STUMPY 文档#
![]()
![]()
![]()
![]()
![]()
![]()

树桩#
STUMPY 是一个强大且可扩展的 Python 库,能够有效地计算一种叫做 matrix profile 的东西,这只是一个学术术语,意为“自动识别您时间序列中每个(绿色)子序列对应的最近邻(灰色)。”:
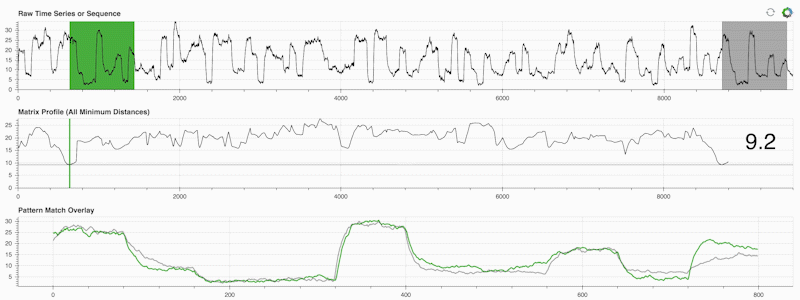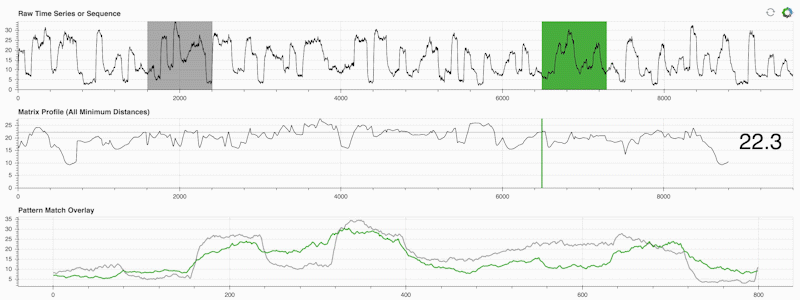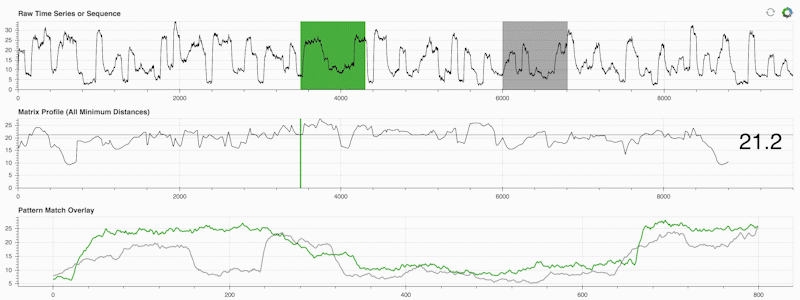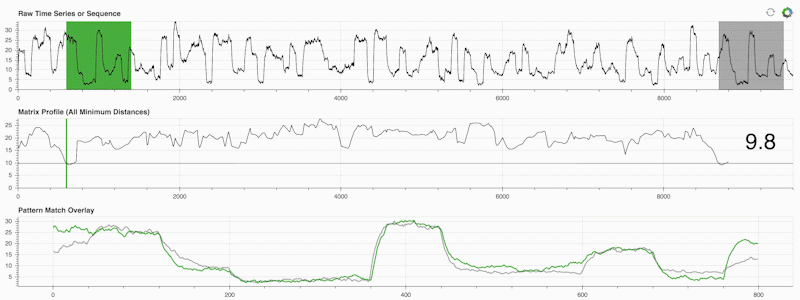
重要的是,一旦你计算了你的矩阵剖面(上面的中间面板),它可以用于各种时间序列数据挖掘任务,例如:
模式/主题(在较长时间序列中大致重复的子序列)发现
异常/新颖性(分布)发现
形状元发现
语义分割
流数据(在线数据)
快速近似矩阵剖面
时间序列链(时间排序的子序列模式集合)
用于总结长时间序列的片段
用于选择最佳子序列窗口大小的平面矩阵剖面
无论您是学者、数据科学家、软件开发者还是时间序列爱好者,STUMPY都很容易安装,我们的目标是让您更快地获得时间序列的洞察。有关更多信息,请参见documentation。
如何使用 STUMPY#
请查看我们的 API 文档 以获取可用函数的完整列表,并查看我们的详细 教程 以获取更全面的示例用例。下面,您将找到一些代码片段,快速演示如何使用 STUMPY。
典型用法(1维时间序列数据)使用 STUMP:
import stumpy
import numpy as np
if __name__ == "__main__":
your_time_series = np.random.rand(10000)
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy.stump(your_time_series, m=window_size)
通过 STUMPED 使用 Dask Distributed 进行一维时间序列数据的分布式处理:
import stumpy
import numpy as np
from dask.distributed import Client
if __name__ == "__main__":
with Client() as dask_client:
your_time_series = np.random.rand(10000)
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy.stumped(dask_client, your_time_series, m=window_size)
针对具有 GPU-STUMP 的一维时间序列数据的 GPU 使用情况:
import stumpy
import numpy as np
from numba import cuda
if __name__ == "__main__":
your_time_series = np.random.rand(10000)
window_size = 50 # Approximately, how many data points might be found in a pattern
all_gpu_devices = [device.id for device in cuda.list_devices()] # Get a list of all available GPU devices
matrix_profile = stumpy.gpu_stump(your_time_series, m=window_size, device_id=all_gpu_devices)
多维时间序列数据与 MSTUMP:
import stumpy
import numpy as np
if __name__ == "__main__":
your_time_series = np.random.rand(3, 1000) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile, matrix_profile_indices = stumpy.mstump(your_time_series, m=window_size)
使用 Dask Distributed 的分布式多维时间序列数据分析 MSTUMPED:
import stumpy
import numpy as np
from dask.distributed import Client
if __name__ == "__main__":
with Client() as dask_client:
your_time_series = np.random.rand(3, 1000) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile, matrix_profile_indices = stumpy.mstumped(dask_client, your_time_series, m=window_size)
带有锚定时间序列链 (ATSC)的时间序列链:
import stumpy
import numpy as np
if __name__ == "__main__":
your_time_series = np.random.rand(10000)
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy.stump(your_time_series, m=window_size)
left_matrix_profile_index = matrix_profile[:, 2]
right_matrix_profile_index = matrix_profile[:, 3]
idx = 10 # Subsequence index for which to retrieve the anchored time series chain for
anchored_chain = stumpy.atsc(left_matrix_profile_index, right_matrix_profile_index, idx)
all_chain_set, longest_unanchored_chain = stumpy.allc(left_matrix_profile_index, right_matrix_profile_index)
使用 快速低成本单能语义分割(FLUSS) 的语义分割:
import stumpy
import numpy as np
if __name__ == "__main__":
your_time_series = np.random.rand(10000)
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy.stump(your_time_series, m=window_size)
subseq_len = 50
correct_arc_curve, regime_locations = stumpy.fluss(matrix_profile[:, 1],
L=subseq_len,
n_regimes=2,
excl_factor=1
)
依赖项#
支持的Python和NumPy版本是根据NEP 29弃用政策来确定的。
在哪里获取它#
推荐使用 Conda 安装:
conda install -c conda-forge stumpy
假设您已安装numpy、scipy和numba,使用PyPI安装:
python -m pip install stumpy
要从源代码安装stumpy,请参阅文档中的说明。
文档#
为了充分理解和欣赏基本的算法和应用,您必须阅读原始的 publications。有关如何使用 STUMPY 的更详细示例,请查阅最新的 documentation 或探索我们的 hands-on tutorials。
性能#
我们测试了使用Numba JIT编译版本的代码在随机生成的不同长度的时间序列数据上计算精确矩阵轮廓的性能(即,np.random.rand(n)),以及不同的CPU和GPU硬件资源。
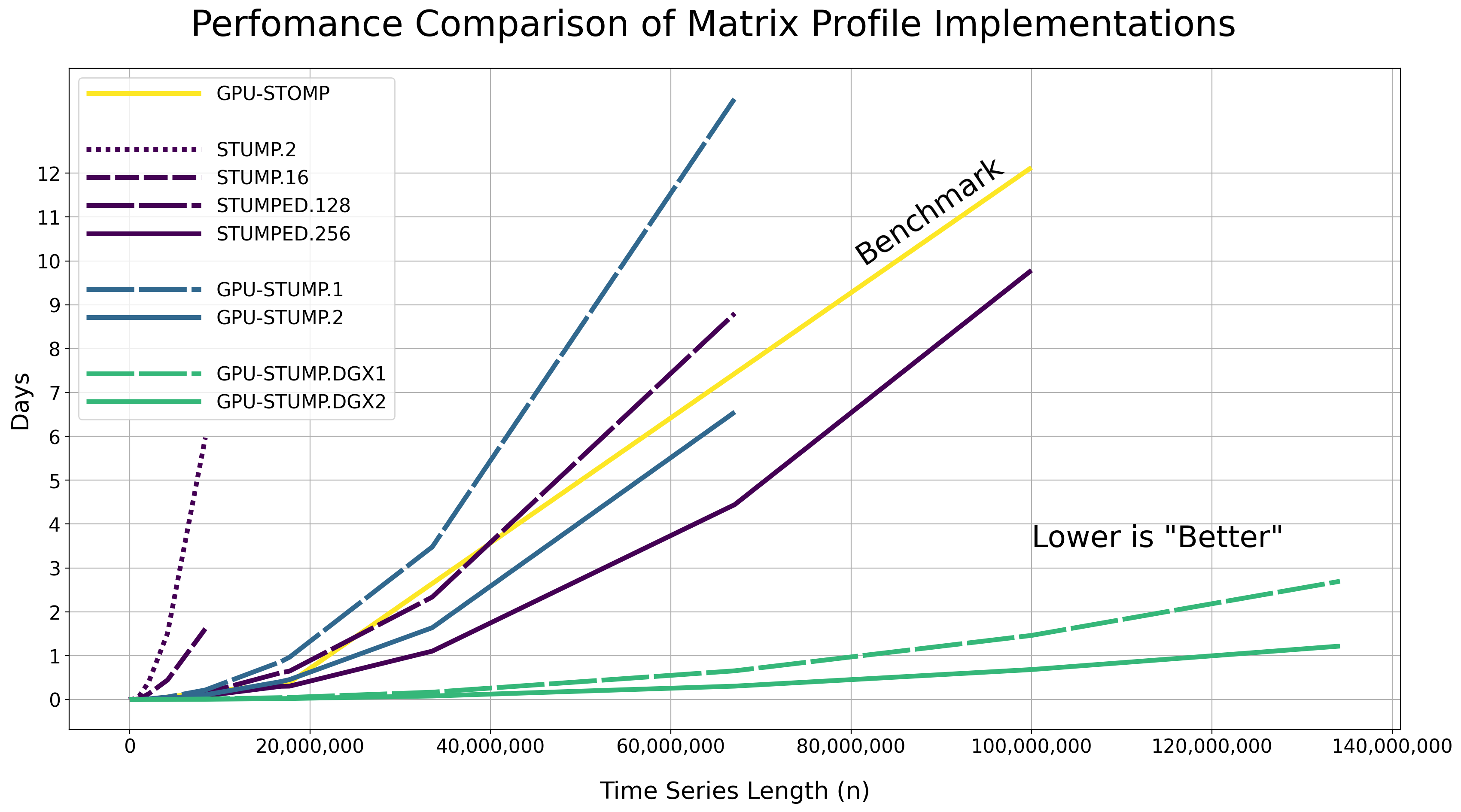
原始结果以小时:分钟:秒.毫秒的形式显示在下面的表格中,窗口大小为m = 50。请注意,这些报告的运行时间包括将数据从主机移动到所有GPU设备所花费的时间。您可能需要向右滚动表格以查看所有的运行时间。
i |
n = 2i |
GPU-STOMP |
STUMP.2 |
STUMP.16 |
STUMPED.128 |
STUMPED.256 |
GPU-STUMP.1 |
GPU-STUMP.2 |
GPU-STUMP.DGX1 |
GPU-STUMP.DGX2 |
|---|---|---|---|---|---|---|---|---|---|---|
6 |
64 |
00:00:10.00 |
00:00:00.00 |
00:00:00.00 |
00:00:05.77 |
00:00:06.08 |
00:00:00.03 |
00:00:01.63 |
NaN |
NaN |
7 |
128 |
00:00:10.00 |
00:00:00.00 |
00:00:00.00 |
00:00:05.93 |
00:00:07.29 |
00:00:00.04 |
00:00:01.66 |
NaN |
NaN |
8 |
256 |
00:00:10.00 |
00:00:00.00 |
00:00:00.01 |
00:00:05.95 |
00:00:07.59 |
00:00:00.08 |
00:00:01.69 |
00:00:06.68 |
00:00:25.68 |
9 |
512 |
00:00:10.00 |
00:00:00.00 |
00:00:00.02 |
00:00:05.97 |
00:00:07.47 |
00:00:00.13 |
00:00:01.66 |
00:00:06.59 |
00:00:27.66 |
10 |
1024 |
00:00:10.00 |
00:00:00.02 |
00:00:00.04 |
00:00:05.69 |
00:00:07.64 |
00:00:00.24 |
00:00:01.72 |
00:00:06.70 |
00:00:30.49 |
11 |
2048 |
NaN |
00:00:00.05 |
00:00:00.09 |
00:00:05.60 |
00:00:07.83 |
00:00:00.53 |
00:00:01.88 |
00:00:06.87 |
00:00:31.09 |
12 |
4096 |
NaN |
00:00:00.22 |
00:00:00.19 |
00:00:06.26 |
00:00:07.90 |
00:00:01.04 |
00:00:02.19 |
00:00:06.91 |
00:00:33.93 |
13 |
8192 |
无穷大 |
00:00:00.50 |
00:00:00.41 |
00:00:06.29 |
00:00:07.73 |
00:00:01.97 |
00:00:02.49 |
00:00:06.61 |
00:00:33.81 |
14 |
16384 |
NaN |
00:00:01.79 |
00:00:00.99 |
00:00:06.24 |
00:00:08.18 |
00:00:03.69 |
00:00:03.29 |
00:00:07.36 |
00:00:35.23 |
15 |
32768 |
NaN |
00:00:06.17 |
00:00:02.39 |
00:00:06.48 |
00:00:08.29 |
00:00:07.45 |
00:00:04.93 |
00:00:07.02 |
00:00:36.09 |
16 |
65536 |
无 |
00:00:22.94 |
00:00:06.42 |
00:00:07.33 |
00:00:09.01 |
00:00:14.89 |
00:00:08.12 |
00:00:08.10 |
00:00:36.54 |
17 |
131072 |
00:00:10.00 |
00:01:29.27 |
00:00:19.52 |
00:00:09.75 |
00:00:10.53 |
00:00:29.97 |
00:00:15.42 |
00:00:09.45 |
00:00:37.33 |
18 |
262144 |
00:00:18.00 |
00:05:56.50 |
00:01:08.44 |
00:00:33.38 |
00:00:24.07 |
00:00:59.62 |
00:00:27.41 |
00:00:13.18 |
00:00:39.30 |
19 |
524288 |
00:00:46.00 |
00:25:34.58 |
00:03:56.82 |
00:01:35.27 |
00:03:43.66 |
00:01:56.67 |
00:00:54.05 |
00:00:19.65 |
00:00:41.45 |
20 |
1048576 |
00:02:30.00 |
01:51:13.43 |
00:19:54.75 |
00:04:37.15 |
00:03:01.16 |
00:05:06.48 |
00:02:24.73 |
00:00:32.95 |
00:00:46.14 |
21 |
2097152 |
00:09:15.00 |
09:25:47.64 |
03:05:07.64 |
00:13:36.51 |
00:08:47.47 |
00:20:27.94 |
00:09:41.43 |
00:01:06.51 |
00:01:02.67 |
22 |
4194304 |
NaN |
36:12:23.74 |
10:37:51.21 |
00:55:44.43 |
00:32:06.70 |
01:21:12.33 |
00:38:30.86 |
00:04:03.26 |
00:02:23.47 |
23 |
8388608 |
无效数字 |
143:16:09.94 |
38:42:51.42 |
03:33:30.53 |
02:00:49.37 |
05:11:44.45 |
02:33:14.60 |
00:15:46.26 |
00:08:03.76 |
24 |
16777216 |
无穷大 |
无穷大 |
无穷大 |
14:39:11.99 |
07:13:47.12 |
20:43:03.80 |
09:48:43.42 |
01:00:24.06 |
00:29:07.84 |
非数字 |
17729800 |
09:16:12.00 |
非数字 |
非数字 |
15:31:31.75 |
07:18:42.54 |
23:09:22.43 |
10:54:08.64 |
01:07:35.39 |
00:32:51.55 |
25 |
33554432 |
NaN |
NaN |
NaN |
56:03:46.81 |
26:27:41.29 |
83:29:21.06 |
39:17:43.82 |
03:59:32.79 |
01:54:56.52 |
26 |
67108864 |
非数字 |
非数字 |
非数字 |
211:17:37.60 |
106:40:17.17 |
328:58:04.68 |
157:18:30.50 |
15:42:15.94 |
07:18:52.91 |
无效数字 |
100000000 |
291:07:12.00 |
无效数字 |
无效数字 |
无效数字 |
234:51:35.39 |
无效数字 |
无效数字 |
35:03:44.61 |
16:22:40.81 |
27 |
134217728 |
非数字值 |
非数字值 |
非数字值 |
非数字值 |
非数字值 |
非数字值 |
非数字值 |
64:41:55.09 |
29:13:48.12 |
硬件资源#
GPU-STOMP:这些结果是从原始的 Matrix Profile II 论文中复制的 - NVIDIA Tesla K80(包含2个GPU)并作为性能基准进行比较。
STUMP.2: stumpy.stump 在总共 2 个 CPU 上执行 - 2x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 处理器在单个服务器上使用 Numba 并行化,没有使用 Dask。
STUMP.16: stumpy.stump 在总共 16 个 CPU 上执行 - 16 个 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 处理器在单台服务器上通过 Numba 进行并行处理,没有使用 Dask。
困惑。128: stumpy.stumped 在总共128个CPU上执行 - 8个英特尔(R) 至强(R) 处理器 E5-2650 v4 @ 2.20GHz x 16台服务器,使用Numba进行并行处理,使用Dask分布式进行分发。
STUMPED.256: stumpy.stumped 使用256个CPU执行 - 8个Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz处理器 x 32台服务器,使用Numba并通过Dask Distributed进行并行化。
GPU-STUMP.1: stumpy.gpu_stump 使用 1 个 NVIDIA GeForce GTX 1080 Ti GPU 执行,每个块 512 个线程,200W 功率限制,使用 Numba 编译为 CUDA,并通过 Python 多进程实现并行化
GPU-STUMP.2: stumpy.gpu_stump 使用2台NVIDIA GeForce GTX 1080 Ti GPU 执行, 每个块512个线程,200W功率限制, 使用Numba编译为CUDA,并使用Python多处理进行并行化
GPU-STUMP.DGX1: stumpy.gpu_stump 使用了8个NVIDIA Tesla V100执行,块每个有512个线程,使用Numba编译为CUDA,并使用Python多进程进行并行化
GPU-STUMP.DGX2: stumpy.gpu_stump 使用16个NVIDIA Tesla V100执行,每个块512个线程,编译为CUDA并使用Python多进程并行化
运行测试#
测试写在 tests 目录中,并使用 PyTest 处理,需要 coverage.py 进行代码覆盖率分析。测试可以通过以下方式执行:
./test.sh
Python 版本#
STUMPY 支持 Python 3.9+,并且由于使用了 unicode 变量名/标识符,不兼容 Python 2.x。考虑到小型的依赖性,STUMPY 可能在旧版本的 Python 上工作,但这超出了我们的支持范围,我们强烈建议您升级到最新版本的 Python。
获取帮助#
首先,请检查讨论和问题在Github上,以查看您的问题是否已经得到解答。如果那里没有可用的解决方案,请随意打开一个新的讨论或问题,作者将努力在合理的时间内做出回应。
贡献#
我们欢迎 贡献 以任何形式!对文档的帮助,特别是扩展教程,总是受到欢迎。如要贡献,请 分叉项目,进行更改,并提交拉取请求。我们将尽力与您一起解决任何问题,并将您的代码合并到主分支。
引用#
如果您在科学出版物中使用了此代码库并希望引用它,请使用开放源代码软件杂志文章。
S.M. Law, (2019). STUMPY: 一个强大且可扩展的Python库,用于时间序列数据挖掘. 开源软件杂志, 4(39), 1504.
@article{law2019stumpy,
author = {Law, Sean M.},
title = {{STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining}},
journal = {{The Journal of Open Source Software}},
volume = {4},
number = {39},
pages = {1504},
year = {2019}
}
参考文献#
是的,Yeh, Chin-Chia Michael 等人 (2016) 矩阵简档 I:时间序列的所有配对相似性连接:一个包括模式、离群点和形状图的统一视图。ICDM:1317-1322。 Link
朱燕等。(2016) 矩阵剖面 II:利用新算法和GPU突破时间序列模式和连接的一亿个障碍。ICDM:739-748. Link
耶,金家迈克尔等(2017)矩阵简介 VI:有意义的多维模式发现。ICDM:565-574。 Link
朱、燕等人(2017)矩阵剖析 VII:时间序列链:时间序列数据挖掘的新原语。ICDM:695-704. Link
Gharghabi, Shaghayegh, 等(2017)矩阵轮廓 VIII:超人性能水平下的领域无关在线语义分割。ICDM:117-126. Link
朱燕等(2017)利用新算法和GPU突破时间序列模式和连接的十千万亿对比障碍。KAIS:203-236。 Link
朱燕等. (2018) 矩阵轮廓XI:SCRIMP++:交互速度下的时间序列模式发现. ICDM:837-846. Link
耶,Chin-Chia Michael 等人 (2018) 时间序列连接、模式、离群值和形状特征:利用矩阵配置文件的统一视角。 数据挖掘与知识发现:83-123。 Link
Gharghabi, Shaghayegh等(2018)“矩阵轮廓XII:MPdist:一种新的时间序列距离测量方法,以允许在更具挑战性的场景中进行数据挖掘。” ICDM:965-970. Link
Zimmerman, Zachary, et al. (2019) 矩阵轮廓 XIV:利用 GPU 扩展时间序列模式发现,以打破每日一千亿对比及更高。SoCC ‘19:74-86. Link
Akbarinia, Reza, 和 Betrand Cloez. (2019) 使用不同距离函数的有效矩阵概况计算. arXiv:1901.05708. Link
Kamgar, Kaveh, et al. (2019) 矩阵剖面 XV:利用时间序列一致性模式在时间序列集合中寻找结构。ICDM:1156-1161. Link