图像#
如何从文档页面制作图像#
这个小脚本将获取一个文档文件名,并从它的每一页生成一个PNG文件。
文档可以是任何 支持的类型。
该脚本作为一个命令行工具,期望提供文件名作为参数。生成的图像文件(每页1个)存储在脚本的目录中:
import sys, pymupdf # import the bindings
fname = sys.argv[1] # get filename from command line
doc = pymupdf.open(fname) # open document
for page in doc: # iterate through the pages
pix = page.get_pixmap() # render page to an image
pix.save("page-%i.png" % page.number) # store image as a PNG
脚本目录现在将包含名为 page-0.png、page-1.png 等的 PNG 图像文件。图片的尺寸与其页面相同,宽度和高度四舍五入为整数,例如 A4 纵向页面的尺寸为 595 x 842 像素。它们在 x 和 y 方向上的分辨率为 96 dpi,并且没有透明度。您可以更改所有这些 - 有关如何执行此操作,请阅读接下来的部分。
如何提高 图像分辨率#
文档页面的图像由一个 Pixmap 表示,创建 pixmap 的最简单方法是通过方法 Page.get_pixmap()。
此方法有许多选项可以影响结果。其中最重要的是矩阵,它可以让你放大、旋转、扭曲或镜像结果。
Page.get_pixmap() 默认将使用 Identity 矩阵,该矩阵什么也不做。
在以下内容中,我们对每个维度应用一个的缩放因子为2,这将为我们生成一幅四倍于原始分辨率的图像(大小也大约是原来的4倍):
zoom_x = 2.0 # horizontal zoom
zoom_y = 2.0 # vertical zoom
mat = pymupdf.Matrix(zoom_x, zoom_y) # zoom factor 2 in each dimension
pix = page.get_pixmap(matrix=mat) # use 'mat' instead of the identity matrix
从版本 1.19.2 起,有一种更直接的方式来设置分辨率:参数 "dpi"(每英寸点数)可以替代 "matrix"。要创建一个 300 dpi 的页面图像,请指定 pix = page.get_pixmap(dpi=300)。除了符号简洁性,这种方法还有一个额外的优点,即 dpi 值与图像 文件一起保存——当使用矩阵表示法时,系统不会自动进行此操作。
如何创建局部位图(剪辑)#
您并不总是需要或想要页面的完整图像。这种情况例如在您在GUI中显示图像并希望将相应的窗口填充为页面的放大部分时。
假设您的GUI窗口有足够的空间显示完整的文档页面,但您现在想要用页面的右下四分之一填充这个空间,从而使用四倍更好的分辨率。
为了实现这一点,定义一个矩形,使其等于您希望在GUI中显示的区域,并将其称为“clip”。在PyMuPDF中构造矩形的一种方法是提供两个对角的角,这正是我们在这里所做的。
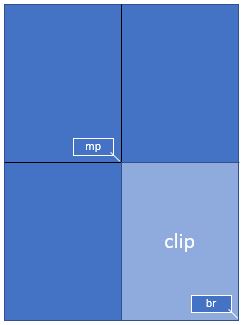
mat = pymupdf.Matrix(2, 2) # zoom factor 2 in each direction
rect = page.rect # the page rectangle
mp = (rect.tl + rect.br) / 2 # its middle point, becomes top-left of clip
clip = pymupdf.Rect(mp, rect.br) # the area we want
pix = page.get_pixmap(matrix=mat, clip=clip)
在上面,我们通过指定两个对角的点来构造 clip:页面矩形的中点 mp 和它的右下角 rect.br。
如何将剪辑缩放到GUI窗口#
请您也阅读上一节。这次我们想要计算缩放因子以便剪辑,使其图像最佳适应给定的GUI窗口。这意味着,图像的宽度或高度(或两者)将等于窗口尺寸。对于以下代码片段,您需要提供您GUI窗口的WIDTH和HEIGHT,该窗口应该接收页面的剪辑矩形。
# WIDTH: width of the GUI window
# HEIGHT: height of the GUI window
# clip: a subrectangle of the document page
# compare width/height ratios of image and window
if clip.width / clip.height < WIDTH / HEIGHT:
# clip is narrower: zoom to window HEIGHT
zoom = HEIGHT / clip.height
else: # clip is broader: zoom to window WIDTH
zoom = WIDTH / clip.width
mat = pymupdf.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat, clip=clip)
对于反向情况,现在假设你 拥有 缩放因子并且需要 计算合适的剪辑。
在这种情况下,我们有 zoom = HEIGHT/clip.height = WIDTH/clip.width,所以我们必须设置 clip.height = HEIGHT/zoom 和 clip.width = WIDTH/zoom。选择页面上 tl 的剪裁的左上点来计算正确的位图:
width = WIDTH / zoom
height = HEIGHT / zoom
clip = pymupdf.Rect(tl, tl.x + width, tl.y + height)
# ensure we still are inside the page
clip &= page.rect
mat = pymupdf.Matrix(zoom, zoom)
pix = pymupdf.Pixmap(matrix=mat, clip=clip)
如何创建或抑制注释图像#
通常,页面的位图还会显示页面的注释。有时候,这可能并不是所希望的。
要在渲染的页面上抑制注释图片,只需在 Page.get_pixmap() 中指定 annots=False。
您还可以单独渲染注释:它们有自己的 Annot.get_pixmap() 方法。生成的位图具有与注释矩形相同的尺寸。
如何提取图像:非PDF文档#
与前面的部分相比,本节讨论的是提取文档中包含的图像,以便将它们显示为一个或多个页面的一部分。
如果您想以文件形式或作为内存区域重新创建原始图像,您基本上有两个选择:
将您的文档转换为PDF,然后使用其中一种仅限PDF的提取方法。此代码片段将文档转换为PDF:
>>> pdfbytes = doc.convert_to_pdf() # this a bytes object >>> pdf = pymupdf.open("pdf", pdfbytes) # open it as a PDF document >>> # now use 'pdf' like any PDF document
使用
Page.get_text()结合 “dict” 参数。这适用于所有文档类型。它将提取页面上显示的所有文本和图像,格式化为一个Python字典。每个图像都将在一个图像块中出现,包含元信息和 二进制图像数据。有关字典结构的详细信息,请参见 TextPage。该方法同样适用于PDF文件。这将创建一个页面上所有图像的列表:>>> d = page.get_text("dict") >>> blocks = d["blocks"] # the list of block dictionaries >>> imgblocks = [b for b in blocks if b["type"] == 1] >>> pprint(imgblocks[0]) {'bbox': (100.0, 135.8769989013672, 300.0, 364.1230163574219), 'bpc': 8, 'colorspace': 3, 'ext': 'jpeg', 'height': 501, 'image': b'\xff\xd8\xff\xe0\x00\x10JFIF\...', # CAUTION: LARGE! 'size': 80518, 'transform': (200.0, 0.0, -0.0, 228.2460174560547, 100.0, 135.8769989013672), 'type': 1, 'width': 439, 'xres': 96, 'yres': 96}
如何提取图像:PDF文档#
像PDF中的任何其他“对象”一样,图像都通过交叉引用编号 (xref, 一个整数) 进行识别。如果你知道这个编号,你可以通过两种方式访问图像的数据:
创建一个Pixmap,其图像的指令为pix = pymupdf.Pixmap(doc, xref)。这个方法非常快(个位数微秒)。pixmap的属性(宽度,高度,…)将反映图像的属性。在这种情况下,没有办法判断嵌入的原始图像具有哪种格式。
提取 图像,使用 img = doc.extract_image(xref)。这是一个包含二进制图像数据的字典,作为 img[“image”]。还提供了多种元数据——大部分与您在图像的像素映像中找到的相同。主要区别在于字符串 img[“ext”],指定了图像格式:除了“png”,还可能出现“jpeg”、“bmp”、“tiff”等字符串。如果您想将其存储到磁盘,请使用此字符串作为文件扩展名。此方法的执行速度应与语句 pix = pymupdf.Pixmap(doc, xref);pix.tobytes() 的组合速度进行比较。如果嵌入的图像为PNG格式,
Document.extract_image()的速度大致相同(而且二进制图像数据是相同的)。否则,此方法 快千倍,且 图像数据更小。
问题仍然是: “我怎么知道那些图像的‘xref’编号?”。对此有两个答案:
“检查页面对象:” 遍历
Page.get_images()的项目。它是一个列表的列表,其项目看起来像 [xref, smask, …],包含一个图像的xref。这个xref可以与上述方法之一一起使用。对有效(未损坏)的文档使用此方法。然而要注意,同一图像可能被多次引用(由不同页面),因此您可能想要提供一种机制来避免多次提取。“不需要知道:” 遍历文档的所有交叉引用列表,并对每一个执行
Document.extract_image()。如果返回的字典为空,则继续 – 这个xref不是图像。如果PDF损坏(无法使用的页面),请使用此方法。请注意,PDF通常包含“伪图像”(“模板蒙版”),其特殊目的是定义其他图像的透明度。您可能希望提供逻辑以将其排除在提取之外。还请查看下一部分。
对于这两种提取方法,存在现成可用的通用脚本:
extract-from-pages.py 按页面提取图像:

并且 extract-from-xref.py 通过 xref 表提取图像:
如何处理图像蒙版#
在PDF中的某些图像伴随着图像蒙版。在最简单的形式中,蒙版表示作为单独图像存储的alpha(透明度)字节。为了重建具有蒙版的图像的原始状态,它必须与来自其蒙版的透明度字节进行“增强”。
在PyMuPDF中,图像是否具有这样的遮罩可以通过两种方式识别:
一个
Document.get_page_images()的项目具有一般格式(xref, smask, ...),其中 xref 是图像的xref,如果 smask 为正,则它是一个遮罩的xref。(字典)
Document.extract_image()的结果有一个键“smask”,如果存在,则还包含任何掩码的xref。
如果 smask == 0 那么通过 xref 遇到的图像可以直接处理。
要使用PyMuPDF恢复原始图像,必须执行如下所示的步骤:

>>> pix1 = pymupdf.Pixmap(doc.extract_image(xref)["image"]) # (1) pixmap of image w/o alpha
>>> mask = pymupdf.Pixmap(doc.extract_image(smask)["image"]) # (2) mask pixmap
>>> pix = pymupdf.Pixmap(pix1, mask) # (3) copy of pix1, image mask added
步骤 (1) 创建基本图像的位图。步骤 (2) 对图像蒙版执行相同操作。步骤 (3) 添加 alpha 通道并用透明度信息填充。
上述脚本 extract-from-pages.py 和 extract-from-xref.py 也包含了这个逻辑。
如何将所有图片(或文件)制作成一个PDF#
我们在这里展示三个脚本,它们将一系列(图像和其他)文件放入一个PDF中。
方法 1:将图像插入为页面
第一个将每个图像转换为具有相同尺寸的PDF页面。结果将是一个每个图像对应一页的PDF。它仅适用于 支持的图像 文件格式:
import os, pymupdf
import PySimpleGUI as psg # for showing a progress bar
doc = pymupdf.open() # PDF with the pictures
imgdir = "D:/2012_10_05" # where the pics are
imglist = os.listdir(imgdir) # list of them
imgcount = len(imglist) # pic count
for i, f in enumerate(imglist):
img = pymupdf.open(os.path.join(imgdir, f)) # open pic as document
rect = img[0].rect # pic dimension
pdfbytes = img.convert_to_pdf() # make a PDF stream
img.close() # no longer needed
imgPDF = pymupdf.open("pdf", pdfbytes) # open stream as PDF
page = doc.new_page(width = rect.width, # new page with ...
height = rect.height) # pic dimension
page.show_pdf_page(rect, imgPDF, 0) # image fills the page
psg.EasyProgressMeter("Import Images", # show our progress
i+1, imgcount)
doc.save("all-my-pics.pdf")
这将生成一个仅比合并的图片大小略大的PDF。关于性能的一些数字:
上述脚本在我的机器上处理149张图片,总大小为514MB(生成的PDF大小大致相同),大约需要1分钟。

请在这里查找更完整的源代码:它提供了一个目录选择对话框,并跳过不支持的文件和非文件条目。
注意
我们可能使用了 Page.insert_image() 而不是 Page.show_pdf_page(),结果会是一个相似的文件。然而,根据图像类型,它可能会存储 未压缩的图像。因此,保存选项 deflate = True 必须使用以实现合理的文件大小,这会大幅增加处理大量图像时的运行时间。所以这种替代方案 在这里不推荐。
方法 2:嵌入文件
第二个脚本嵌入任意文件——不仅仅是图像。生成的PDF将只有一页(空白),这是出于技术原因所需。要想再次访问嵌入的文件,您需要一个适合的PDF查看器,可以显示和/或提取嵌入的文件:
import os, pymupdf
import PySimpleGUI as psg # for showing progress bar
doc = pymupdf.open() # PDF with the pictures
imgdir = "D:/2012_10_05" # where my files are
imglist = os.listdir(imgdir) # list of pictures
imgcount = len(imglist) # pic count
imglist.sort() # nicely sort them
for i, f in enumerate(imglist):
img = open(os.path.join(imgdir,f), "rb").read() # make pic stream
doc.embfile_add(img, f, filename=f, # and embed it
ufilename=f, desc=f)
psg.EasyProgressMeter("Embedding Files", # show our progress
i+1, imgcount)
page = doc.new_page() # at least 1 page is needed
doc.save("all-my-pics-embedded.pdf")
这无疑是最快的方法,它还生成了尽可能小的输出文件大小。上述图片在我的机器上需要 20 秒,并且生成了 510 MB 的 PDF 文件大小。查看 这里 以获取更完整的源代码:它提供了目录选择对话框并跳过非文件条目。
方法 3:附加文件
实现此任务的第三种方法是通过页面注释附加文件,完整的源代码请参见这里。
这与之前的脚本具有类似的性能,并且生成的文件大小也类似。它将生成PDF页面,其中为每个附加文件显示一个“文件附件”图标。
注意
这两种方法,embed 和 attach 可以用于 任意文件 – 不仅仅是图像。
注意
我们强烈推荐使用这个非常棒的包 PySimpleGUI 来显示任务的进度条,这些任务可能会运行较长时间。它是纯Python,使用Tkinter(不需要额外的GUI包),只需多一行代码!
如何创建矢量图像#
从文档页面创建图像的常用方法是 Page.get_pixmap()。Pixmap 表示一个栅格图像,因此您必须在创建时决定其质量(即分辨率)。之后无法更改。
PyMuPDF 还提供了一种以 SVG 格式(可缩放矢量图形,采用 XML 语法定义)创建页面的 矢量图像 的方法。SVG 图像在缩放级别之间保持精确(当然,对其中嵌入的任何光栅图形元素的情况除外)。
说明 svg = page.get_svg_image(matrix=pymupdf.Identity) 生成一个UTF-8字符串 svg ,可以以扩展名“.svg”存储。
如何转换图像#
作为众多功能之一,PyMuPDF的图像转换非常简单。在许多情况下,它可能避免使用其他图形包,如PIL/Pillow。
尽管与Pillow的接口几乎是微不足道的。
输入格式 |
输出格式 |
描述 |
|---|---|---|
位图 |
. |
Windows 位图 |
JPEG |
JPEG |
联合图像专家组 |
JXR |
. |
JPEG扩展范围 |
JPX/JP2 |
. |
JPEG 2000 |
GIF |
. |
图形交换格式 |
TIFF |
. |
标记图像文件格式 |
PNG |
PNG |
可移植网络图形 |
PNM |
PNM |
可移植任意映像 |
PGM |
PGM |
可移植灰度图 |
PBM |
PBM |
可移植位图 |
PPM |
PPM |
可移植像素图 |
PAM |
PAM |
可携带任意地图 |
. |
PSD |
Adobe Photoshop 文档 |
. |
PS |
Adobe Postscript |
一般方案仅如下两行:
Nonepix = pymupdf.Pixmap("input.xxx") # any supported input format
pix.save("output.yyy") # any supported output format
备注
input 参数的 pymupdf.Pixmap(arg) 可以是一个文件或包含图像的字节 / io.BytesIO 对象。
除了输出 文件 外,您还可以通过 pix.tobytes(“yyy”) 创建一个字节对象并传递它。
作为一种常规,输入和输出格式在颜色空间和透明度方面必须兼容。如果需要进行调整,Pixmap 类已经包含了必要的功能。
注意
将JPEG转换为Photoshop:
pix = pymupdf.Pixmap("myfamily.jpg")
pix.save("myfamily.psd")
注意
将 JPEG 转换为 Tkinter PhotoImage。任何 RGB / 无 alpha 图像都可以完全相同地工作。转换为其中一种 可移植任意映像 格式 (PPM, PGM 等) 可以解决问题,因为所有 Tkinter 版本都支持它们:
import tkinter as tk
pix = pymupdf.Pixmap("input.jpg") # or any RGB / no-alpha image
tkimg = tk.PhotoImage(data=pix.tobytes("ppm"))
注意
将 带有透明通道的PNG 转换为 Tkinter PhotoImage。这需要在进行 PPM 转换之前 去除透明通道字节:
import tkinter as tk
pix = pymupdf.Pixmap("input.png") # may have an alpha channel
if pix.alpha: # we have an alpha channel!
pix = pymupdf.Pixmap(pix, 0) # remove it
tkimg = tk.PhotoImage(data=pix.tobytes("ppm"))
如何使用位图:粘贴图像#
这显示了如何将位图用于纯图形、非文档目的。该脚本读取一个图像文件并创建一个由原始图像的3 * 4块组成的新图像:
import pymupdf
src = pymupdf.Pixmap("img-7edges.png") # create pixmap from a picture
col = 3 # tiles per row
lin = 4 # tiles per column
tar_w = src.width * col # width of target
tar_h = src.height * lin # height of target
# create target pixmap
tar_pix = pymupdf.Pixmap(src.colorspace, (0, 0, tar_w, tar_h), src.alpha)
# now fill target with the tiles
for i in range(col):
for j in range(lin):
src.set_origin(src.width * i, src.height * j)
tar_pix.copy(src, src.irect) # copy input to new loc
tar_pix.save("tar.png")
这是输入图片:

这里是输出:

如何使用位图:创建分形#
这里是另一个Pixmap示例,它创建了谢尔宾斯基地毯 - 一个将康托集推广到二维的分形。给定一个方形地毯,标记其9个子方块(3乘3),并切去中间的一个。以相同的方式处理剩下的八个子方块,并继续无穷大。最终结果是一个面积为零且分形维度为1.8928…的集合。
该脚本通过将精度降至一个像素的粒度,创建其近似图像为PNG格式。要提高图像精度,请更改n(精度)的值:
import pymupdf, time
if not list(map(int, pymupdf.VersionBind.split("."))) >= [1, 14, 8]:
raise SystemExit("need PyMuPDF v1.14.8 for this script")
n = 6 # depth (precision)
d = 3**n # edge length
t0 = time.perf_counter()
ir = (0, 0, d, d) # the pixmap rectangle
pm = pymupdf.Pixmap(pymupdf.csRGB, ir, False)
pm.set_rect(pm.irect, (255,255,0)) # fill it with some background color
color = (0, 0, 255) # color to fill the punch holes
# alternatively, define a 'fill' pixmap for the punch holes
# this could be anything, e.g. some photo image ...
fill = pymupdf.Pixmap(pymupdf.csRGB, ir, False) # same size as 'pm'
fill.set_rect(fill.irect, (0, 255, 255)) # put some color in
def punch(x, y, step):
"""Recursively "punch a hole" in the central square of a pixmap.
Arguments are top-left coords and the step width.
Some alternative punching methods are commented out.
"""
s = step // 3 # the new step
# iterate through the 9 sub-squares
# the central one will be filled with the color
for i in range(3):
for j in range(3):
if i != j or i != 1: # this is not the central cube
if s >= 3: # recursing needed?
punch(x+i*s, y+j*s, s) # recurse
else: # punching alternatives are:
pm.set_rect((x+s, y+s, x+2*s, y+2*s), color) # fill with a color
#pm.copy(fill, (x+s, y+s, x+2*s, y+2*s)) # copy from fill
#pm.invert_irect((x+s, y+s, x+2*s, y+2*s)) # invert colors
return
#==============================================================================
# main program
#==============================================================================
# now start punching holes into the pixmap
punch(0, 0, d)
t1 = time.perf_counter()
pm.save("sierpinski-punch.png")
t2 = time.perf_counter()
print ("%g sec to create / fill the pixmap" % round(t1-t0,3))
print ("%g sec to save the image" % round(t2-t1,3))
结果应该看起来像这样:

如何与NumPy接口#
这显示了如何从numpy数组创建PNG文件(比其他大多数方法快几倍):
import numpy as np
import pymupdf
#==============================================================================
# create a fun-colored width * height PNG with pymupdf and numpy
#==============================================================================
height = 150
width = 100
bild = np.ndarray((height, width, 3), dtype=np.uint8)
for i in range(height):
for j in range(width):
# one pixel (some fun coloring)
bild[i, j] = [(i+j)%256, i%256, j%256]
samples = bytearray(bild.tostring()) # get plain pixel data from numpy array
pix = pymupdf.Pixmap(pymupdf.csRGB, width, height, samples, alpha=False)
pix.save("test.png")
如何在PDF页面中添加图像#
将图像添加到PDF页面有两种方法: Page.insert_image() 和 Page.show_pdf_page()。这两种方法有相似之处,但也存在差异。
标准 |
||
|---|---|---|
可显示内容 |
图像文件,内存中的图像,像素图 |
PDF页面 |
显示分辨率 |
图像分辨率 |
矢量化(除了栅格页面内容) |
旋转 |
0、90、180 或 270 度 |
任何角度 |
裁剪 |
否(仅全图) |
是 |
保持纵横比 |
是(默认选项) |
是(默认选项) |
透明度(水印) |
取决于图像 |
取决于页面 |
位置 / 放置 |
缩放以适应目标矩形 |
缩放以适应目标矩形 |
性能 |
自动防止重复; |
自动防止重复; |
多页图像支持 |
不 |
是 |
易用性 |
简单、直观; |
简单、直观;
转换为PDF后,可以用于所有文档类型
(包括图像!)通过 |
基本代码模式为 Page.insert_image()。必须提供确切的一个参数 filename / stream / pixmap,如果不是重新插入已存在的图像:
page.insert_image(
rect, # where to place the image (rect-like)
filename=None, # image in a file
stream=None, # image in memory (bytes)
pixmap=None, # image from pixmap
mask=None, # specify alpha channel separately
rotate=0, # rotate (int, multiple of 90)
xref=0, # re-use existing image
oc=0, # control visibility via OCG / OCMD
keep_proportion=True, # keep aspect ratio
overlay=True, # put in foreground
)
基本代码模式为 Page.show_pdf_page()。源PDF和目标PDF必须是不同的 Document 对象(但可以从同一个文件中打开):
page.show_pdf_page(
rect, # where to place the image (rect-like)
src, # source PDF
pno=0, # page number in source PDF
clip=None, # only display this area (rect-like)
rotate=0, # rotate (float, any value)
oc=0, # control visibility via OCG / OCMD
keep_proportion=True, # keep aspect ratio
overlay=True, # put in foreground
)
如何使用位图:检查文本可见性#
None一段给定文本是否在页面上实际可见取决于多个因素:
None文本没有被其他对象覆盖,但可能与背景颜色相同,即白底白字等。
文本可能会被图像或矢量图形覆盖。检测这一点是一个重要的能力,例如用来揭示错误匿名化的法律文件。
文本是以隐藏形式创建的。这种技术通常被OCR工具用来将识别的文本存储在页面的一个隐形层中。
以下内容展示了如何检测情况 1. 上述情况,或情况 2. 如果覆盖物体是单色的:
pix = page.get_pixmap(dpi=150) # make page image with a decent resolution
# the following matrix transforms page to pixmap coordinates
mat = page.rect.torect(pix.irect)
# search for some string "needle"
rlist = page.search_for("needle")
# check the visibility for each hit rectangle
for rect in rlist:
if pix.color_topusage(clip=rect * mat)[0] > 0.95:
print("'needle' is invisible here:", rect)
方法 Pixmap.color_topusage() 返回一个元组 (ratio, pixel) 其中 0 < ratio <= 1 且 pixel 是颜色的像素值。请注意,我们只创建一次pixmap。如果有多个命中矩形,这可以节省大量处理时间。
上述代码的逻辑是:如果针的矩形是(“几乎”:> 95%)单色,则文本将不可见。可见文本的典型结果返回背景的颜色(主要是白色)和大约0.7到0.8的比率,例如 (0.685, b'xffxffxff')。