QlibRL框架
QlibRL 包含了一整套组件,涵盖了强化学习管道的整个生命周期,包括构建市场模拟器、塑造状态和动作、训练策略(策略),以及在模拟环境中回测策略。
QlibRL 基本上是在 Tianshou 和 Gym 框架的支持下实现的。QlibRL 的高级结构如下所示:
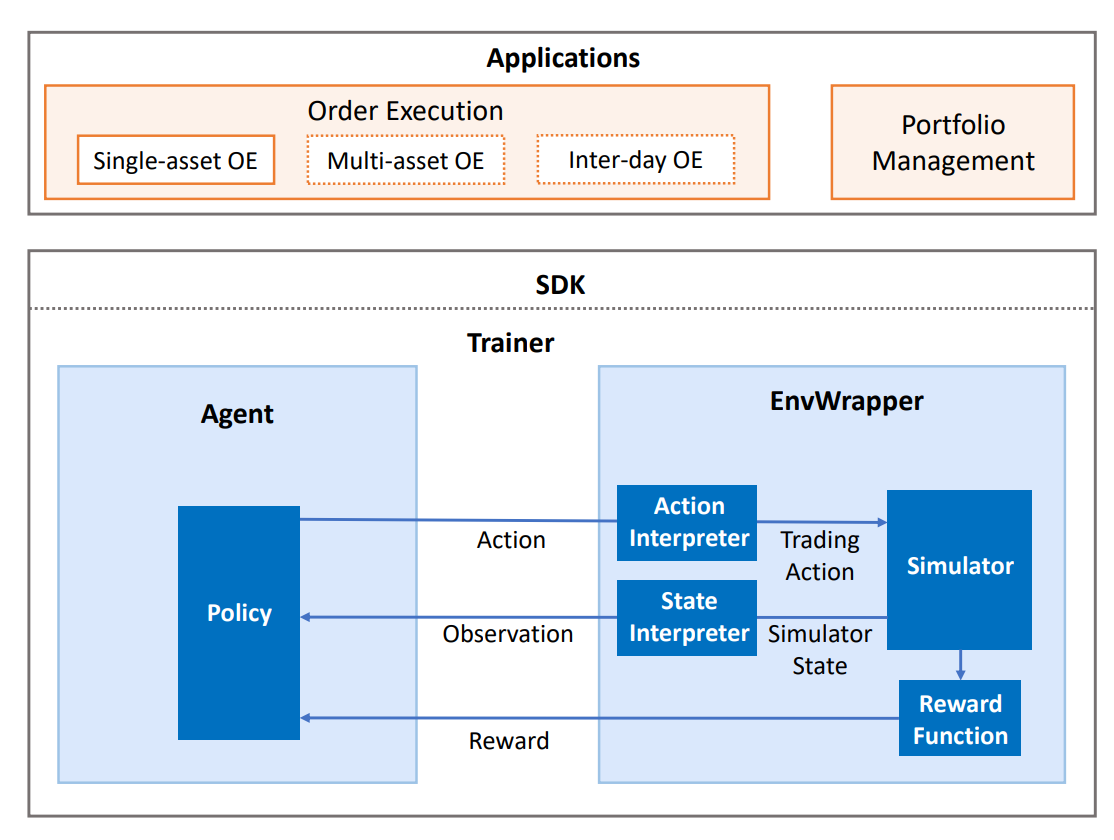
在这里,我们简要介绍图中的每个组件。
环境包装器
EnvWrapper 是模拟环境的完整封装。它接收来自外部(策略/策略/代理)的动作,模拟市场的变化,然后回复奖励和更新状态,从而形成一个交互循环。
在QlibRL中,EnvWrapper是gym.Env的一个子类,因此它实现了gym.Env的所有必要接口。任何接受gym.Env的类或管道也应该接受EnvWrapper。开发者不需要实现自己的EnvWrapper来构建自己的环境。相反,他们只需要实现EnvWrapper的4个组件:
- Simulator
模拟器是负责环境模拟的核心组件。开发者可以以任何他们喜欢的方式在模拟器中实现所有与环境模拟直接相关的逻辑。在QlibRL中,已经有两种用于单一资产交易的模拟器实现:1)
SingleAssetOrderExecution,它是基于Qlib的回测工具包构建的,因此考虑了许多实际的交易细节,但速度较慢。2)SimpleSingleAssetOrderExecution,它是基于简化的交易模拟器构建的,忽略了许多细节(例如交易限制、四舍五入),但速度非常快。
- State interpreter
状态解释器负责将原始格式(由模拟器提供的格式)中的状态“解释”为策略可以理解的格式。例如,将非结构化的原始特征转换为数值张量。
- Action interpreter
动作解释器与状态解释器类似。但它不是解释状态,而是解释由策略生成的动作,从策略提供的格式转换为模拟器可接受的格式。
- Reward function
奖励函数在策略每次采取行动后返回一个数值奖励给策略。
EnvWrapper 将有机地组织这些组件。这种分解允许在开发中具有更好的灵活性。例如,如果开发者希望在同一环境中训练多种类型的策略,他们只需要设计一个模拟器,并为不同类型的策略设计不同的状态解释器/动作解释器/奖励函数。
QlibRL 为所有这4个组件定义了良好的基类。所有开发者需要做的就是通过继承基类来定义自己的组件,然后实现基类所需的所有接口。上述基组件的API可以在这里找到。
策略
QlibRL 直接使用 Tianshou 的策略。开发者可以使用 Tianshou 提供的现成策略,或者通过继承 Tianshou 的策略来实现自己的策略。
训练船与训练师
正如它们的名称所示,训练容器和训练器是用于训练的辅助类。训练容器是一个包含模拟器/解释器/奖励函数/策略的船,它控制着训练中与算法相关的部分。相应地,训练器负责控制训练的运行时部分。
正如你可能已经注意到的,训练容器本身包含了构建EnvWrapper所需的所有组件,而不是直接持有EnvWrapper的实例。这使得训练容器能够在必要时动态创建EnvWrapper的副本(例如,在并行训练的情况下)。
有了训练容器,训练者最终可以通过简单的、类似于Scikit-learn的接口(即trainer.fit())启动训练管道。
Trainer 和 TrainingVessel 的 API 可以在 这里 找到。
RL模块以松耦合的方式设计。目前,RL示例与具体的业务逻辑集成在一起。 但RL的核心部分比您看到的要简单得多。 为了展示RL的简单核心,创建了一个专门的笔记本,用于没有业务损失的RL。