托管作业#
提示
此功能非常适合扩展:长时间运行单个作业,或并行运行多个作业。
SkyPilot 支持 托管作业 (sky jobs),这些作业可以从任何底层抢占或硬件故障中自动恢复。
托管作业可以在三种模式下使用:
Managed spot jobs: 作业在自动恢复的spot实例上运行。通过使可抢占的spot实例适用于长时间运行的作业,这显著节省了成本(例如,GPU虚拟机节省约70%)。
Managed on-demand/reserved jobs: 作业在自动恢复的按需或预留实例上运行。适用于需要保证资源的作业。
托管管道: 运行包含多个任务的管道(这些任务可以有不同的资源需求和
setup/run命令)。适用于运行一系列相互依赖的任务,例如数据处理、训练模型,然后在其上运行推理。
托管Spot作业#
在这种模式下,作业在竞价实例上运行,抢占由SkyPilot自动恢复。
要启动一个托管竞价作业,请使用 sky jobs launch --use-spot。
SkyPilot 会自动在各个区域和云中找到可用的竞价实例,以最大化可用性。
任何竞价中断都会由 SkyPilot 自动处理,无需用户干预。
这里是一个BERT训练任务在AWS和GCP不同区域失败的示例。

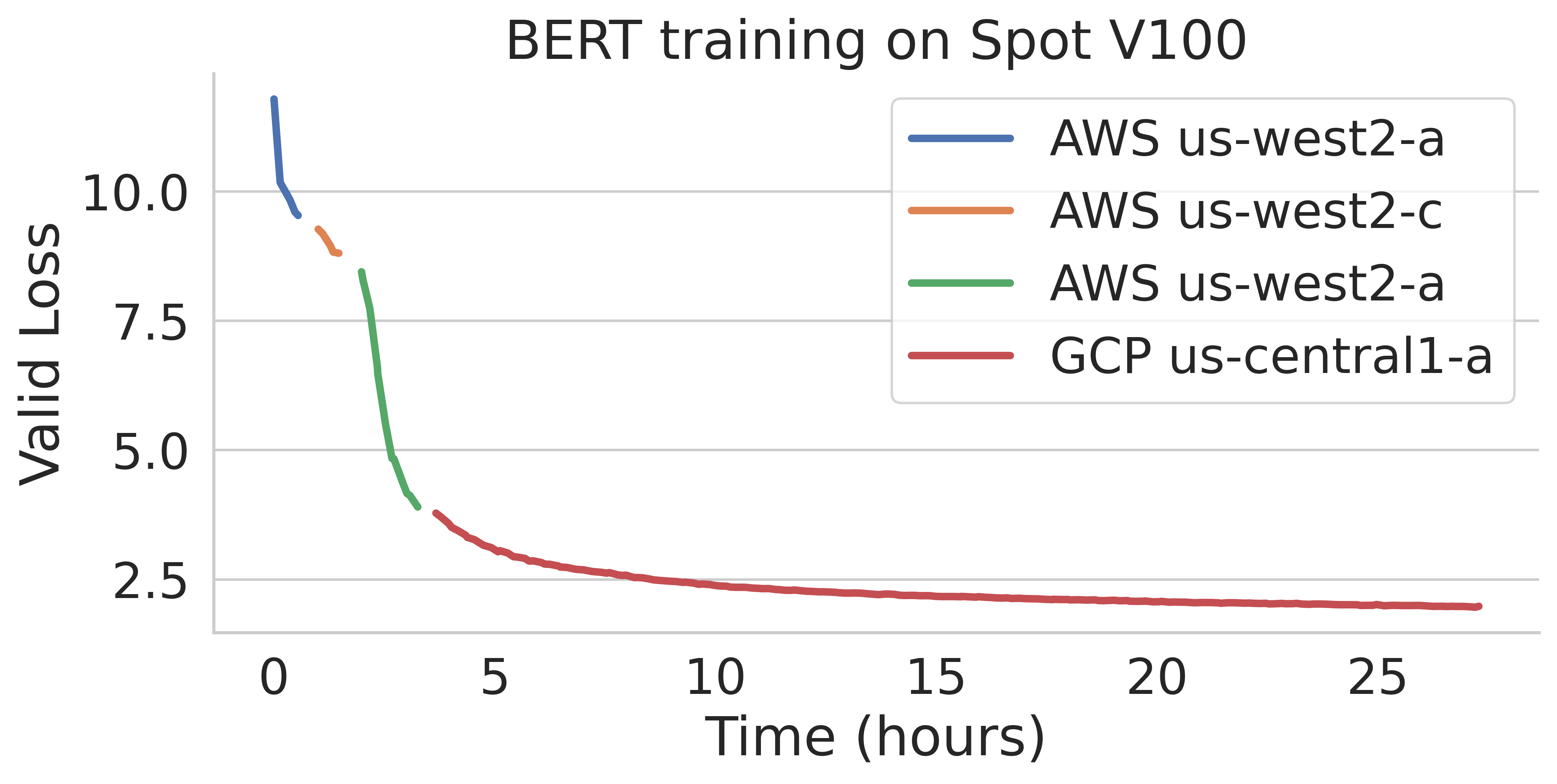
要使用托管点作业,有两个要求:
Job YAML: 托管Spot需要一个YAML来描述任务,已通过
sky launch进行测试。Checkpointing(可选):由于抢占导致的作业恢复,用户应用程序代码可以定期将其进度检查点到挂载的云存储桶。程序在重新启动时可以重新加载最新的检查点。
托管点作业与启动点集群之间的快速比较:
命令 |
托管? |
是否支持SSH? |
最适合 |
|---|---|---|---|
|
是的,抢占是自动恢复的 |
否 |
扩展长时间运行的作业(例如,数据处理、训练、批量推理) |
|
不,抢占不被处理 |
是 |
在现货实例上进行交互式开发(特别是对于抢占率较低的硬件) |
任务 YAML#
要启动一个托管作业,您可以简单地重用您的作业YAML(建议先使用sky launch进行测试)。
例如,我们发现BERT微调YAML与sky launch兼容,并希望使用SkyPilot托管Spot作业启动它。
我们可以使用以下方式启动它:
$ git clone https://github.com/huggingface/transformers.git ~/transformers -b v4.30.1
$ sky jobs launch -n bert-qa bert_qa.yaml
# bert_qa.yaml
name: bert-qa
resources:
accelerators: V100:1
use_spot: true # Use spot instances to save cost.
envs:
# Fill in your wandb key: copy from https://wandb.ai/authorize
# Alternatively, you can use `--env WANDB_API_KEY=$WANDB_API_KEY`
# to pass the key in the command line, during `sky jobs launch`.
WANDB_API_KEY:
# Assume your working directory is under `~/transformers`.
workdir: ~/transformers
setup: |
pip install -e .
cd examples/pytorch/question-answering/
pip install -r requirements.txt torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
pip install wandb
run: |
cd examples/pytorch/question-answering/
python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 50 \
--max_seq_length 384 \
--doc_stride 128 \
--report_to wandb \
--output_dir /tmp/bert_qa/
注意
workdir 和 带有本地文件的文件挂载 将自动上传到 云存储桶。存储桶将在作业运行期间创建,并在作业完成后清理。
SkyPilot 将启动并开始监控任务。当发生抢占或任何机器故障时,SkyPilot 将自动跨区域和云搜索资源以重新启动任务。
在这个例子中,作业将在每次抢占恢复后从头开始重新启动。 要从之前的状态恢复作业,用户的应用程序需要实现检查点和恢复。
检查点与恢复#
为了实现作业恢复,通常需要一个云存储桶来存储作业的状态(例如,模型检查点)。
下面是一个将存储桶挂载到/checkpoint的示例。
file_mounts:
/checkpoint:
name: # NOTE: Fill in your bucket name
mode: MOUNT
SkyPilot bucket mounting 中的 MOUNT 模式确保输出到 /checkpoint 的检查点会自动同步到持久存储桶中。
请注意,应用程序代码应定期保存程序检查点,并在作业重新启动时重新加载这些状态。
这通常通过在程序开始时重新加载最新的检查点来实现。
端到端示例#
下面我们展示了一个示例,用于在HuggingFace上进行问答任务的BERT模型微调。
# bert_qa.yaml
name: bert-qa
resources:
accelerators: V100:1
use_spot: true # Use spot instances to save cost.
file_mounts:
/checkpoint:
name: # NOTE: Fill in your bucket name
mode: MOUNT
envs:
# Fill in your wandb key: copy from https://wandb.ai/authorize
# Alternatively, you can use `--env WANDB_API_KEY=$WANDB_API_KEY`
# to pass the key in the command line, during `sky jobs launch`.
WANDB_API_KEY:
# Assume your working directory is under `~/transformers`.
workdir: ~/transformers
setup: |
pip install -e .
cd examples/pytorch/question-answering/
pip install -r requirements.txt torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
pip install wandb
run: |
cd examples/pytorch/question-answering/
python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 50 \
--max_seq_length 384 \
--doc_stride 128 \
--report_to wandb \
--output_dir /checkpoint/bert_qa/ \
--run_name $SKYPILOT_TASK_ID \
--save_total_limit 10 \
--save_steps 1000
由于HuggingFace内置了定期检查点的支持,我们只需要传递高亮的参数来设置输出目录和检查点的频率(更多信息请参见Huggingface API)。 你也可以参考另一个示例这里,了解如何使用PyTorch进行定期检查点。
我们还设置了--run_name为$SKYPILOT_TASK_ID,以便同一作业的所有恢复日志都将保存到Weights & Biases中的同一运行中。
注意
环境变量 $SKYPILOT_TASK_ID(例如:“sky-managed-2022-10-06-05-17-09-750781_bert-qa_8-0”)可用于识别相同的作业,即在所有作业恢复中保持不变。
它可以在任务的 run 命令中访问,或直接在程序本身中访问(例如,通过 os.environ 访问并传递给 Weights & Biases 以在训练脚本中进行跟踪)。每当任务被调用时,它都会提供给任务。
通过高亮显示的更改,托管spot作业现在可以在抢占后恢复训练!我们可以享受spot实例带来的成本节省优势,而无需担心抢占或失去进度。
$ sky jobs launch -n bert-qa bert_qa.yaml
提示
尝试复制粘贴此示例并适应您自己的工作。
实际案例#
托管按需/预留作业#
相同的 sky jobs launch 和 YAML 接口可以在自动恢复的按需或预留实例上运行作业。这对于让 SkyPilot 监控任何底层机器故障并透明地恢复作业非常有用。
为此,只需在resources部分中设置use_spot: false,或在CLI中使用--use-spot false覆盖它。
$ sky jobs launch -n bert-qa bert_qa.yaml --use-spot false
提示
将sky jobs launch视为“无服务器”托管作业接口是有用的,而sky launch是一个集群接口(你可以在其上启动任务,尽管不是托管的)。
无论是现货还是按需/预留#
你可以使用 any_of 来指定 spot 或 on-demand/reserved 实例作为作业的候选资源。更多详情请参阅文档 这里。
resources:
accelerators: A100:8
any_of:
- use_spot: true
- use_spot: false
在这个例子中,SkyPilot将执行成本优化以选择要使用的资源,几乎可以肯定的是,这将选择spot实例。如果spot实例不可用,SkyPilot将回退到启动按需/预留实例。
作业在用户代码失败时重启#
默认情况下,当底层集群被抢占或失败时,SkyPilot 会尝试恢复作业。任何用户代码失败(非零退出代码)都不会自动恢复。
在某些情况下,您可能希望作业在自身失败时自动重启,例如,当训练作业由于Nvidia驱动程序问题或NCCL超时而崩溃时。要指定这一点,您可以在作业YAML文件中的resources.job_recovery中设置max_restarts_on_errors。
resources:
accelerators: A100:8
job_recovery:
# Restart the job up to 3 times on user code errors.
max_restarts_on_errors: 3
更高级的资源选择策略,例如Can’t Be Late (NSDI’24)论文,未来可能会得到支持。
运行多个并行作业#
对于诸如数据处理或超参数扫描等批处理作业,您可以并行启动多个作业。请参阅许多并行作业。
有用的CLI#
这里是一些用于管理作业的命令。查看 sky jobs --help 和 CLI reference 以获取更多详细信息。
查看所有托管作业:
$ sky jobs queue
Fetching managed job statuses...
Managed jobs:
ID NAME RESOURCES SUBMITTED TOT. DURATION JOB DURATION #RECOVERIES STATUS
2 roberta 1x [A100:8][Spot] 2 hrs ago 2h 47m 18s 2h 36m 18s 0 RUNNING
1 bert-qa 1x [V100:1][Spot] 4 hrs ago 4h 24m 26s 4h 17m 54s 0 RUNNING
流式传输正在运行的托管作业的日志:
$ sky jobs logs -n bert-qa # by name
$ sky jobs logs 2 # by job ID
取消一个托管作业:
$ sky jobs cancel -n bert-qa # by name
$ sky jobs cancel 2 # by job ID
注意
如果托管作业发生任何故障,您可以检查sky jobs queue -a以获取故障的简要原因。要获取更多详细信息,检查sky jobs logs --controller 将会很有帮助。
托管管道#
管道是一个包含一系列按顺序运行的任务的托管作业。
这对于运行一系列相互依赖的任务非常有用,例如训练模型然后在其上运行推理。 不同的任务可以有不同的资源需求,以使用适当的每任务资源,从而节省成本,同时将管理任务的负担从用户身上移开。
注意
换句话说,托管作业可以是单个任务或任务管道。所有托管作业都由sky jobs launch提交。
要运行一个管道,请在YAML文件中指定任务的顺序。以下是一个示例:
name: pipeline
---
name: train
resources:
accelerators: V100:8
any_of:
- use_spot: true
- use_spot: false
file_mounts:
/checkpoint:
name: train-eval # NOTE: Fill in your bucket name
mode: MOUNT
setup: |
echo setup for training
run: |
echo run for training
echo save checkpoints to /checkpoint
---
name: eval
resources:
accelerators: T4:1
use_spot: false
file_mounts:
/checkpoint:
name: train-eval # NOTE: Fill in your bucket name
mode: MOUNT
setup: |
echo setup for eval
run: |
echo load trained model from /checkpoint
echo eval model on test set
上面的YAML定义了一个包含两个任务的管道。第一个name:
pipeline为管道命名。第一个任务的名称为train,第二个任务的名称为eval。任务之间用三个破折号---分隔。每个任务都有自己的resources、setup和run部分。任务是按顺序执行的。
要提交管道,使用相同的命令 sky jobs launch。管道将由SkyPilot自动启动和监控。您可以使用 sky jobs queue 或 sky jobs dashboard 检查管道的状态。
$ sky jobs launch -n pipeline pipeline.yaml
$ sky jobs queue
Fetching managed job statuses...
Managed jobs
In progress jobs: 1 RECOVERING
ID TASK NAME RESOURCES SUBMITTED TOT. DURATION JOB DURATION #RECOVERIES STATUS
8 pipeline - 50 mins ago 47m 45s - 1 RECOVERING
↳ 0 train 1x [V100:8][Spot|On-demand] 50 mins ago 47m 45s - 1 RECOVERING
↳ 1 eval 1x [T4:1] - - - 0 PENDING
注意
$SKYPILOT_TASK_ID 环境变量在每个任务的 run 部分也是可用的。它在管道中的每个任务中是唯一的。
例如,上面 eval 任务的 $SKYPILOT_TASK_ID 是:
“sky-managed-2022-10-06-05-17-09-750781_pipeline_eval_8-1”。
工作仪表板#
使用 sky jobs dashboard 打开一个仪表板以查看所有作业:
$ sky jobs dashboard
这会自动打开一个浏览器标签以显示仪表板:
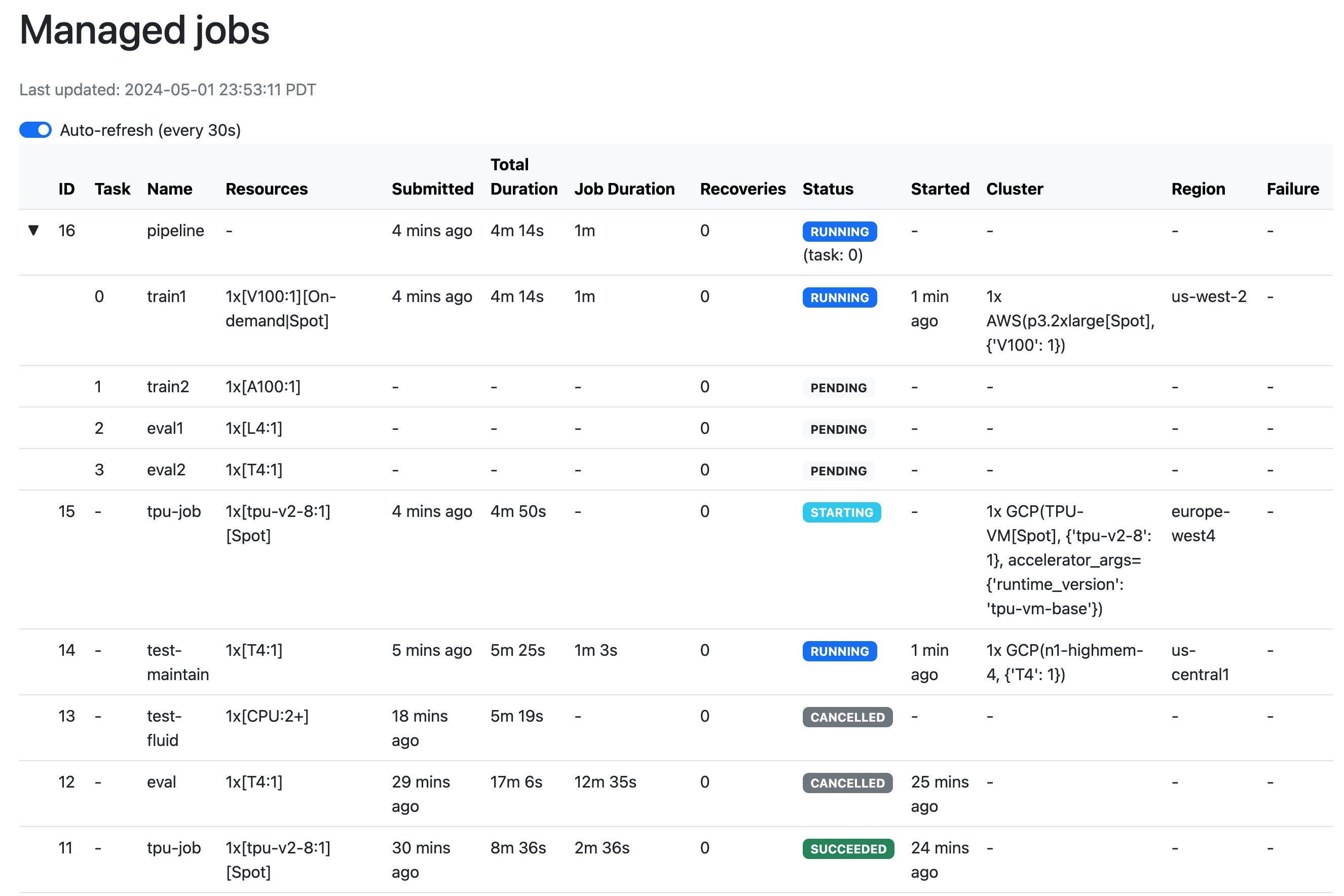
用户界面显示与命令行界面 sky jobs queue -a 相同的信息。当有许多进行中的任务需要监控时,用户界面尤其有用,因为基于终端的命令行界面可能需要多页才能显示。
文件的中间存储#
对于托管作业,SkyPilot需要一个中间存储桶来存储任务中使用的文件,例如本地文件挂载、临时文件和工作目录。
如果您没有配置存储桶,SkyPilot将自动为每次作业启动创建一个名为skypilot-filemounts-{username}-{run_id}的临时存储桶。SkyPilot在作业完成后会自动删除该存储桶。
或者,你可以预先配置一个存储桶,并通过在~/.sky/config.yaml中设置jobs.bucket来将其用作存储文件的中间介质:
# ~/.sky/config.yaml
jobs:
bucket: s3://my-bucket # Supports s3://, gs://, https://<azure_storage_account>.blob.core.windows.net/<container>, r2://, cos://<region>/<bucket>
如果您选择指定一个存储桶,请确保该存储桶已经存在并且您拥有必要的权限。
当使用预配置的中间存储桶与jobs.bucket时,SkyPilot会在存储桶根目录下创建特定于作业的目录来存储文件。它们按照以下结构组织:
# cloud bucket, s3://my-bucket/ for example
my-bucket/
├── job-15891b25/ # Job-specific directory
│ ├── local-file-mounts/ # Files from local file mounts
│ ├── tmp-files/ # Temporary files
│ └── workdir/ # Files from workdir
└── job-cae228be/ # Another job's directory
├── local-file-mounts/
├── tmp-files/
└── workdir/
当使用自定义存储桶(jobs.bucket)时,SkyPilot创建的作业特定目录(例如,job-15891b25/)在作业完成时会被移除。
提示
多个用户可以共享同一个中间存储桶。每个用户的任务将拥有自己独特的任务特定目录,确保文件保持分离和组织。
概念:作业控制器#
作业控制器是一个在云中运行的小型按需CPU虚拟机,用于管理用户的所有作业。 当提交第一个托管作业时,它会自动启动,并且在空闲10分钟后自动停止(即,在所有托管作业完成且在该时间段内没有提交新的托管作业后)。 因此,不需要用户操作来管理其生命周期。
你可以使用sky status查看控制器,并通过使用-r/--refresh标志刷新其状态。
虽然作业控制器的成本可以忽略不计(运行时约为$0.4/小时,停止时不到$0.004/小时),你仍然可以使用sky down 手动将其拆除,其中sky status的输出中找到。
注意
销毁作业控制器会丢失所有已完成托管作业的日志和状态信息。只有在没有进行中的托管作业时,才允许这样做,以确保没有资源泄漏。
自定义作业控制器资源#
您可能出于多种原因想要自定义作业控制器的资源:
更改可以同时运行的最大作业数,这是控制器vCPU的两倍。(默认值:16)
使用成本较低的控制器(如果您同时管理的作业数量较少)。
强制作业控制器在特定位置运行。(默认:最便宜的位置)
更改作业控制器的磁盘大小以存储更多日志。(默认值:50GB)
为了实现上述目标,您可以在~/.sky/config.yaml中指定自定义配置,包含以下字段:
jobs:
# NOTE: these settings only take effect for a new jobs controller, not if
# you have an existing one.
controller:
resources:
# All configs below are optional.
# Specify the location of the jobs controller.
cloud: gcp
region: us-central1
# Specify the maximum number of managed jobs that can be run concurrently.
cpus: 4+ # number of vCPUs, max concurrent jobs = 2 * cpus
# Specify the disk_size in GB of the jobs controller.
disk_size: 100
resources 字段与普通的 SkyPilot 作业具有相同的规范;请参阅 这里。
注意
如果您已经有一个现有的控制器(无论是停止的还是活动的),这些设置将不会生效。要使它们生效,首先需要拆除现有的控制器,这要求所有进行中的作业完成或被取消。