项目
spaCy项目让您能够管理和共享针对不同使用场景和领域的端到端spaCy工作流,并协调训练、打包和部署自定义流程。您可以从克隆预定义的项目模板开始,根据需求进行调整,加载数据,训练流程,将其导出为Python包,将输出上传到远程存储,并与团队共享结果。spaCy项目可通过新的spacy project命令使用,我们在projects代码库中提供了模板。

spaCy项目让与数据科学和机器学习生态系统中许多其他优秀工具的集成变得简单,以便跟踪和管理您的数据和实验,迭代演示和原型,并将您的模型投入生产。
1. 克隆项目模板
spacy project clone 命令用于克隆现有的项目模板,并将文件复制到本地目录。随后您可以运行该项目,例如训练一个流程管道,并编辑命令和脚本来构建完全自定义的工作流。
默认情况下,项目会被克隆到当前工作目录。您可以通过可选的第二个参数来指定输出目录。如果不想使用spaCy的projects仓库,--repo选项允许您定义自定义仓库进行克隆。您也可以使用任何您有Git访问权限的私有仓库。
2. 获取项目资产
资产(Assets)是项目所需的数据文件 - 例如训练和评估数据,或用于初始化模型的预训练向量和嵌入。每个项目模板都附带一个project.yml文件,用于定义要下载的资产及其存放位置。spacy project assets命令将为您获取项目资产:
资源URL可以支持多种不同的协议:HTTP、HTTPS、FTP、SSH,甚至包括GCS和S3等云存储。您还可以通过将url字符串替换为git代码块来使用git获取资源。spaCy将利用Git的"稀疏检出"功能来避免下载整个代码库。
有时您的项目配置可能包含一些大型资源文件,您不一定希望在运行spacy project assets时就下载它们。这就是为什么资源可以被标记为extra的原因 - 默认情况下,这些资源不会被下载。如果需要下载它们,请运行spacy project assets --extra。
3. 运行命令
命令由一个或多个步骤组成,可以通过spacy project run运行。以下将运行project.yml中定义的preprocess命令:
命令可以通过deps(命令所需的文件)和outputs(命令生成的文件)键来定义其预期的依赖项和输出。这使您的项目能够跟踪更改并确定是否需要重新运行命令。例如,如果输入数据发生变化,您需要重新运行preprocess命令。但如果没有任何变化,则可以跳过此步骤。您还可以设置--force强制重新运行命令,或使用--dry执行"试运行"查看将会发生什么(而无需实际运行脚本)。
自spaCy v3.4.2版本起,spacy projects run会检查您已安装的依赖项,以验证您的环境是否设置正确并与项目的requirements.txt(如果有)保持一致。如果检测到缺失或冲突的依赖项,将显示相应的警告。如果您想禁用依赖项检查,请在项目的project.yml中设置check_requirements: false。
4. 运行工作流
工作流是按顺序运行且通常相互依赖的一系列命令。例如,要生成一个管道包,你可能需要先转换数据,然后运行spacy train在转换后的数据上训练管道,如果训练成功,再运行spacy package将训练出的最佳模型转换为可安装的Python包。以下命令运行project.yml中定义的名为all的工作流,并按顺序执行其中指定的命令:
利用命令中定义的预期依赖项和输出,spaCy可以判断是否需要重新运行某个命令(如果其输入或输出发生变化)或跳过执行。如果您希望实现更高级的数据管道并在Git中跟踪变更,请查看数据版本控制(DVC)集成。spacy project dvc命令会根据project.yml中定义的工作流生成DVC配置文件,从而让您可以将spaCy项目作为DVC代码库进行管理。
5. 可选:推送到远程存储
训练完一个流程后,你可以选择使用
spacy project push命令将输出上传到
远程存储,使用如S3、
Google云存储或SSH等协议。这可以帮助你
导出流程包、共享工作成果给团队,或缓存
结果以避免重复工作。
project.yml文件中的remotes部分允许您为不同的存储分配名称。要从远程存储下载状态,您可以使用spacy project pull命令。更多详细信息,请参阅远程存储文档。
项目目录和资源
project.yml
project.yml文件定义了项目所依赖的资源,例如数据集和预训练权重,以及一系列可以单独运行或作为工作流执行的命令——例如预处理数据、将其转换为spaCy格式、训练流程、评估并导出指标、打包以及快速启动一个网页演示。它看起来与用于定义持续集成(CI)流程的配置文件非常相似。
explosion/projects/v3/pipelines/tagger_parser_ud/project.yml
| 章节 | 描述 |
|---|---|
title | An optional project title used in --help message and auto-generated docs. |
description | An optional project description used in auto-generated docs. |
vars | A dictionary of variables that can be referenced in paths, URLs and scripts and overridden on the CLI, just like config.cfg variables. For example, ${vars.name} will use the value of the variable name. Variables need to be defined in the section vars, but can be a nested dict, so you’re able to reference ${vars.model.name}. |
env | A dictionary of variables, mapped to the names of environment variables that will be read in when running the project. For example, ${env.name} will use the value of the environment variable defined as name. |
directories | An optional list of directories that should be created in the project for assets, training outputs, metrics etc. spaCy will make sure that these directories always exist. |
assets | A list of assets that can be fetched with the project assets command. url defines a URL or local path, dest is the destination file relative to the project directory, and an optional checksum ensures that an error is raised if the file’s checksum doesn’t match. Instead of url, you can also provide a git block with the keys repo, branch and path, to download from a Git repo. |
workflows | A dictionary of workflow names, mapped to a list of command names, to execute in order. Workflows can be run with the project run command. |
commands | A list of named commands. A command can define an optional help message (shown in the CLI when the user adds --help) and the script, a list of commands to run. The deps and outputs let you define the created file the command depends on and produces, respectively. This lets spaCy determine whether a command needs to be re-run because its dependencies or outputs changed. Commands can be run as part of a workflow, or separately with the project run command. |
spacy_version | Optional spaCy version range like >=3.0.0,<3.1.0 that the project is compatible with. If it’s loaded with an incompatible version, an error is raised when the project is loaded. |
check_requirements v3.4.2 | A flag determining whether to verify that the installed dependencies align with the project’s requirements.txt. Defaults to true. |
数据资产
资产(Assets)是项目可能需要的任何文件,例如训练和开发语料库或用于初始化模型的预训练权重。资产在project.yml的assets块中定义,可以使用project assets命令下载。定义校验和可以确保其他运行您项目的人使用与您相同的文件。资产URL支持多种协议:HTTP、HTTPS、FTP、SSH,甚至包括GCS和S3等云存储。您也可以从Git仓库下载资产。
从URL或云存储下载
在底层实现中,spaCy使用了smart-open库,因此您可以使用它支持的任何协议。请注意,使用某些协议可能需要安装额外的依赖项。
| 名称 | 描述 |
|---|---|
dest | The destination path to save the downloaded asset to (relative to the project directory), including the file name. |
extra | Optional flag determining whether this asset is downloaded only if spacy project assets is run with --extra. False by default. |
url | The URL to download from, using the respective protocol. |
checksum | Optional checksum of the file. If provided, it will be used to verify that the file matches and downloads will be skipped if a local file with the same checksum already exists. |
description | Optional asset description, used in auto-generated docs. |
从Git仓库下载
如果提供了git代码块,资产将从给定的Git仓库下载。您可以下载任何您有权限访问的仓库。在底层实现中,这使用了Git的"sparse checkout"功能,因此您只会下载所需的文件而非整个仓库。
| 名称 | 描述 |
|---|---|
dest | The destination path to save the downloaded asset to (relative to the project directory), including the file name. |
git | repo: The URL of the repo to download from.path: Path of the file or directory to download, relative to the repo root. "" specifies the root directory.branch: The branch to download from. Defaults to "master". |
checksum | Optional checksum of the file. If provided, it will be used to verify that the file matches and downloads will be skipped if a local file with the same checksum already exists. |
description | Optional asset description, used in auto-generated docs. |
处理私有资产
对于许多项目来说,您正在使用的数据集和权重可能是公司内部数据,无法通过互联网获取。在这种情况下,您可以指定目标路径和校验值,并省略URL。当您的团队成员克隆并运行项目时,他们可以自行将文件放置在相应目录中。project assets命令会提醒您有关缺失文件和不匹配校验值的情况,从而确保其他人使用相同的数据运行您的项目。
Dependencies and outputs
在project.yml中定义的每个命令都可以选择性地定义依赖项和输出项的列表。这些是命令所需和创建的文件。
例如,一个用于训练管道的命令可能依赖于config.cfg以及训练和评估数据,
并且它将导出一个目录model-best,然后您可以在其他命令中重复使用该目录。
project.yml
如果您运行的命令依赖于缺失的文件,spaCy会显示错误。如果命令定义的依赖项和输出自上次运行以来未更改,则该命令将被跳过。这意味着您只需在需要时重新运行命令。命令还可以设置no_skip: true来确保永远不会被跳过——例如运行测试的命令。没有输出的命令也永远不会被跳过。要强制重新运行命令或工作流(即使没有任何更改),您可以设置--force标志。
请注意spacy project不会基于依赖项和输出编译任何依赖关系图,也不会自动重新运行之前的步骤。例如,如果您只运行依赖preprocess生成数据的train命令,而这些文件缺失时,spaCy会显示错误——它不会自动重新运行preprocess。如果您需要更高级的数据管理功能,请查看数据版本控制(DVC)集成。如果您计划将spaCy项目与DVC集成,也可以使用outputs_no_cache而非outputs来定义不会被缓存或跟踪的输出。
文件与目录结构
project.yml 可以定义项目中需要创建的 directories 列表,例如 assets、training、corpus 等目录。spaCy 会确保这些目录始终可用,因此您的命令可以对其进行读写操作。项目目录还将包含从项目模板复制的所有文件和目录,通过 spacy project clone 命令实现。以下是一个项目目录的示例:
示例项目目录
如果不想让项目创建目录,可以删除它并从project.yml中移除其条目——只需确保没有任何命令需要它。自定义模板可以使用它们需要的任何目录——项目唯一必需的文件是project.yml。
自定义脚本与项目
The project.yml lets you define any custom commands and run them as part of
your training, evaluation or deployment workflows. The script section defines
a list of commands that are called in a subprocess, in order. This lets you
execute other Python scripts or command-line tools. Let’s say you’ve written a
few integration tests that load the best model produced by the training command
and check that it works correctly. You can now define a test command that
calls into pytest, runs your tests and
uses pytest-html to export a test
report:
project.yml
将training/model-best添加到命令的deps中可以确保该文件可用。如果不可用,spaCy会显示错误且命令不会运行。设置no_skip: true意味着命令将始终运行,即使依赖项(训练好的管道)没有更改。这在此处是合理的,因为通常您不希望跳过测试。
编写自定义脚本
您的项目命令可以包含任何自定义脚本——基本上,任何您可以从命令行运行的内容。这里有一个使用typer的自定义脚本示例,用于快速简单地处理命令行参数,您可以通过project.yml来定义这些参数:
scripts/custom_evaluation.py
在您的project.yml中,您可以通过调用python scripts/custom_evaluation.py并传入函数参数来运行脚本。您还可以使用vars部分定义可重用变量,这些变量将在命令、路径和URL中被替换。在这个示例中,批量大小被定义为一个变量,将在脚本中替换${vars.batch_size}的位置。就像在训练配置中一样,您也可以在命令行中覆盖设置——例如使用--vars.batch_size。
project.yml
你也可以使用env部分来引用环境变量,并使它们的值对命令可用。这对于在命令行上覆盖设置和传递系统级设置非常有用。
project.yml
项目文档编写
当您的自定义项目准备就绪并希望与他人分享时,您可以使用spacy project document命令自动生成一个美观的Markdown格式README文件,该文件基于您的项目project.yml。它将列出项目中定义的所有命令、工作流和资源,并包含有关如何运行项目的详细信息,以及指向相关spaCy文档的链接,使其他人能够轻松开始使用您的项目。
在底层实现中,系统会添加隐藏标记来标识自动生成内容的起始和结束位置。这意味着您可以在自动生成内容的前后添加自定义内容,重新运行project document命令时只会更新自动生成的部分。这使得保持文档更新变得非常简单。
从您自己的仓库克隆
spacy project clone 命令允许您通过 --repo 选项自定义要克隆的代码库。它会调用 git,因此您可以克隆任何您有权访问的代码库,包括私有代码库。
一个有效的项目模板至少需要包含一个
project.yml文件。它还可以包含
其他文件,比如自定义脚本、
列出额外依赖项的requirements.txt文件、
训练配置和模型元模板,或者带有使用示例的Jupyter
笔记本。
远程存储
您可以使用project push命令将项目输出持久化到远程存储。这可以帮助您导出管道包、共享工作给团队,或缓存结果以避免重复工作。project pull命令会下载远程存储中存在但本地不可用的所有输出。
您可以在project.yml文件的remotes部分列出一个或多个远程存储,通过将字符串名称映射到存储URL。在底层,spaCy使用cloudpathlib与远程存储进行通信,因此您可以使用cloudpathlib支持的任何协议,包括S3、Google云存储以及本地文件系统,不过某些协议可能需要安装额外的依赖项。
project.yml
例如,假设您的project.yml中有以下命令:
project.yml
训练完成后,您需要运行project push来确保training/model-best输出结果保存到远程存储。spaCy随后会根据您的命令脚本和列出的依赖项(corpus/train、corpus/dev和config.cfg)构建一个哈希值,用于标识输出的执行上下文。然后它会计算training/model-best目录的MD5哈希值,并使用这三部分信息来构建存储URL。
如果您更改命令或其依赖项(例如通过编辑config.cfg文件来调整超参数),系统将计算出一个不同的创建哈希值,因此当您使用project push时,不会覆盖之前的文件。该系统甚至支持同一文件和相同上下文的多个输出,这种情况可能发生在训练过程非确定性时,或者当存在未在命令中体现的依赖项时。
总之,spacy project远程存储的设计旨在实现特定的权衡。优先考虑便捷性、正确性和避免数据丢失。您可以自由使用project push,因为您永远不会覆盖远程状态,也不需要想名称或版本号。但是,您需要自行管理远程存储的大小,并删除不再相关的文件。
集成
数据版本控制 (DVC)
训练语料库或预训练权重等数据资产是任何NLP项目的核心,但它们通常难以管理:您不能简单地将它们检入Git仓库进行版本控制和跟踪。如果您有多个相互依赖的步骤,比如生成训练数据的预处理步骤,您需要确保数据始终是最新的,并且为了安全起见,每次都要重新运行流程的所有步骤。
Data Version Control (DVC) 是一个独立的开源工具,它能像Git一样集成到您的工作流程中,为数据管道构建依赖关系图,并跟踪和缓存数据文件。如果您从外部源(如存储桶)下载数据,DVC可以判断资源是否已更改。它还可以根据输入是否发生变化来决定是否重新运行某个步骤。所有元数据都可以提交到Git仓库中,因此您始终能够复现实验。
要设置DVC,请安装该软件包并将您的spaCy项目初始化为Git和DVC仓库。您还可以 自定义DVC安装 以包含对Google云存储、S3、Azure、SSH等远程存储的支持。
spacy project dvc 命令会根据 project.yml 中定义的工作流创建一个 dvc.yaml 配置文件。每当您更新项目时,可以重新运行该命令来更新 DVC 配置。之后您可以像管理其他 DVC 项目一样管理 spaCy 项目,运行 dvc add 来添加和跟踪资源,以及运行 dvc repro 来重现工作流或单个命令。
Prodigy
Prodigy 是一款由我们开发的现代化标注工具,用于为机器学习模型创建训练数据。它开箱即用地集成了spaCy,并为各种NLP任务提供了多种不同的标注方案,无论是否包含模型循环。如果在您的项目中安装了Prodigy,您可以从project.yml启动标注服务器,实现数据开发和训练之间的紧密反馈循环。
以下示例展示了合并和导出使用Prodigy收集的NER标注数据,并训练spaCy管道的流程:
project.yml
train-curve配方是另一个可以纳入项目的实用工作流。它会使用不同比例的数据进行训练,例如25%、50%、75%和100%。根据经验法则,如果在最后阶段准确率持续提升,这可能表明收集更多同类标注数据有望进一步优化模型。
project.yml (节选)
您可以将相同的方法应用于各类项目和标注工作流程,包括 命名实体识别、 跨度分类、 文本分类、 依存句法分析、 词性标注或完全 自定义方案。您还可以使用spaCy 项目模板快速启动标注服务器,收集更多标注数据并将其添加到您的Prodigy数据集中。
Streamlit
Streamlit 是一个用于构建交互式数据应用的Python框架。spacy-streamlit 包可帮助您将spaCy可视化集成到Streamlit应用中,并快速搭建交互式管道探索演示。它包含完整的嵌入式可视化工具以及独立组件。
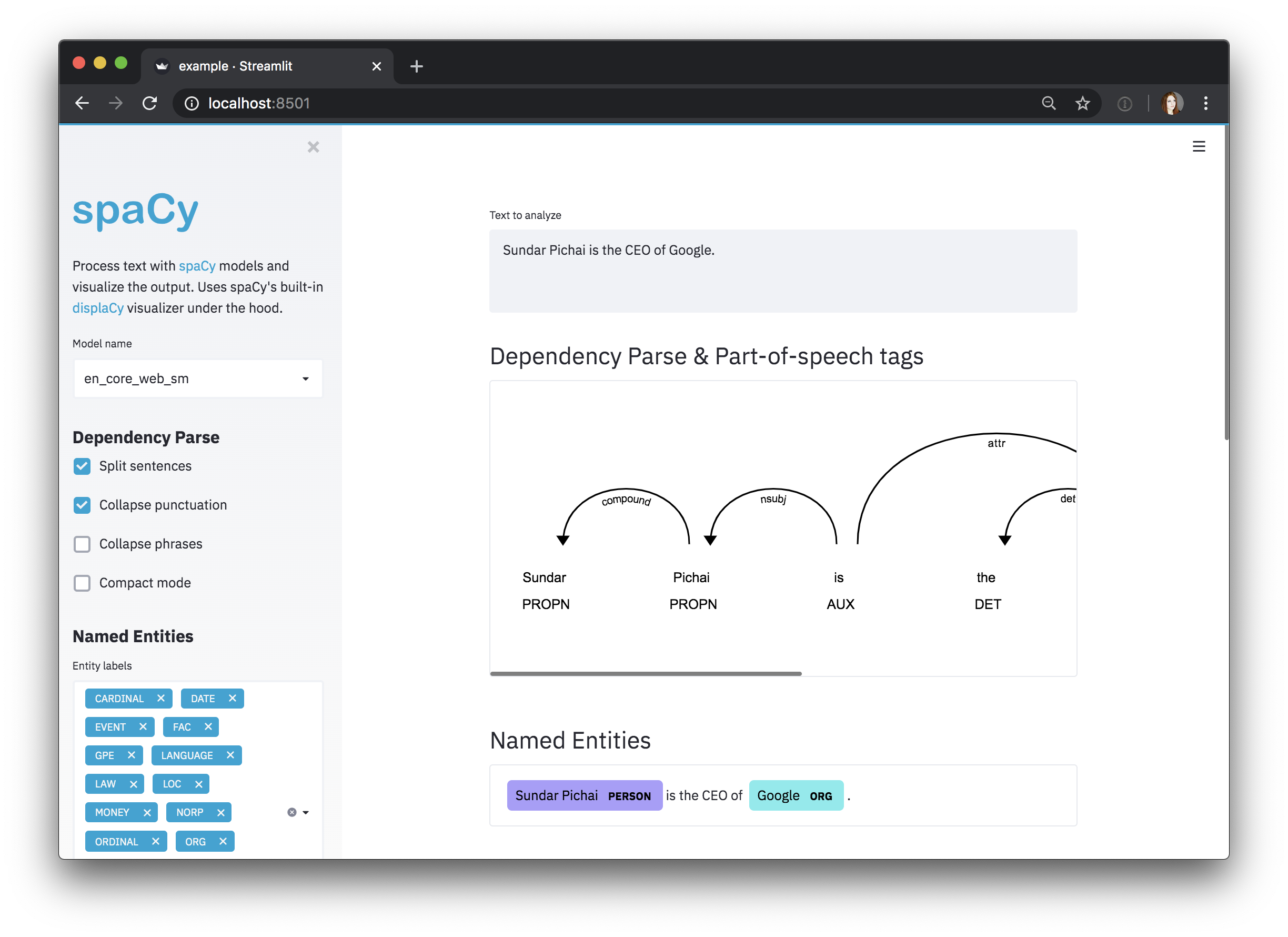
使用spacy-streamlit,您的项目可以轻松定义自己的脚本,通过最新训练的流程或选择的多个流程启动交互式可视化工具,以便比较它们的结果。
project.yml
以下脚本从project.yml中调用,并接收两个位置参数:一个逗号分隔的路径或包列表用于加载管道,以及一个用作默认文本的示例文本。
explosion/projects/v3/integrations/streamlit/scripts/visualize.py
FastAPI
FastAPI 是一个基于Python 类型提示的现代高性能框架,用于构建REST API。它已成为服务机器学习模型的流行库,您可以在spaCy项目中使用它快速部署训练好的管道,并通过REST API提供服务。
project.yml
模板中包含的脚本展示了一个简单的REST API,带有一个POST端点,该端点接收文本批次并返回预测结果批次,例如在文档中找到的命名实体。使用了类型提示和pydantic来定义预期的数据类型。
explosion/projects/v3/integrations/fastapi/scripts/main.py
Weights & Biases
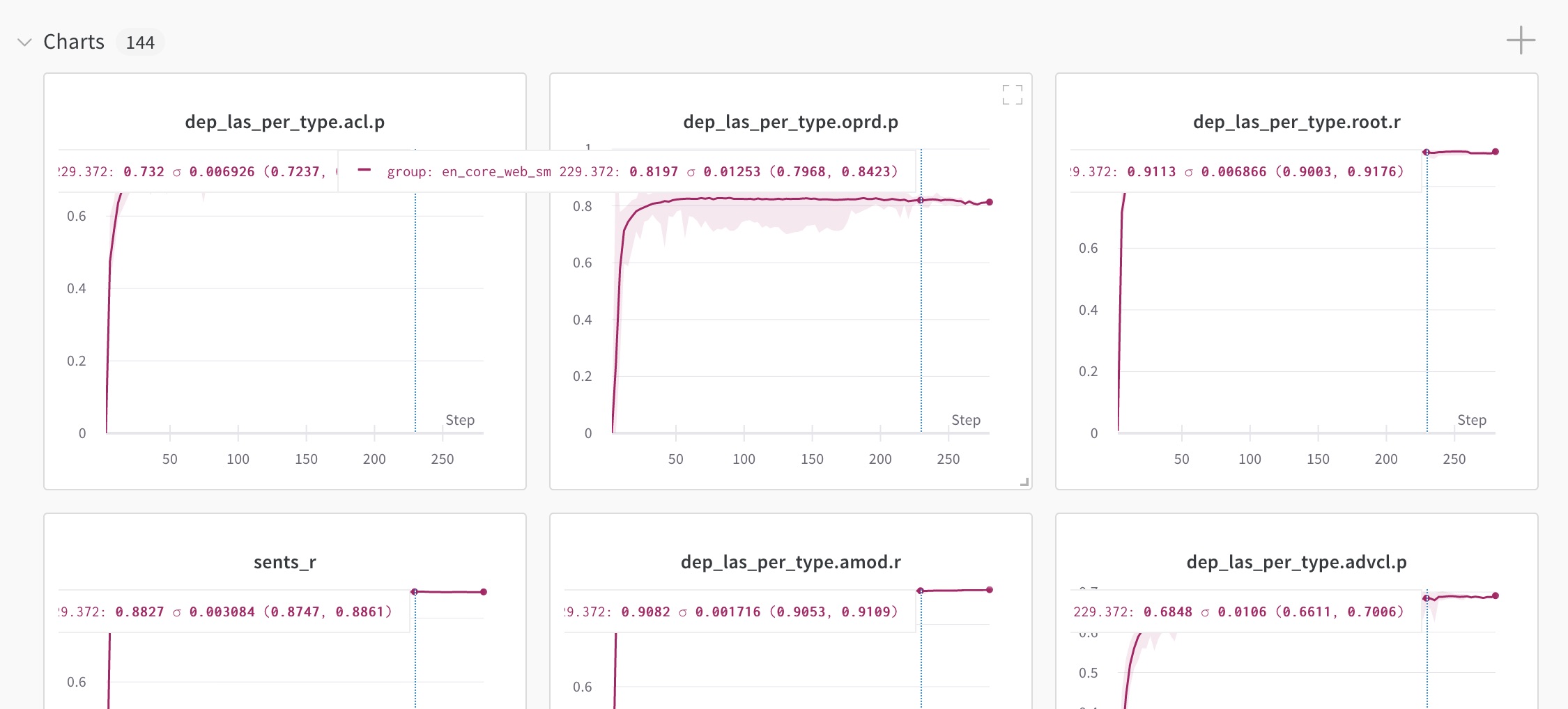
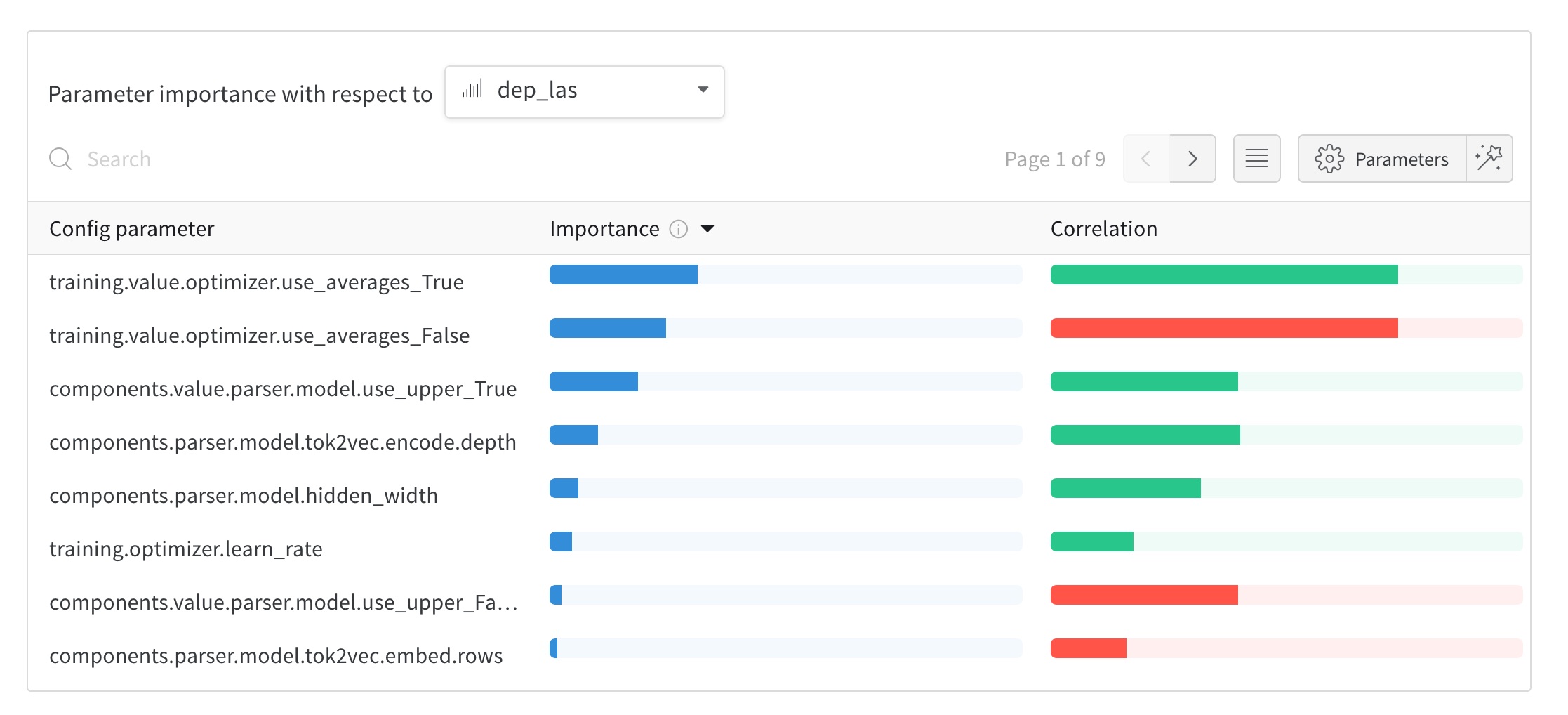
Weights & Biases 是一个流行的实验跟踪平台。spaCy通过内置的WandbLogger与其集成,您可以将其添加为训练config中的[training.logger]模块。每个步骤的结果将与完整的训练配置一起记录到您的项目中。这意味着每个超参数、注册函数名称和参数都将被跟踪,您将能够看到它们对结果的影响。
Hugging Face Hub
Hugging Face Hub 允许您上传模型并与他人分享。它将模型托管为基于Git的代码仓库,这些仓库是可以包含所有文件的存储空间。它开箱即用地支持版本控制、分支和自定义元数据,并提供基于浏览器的可视化工具以交互方式探索模型,同时还提供用于生产环境的API。spacy-huggingface-hub包在安装后会自动将huggingface-hub命令添加到您的spacy CLI中。
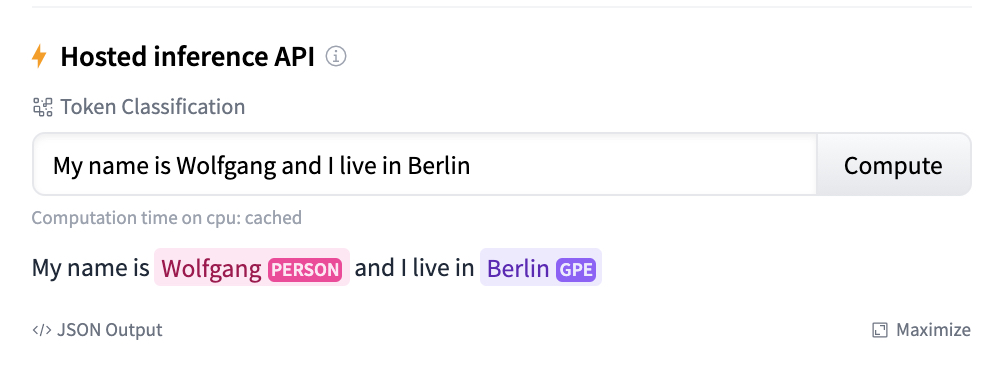
然后你可以上传任何使用spacy package打包的流程管线。请确保设置--build wheel参数来输出二进制.whl文件。上传工具会从流程管线包中读取所有元数据,包括自动生成的美观README.md文件和meta.json中提供的模型详细信息。如需示例,请查看我们已上传的spaCy流程管线。
上传后,您将看到管道包的实时URL,以及可通过pip install安装的模型wheel的直接URL。您还可以直接从浏览器交互式测试您的管道:
在您的project.yml中,可以添加一个命令将训练并打包好的管道上传到中心。您可以选择手动执行此步骤,或作为工作流的一部分自动执行。请确保在运行spacy package时设置--build wheel来为您的管道包构建wheel文件。
project.yml