17.1中的新功能
- load_annot(ident)#
仅限PDF:返回由 ident 识别的注释。这可能是它的唯一名称(PDF
/NM键),或其xref。- Parameters:
ident (str,int) – 注释名称或xref。
- Return type:
- Returns:
注释或
None。
注意
方法
Page.annot_names()和Page.annot_xrefs()分别提供名称或交叉引用的列表,从中可以选择和加载项目。显示/隐藏历史
v1.17.1 中的新功能
- load_widget(xref)#
仅限PDF:返回由 xref 标识的字段。
- Parameters:
xref (int) – 字段的 xref。
- Return type:
- Returns:
字段或
None。
注意
这类似于相应的方法
Page.load_annot()– 只是这里仅支持 xref 作为标识符。显示/隐藏历史
v1.19.6中的新内容
- load_links()#
返回页面上的第一个链接。
first_link的同义词。- Return type:
- Returns:
页面上的第一个链接(或
None)。
- set_rotation(rotate)#
只有PDF:设置页面的旋转。
- Parameters:
rotate (int) – 一个指定所需旋转角度的整数。必须是90的整数倍。值将被转换为0、90、180、270之一。
- remove_rotation()#
仅限PDF:在保持外观和页面内容的同时,将页面旋转设置为0。
- Returns:
用于实现此更改的逆矩阵。如果页面没有旋转(旋转 0),则返回 单位矩阵。该方法会自动重新计算页面上任何注释、链接和小部件的矩形。
当与
Page.show_pdf_page()一起使用时,此方法可能会很有用。
- show_pdf_page(rect, docsrc, pno=0, keep_proportion=True, overlay=True, oc=0, rotate=0, clip=None)#
仅限PDF:将另一个PDF的页面显示为矢量图像(否则与
Page.insert_image()相似)。这是一个多用途的方法。例如,您可以使用它来:创建现有PDF文件的“n-up”版本,将多个输入页面合并为一个输出页面(见示例 combine.py),
创建“海报化”的PDF文件,即每个输入页面被拆分成多个部分,每个部分创建一个单独的输出页面(见 posterize.py),
包括基于PDF的矢量图像,如公司标志、水印等,见 svg-logo.py,它在每个页面上放置基于SVG的标志(需要额外的包来处理SVG到PDF的转换)。
- Parameters:
rect (rect_like) – 图像在当前页面中的放置位置。必须是有限的,并且与页面的交集不得为空。
docsrc (文档) – 包含页面的源 PDF 文档。必须是一个不同的文档对象,但可以是同一个文件。
pno (int) – 页面编号(从0开始,在
-∞ < pno < docsrc.page_count)中显示。keep_proportion (bool) – 是否保持宽高比(默认)。如果为假,则所有 4 个角始终定位在目标矩形的边界上——无论旋转值如何。一般来说,这将产生扭曲和/或不规则的图像。
overlay (bool) – 将图像放置在前景(默认)或背景中。
oc (int) – (
xref) 使可见性依赖于这个OCG/OCMD(必须在目标 PDF 中定义) [9]. (在 v1.18.3 中新增加)rotate (float) – 显示经某个角度旋转的源矩形。支持任何角度(在v1.14.11中更改)。 (在v1.14.10中新增)
clip (rect_like) – 选择要显示的源页面的哪一部分。默认是全页,否则必须是有限的,并且与源页面的交集不能为空。
注意
与方法
Document.insert_pdf()相比,此方法不会复制注释、控件或链接,因此这些不会包含在目标 [6] 中。但所有其他资源(文本、图像、字体等)将被导入到当前的PDF中。因此,它们将在文本提取和get_fonts()和get_images()列表中出现——即使它们不包含在 clip 给出的可见区域中。示例:显示相同的源页面,旋转90度和-90度:
>>> doc = pymupdf.open() # new empty PDF >>> page=doc.new_page() # new page in A4 format >>> >>> # upper half page >>> r1 = pymupdf.Rect(0, 0, page.rect.width, page.rect.height/2) >>> >>> # lower half page >>> r2 = r1 + (0, page.rect.height/2, 0, page.rect.height/2) >>> >>> src = pymupdf.open("PyMuPDF.pdf") # show page 0 of this >>> >>> page.show_pdf_page(r1, src, 0, rotate=90) >>> page.show_pdf_page(r2, src, 0, rotate=-90) >>> doc.save("show.pdf")
显示/隐藏历史
在 v1.14.11 中更改:参数 reuse_xref 已被弃用。将源矩形置于目标矩形的中心。现在支持任何旋转角度。
在 v1.18.3 中更改:新参数
oc。
- search_for(needle, *, clip=None, quads=False, flags=TEXT_DEHYPHENATE | TEXT_PRESERVE_WHITESPACE | TEXT_PRESERVE_LIGATURES | TEXT_MEDIABOX_CLIP, textpage=None)#
在页面上搜索 needle。
TextPage.search()的包装器。- Parameters:
needle (str) – 要搜索的文本。可以包含空格。忽略大小写,但仅适用于ASCII字符:例如,如果needle是“compétences”,则“COMPÉTENCES”将不会被找到 – 但是“compÉtences”会。德语的变音符号等情况也是如此。
clip (rect_like) – 仅在此区域内进行搜索。 (v1.18.2 中新增)
flags (int) – 控制由基础 TextPage 提取的数据。默认情况下,连字和空格被保留,并检测连字符 [8]。
textpage – 使用之前创建的 TextPage。这显著减少了执行时间 显著。 如果指定,则‘flags’和‘clip’参数将被忽略。如果省略,将创建一个临时文本页面。(v1.19.0 新增)
- Return type:
列表
- Returns:
一个 Rect 或 Quad 对象的列表,每个对象 - 通常! - 包围一个 needle 的实例。 然而: 如果 needle 的部分出现在多于一行上,则每个部分生成一个单独的项目。因此,如果
needle = "search string",可能会生成两个矩形。显示/隐藏历史记录
v1.18.2 的更改:
列表长度不再有限制(移除了
hit_max参数)。如果一个单词在换行时 连字符 分隔,它仍然会被找到。例如,needle “method” 即使以“meth-od” 形式连字符也会被找到,并且将返回两个矩形:一个包围“meth”(没有连字符),另一个包围“od”。
注意
该方法支持多行文本标记注释:您可以将返回的完整列表作为一个单一参数来创建注释。
注意
有一个棘手的方面:搜索逻辑将连续多个出现的needle视为一个:假设needle是“abc”,页面包含“abc”和“abcabc”,那么只会返回两个矩形,一个用于“abc”,另一个用于“abcabc”。
您可以随时使用
Page.get_textbox()来检查每个矩形周围实际包含的文本。
注意
一个反复被要求的功能是支持 正则表达式 当指定
"needle"字符串时: 没有办法做到这一点。 如果你需要朝这个方向发展,首先提取所需格式的文本,然后通过与某些正则表达式模式匹配来选择结果。以下是匹配单词的示例:>>> pattern = re.compile(r"...") # the regex pattern >>> words = page.get_text("words") # extract words on page >>> matches = [w for w in words if pattern.search(w[4])]
matches列表将包含与给定模式匹配的单词。同样,您可以从page.get_text("dict")的输出中选择span["text"]。显示/隐藏历史
在v1.18.2中更改:添加了
clip参数。移除hit_max参数。添加默认值“dehyphenate”。在v1.19.0中更改: 添加了 TextPage 参数。
- set_mediabox(r)#
仅限PDF:通过在页面的对象定义中设置
mediabox来更改物理页面尺寸。- Parameters:
r (矩形状) – 新的
mediabox值。
注意
此方法还移除了页面的其他(可选)矩形(
cropbox、ArtBox、TrimBox 和 Bleedbox),以防止不一致的情况。这将导致这些矩形采用它们的默认值。注意
对于非空页面,这可能会产生不希望的效果,因为所有内容的位置取决于这个值,因此会改变位置甚至消失。
显示/隐藏历史
v1.16.13中的新功能
在 v1.19.4 中更改:删除所有其他矩形定义。
- set_cropbox(r)#
仅限PDF:更改页面的可见部分。
- Parameters:
r (rect_like) – 页面的新可见区域。注意,这必须以未旋转坐标指定,不能为空,也不能是无限的,并且必须完全包含在
Page.mediabox中。
执行后 (如果页面没有旋转),
Page.rect将等于这个矩形,但如果有必要,将移动到左上角位置 (0, 0)。示例会话:>>> page = doc.new_page() >>> page.rect pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> page.cropbox # cropbox and mediabox still equal pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> # now set cropbox to a part of the page >>> page.set_cropbox(pymupdf.Rect(100, 100, 400, 400)) >>> # this will also change the "rect" property: >>> page.rect pymupdf.Rect(0.0, 0.0, 300.0, 300.0) >>> >>> # but mediabox remains unaffected >>> page.mediabox pymupdf.Rect(0.0, 0.0, 595.0, 842.0) >>> >>> # revert CropBox change >>> # either set it to MediaBox >>> page.set_cropbox(page.mediabox) >>> # or 'refresh' MediaBox: will remove all other rectangles >>> page.set_mediabox(page.mediabox)
- set_artbox(r)#
- set_bleedbox(r)#
- set_trimbox(r)#
仅限PDF:在页面对象中设置相应的矩形。有关这些对象的含义,请参阅 Adobe PDF References,第77页。参数和限制与
Page.set_cropbox()相同。显示/隐藏历史
v1.19.4的新特性
- rotation#
包含页面的旋转角度(对非PDF类型始终为0)。这是PDF文件中值的副本。PDF文档中说:
“页面在显示或打印时应顺时针旋转的度数。该值必须是90的倍数。默认值:0。”
在PyMuPDF中,我们确保这个属性始终是0、90、180或270之一。
- Type:
整型
- cropbox#
页面的
/CropBox用于PDF。始终返回 未旋转 的页面矩形。对于非PDF,这始终等于页面矩形。注意
在PDF中,
/MediaBox、/CropBox和页面矩形之间的关系有时可能令人困惑,请查阅MediaBox的术语表。- Type:
- artbox#
- bleedbox#
- trimbox#
页面的
/ArtBox,/BleedBox,/TrimBox,如果未提供,则默认为Page.cropbox。- Type:
- mediabox_size#
包含页面的
Page.mediabox的宽度和高度,适用于 PDF,否则是Page.rect的右下角坐标。- Type:
- mediabox#
该页面的
mediabox用于 PDF,否则使用Page.rect。- Type:
注意
对于大多数PDF文档和所有其他文档类型,
page.rect == page.cropbox == page.mediabox为真。然而,对于某些PDF,可见页面是真正的mediabox的一个子集。此外,如果页面被旋转,其Page.rect可能不等于Page.cropbox。在这些情况下,上述属性有助于正确定位页面元素。
- transformation_matrix#
该矩阵将坐标从PDF空间转换到MuPDF空间。例如,在PDF
/Rect [x0 y0 x1 y1]中,(x0, y0) 指定了矩形的 左下 角点 – 与MuPDF的系统相反,在MuPDF中,(x0, y0) 指定左上角。将PDF坐标与该矩阵相乘将得到(Python) MuPDF矩形版本。显然,逆矩阵将再次得到PDF矩形。- Type:
- rotation_matrix#
- derotation_matrix#
这些矩阵可以用于处理旋转的PDF页面。当向PDF页面添加/插入任何内容时,总是使用未旋转页面的坐标。这些矩阵有助于在两种状态之间进行转换。示例:如果一个页面旋转了90度,那么A4页面的左上角点(0, 0)的坐标将是什么?
>>> page.set_rotation(90) # rotate an ISO A4 page >>> page.rect Rect(0.0, 0.0, 842.0, 595.0) >>> p = pymupdf.Point(0, 0) # where did top-left point land? >>> p * page.rotation_matrix Point(842.0, 0.0) >>>
- Type:
- number#
页码。
- Type:
整型
- rect#
包含页面的矩形。与
Page.bound()的结果相同。- Type:
get_links()条目的描述#
Page.get_links()列表的每个条目都是一个字典,具有以下键:
kind: (必需) 一个整数,指示链接的种类。这是 LINK_NONE、LINK_GOTO、LINK_GOTOR、LINK_LAUNCH 或 LINK_URI 之一。有关这些名称的值和含义,请参考 链接目的地种类。
来自: (必需)一个 矩形 描述页面可见表示中的“热点”位置(光标通常会变成手形图像)。
page: 一个以0为基准的整数,表示目标页面。对于 LINK_GOTO 和 LINK_GOTOR 是必需的,否则被忽略。
到: 可以是一个 pymupdf.Point,指定所提供页面上的目标位置,默认值是 pymupdf.Point(0, 0),或者是一个符号(间接)名称。如果指定了间接名称,则需要 page = -1,并且该名称必须在PDF中定义以便正常工作。LINK_GOTO 和 LINK_GOTOR 需要此项,否则被忽略。
file: 一个指定目标文件的字符串。对于 LINK_GOTOR 和 LINK_LAUNCH 是必需的,否则被忽略。
uri: 一个指定目标互联网资源的字符串。对于 LINK_URI 是必需的,否则被忽略。你应该确保以一个明确的子字符串开始这个字符串,用于分类URL的子类型,例如
"http://","https://","file://","ftp://","mailto:"等等。否则你的浏览器可能会试图解释文本并得出关于预期URL类型的不希望的/意外的结论。xref: 一个整数,指定链接对象的PDF
xref。请勿以任何方式更改此条目。删除和更新链接时是必需的,否则被忽略。对于非PDF文档,此条目包含 -1。如果任何链接不被MuPDF支持,则在get_links()列表中的所有条目也为-1 - 请参见 支持链接的说明。
关于支持链接的说明#
MuPDF对链接的支持在v1.10a中发生了变化。这些变化影响链接类型 LINK_GOTO 和 LINK_GOTOR。
阅读(与方法 get_links() 和 first_link 属性链相关)#
如果 MuPDF 检测到一个指向另一个文件的链接,它将提供一个 LINK_GOTOR 或 LINK_LAUNCH 链接类型。在 LINK_GOTOR 的情况下,目标详细信息可以作为页码(最终可能包括位置信息)提供,或者作为间接目标。
如果给定了间接目的地,则通过page = -1来表示,link.dest.dest将包含此名称。get_links()列表中的字典将包含此信息作为to值。
内部链接总是属于 LINK_GOTO 类型。如果内部链接指定了间接目标,它 将始终被解析,并将返回结果直接目标。内部链接的名称 永远不会被返回,未定义的目标将导致链接被忽略。
写作#
PyMuPDF 通过构建并写入适当的 PDF 对象 source 来写入(更新、插入)链接。这使得可以为 LINK_GOTOR 和 LINK_GOTO 链接类型指定间接目标(PDF 1.2 之前的文件格式 不支持)。
警告
如果一个 LINK_GOTO 间接目标指定了一个未定义的名称,则此链接在以后的时间里无法通过 MuPDF / PyMuPDF 找到 / 再次读取。然而,其他阅读器 将 检测到它,但会将其标记为错误。
间接 LINK_GOTOR 目标一般情况下无法检查其有效性,因此 始终被接受。
示例:如何在同一文档中插入指向另一个页面的链接
确定当前页面上的矩形,链接应放置在其中。这可能是图像的边框或某些文本。
确定目标页码(“pno”,基于0)及其上的点,链接应指向该处。
创建一个字典
d = {"kind": pymupdf.LINK_GOTO, "page": pno, "from": bbox, "to": point}.执行
page.insert_link(d)。
文档和页面的同源方法#
文档级别 |
页面级别 |
|---|---|
Document.get_page_fonts(pno) |
|
Document.get_page_images(pno) |
|
文档.get_page_pixmap(pno, …) |
|
Document.get_page_text(pno, …) |
|
Document.search_page_for(pno, …) |
页面编号“pno”是一个从0开始的整数 -∞ < pno < page_count.
注意
大多数文档方法(左列)是出于便利原因存在的,仅仅是: Document[pno].
然而,前两种方法的工作方式不同。它们只需要页面的对象定义语句 - 页面本身不会被加载。因此,例如 Page.get_fonts() 是反向封装,定义如下:page.get_fonts == page.parent.get_page_fonts(page.number)。
脚注