Apache Zeppelin 的 Submarine 解释器
Hadoop Submarine 是Hadoop 3.1版本中最新推出的机器学习框架子项目。它使得Hadoop能够支持Tensorflow、MXNet、Caffe、Spark等多种深度学习框架,为机器学习算法开发、分布式模型训练、模型管理以及模型发布提供了一个全功能的系统框架,结合Hadoop固有的数据存储和数据处理能力,使数据科学家能够更好地挖掘数据的价值。
一个深度学习算法项目需要数据采集、数据处理、数据清洗、交互式可视化编程调整参数、算法测试、算法发布、算法作业调度、离线模型训练、模型在线服务等多个流程和过程。Zeppelin 是一个基于网页的笔记本,支持交互式数据分析。您可以使用 SQL、Scala、Python 等来制作数据驱动的、交互式的、协作的文档。
您可以使用Zeppelin中的20多种解释器(例如:spark、hive、Cassandra、Elasticsearch、HBase等)在完成机器学习模型训练之前,在Hadoop中的数据收集、数据清洗、特征提取等数据预处理过程。
通过将submarine集成到zeppelin中,我们利用zeppelin的数据发现、数据分析和数据可视化及协作能力,来可视化机器学习模型训练期间的算法开发和参数调整结果。
架构

如上图所示,从系统架构的角度解释了Submarine如何通过Zeppelin开发和建模机器学习算法。
在安装和部署Hadoop 3.1+和Zeppelin之后,submarine将在YARN中为每个用户创建一个完全独立的Zeppelin Submarine解释器Docker容器。该容器包含Tensorflow的开发和运行时环境。Zeppelin服务器连接到YARN中的Zeppelin Submarine解释器Docker容器。允许算法工程师在Zeppelin Notebook中的Tensorflow独立环境中进行算法开发和数据可视化。
算法开发完成后,算法工程师可以直接将算法提交到YARN,在Zeppelin中进行离线传输训练,并通过Submarine的TensorBoard实时展示每个算法工程师的模型训练情况。
你不仅可以完成算法的模型训练,还可以使用Zeppelin中的二十多种解释器。完成模型的数据预处理,例如,你可以在算法笔记中通过Zeppelin中的Spark解释器执行数据提取、过滤和特征提取。
未来,您还可以使用Zeppelin即将推出的Workflow工作流编排服务。您可以在一个Note中完成Spark、Hive数据处理和Tensorflow模型训练。通过可视化等方式将其组织成工作流,并在生产环境中执行作业调度。
概述

如上图所示,从内部实现来看,Submarine 如何结合 Zeppelin 的机器学习算法开发和模型训练。
算法工程师使用Submarine解释器在Zeppelin中创建了一个Tensorflow笔记本(左图)。
需要注意的是,您需要在一个Note中完成整个算法的开发。
你可以在Note的某些段落中使用Spark进行数据预处理。
在其他段落的笔记本中使用Python进行Tensorflow的算法开发和调试,Submarine在YARN中为您创建了一个Zeppelin Submarine Interpreter Docker容器,该容器包含以下功能和服务:
- Shell 命令行工具:允许您在 Zeppelin Submarine Interpreter Docker 容器中查看系统环境,安装您需要的扩展工具或 Python 依赖项。
- Kerberos lib:允许您执行Kerberos身份验证并访问启用了Kerberos身份验证的Hadoop集群。
- Tensorflow 环境:允许您开发 tensorflow 算法代码。
- Python 环境:允许你开发 tensorflow 代码。
- 在Zeppelin中使用Note完成一个完整的算法开发。如果这个算法包含多个模块,你可以在Note的多个段落中编写不同的算法模块。每个段落的标题是算法模块的名称。段落的内容是这个算法模块的代码内容。
HDFS 客户端:Zeppelin Submarine 解释器会自动将你在笔记中编写的算法代码提交到 HDFS。
Submarine 解释器 Docker 镜像 这是 Submarine 为您提供的支持 Tensorflow(CPU 和 GPU 版本)的镜像文件。 并且安装了 Python 常用的算法库。 您还可以在 Submarine 提供的基础镜像上安装您所需的其他开发依赖项。
- 当你完成算法模块的开发时,你可以在Note中创建一个新的段落并输入
%submarine dashboard。Zeppelin将创建一个Submarine Dashboard。通过选择控制面板中的JOB RUN命令选项,可以将此Note中编写的机器学习算法作为JOB提交到YARN。创建一个Tensorflow模型训练Docker容器,该容器包含以下部分:
- Tensorflow 环境
HDFS客户端将自动从HDFS下载算法文件挂载到容器中,用于分布式模型训练。将算法文件挂载到容器的工作目录路径。
Submarine Tensorflow Docker 镜像 Submarine 提供了一个支持 Tensorflow(CPU 和 GPU 版本)的镜像文件。并且安装了 Python 常用的算法库。你也可以在 Submarine 提供的基础镜像上安装你需要的其他开发依赖。
| 名称 | 类别 | 描述 |
|---|---|---|
| %submarine | SubmarineInterpreter | 提供Apache Submarine仪表板的解释器 |
| %submarine.sh | SubmarineShellInterpreter | 提供Apache Submarine shell的解释器 |
| %submarine.python | PySubmarineInterpreter | 提供Apache Submarine的Python解释器 |
潜艇外壳
在Zeppelin中使用Submarine Interpreter创建Note后,如果需要,您可以向Note添加一个段落。使用%submarine.sh标识符,您可以使用Shell命令在Submarine Interpreter Docker容器上执行各种操作,例如:
- 查看容器中的Python版本
- 查看容器的系统环境
- 自行安装所需的依赖项
- 使用kinit进行Kerberos认证
- 在容器中使用Hadoop进行HDFS操作等。
潜艇 Python
您可以在Note中添加一个或多个段落。使用%submarine.python标识符在Python中编写Tensorflow的算法模块。
潜艇仪表盘
在使用%submarine.python编写Tensorflow算法后,您可以在Note中添加一段文字。进入%submarine仪表板并执行它。Zeppelin将创建一个Submarine仪表板。
通过Submarine仪表板,您可以进行Submarine的所有操作控制,例如:
用法:显示Submarine的命令描述,以帮助开发者定位问题。
刷新:Zeppelin 将清除您在仪表板中的所有输入。
Tensorboard:您将被重定向到由Submarine为每个用户创建的Tensorboard WEB系统。通过Tensorboard,您可以实时查看Tensorflow模型训练的实时状态。
命令
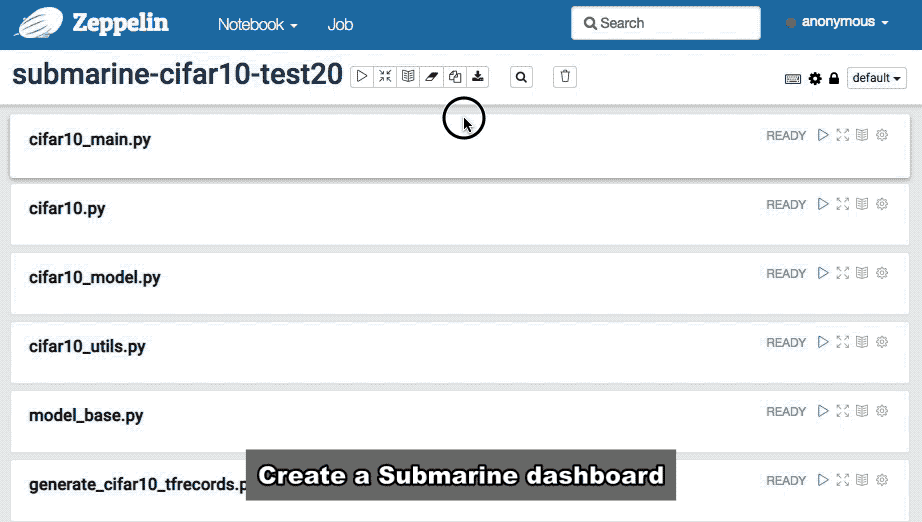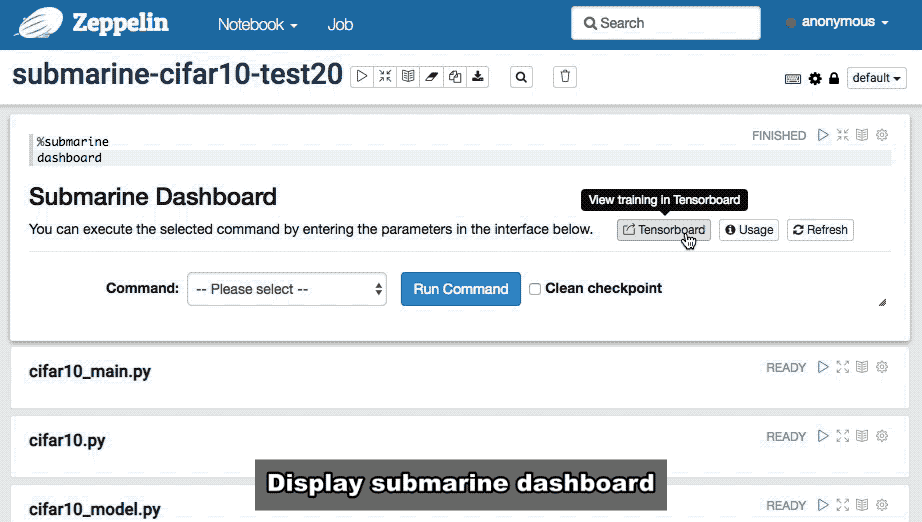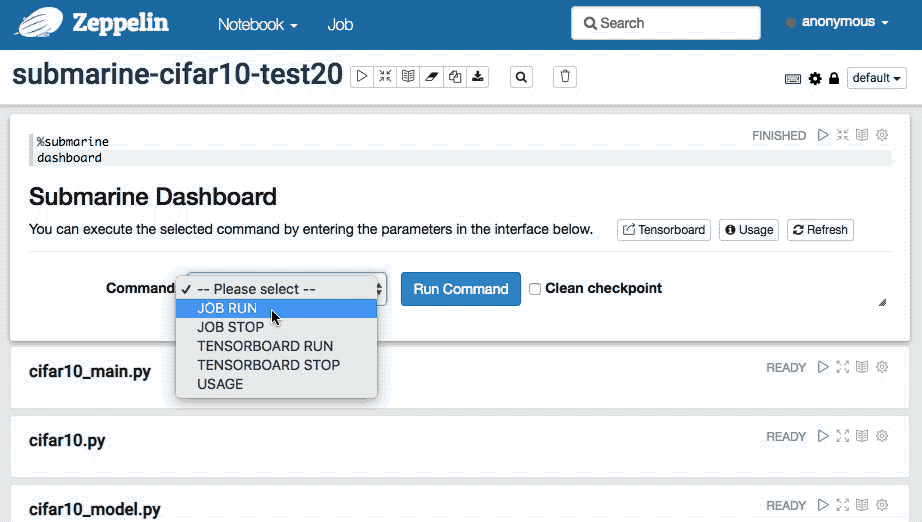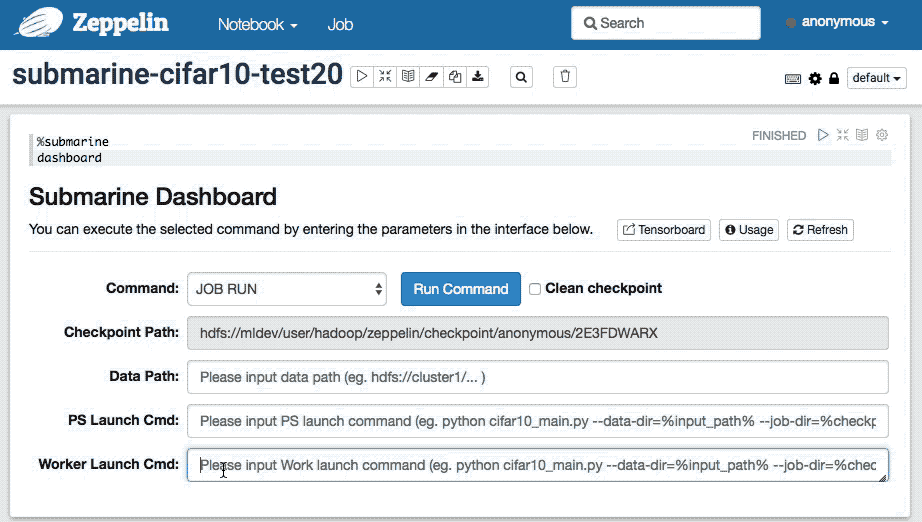
- JOB RUN:选择
JOB RUN将显示用于提交 JOB 的参数输入界面。
| 名称 | 描述 |
|---|---|
| 检查点路径 | Submarine 为每个用户的 Tensorflow 训练笔记设置了一个独立的检查点路径。保存了该笔记历史的训练数据,用于训练模型数据的输出,Tensorboard 使用此路径中的数据来展示模型。用户无法修改它。例如:`hdfs://cluster1/...`,检查点路径的环境变量名称为 `%checkpoint_path%`,你可以在 `PS Launch Cmd` 和 `Worker Launch Cmd` 中使用 `%checkpoint_path%` 来代替数据路径中的输入值。 |
| 输入路径 | 用户指定Tensorflow算法的数据目录。仅支持启用HDFS的目录。数据路径的环境变量名称为`%input_path%`,您可以在`PS启动命令`和`Worker启动命令`中使用`%input_path%`代替数据路径中的输入值。 |
| PS Launch Cmd | Tensorflow Parameter services launch command,例如:`python cifar10_main.py --data-dir=%input_path% --job-dir=%checkpoint_path% --num-gpus=0 ...` |
| Worker Launch Cmd | Tensorflow Worker services launch command,例如:`python cifar10_main.py --data-dir=%input_path% --job-dir=%checkpoint_path% --num-gpus=1 ...` |
任务停止
您可以选择执行
JOB STOP命令。停止已提交并正在运行的Tensorflow模型训练任务TensorBoard 启动
您可以选择执行
TENSORBOARD START命令来创建您的TENSORBOARD Docker容器。停止TENSORBOARD
您可以选择执行
TENSORBOARD STOP命令来停止并销毁您的TENSORBOARD Docker容器。
- 运行命令:执行您选择的动作命令
- 清理检查点:选择此选项将在每次
JOB RUN执行前清除此笔记检查点路径中的数据。
配置
Zeppelin Submarine 解释器提供了以下属性来自定义 Submarine 解释器
| 属性名称 | 属性值 | 描述 |
|---|---|---|
| DOCKER_CONTAINER_TIME_ZONE | Etc/UTC | 设置容器中的时区 | |
| DOCKER_HADOOP_HDFS_HOME | /hadoop-3.1-0 | 以下3个镜像中的Hadoop路径(SUBMARINE_INTERPRETER_DOCKER_IMAGE、tf.parameter.services.docker.image、tf.worker.services.docker.image) | |
| DOCKER_JAVA_HOME | /opt/java | 以下3个镜像中的JAVA路径(SUBMARINE_INTERPRETER_DOCKER_IMAGE、tf.parameter.services.docker.image、tf.worker.services.docker.image) | |
| HADOOP_YARN_SUBMARINE_JAR | Zeppelin服务器上安装的Hadoop-3.1+版本中Submarine JAR包的路径 | | |
| INTERPRETER_LAUNCH_MODE | local/yarn | 在本地或YARN上运行Submarine解释器实例,本地主要用于Submarine解释器的开发和调试,YARN模式用于生产环境 | |
| SUBMARINE_HADOOP_CONF_DIR | 设置HADOOP-CONF路径以支持多个Hadoop集群环境 | |
| SUBMARINE_HADOOP_HOME | 在Zeppelin服务器上安装的Hadoop-3.1+以上路径 | |
| SUBMARINE_HADOOP_KEYTAB | 启用Kerberos认证的Hadoop集群的Keytab文件路径 | |
| SUBMARINE_HADOOP_PRINCIPAL | 启用Kerberos认证的Hadoop集群的keytab文件的PRINCIPAL信息 | |
| SUBMARINE_INTERPRETER_DOCKER_IMAGE | 在INTERPRETER_LAUNCH_MODE=yarn时,Submarine使用此镜像创建Zeppelin Submarine解释器容器,为用户创建算法开发环境。 | | |
| docker.container.network | YARN的Docker网络名称 | |
| machinelearing.distributed.enable | 是否使用分布式模式的模型训练JOB RUN提交 | |
| shell.command.timeout.millisecs | 60000 | Submarine解释器容器中shell命令的执行超时设置 |
| submarine.algorithm.hdfs.path | 将使用Submarine解释器开发的基于机器的算法保存为文件到HDFS | |
| submarine.yarn.queue | root.default | Submarine 提交模型训练的 YARN 队列名称 |
| tf.checkpoint.path | Tensorflow 检查点路径,每个用户将在此路径下使用用户名创建用户的检查点二级路径。用户提交的每个算法将使用笔记ID创建检查点三级路径(用户的Tensorboard使用此路径中的检查点数据进行可视化显示) | |
| tf.parameter.services.cpu | 当Submarine提交模型分布式训练时,应用于Tensorflow参数服务的CPU核心数量 | |
| tf.parameter.services.docker.image | Submarine 在提交模型分布式训练时为 Tensorflow 参数服务创建镜像 | |
| tf.parameter.services.gpu | 当Submarine提交模型分布式训练时,应用于Tensorflow参数服务的GPU核心 | |
| tf.parameter.services.memory | 2G | 当Submarine提交模型分布式训练时,Tensorflow参数服务请求的内存资源 |
| tf.parameter.services.num | Submarine 用于提交模型分布式训练所使用的 Tensorflow 参数服务数量 | |
| tf.tensorboard.enable | true | 为每个用户创建一个单独的Tensorboard |
| tf.worker.services.cpu | 在提交模型训练时,Submarine 为 Tensorflow 工作服务提交模型资源 | |
| tf.worker.services.docker.image | Submarine 在提交模型分布式训练时为 Tensorflow worker 服务创建镜像 | |
| tf.worker.services.gpu | Submarine 在提交模型训练时为 Tensorflow 工作节点服务提交 GPU 资源 | |
| tf.worker.services.memory | 在提交模型训练时,Submarine 为 Tensorflow 工作节点服务提交模型资源 | |
| tf.worker.services.num | Submarine 用于提交模型分布式训练的 Tensorflow 工作服务数量 | |
| yarn.webapp.http.address | http://hadoop:8088 | YARN web界面地址 |
| zeppelin.interpreter.rpc.portRange | 29914 | 你需要在SUBMARINE_INTERPRETER_DOCKER_IMAGE配置镜像中导出此端口。用于Zeppelin服务器和Submarine解释器容器之间的RPC通信 |
| zeppelin.ipython.grpc.message_size | 33554432 | Submarine解释器容器中IPython grpc的消息大小设置 |
| zeppelin.ipython.launch.timeout | 30000 | Submarine 解释器容器中的 IPython 执行超时设置 |
| zeppelin.python | python | Submarine解释器容器中python的执行路径 |
| zeppelin.python.maxResult | 10000 | 从Submarine解释器容器返回的Python执行结果的最大数量 |
| zeppelin.python.useIPython | false | 目前不支持IPython,必须为false |
| zeppelin.submarine.auth.type | simple/kerberos | Hadoop是否开启了kerberos认证? |
Docker 镜像
Docker 镜像文件存储在 zeppelin/scripts/docker/submarine 目录中。
潜艇解释器 CPU 版本
潜艇解释器 GPU 版本
tensorflow 1.10 & hadoop 3.1.2 cpu 版本
tensorflow 1.10 & hadoop 3.1.2 gpu 版本
变更日志
0.1.0 (Zeppelin 0.9.0) :
- 支持分布式或独立的TensorFlow模型训练。
- 支持本地运行的潜艇解释器。
- 支持运行YARN的submarine解释器。
- 支持在YARN-3.3.0上使用Docker,计划与较低版本的yarn兼容。
错误与联系
- Submarine 解释器 BUG 如果您遇到此解释器的错误,请在 ZEPPELIN-3856 上创建一个子 JIRA 票证。
- Submarine 运行问题 如果您遇到 Submarine 运行时的问题,请在 apache-hadoop-submarine 上创建一个 ISSUE。
- YARN Submarine BUG 如果您遇到Yarn Submarine的bug,请在SUBMARINE上创建一个JIRA工单。
依赖
- YARN Submarine 目前需要在 Hadoop 3.3+ 上运行
- hadoop submarine 团队的 git 仓库的 hadoop 版本会定期提交到 hadoop 的代码仓库中。
- hadoop submarine 团队的 git 仓库版本将比 hadoop 版本发布周期更快。
- 您可以使用hadoop submarine团队的git仓库中的hadoop版本。
- Submarine 运行时环境 你可以使用 Submarine-installer https://github.com/apache/submarine,部署 Docker 和网络环境。
更多
Hadoop Submarine 项目: https://submarine.apache.org/ Youtube Submarine 频道: https://www.youtube.com/channel/UC4JBt8Y8VJ0BW0IM9YpdCyQ