
自v0.8版本起,RAGFlow正式进入代理时代,后端提供全面的基于图的任务编排框架,前端提供无代码工作流编辑器。为什么是代理?此功能与现有工作流编排系统有何不同?
为了解决这些问题,我们首先必须研究RAG和Agent之间的关系。没有RAG,LLMs只能通过长上下文有限地访问私有数据,这使得使用代理为企业场景服务变得困难。客户服务、营销推荐、合规检查和库存优化需要的不仅仅是长上下文的LLM和工作流组装。一个简单的RAG系统,以单轮对话为例,是支持工作流中代理编排的关键操作者。相反,RAG是一种架构模式,使LLMs能够访问私有企业数据。因此,一个高级的RAG系统应该提供更多功能。当用户查询有明确意图时,它应该能够处理多跳问答,这需要跨文档推理和查询分解;对于模糊的查询意图,它应该能够与代理一起工作,采用动态代理编排来“批评”/评估检索,相应地重写查询,并为这些复杂的问答任务进行“多跳”推理。本质上,代理和RAG是互补的技术,各自在企业应用中增强了对方的能力。
RAGFlow在开源发布不到三个月内就获得了10,000个GitHub星标。现在是时候反思RAGFlow的成功并展望其未来的革命了。

上述图示展示了RAG的典型工作流程。这种基于语义相似性的方法已经保持多年的一致性,可以分为四个阶段:文档分块、索引、检索和生成。这个过程实现起来相当直接,但搜索结果往往不尽如人意,因为这种基于语义相似性的简单搜索系统有几个局限性:
- 作为一个块级操作,嵌入过程使得难以区分需要增加权重的标记,例如实体、关系或事件。这导致生成的嵌入中有效信息的密度较低,召回率较差。
- 嵌入对于精确检索是不够的。例如,用户询问其公司2024年3月财务计划中的投资组合时,可能会收到来自不同时间段的投资组合、同一时间段的市场或运营计划,甚至其他类型的数据。
- 其检索结果高度依赖于所选的嵌入模型;通用模型在特定领域可能表现不佳。
- 其检索结果对数据分块方法敏感。然而,这个基于LLMOps的系统在文档分块方面天生简单且粗糙,导致数据语义和结构的丢失。
- 缺乏用户意图识别,仅改进相似性搜索方法无法有效增强对模糊用户查询的答案。
- 无法处理复杂查询,例如多跳问答,这需要从异构信息源进行多步推理。
因此,这个以LLMOps为中心的系统可以被视为RAG 1.0。它具有编排和生态系统的特点,但在有效性方面有所不足。尽管开发者可以快速使用RAG 1.0构建原型系统,但在实际企业环境中解决问题时,他们常常发现自己陷入困境。因此,RAG必须继续与LLMs一起发展,以促进各种专业领域的搜索。基于这些考虑,我们为RAG 2.0提出了以下关键特性和组件:

- RAG 2.0 是一个端到端的搜索系统,分为以下几个阶段:信息提取、文档预处理、索引和检索。
- RAG 2.0 无法通过重用为 RAG 1.0 设计的 LLMOps 工具来进行编排,因为这些阶段是耦合的,缺乏统一的 API 和数据格式,并且存在循环依赖。例如,查询重写对于多跳问答和用户意图识别至关重要,涉及迭代检索和重写。
- 需要一个更全面和强大的数据库来支持混合搜索,以解决RAG 1.0中的低召回率问题。除了向量搜索,它还应包括全文搜索和稀疏向量搜索。它甚至应该实现张量搜索,支持像ColBERT这样的后期交互机制。
- 数据库仅涵盖RAG 2.0中的查询和检索。从全局角度来看,优化RAG管道的每个阶段至关重要。这包括:
- 需要一个单独的数据提取和清理模块来分块用户数据。依靠一系列识别模型,它识别各种复杂的文档结构,包括表格和带有插图的文本,并根据检索到的搜索结果迭代调整其分块大小。
- 在发送到数据库进行索引之前,提取的数据可能会经过几个预处理程序,包括知识图谱构建、文档聚类和特定领域的嵌入。这些程序通过多种方式预处理提取的数据,确保检索结果包含必要的答案。这对于解决复杂查询问题如多跳问答、模糊用户意图和特定领域查询至关重要。
- 检索阶段涉及粗排名和精排名。精排名通常发生在数据库外部,因为它需要不同的重新排名模型。此外,用户查询将根据AI模型识别的用户意图进行持续的改写循环。这个过程会持续进行,直到检索到的答案令用户满意。
一般来说,RAG 2.0中的每个阶段基本上都是围绕AI模型构建的。它们与数据库协同工作,以确保最终答案的有效性。
当前的开源版本RAGFlow主要解决了管道的第一阶段问题,使用深度文档理解模型来确保数据的“质量输入,质量输出”。此外,它在索引的第三阶段采用了双向检索(双检索),结合了关键词全文搜索和向量搜索。这些特性使其与其他RAG产品区分开来,表明RAGFlow已经踏上了通往RAG 2.0的道路。
RAGFlow v0.8 实现了代理以更好地支持 RAG 2.0 管道的后续阶段。例如,为了改进对话中模糊查询的处理,RAGFlow 引入了类似 Self-RAG 的机制来评分检索结果并重写用户查询。此机制需要使用代理来实现一个反思性的代理 RAG 系统,该系统作为一个循环图而不是传统的工作流(DAG:有向无环图)运行。请参见下图:

这个循环图编排系统为代理引入了反射机制。反射使代理能够探索用户意图,动态适应上下文,引导对话,并最终提供高质量的响应。反射能力为代理智能奠定了基础。
Agentic RAG和工作流的引入自然促进了RAG 2.0与企业检索场景的集成。为了支持这一点,RAGFlow提供了一种无代码工作流编辑方法,适用于Agentic RAG和工作流业务系统。下面的截图展示了RAGFlow无代码工作流编排系统中目前可用的几个内置模板,供用户开始使用,包括客户服务和人力资源呼叫助手模板。此模板列表正在不断扩大,以覆盖更多场景。

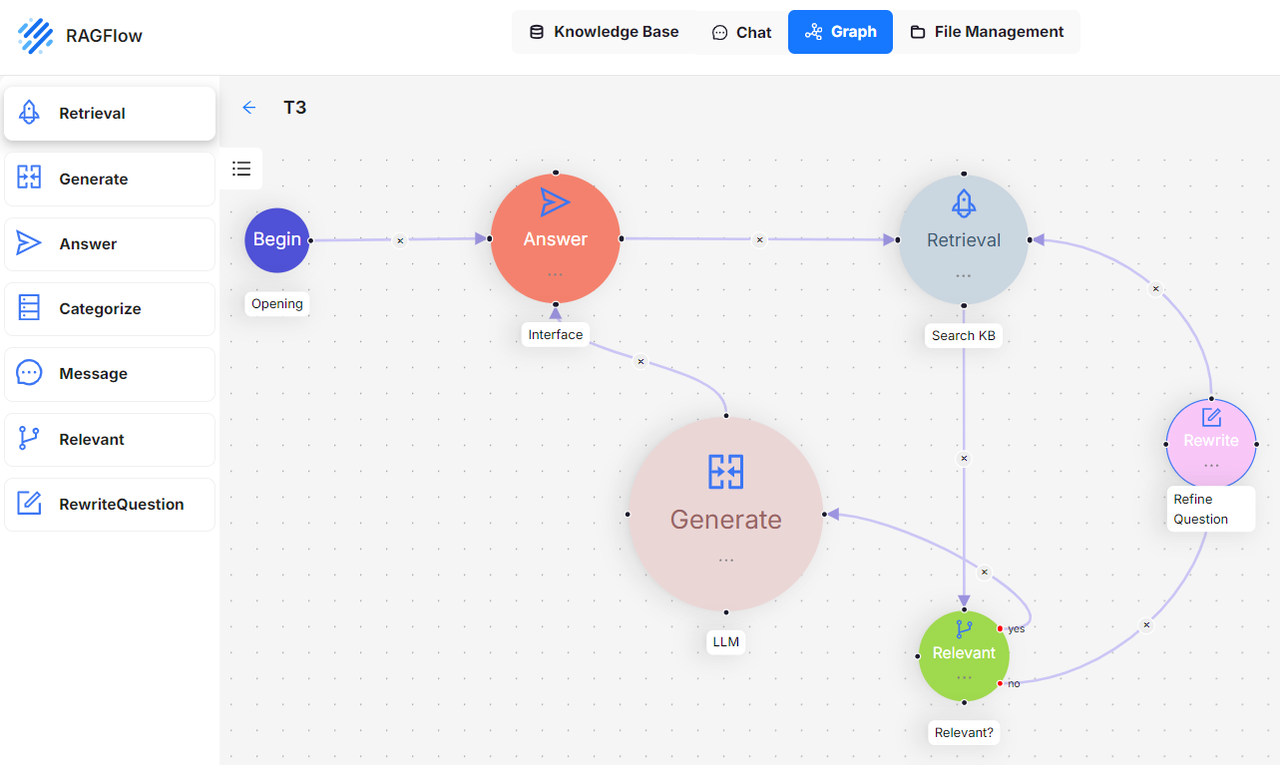
下面的截图展示了一个Self-RAG工作流程的示例。一个'Relevant'操作符评估检索结果是否与用户查询相关。如果被认为不相关,查询将被重写。这个过程会重复,直到'Relevant'操作符确定结果令人满意。
下图展示了一个HR候选人管理系统,展示了一个多轮对话场景的示例。紧接着这个无代码编排模板,提供了一个相应的示例对话。


以下是可以无代码编排的工作流操作符。分界线以上是与RAG和对话密切相关的功能操作符,这些操作符使RAGFlow与其他RAG系统区别开来。分界线以下是一些工具。许多现有的工作流代理系统已经整合了许多这样的工具。RAGFlow仍处于早期阶段,将会添加更多此类工具。

现在,让我们来解决最初的问题:RAGFlow的无代码编排与市场上类似的RAG项目有何不同。首先,RAGFlow以RAG为中心,而不是以LLM为中心,因此强调RAG如何在企业级场景中支持特定领域的业务。其次,它解决了RAG 2.0的核心需求,同时编排了与搜索相关的技术,如查询意图识别、查询重写和数据预处理,以提供更精确的对话,同时也适应了以工作流编排为特征的业务系统。

RAGFlow 的未来愿景是成为一个 Agentic RAG 2.0 平台,我们的最终目标是让 RAG 在企业场景中“流动”。如果您有相同的愿景,请在 GitHub 上关注并给我们的项目点赞。