命令行界面
spaCy的CLI提供了多种实用命令,用于下载和训练流程、转换数据以及调试配置、数据和安装。要查看可用命令列表,可以输入python -m spacy --help。您还可以在任何命令或子命令后添加--help标志来查看描述、可用参数和用法。
download 命令
下载训练好的管道用于spaCy。下载器会找到最佳匹配的兼容版本并使用pip install来下载Python包。直接下载不会执行任何兼容性检查,并且需要指定管道名称及其版本(例如en_core_web_sm-3.0.0)。
| 名称 | 描述 |
|---|---|
model | Pipeline package name, e.g. en_core_web_sm. str |
--direct, -D | Force direct download of exact package version. bool |
--sdist, -S v3.0 | Download the source package (.tar.gz archive) instead of the default pre-built binary wheel. bool |
--help, -h | Show help message and available arguments. bool |
| pip args | Additional installation options to be passed to pip install when installing the pipeline package. For example, --user to install to the user home directory or --no-deps to not install package dependencies. Any |
| CREATES | The installed pipeline package in your site-packages directory. |
info 命令
打印有关您的spaCy安装、训练管道和本地设置的信息,并生成Markdown格式的标记以便复制粘贴到GitHub issues中。
| 名称 | 描述 |
|---|---|
model | A trained pipeline, i.e. package name or path (optional). Optional[str] |
--markdown, -md | Print information as Markdown. bool |
--silent, -s | Don’t print anything, just return the values. bool |
--exclude, -e | Comma-separated keys to exclude from the print-out. Defaults to "labels". Optional[str] |
--url, -u v3.5.0 | Print the URL to download the most recent compatible version of the pipeline. Requires a pipeline name. bool |
--help, -h | Show help message and available arguments. bool |
| PRINTS | 关于您的spaCy安装信息。 |
validate 命令
查找当前环境中安装的所有训练好的流水线包,并检查它们是否与当前安装的spaCy版本兼容。在通过pip install -U spacy升级spaCy后应运行此操作,以确保所有已安装的包都能与新版本一起使用。它将显示一个包及其安装版本的列表。如果有任何包已过时,将显示最新的兼容版本和更新命令。
| 名称 | 描述 |
|---|---|
| PRINTS | 显示您已安装的流水线(pipeline)包的兼容性详情。 |
init v3.0
spacy init 命令行界面包含用于初始化训练配置文件和流水线目录的有用命令。
初始化配置 命令v3.0
根据您的使用场景,使用推荐设置来初始化并保存一个config.cfg文件。它的工作原理与快速启动小工具类似,不同之处在于它还会自动填充所有默认值并导出一个训练就绪的配置文件。您指定的设置将影响建议的模型架构、流水线配置以及超参数。之后您还可以在配置文件中调整和自定义这些设置。
| 名称 | 描述 |
|---|---|
output_file | Path to output .cfg file or - to write the config to stdout (so you can pipe it forward to a file or to the train command). Note that if you’re writing to stdout, no additional logging info is printed. Path |
--lang, -l | Optional code of the language to use. Defaults to "en". str |
--pipeline, -p | Comma-separated list of trainable pipeline components to include. Defaults to "tagger,parser,ner". str |
--optimize, -o | "efficiency" or "accuracy". Whether to optimize for efficiency (faster inference, smaller model, lower memory consumption) or higher accuracy (potentially larger and slower model). This will impact the choice of architecture, pretrained weights and related hyperparameters. Defaults to "efficiency". str |
--gpu, -G | Whether the model can run on GPU. This will impact the choice of architecture, pretrained weights and related hyperparameters. bool |
--pretraining, -pt | Include config for pretraining (with spacy pretrain). Defaults to False. bool |
--force, -f | Force overwriting the output file if it already exists. bool |
--help, -h | Show help message and available arguments. bool |
| CREATES | 创建用于训练的配置文件。 |
init fill-config v3.0
自动填充部分.cfg文件的所有默认值,例如通过快速启动小工具生成的配置。用于训练的配置文件应始终保持完整,不包含任何隐藏默认值或缺失项,因此该命令可帮助您创建最终的训练配置。为了查找可用设置和默认值,系统将创建配置中引用的所有函数,并通过其签名确定默认值。如果您的配置存在无法自动解决的问题,spaCy将显示包含更多细节的验证错误。
| 名称 | 描述 |
|---|---|
base_path | Path to base config to fill, e.g. generated by the quickstart widget. Path |
output_file | Path to output .cfg file or ”-” to write to stdout so you can pipe it to a file. Defaults to ”-” (stdout). Path |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--pretraining, -pt | Include config for pretraining (with spacy pretrain). Defaults to False. bool |
--diff, -D | Print a visual diff highlighting the changes. bool |
--help, -h | Show help message and available arguments. bool |
| CREATES | 为训练创建完整且自动填充的配置文件。 |
init fill-curated-transformer 命令v3.7
自动填充精选Transformer流水线组件在.cfg文件中的Hugging Face模型超参数和加载器参数。可通过命令行参数传递或从initialize.components.transformer.encoder_loader配置部分读取Hugging Face模型的名称和版本。
| 名称 | 描述 |
|---|---|
base_path | Path to base config to fill, e.g. generated by the quickstart widget. Path |
output_file | Path to output .cfg file or ”-” to write to stdout so you can pipe it to a file. Defaults to ”-” (stdout). Path |
--model-name, -m | Name of the Hugging Face model. Defaults to the model name from the encoder loader config. Optional[str] |
--model-revision, -r | Revision of the Hugging Face model. Defaults to main. Optional[str] |
--pipe-name, -n | Name of the Curated Transformer pipe whose config is to be filled. Defaults to the first transformer pipe. Optional[str] |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
| CREATES | 为训练创建完整且自动填充的配置文件。 |
初始化向量 命令v3.0
将词向量转换为适用于spaCy的格式。将导出一个nlp对象,您可以在配置文件的[initialize]块中使用它来初始化带向量的模型。有关如何在模型中使用向量的详细信息,请参阅静态向量使用指南。
| 名称 | 描述 |
|---|---|
lang | Pipeline language IETF language tag, such as en. str |
vectors_loc | Location of vectors. Should be a file where the first row contains the dimensions of the vectors, followed by a space-separated Word2Vec table. File can be provided in .txt format or as a zipped text file in .zip or .tar.gz format. Path |
output_dir | Pipeline output directory. Will be created if it doesn’t exist. Path |
--truncate, -t | Number of vectors to truncate to when reading in vectors file. Defaults to 0 for no truncation. int |
--prune, -p | Number of vectors to prune the vocabulary to. Defaults to -1 for no pruning. int |
--mode, -m | Vectors mode: default or floret. Defaults to default. str |
--attr, -a | Token attribute to use for vectors, e.g. LOWER or NORM) Defaults to ORTH. str |
--name, -n | Name to assign to the word vectors in the meta.json, e.g. en_core_web_md.vectors. Optional[str] |
--verbose, -V | Print additional information and explanations. bool |
--help, -h | Show help message and available arguments. bool |
| CREATES | 创建一个包含词汇表和向量的spaCy管道目录。 |
init labels 命令v3.0
为数据中的标签生成JSON文件。这有助于加快训练过程,因为spaCy无需预处理数据来提取标签。生成标签后,您可以通过配置文件的[initialize]块将它们提供给在初始化时接受labels参数的组件。
| 名称 | 描述 |
|---|---|
config_path | Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. Union[Path, str] |
output_path | Output directory for the label files. Will create one JSON file per component. Path |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--verbose, -V | Show more detailed messages for debugging purposes. bool |
--gpu-id, -g | GPU ID or -1 for CPU. Defaults to -1. int |
--help, -h | Show help message and available arguments. bool |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. Any |
| CREATES | 创建标签文件。 |
find-function 命令v3.7
查找给定注册函数对应的模块、路径和文件行号。此功能有助于理解配置文件中使用的注册函数是在何处定义的。
| 名称 | 描述 |
|---|---|
func_name | Name of the registered function. str |
--registry, -r | Name of the catalogue registry. str |
convert 命令
将文件转换为spaCy的二进制训练数据格式,即序列化的DocBin,用于train命令和其他实验管理功能。转换器可以在命令行中指定,或根据输入文件的扩展名自动选择。
| 名称 | 描述 |
|---|---|
input_path | Input file or directory. Path |
output_dir | Output directory for converted file. Defaults to "-", meaning data will be written to stdout. Optional[Path] |
--converter, -c | Name of converter to use (see below). str |
--file-type, -t | Type of file to create. Either spacy (default) for binary DocBin data or json for v2.x JSON format. str |
--n-sents, -n | Number of sentences per document. Supported for: conll, conllu, iob, ner int |
--seg-sents, -s | Segment sentences. Supported for: conll, ner bool |
--base, -b, --model | Trained spaCy pipeline for sentence segmentation to use as base (for --seg-sents). Optional[str] |
--morphology, -m | Enable appending morphology to tags. Supported for: conllu bool |
--merge-subtokens, -T | Merge CoNLL-U subtokens bool |
--ner-map, -nm | NER tag mapping (as JSON-encoded dict of entity types). Supported for: conllu Optional[Path] |
--lang, -l | Language code (if tokenizer required). Optional[str] |
--concatenate, -C | Concatenate output to a single file bool |
--help, -h | Show help message and available arguments. bool |
| CREATES | Binary DocBin training data that can be used with spacy train. |
转换器
| ID | 描述 |
|---|---|
auto | Automatically pick converter based on file extension and file content (default). |
json | JSON-formatted training data used in spaCy v2.x. |
conllu | Universal Dependencies .conllu format. |
ner / conll | NER with IOB/IOB2/BILUO tags, one token per line with columns separated by whitespace. The first column is the token and the final column is the NER tag. Sentences are separated by blank lines and documents are separated by the line -DOCSTART- -X- O O. Supports CoNLL 2003 NER format. See sample data. |
iob | NER with IOB/IOB2/BILUO tags, one sentence per line with tokens separated by whitespace and annotation separated by |, either word|B-ENTorword|POS|B-ENT. See sample data. |
debug v3.0
spacy debug 命令行界面包含一系列实用命令,可用于调试和分析您的配置文件、数据及实现。
调试配置 命令v3.0
调试config.cfg文件并显示验证错误。
该命令将创建树中的所有对象并进行验证。请注意,
某些配置验证错误是阻塞性的,会阻止其余配置的解析。
这意味着您可能无法一次性看到所有验证错误,某些问题只有在修复之前的错误后才会显示。
要自动填充部分配置并保存结果,您可以使用
init fill-config命令。
| 名称 | 描述 |
|---|---|
config_path | Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. Union[Path, str] |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--show-functions, -F | Show an overview of all registered function blocks used in the config and where those functions come from, including the module name, Python file and line number. bool |
--show-variables, -V | Show an overview of all variables referenced in the config, e.g. ${paths.train} and their values that will be used. This also reflects any config overrides provided on the CLI, e.g. --paths.train /path. bool |
--help, -h | Show help message and available arguments. bool |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. Any |
| PRINTS | 如果有配置验证错误则打印。 |
debug data 命令
Analyze, debug and validate your training and development data. Get useful stats, and find problems like invalid entity annotations, cyclic dependencies, low data labels and more.
| 名称 | 描述 |
|---|---|
config_path | Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. Union[Path, str] |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--ignore-warnings, -IW | Ignore warnings, only show stats and errors. bool |
--verbose, -V | Print additional information and explanations. bool |
--no-format, -NF | Don’t pretty-print the results. Use this if you want to write to a file. bool |
--help, -h | Show help message and available arguments. bool |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. Any |
| PRINTS | 调试信息。 |
debug diff-config 命令
显示配置文件与spaCy默认设置或其他配置文件的差异。如果在创建配置文件时使用了额外设置,那么在与默认设置进行比较时,必须将这些设置作为额外参数提供给命令。生成的差异也可以在发布到讨论论坛时使用,以便为维护者提供更多信息。
| 名称 | 描述 |
|---|---|
config_path | Path to training config file containing all settings and hyperparameters. Union[Path, str] |
compare_to | Path to another config file to diff against, or None to compare against default settings. Optional[Union[Path, str] |
optimize, -o | "efficiency" or "accuracy". Whether the config was optimized for efficiency (faster inference, smaller model, lower memory consumption) or higher accuracy (potentially larger and slower model). Only relevant when comparing against a default config. Defaults to "efficiency". str |
gpu, -G | Whether the config was made to run on a GPU. Only relevant when comparing against a default config. bool |
pretraining, -pt | Include config for pretraining (with spacy pretrain). Only relevant when comparing against a default config. Defaults to False. bool |
markdown, -md | Generate Markdown for Github issues. Defaults to False. bool |
| PRINTS | 两个配置文件之间的差异。 |
debug profile 命令
分析spaCy管道中哪些函数耗时最多。输入应格式化为每行一个JSON对象,包含键"text"。可以通过JSONL文件提供,或从sys.sytdin读取。如果未指定输入文件,将通过ml_datasets加载IMDB数据集。
| 名称 | 描述 |
|---|---|
model | A loadable spaCy pipeline (package name or path). str |
inputs | Path to input file, or - for standard input. Path |
--n-texts, -n | Maximum number of texts to use if available. Defaults to 10000. int |
--help, -h | Show help message and available arguments. bool |
| PRINTS | 管道的性能分析信息。 |
调试模型 命令v3.0
通过在一个示例文本上运行并检查其如何更新内部权重和参数,来调试Thinc Model。
在此示例日志中,我们仅在模型创建后打印每一层的名称("步骤0"),这有助于我们理解神经网络的内部结构,并专注于需要进一步检查的特定层(参见下一个示例)。
在这个示例日志中,我们可以看到模型初始化(步骤1)如何为各层的nI(输入)和nO(输出)维度传播正确的值。在softmax层中,此步骤还将W矩阵定义为由nO和nI维度决定的全零矩阵。经过第一个训练步骤(步骤2)后,该矩阵显然已通过训练反馈循环更新了其值。
| 名称 | 描述 |
|---|---|
config_path | Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. Union[Path, str] |
component | Name of the pipeline component of which the model should be analyzed. str |
--layers, -l | Comma-separated names of layer IDs to print. str |
--dimensions, -DIM | Show dimensions of each layer. bool |
--parameters, -PAR | Show parameters of each layer. bool |
--gradients, -GRAD | Show gradients of each layer. bool |
--attributes, -ATTR | Show attributes of each layer. bool |
--print-step0, -P0 | Print model before training. bool |
--print-step1, -P1 | Print model after initialization. bool |
--print-step2, -P2 | Print model after training. bool |
--print-step3, -P3 | Print final predictions. bool |
--gpu-id, -g | GPU ID or -1 for CPU. Defaults to -1. int |
--help, -h | Show help message and available arguments. bool |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. Any |
| PRINTS | 调试信息。 |
debug pieces 命令v3.7
分析单词或句子片段统计信息。
| 名称 | 描述 |
|---|---|
config_path | Path to config file. Union[Path, str] |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--name, -n | Name of the Curated Transformer pipe whose config is to be filled. Defaults to the first transformer pipe. Optional[str] |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. Any |
| PRINTS | 调试信息。 |
train 命令
训练一个流程管道。期望数据采用spaCy的
二进制格式以及包含所有设置和超参数的
配置文件。
将保存所有训练周期中的最佳模型以及最终流程管道。
--code参数可用于提供在训练过程开始前导入的Python文件,这使您可以注册
自定义函数和架构并在配置中引用它们,同时仍使用spaCy内置的train工作流程。
如果需要管理复杂的多步骤训练工作流,请查看新的
spaCy projects。
| 名称 | 描述 |
|---|---|
config_path | Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. Union[Path, str] |
--output, -o | Directory to store trained pipeline in. Will be created if it doesn’t exist. Optional[Path] |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--verbose, -V | Show more detailed messages during training. bool |
--gpu-id, -g | GPU ID or -1 for CPU. Defaults to -1. int |
--help, -h | Show help message and available arguments. bool |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. Any |
| CREATES | 最终训练完成的流水线和最佳训练完成的流水线。 |
从Python调用训练函数 v3.2
训练命令行界面提供了一个train辅助函数,使您可以像运行spacy train一样执行训练。通常直接使用命令行会更方便,但如果您需要从代码中启动训练,这就是实现方式。
| 名称 | 描述 |
|---|---|
config_path | Path to the config to use for training. Union[str,Path] |
output_path | Optional name of directory to save output model in. If not provided a model will not be saved. Optional[Union[str,Path]] |
| 仅关键字 | |
use_gpu | Which GPU to use. Defaults to -1 for no GPU. int |
overrides | Values to override config settings. Dict[str, Any] |
pretrain 预训练实验性
在原始文本上预训练流水线组件的“token to vector”(Tok2vec)层,使用近似语言建模目标。具体来说,我们加载预训练向量,并训练如CNN、BiLSTM等组件来预测与预训练向量匹配的向量。每轮训练后权重会被保存到目录中。之后,您可以在训练配置中的init_tok2vec设置里指定这些预训练权重文件的路径来训练您的流水线。如果您只有少量标注数据,这项技术可能特别有用。更多信息请参阅预训练的使用文档。通常使用JsonlCorpus来读取原始文本。
| 名称 | 描述 |
|---|---|
config_path | Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. Union[Path, str] |
output_dir | Directory to save binary weights to on each epoch. Path |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--resume-path, -r | Path to pretrained weights from which to resume pretraining. Optional[Path] |
--epoch-resume, -er | The epoch to resume counting from when using --resume-path. Prevents unintended overwriting of existing weight files. Optional[int] |
--gpu-id, -g | GPU ID or -1 for CPU. Defaults to -1. int |
--skip-last, -L v3.5.2 | Skip saving model-last.bin. Defaults to False. bool |
--help, -h | Show help message and available arguments. bool |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --training.dropout 0.2. Any |
| CREATES | The pretrained weights that can be used to initialize spacy train. |
evaluate 命令
evaluate 子命令已被 spacy benchmark accuracy 取代。为了保持兼容性,evaluate 作为 benchmark accuracy 的别名提供。
benchmark v3.5
spacy benchmark 命令行界面包含用于评估您的spaCy管道准确性和速度的命令。
accuracy 命令v3.5
Evaluate the accuracy of a trained pipeline. Expects a loadable spaCy pipeline
(package name or path) and evaluation data in the
binary .spacy format. The
--gold-preproc option sets up the evaluation examples with gold-standard
sentences and tokens for the predictions. Gold preprocessing helps the
annotations align to the tokenization, and may result in sequences of more
consistent length. However, it may reduce runtime accuracy due to train/test
skew. To render a sample of dependency parses in a HTML file using the
displaCy visualizations, set as output directory as the
--displacy-path argument.
| 名称 | 描述 |
|---|---|
model | Pipeline to evaluate. Can be a package or a path to a data directory. str |
data_path | Location of evaluation data in spaCy’s binary format. Path |
--output, -o | Output JSON file for metrics. If not set, no metrics will be exported. Optional[Path] |
--code, -c v3.0 | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--gold-preproc, -G | Use gold preprocessing. bool |
--gpu-id, -g | GPU to use, if any. Defaults to -1 for CPU. int |
--displacy-path, -dp | Directory to output rendered parses as HTML. If not set, no visualizations will be generated. Optional[Path] |
--displacy-limit, -dl | Number of parses to generate per file. Defaults to 25. Keep in mind that a significantly higher number might cause the .html files to render slowly. int |
--per-component, -P v3.6 | Whether to return the scores keyed by component name. Defaults to False. bool |
--spans-key, -sk v3.6.2 | Spans key to use when evaluating Doc.spans. Defaults to sc. str |
--help, -h | Show help message and available arguments. bool |
| CREATES | 生成训练结果及可选的指标和可视化图表。 |
speed 命令v3.5
以95%置信区间对训练好的流水线进行速度基准测试。
需要一个可加载的spaCy流水线(包名称或路径)以及二进制.spacy格式的基准测试数据。在进行任何测量之前,流水线会先进行预热。
| 名称 | 描述 |
|---|---|
model | Pipeline to benchmark the speed of. Can be a package or a path to a data directory. str |
data_path | Location of benchmark data in spaCy’s binary format. Path |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--batch-size, -b | Set the batch size. If not set, the pipeline’s batch size is used. Optional[int] |
--no-shuffle | Do not shuffle documents in the benchmark data. bool |
--gpu-id, -g | GPU to use, if any. Defaults to -1 for CPU. int |
--batches | Number of batches to benchmark on. Defaults to 50. Optional[int] |
--warmup, -w | Iterations over the benchmark data for warmup. Defaults to 3 Optional[int] |
--help, -h | Show help message and available arguments. bool |
| PRINTS | 流水线处理速度(单位:词/秒),附带95%置信区间。 |
apply 命令v3.5
将训练好的管道应用于数据,并将生成的标注文档存储在DocBin中。输入可以是单个文件或目录。支持的输入格式包括:
.spacy.jsonl包含用户指定的text_key- 具有任何其他扩展名的文件将被视为包含单个文档的纯文本文件。
当提供目录时,将递归遍历以收集所有文件。
加载.spacy文件时,任何存储在Doc上未被管道覆盖的潜在注释都将被保留。
如果您只想在原始文本上评估管道,请确保.spacy文件不包含任何注释。
| 名称 | 描述 |
|---|---|
model | Pipeline to apply to the data. Can be a package or a path to a data directory. str |
data_path | Location of data to be evaluated in spaCy’s binary format, jsonl, or plain text. Path |
output-file | Output DocBin path. str |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--text-key, -tk | The key for .jsonl files to use to grab the texts from. Defaults to text. Optional[str] |
--force-overwrite, -F | If the provided output-file already exists, then force apply to overwrite it. If this is False (default) then quits with a warning instead. bool |
--gpu-id, -g | GPU to use, if any. Defaults to -1 for CPU. int |
--batch-size, -b | Batch size to use for prediction. Defaults to 1. int |
--n-process, -n | Number of processes to use for prediction. Defaults to 1. int |
--help, -h | Show help message and available arguments. bool |
| CREATES | A DocBin with the annotations from the model for all the files found in data-path. |
find-threshold 命令v3.5
为训练好的模型运行预测试验,通过调整不同阈值来最大化指定的评估指标。阈值搜索空间从0到1线性遍历,共进行n_trials步。结果会以表格形式显示在stdout上(对应的API调用spacy.cli.find_threshold.find_threshold()会返回所有结果)。
这仅适用于预测受阈值影响的组件 - 例如textcat_multilabel和spancat,但不包括textcat。请注意,必须提供配置中相应阈值属性的完整路径。
| 名称 | 描述 |
|---|---|
model | Pipeline to evaluate. Can be a package or a path to a data directory. str |
data_path | Path to file with DocBin with docs to use for threshold search. Path |
pipe_name | Name of pipe to examine thresholds for. str |
threshold_key | Key of threshold attribute in component’s configuration. str |
scores_key | Name of score to metric to optimize. str |
--n_trials, -n | Number of trials to determine optimal thresholds. int |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. Optional[Path] |
--gpu-id, -g | GPU to use, if any. Defaults to -1 for CPU. int |
--gold-preproc, -G | Use gold preprocessing. bool |
--verbose, -V, -VV | Display more information for debugging purposes. bool |
--help, -h | Show help message and available arguments. bool |
assemble 命令
无需额外训练即可从配置文件组装一个流水线。需要一个包含所有设置和超参数的配置文件。
--code参数可用于导入一个Python文件,该文件允许您注册自定义函数并在配置中引用它们。
| 名称 | 描述 |
|---|---|
config_path | Path to the config file containing all settings and hyperparameters. If -, the data will be read from stdin. Union[Path, str] |
output_dir | Directory to store the final pipeline in. Will be created if it doesn’t exist. Optional[Path] |
--code, -c | Path to Python file with additional code to be imported. Allows registering custom functions. Optional[Path] |
--verbose, -V | Show more detailed messages during processing. bool |
--help, -h | Show help message and available arguments. bool |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.data ./data. Any |
| CREATES | 最终组装的流水线。 |
package 命令
从现有的流水线数据目录生成可安装的Python包。所有数据文件都会被复制。如果提供了额外的代码文件(例如包含自定义注册函数(如流水线组件)的Python文件),它们将被复制到包中并在__init__.py中导入。如果提供了meta.json的路径,或在输入目录中找到meta.json,则会使用该文件。否则,可以直接从命令行输入数据。spaCy随后会创建一个构建产物,您可以通过pip install进行分发和安装。从v3.1开始,package命令还会根据meta.json中定义的流水线信息创建一个格式化的README.md。如果源目录中已存在README.md,则会直接使用该文件。
| 名称 | 描述 |
|---|---|
input_dir | Path to directory containing pipeline data. Path |
output_dir | Directory to create package folder in. Path |
--code, -c v3.0 | Comma-separated paths to Python files to be included in the package and imported in its __init__.py. This allows including registering functions and custom components. str |
--meta-path, -m | Path to meta.json file (optional). Optional[Path] |
--create-meta, -C | Create a meta.json file on the command line, even if one already exists in the directory. If an existing file is found, its entries will be shown as the defaults in the command line prompt. bool |
--build, -b v3.0 | Comma-separated artifact formats to build. Can be sdist (for a .tar.gz archive) and/or wheel (for a binary .whl file), or none if you want to run this step manually. The generated artifacts can be installed by pip install. Defaults to sdist. str |
--name, -n v3.0 | Package name to override in meta. Optional[str] |
--version, -v v3.0 | Package version to override in meta. Useful when training new versions, as it doesn’t require editing the meta template. Optional[str] |
--force, -f | Force overwriting of existing folder in output directory. bool |
--help, -h | Show help message and available arguments. bool |
| CREATES | 一个包含spaCy管道的Python包。 |
项目 v3.0
spacy project CLI包含用于处理spaCy项目的子命令,这些项目是构建和部署自定义spaCy管道的端到端工作流程。
项目克隆 命令
从Git仓库克隆项目模板。底层调用git命令,如果支持稀疏检出功能则可以使用该特性,这样您只需下载所需内容。默认使用spaCy的项目模板仓库,但您也可以通过--repo选项指定任何您有权限访问的其他仓库(公共或私有)。
| 名称 | 描述 |
|---|---|
name | The name of the template to clone, relative to the repo. Can be a top-level directory or a subdirectory like dir/template. str |
dest | Where to clone the project. Defaults to current working directory. Path |
--repo, -r | The repository to clone from. Can be any public or private Git repo you have access to. str |
--branch, -b | The branch to clone from. Defaults to master. str |
--sparse, -S | Enable sparse checkout to only check out and download what’s needed. Requires Git v22.2+. bool |
--help, -h | Show help message and available arguments. bool |
| CREATES | 克隆的项目目录。 |
项目资源 命令
获取项目资源,如数据集和预训练权重。资源定义在project.yml文件的assets部分。如果提供了checksum校验值,则仅当本地不存在相同校验值的文件时才会下载,且spaCy会在下载文件的校验值不匹配时显示错误。如果资源未指定url则视为"私有"资源,需要手动将其放入目标目录。如果提供了本地路径,资源将被复制到当前项目中。
| 名称 | 描述 |
|---|---|
project_dir | Path to project directory. Defaults to current working directory. Path |
--extra, -e v3.3.1 | Download assets marked as “extra”. Default false. bool |
--sparse, -S | Enable sparse checkout to only check out and download what’s needed. Requires Git v22.2+. bool |
--help, -h | Show help message and available arguments. bool |
| CREATES | Downloaded or copied assets defined in the project.yml. |
项目运行 命令
运行在project.yml中定义的命名命令或工作流。如果指定了工作流名称,则会按顺序运行该工作流中的所有命令。如果命令定义了依赖项或输出,则仅当状态发生更改时才会重新运行。例如,如果输入数据集发生变化,依赖于这些文件的预处理命令将被重新运行。
| 名称 | 描述 |
|---|---|
subcommand | Name of the command or workflow to run. str |
project_dir | Path to project directory. Defaults to current working directory. Path |
--force, -F | Force re-running steps, even if nothing changed. bool |
--dry, -D | Perform a dry run and don’t execute scripts. bool |
--help, -h | Show help message and available arguments. bool |
| EXECUTES | The command defined in the project.yml. |
project push 命令
将所有可用文件或命令outputs部分列出的目录上传至远程存储。输出文件在上传前会被归档压缩,并在远程存储中通过以下方式定位:输出文件的相对路径(URL编码)、其命令字符串和依赖项的哈希值,以及文件内容的哈希值。这意味着push操作绝不会覆盖远程存储中的现有文件。如果所有哈希值匹配,说明内容相同则不会执行任何操作。如果内容不同,则会上传文件的新版本。删除过时文件的操作需要您自行处理。
远程存储可以在project.yml文件的remotes部分进行定义。在底层实现上,spaCy使用cloudpathlib来与远程存储进行通信,因此您可以使用cloudpathlib支持的任何协议,包括S3、Google云存储以及本地文件系统,不过某些协议可能需要安装额外的依赖项才能使用。
| 名称 | 描述 |
|---|---|
remote | The name of the remote to upload to. Defaults to "default". str |
project_dir | Path to project directory. Defaults to current working directory. Path |
--help, -h | Show help message and available arguments. bool |
| UPLOADS | 所有已存在但尚未存储在远程的项目输出文件。 |
project pull 命令
下载所有列为outputs的文件或目录(除非本地已存在)。在远程搜索文件时,pull不仅会查看输出路径,还会考虑命令字符串和依赖项的哈希值。例如,假设您之前已将检查点推送到远程,但现在更改了一些超参数。由于您更改了命令的输入,如果运行pull,将不会检索到过时的结果。如果您训练管道并将输出推送到远程,这些输出将与先前的输出一起保存,因此如果您将配置改回,您将能够取回结果。
远程存储可以在project.yml文件的remotes部分进行定义。在底层实现上,spaCy使用Pathy来与远程存储进行通信,因此您可以使用Pathy支持的任何协议,包括S3、Google云存储以及本地文件系统,不过某些协议可能需要安装额外的依赖项才能使用。
| 名称 | 描述 |
|---|---|
remote | The name of the remote to download from. Defaults to "default". str |
project_dir | Path to project directory. Defaults to current working directory. Path |
--help, -h | Show help message and available arguments. bool |
| 下载 | 所有本地不存在但可以在远程找到的项目输出。 |
项目文档 命令
根据项目的project.yml自动生成格式美观的Markdown格式README文件。将创建记录可用命令、工作流和资源的部分。自动生成的内容将放置在两个隐藏标记之间,因此您可以在自动生成的文档前后添加自定义内容。当您重新运行project document命令时,只会替换自动生成的部分。
更多示例,请参阅我们projects仓库中的模板。
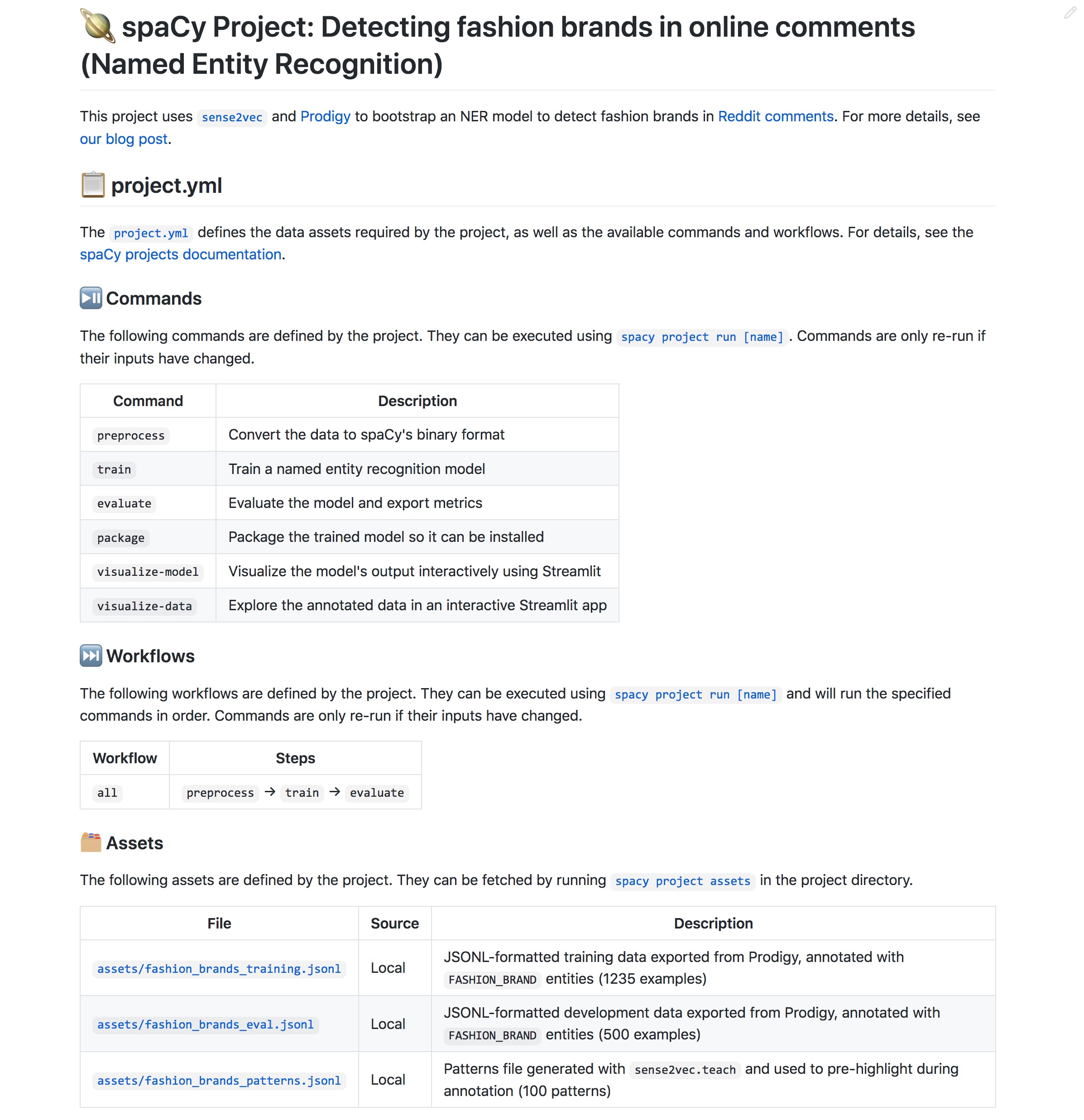
| 名称 | 描述 |
|---|---|
project_dir | Path to project directory. Defaults to current working directory. Path |
--output, -o | Path to output file or - for stdout (default). If a file is specified and it already exists and contains auto-generated docs, only the auto-generated docs section is replaced. Path |
--no-emoji, -NE | Don’t use emoji in the titles. bool |
| CREATES | Markdown格式的项目文档。 |
project dvc 命令
自动生成数据版本控制 (DVC) 配置文件。底层调用dvc run并带上--no-exec参数来生成dvc.yaml文件。一个DVC项目只能定义一个流水线,因此需要指定在project.yml中定义的一个工作流。如果未指定工作流,则默认使用第一个定义的工作流。只有当project.yml文件发生变化时才会更新DVC配置。详情请参阅DVC集成文档。
| 名称 | 描述 |
|---|---|
project_dir | Path to project directory. Defaults to current working directory. Path |
workflow | Name of workflow defined in project.yml. Defaults to first workflow if not set. Optional[str] |
--force, -F | Force-updating config file. bool |
--verbose, -V | Print more output generated by DVC. bool |
--quiet, -q | Print no output generated by DVC. bool |
--help, -h | Show help message and available arguments. bool |
| CREATES | A dvc.yaml file in the project directory, based on the steps defined in the given workflow. |
huggingface-hub v3.1
spacy huggingface-cli 命令行工具包含将训练好的spaCy管道上传至Hugging Face Hub的命令。
huggingface-hub push 命令
将spaCy管道推送到Hugging Face Hub。需要一个通过spacy package和--build wheel打包的.whl文件。更多详情请参阅spaCy项目的集成部分。
| 名称 | 描述 |
|---|---|
whl_path | The path to the .whl file packaged with spacy package. Path(positional) |
--org, -o | Optional name of organization to which the pipeline should be uploaded. str |
--msg, -m | Commit message to use for update. Defaults to "Update spaCy pipeline". str |
--verbose, -V | Output additional info for debugging, e.g. the full generated hub metadata. bool |
| UPLOADS | 上传到中心(hub)的管道。 |