层级与模型架构
模型架构是一个用于连接Thinc Model实例的函数。它描述了作为spaCy管道中组件内部运行的神经网络。要定义实际的架构,您可以直接在Thinc中实现逻辑,或者将Thinc用作PyTorch、TensorFlow和MXNet等框架的轻量级封装。每个Model也可以作为更大网络的子层使用,使您能够自由地将不同框架的实现组合到单个模型中。
spaCy的内置组件需要通过配置系统传递一个Model实例。要更改现有组件的模型架构,您只需更新配置以引用不同的注册函数。一旦根据此配置创建了组件,您将无法再更改它。架构就像神经网络的配方,一旦菜品已经准备好,您就无法更改配方。您必须重新创建一个。
config.cfg (节选)
类型签名
Thinc的Model类是一个泛型类,可以指定其输入和输出类型。Python使用方括号表示法来实现这一点,因此类型Model[List, Dict]表示模型的每批输入将是一个列表,输出将是一个字典。您还可以更具体地指定,例如Model[List[Doc], Dict[str, float]],表示模型期望输入为Doc对象列表,并返回字符串到浮点数的字典映射。您将看到的一些最常见类型包括:
| 类型 | 描述 |
|---|---|
| List[Doc] | A batch of Doc objects. Most components expect their models to take this as input. |
| Floats2d | A two-dimensional numpy or cupy array of floats. Usually 32-bit. |
| Ints2d | A two-dimensional numpy or cupy array of integers. Common dtypes include uint64, int32 and int8. |
| List[Floats2d] | A list of two-dimensional arrays, generally with one array per Doc and one row per token. |
| Ragged | 一个用于处理未填充连续数组中可变长度序列数据的容器。 |
| Padded | 一个用于处理可变长度序列数据的容器,数据存储在填充后的连续数组中。 |
详情请参阅Thinc类型参考。模型类型签名可帮助您了解哪些模型架构和组件能够相互配合。例如,TextCategorizer类期望的模型类型为Model[List[Doc],Floats2d],因为该模型将为每个Doc预测一行类别概率。相比之下,Tagger类期望的模型类型为Model[List[Doc],List[Floats2d]],因为它需要为每个词元预测一行概率。
无法保证具有相同类型签名的两个模型可以互换使用。它们可能还存在许多其他不兼容的方式。然而,如果类型不匹配,它们几乎肯定不会兼容。这种简单的验证非常有用,特别是当你配置编辑器或其他工具来早期突出显示这些错误时。配置文件在训练开始时也会进行验证,以确保所有类型正确匹配。
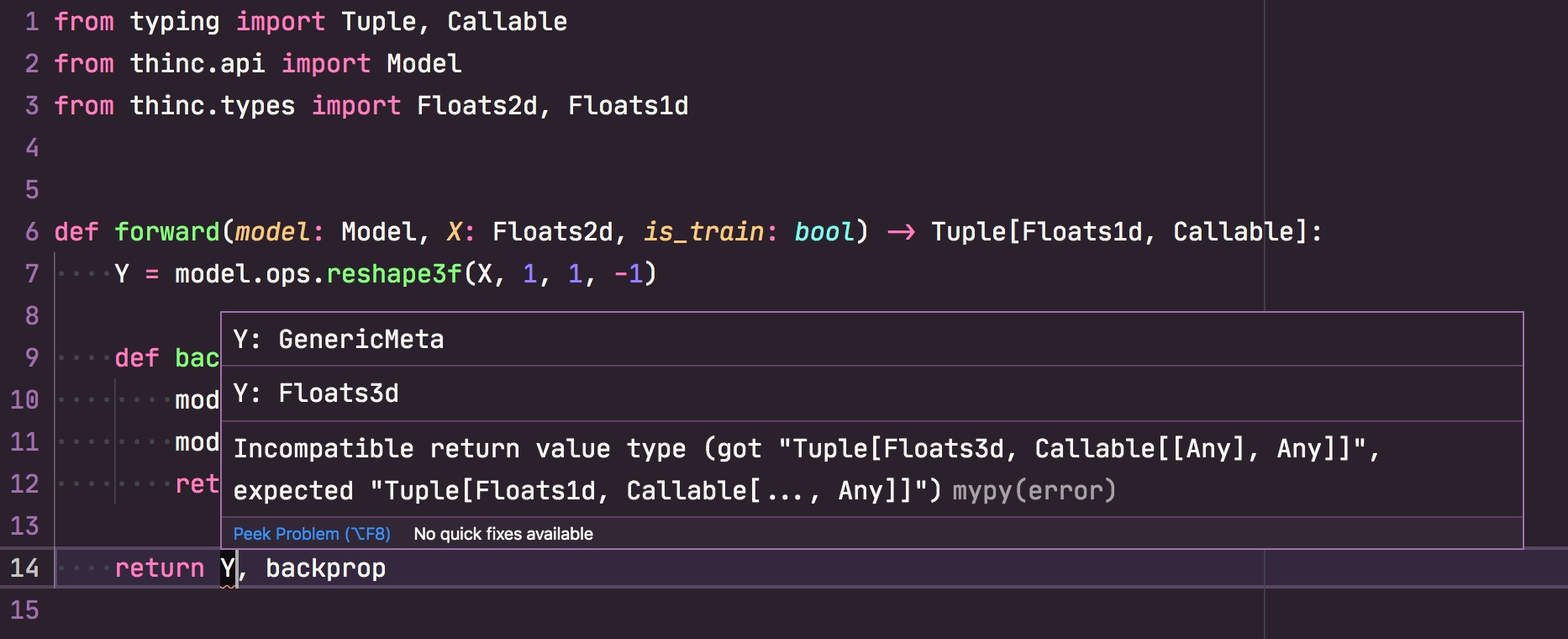
如果您使用的是像Visual Studio Code这样的现代编辑器,可以
设置mypy并配合
自定义Thinc插件,在编写代码时获取关于类型不匹配的实时反馈。
切换模型架构
如果未为TextCategorizer指定模型,默认会使用TextCatEnsemble架构。该架构将简单的词袋模型与神经网络相结合,通常能获得最准确的结果,但会牺牲速度。该模型的配置文件大致如下:
config.cfg (节选)
spaCy 还有两种内置的 textcat 架构,你可以轻松通过替换文本分类模型的定义来使用它们。例如,要使用简单快速的词袋模型 TextCatBOW,你可以将配置更改为:
config.cfg (节选)
有关spaCy提供的所有预定义架构及其配置方式的详细信息,请查阅模型架构文档。
定义子层
模型架构函数通常接受子层作为参数,这样您就可以尝试在网络中替换不同的层。根据架构函数的组织方式,您可能能够完全通过配置系统来定义网络结构,使用已经定义好的层。
在大多数自然语言处理的神经网络模型中,网络最重要的部分就是我们所说的嵌入和编码步骤。这些步骤共同计算了密集且上下文敏感的标记表示,它们的组合形成了一个典型的Tok2Vec层:
config.cfg (节选)
通过明确定义这些子层,可以轻松将一个子层替换为另一个,例如将第一个子层更改为使用CharacterEmbed架构的字符嵌入:
config.cfg (节选)
spaCy的大部分默认架构都接受tok2vec层作为大型任务特定神经网络中的子层。这使得在transformer、CNN、BiLSTM或其他特征提取方法之间切换变得容易。transformers文档部分展示了用transformer替换模型标准tok2vec层的示例。如果你想定义自己的解决方案,只需注册一个Model[List[Doc], List[Floats2d]]架构函数,就可以在任何spaCy组件中尝试使用它。
封装PyTorch、TensorFlow及其他框架
Thinc允许您使用统一的Model API来封装模型,这些模型可以用其他机器学习框架如PyTorch、TensorFlow和MXNet编写。这使得您可以轻松地使用不同框架实现的模型来驱动spaCy管道中的组件。例如,要将PyTorch模型封装为Thinc的Model,您可以使用Thinc的PyTorchWrapper:
让我们使用PyTorch来定义一个非常简单的神经网络,它包含两个带有ReLU激活和dropout的隐藏Linear层,以及一个softmax激活的输出层:
PyTorch模型
最终封装后的Model可以作为自定义架构直接使用,也可以作为更大模型的子组件。例如,我们可以使用Thinc的chain组合器(其功能类似于PyTorch中的Sequential)将封装模型与更大网络中的其他组件连接起来。这实际上意味着您可以轻松封装来自不同框架的组件,并通过Thinc将它们"粘合"在一起:
在上面的示例中,我们将自定义的PyTorch模型与spaCy定义的字符嵌入层相结合。CharacterEmbed返回一个Model,该模型接收List[Doc]作为输入,并输出List[Floats2d]。为了确保封装的PyTorch模型接收到有效输入,我们使用了Thinc的with_array辅助工具。
你也可以实现一个仅使用PyTorch处理transformer层的模型,同时采用"原生"Thinc层来完成精细的输入输出转换,并添加任务特定的"头部"结构,因为对于网络这些部分的效率考量相对较低。
使用封装模型
要使用我们包含PyTorch子网络的自定义模型,只需通过architectures注册表注册该架构即可。这会给架构分配一个名称,以便spaCy知道如何找到它,并允许通过config传入超参数等参数。完整示例如下:
注册架构
现在可以在任何现有的可训练spaCy组件中使用该模型定义,只需在配置文件中指定即可。在此配置中,自定义架构各个子组件所需的所有参数都通过配置以设置形式传递。
config.cfg (节选)
请注意,当使用PyTorch或Tensorflow模型时,建议相应地设置GPU内存分配器。当训练配置中将gpu_allocator设置为"pytorch"或"tensorflow"时,cupy将通过这些相应的库分配内存,从而避免当其他库的内存池中有可用内存时出现OOM错误。
config.cfg (节选)
使用Thinc定制模型
当然也可以完全在Thinc中定义上一节的Model。Thinc文档提供了关于各种层和可用辅助函数的详细信息。组合器可用于重载运算符,常见的使用模式是将chain绑定到>>。那么我们简单神经网络的"原生"Thinc版本将变为:
Thinc中的形状推断
严格来说,并不需要为每一层定义所有的输入和输出维度,因为Thinc可以通过将一层的输出维度与下一层的输入维度相匹配,在连续层之间执行形状推断。这意味着我们可以简化layers的定义:
Thinc甚至可以更进一步,推断出第一层的正确输入维度和最后一层的输出维度。要启用此功能,您需要使用具有正确维度的输入样本X和输出样本Y来调用Model.initialize:
带初始化的形状推断
spaCy内置的管道组件确保其内部模型始终使用适当的样本数据进行初始化。在这种情况下,X通常是List[Doc],而Y通常是List[Array1d]或List[Array2d],具体取决于任务类型。当调用nlp.initialize时会触发此功能。
Thinc中的Dropout和归一化
许多可用的Thinc layers允许您定义dropout参数,这将导致"链式"添加一个额外的Dropout层。您通常还可以选择是否要添加层归一化,这将产生一个额外的LayerNorm层。这意味着以下的layers定义与之前的定义是等效的:
创建新的可训练组件
除了替换现有组件中的层之外,您还可以从头开始实现一个全新的可训练管道组件。这可以通过创建一个继承自TrainablePipe的新类,并将其链接到您的自定义模型实现来完成。
示例:实体关系提取组件
本节概述了一个从头开始实现新型关系抽取组件的示例用例。我们将实现一个二元关系抽取方法,用于判断文档中的两个实体是否存在关联关系,如果存在关联,则确定连接它们的关联类型。我们允许两个实体之间存在多种类型的关系(多标签设置)。这需要完成两个主要步骤:
- 实现一个针对此任务的机器学习模型。它需要从
Doc中提取候选关系实例,并为每个关系标签预测相应的分数。 - 实现一个自定义的管道组件 - 由第一步的机器学习模型驱动 - 将预测分数转换为注释,这些注释在
Doc对象通过nlp管道时被存储在上面。
Step 1: Implementing the Model
我们需要实现一个Model,它接收文档列表(List[Doc])作为输入,并输出预测结果的二维矩阵(Floats2d):
模型架构
我们采用模块化方法来定义这个关系模型,将其定义为将两个层级串联在一起:第一个层级从给定文档集生成实例张量,第二个层级将实例张量转换为包含预测结果的最终张量:
模型架构
classification_layer可以类似于一个Linear层后接logistic激活函数:
分类层
第一层创建实例张量可以通过实现一个带有适当反向传播回调的自定义前向函数来定义。我们还定义了一个初始化方法,确保该层正确设置以进行训练。
我们在此省略了一些实现细节,完整实现请参考 spaCy项目 。
生成实例张量的层
这个自定义层使用嵌入层,例如Tok2Vec组件或Transformer。该层假定为Model[List[Doc], List[Floats2d]]类型,因为它将每个文档转换为一组词元列表,每个词元在向量空间中由其嵌入表示。
pooling层将被应用于将标记向量汇总为实体向量,因为命名实体(由Span对象表示)可能由一个或多个标记组成。例如,该池化层可以采用计算实体中所有标记向量平均值的方式。为此,Thinc提供了多个内置池化操作符。
最后,我们需要一个get_instances方法,该方法生成实体对用于分类它们是否相关。由于这些候选对通常是在同一文档内形成的,此函数接收一个Doc作为输入,并输出一个Span元组的List。例如,以下实现会选取同一文档中的任意两个实体,只要它们之间的最大距离(以词符数量计)不超过设定值:
候选生成
此函数被添加到@misc注册表中,以便我们可以从配置中引用它,并轻松将其替换为任何其他候选生成函数。
插曲:定义如何存储关系数据
对于我们新的关系抽取组件,我们将使用一个自定义的
扩展属性
doc._.rel来存储关系数据。该属性引用一个字典,以每个实体的起始偏移量作为键。字典中的值指向另一个字典,其中关系标签映射到0到1之间的值。我们假设任何高于0.5的值都是True关系。我们将用作训练数据的示例实例,会在example.reference._.rel中包含它们的黄金标准关系标注。
注册扩展属性
步骤2:实现管道组件
要将我们的新关系提取模型作为自定义可训练组件的一部分使用,我们创建一个继承自TrainablePipe的子类来保存该模型。

流水线组件框架
通常,构造函数会定义词汇表、机器学习模型以及该组件的名称。此外,该组件与textcat和tagger类似,存储了一个内部标签列表。机器学习模型将为每个标签预测分数。我们添加了便捷方法来轻松检索和添加标签。
构造函数(续)
创建后,该组件需要进行初始化。此方法可以通过两种方式定义相关标签:显式地通过在配置的initialize块中设置labels参数,或隐式地通过从生成完整训练数据集或代表性样本的get_examples回调中推导出来。
最终的标签数量定义了网络的输出维度,并将用于在整个神经网络层中进行形状推断。这是通过调用Model.initialize触发的。
初始化方法
每当该组件作为nlp管道的一部分时,initialize方法就会被触发,并且调用了nlp.initialize。通常,这种情况发生在spacy train训练前的管道设置阶段。初始化完成后,该管道组件及其内部模型即可用于训练和预测。
在训练过程中,会调用update方法,该方法委托给
Model.begin_update和
get_loss函数,该函数计算一批样本的损失,
以及用于更新模型层权重的损失梯度。Thinc提供了多个
损失函数可用于实现get_loss函数。
更新方法
训练模型后,该组件可用于进行新的预测。每个TrainablePipe子类都需要实现predict方法。在我们的案例中,可以简单地委托给内部模型的predict函数,该函数接收一批Doc对象并返回一个Floats2d数组:
predict方法
需要实现的最后一个方法是set_annotations。该函数接收预测结果,并直接修改给定的Doc对象以存储这些预测。对于我们的关系抽取组件,我们将数据存储在自定义属性doc._.rel中。
要正确理解关系抽取模型预测的分数,我们需要参考模型定义的get_instances函数,该函数确定了哪些实体对是相关候选对,这样预测结果才能与这些具体实体关联起来:
set_annotations 方法
在底层实现中,当管道应用于文档时,它会委托给predict和set_annotations方法:
__call__ 方法
还有一个可选方法需要实现:score用于计算您的组件在一组示例上的性能表现,并将结果以字典形式返回:
评分方法
这在训练组件时使用spacy train计算开发语料库的相关分数特别有用。
一旦我们的TrainablePipe子类完全实现后,就可以通过@Language.factory装饰器注册该组件。这将为其分配一个名称,并允许您通过nlp.add_pipe和配置来创建该组件。
注册管道组件
您可以扩展装饰器以包含以下信息:该组件运行所需的注释类型、它生成的注释类型,以及可以计算的分数:
工厂标注