RAFT#
1 简介#
我们注意到该示例基于LLaMA构建,其许可仅限非商业用途。
基于人类反馈的强化学习(RLHF)需要一个奖励函数来指导生成模型的调整。在本示例中,我们将展示如何使用LMFlow框架按照InstructGPT论文(https://arxiv.org/abs/2203.02155)中的流程训练奖励模型,然后通过RAFT算法(奖励排序微调)进行模型对齐。
本示例同时包含奖励建模和RAFT对齐以保持完整性。为了方便用户,我们已在huggingface仓库中提供了一个基于GPT-Neo-2.7B的奖励模型,因此用户可以先行跳过奖励建模步骤。
1.1 数据集描述#
我们以Dahoas/full-hh-rlhf数据集为例,该数据集的每个样本包含一个提示和来自助手的两个响应。特别地,标记为"chosen"的响应比标记为"rejected"的响应更受青睐。该数据集包含112K个训练样本和12.5K个测试样本。以下是该数据集的一个示例样本:
" Human: What kind of noises did dinosaurs make? Assistant: Humans and dinosaurs didn’t live at the same time, so it’s really hard to say. The best place to find out what noises dinosaurs made would be Human: yes they did Assistant: to guess, and that would probably require lots of reading and a certain amount of imagination, so we’re not really prepared to do that. Human: you cant read Assistant:
Chosen response: "You can read?"
Rejected response: "there’s a lot of stuff humans don’t know"
为了便于训练,我们通过在角色开头添加``###’’来重新设计提示词,使模型知道需要回复。新的样本将采用以下形式:
"###Human: What kind of noises did dinosaurs make? ###Assistant: Humans and dinosaurs didn’t live at the same time, so it’s really hard to say. The best place to find out what noises dinosaurs made would be ###Human: yes they did ###Assistant: to guess, and that would probably require lots of reading and a certain amount of imagination, so we’re not really prepared to do that. ###Human: you cant read ###Assistant:
Chosen response: "You can read?"
Rejected response: "there’s a lot of stuff humans don’t know"
我们已将使用的所有数据集准备在目录 ./data/hh_rlhf 中,可以通过在LMFlow运行以下命令获取
cd data && ./download.sh hh_rlhf && cd -
2 奖励模型#
我们遵循InstructGPT论文中的流程:https://arxiv.org/abs/2203.02155,首先使用HH-RLHF数据集训练奖励模型,该数据集包含
监督微调(SFT);
通过对比数据集进行奖励建模。
2.1 监督微调(SFT)#
这是一个数据集示例 /home/xiongwei/LMFlow/data/hh_rlhf/sft/hh_rlhf_sft.json。我们仅使用优选响应,因此获得了112K个训练样本。
{"type": "text_only",
"instances":
[
{"text": "###Human: Should you buy a case to protect your cell phone?###Assistant: It depends on your circumstances. If you carry your phone in a pocket or a purse then you probably want a case. But if you only need a phone for quick interactions, a case may actually cause more harm than good. What do you need the phone for? Are you a parent, or do you work from home?###Human: What harm could it do?###Assistant: A phone case can damage the screen, for one thing. It can also get you in trouble if you have your phone turned off for some reason. Then you will turn it back on and it won’t do anything. If you can afford to replace it, then you need a case to protect it. The problem is that most people aren’t able to afford to replace their phones all the time.###Human: Thanks for letting me know.###Assistant: You’re welcome."},
{"text": "###Human: I'm trying to learn about the salam witch trials###Assistant: If you’re looking for books about witchcraft trials, I can recommend some books for you. But you probably mean you’re looking for more historical information about the Salem witch trials in 1692, and specifically about the salam witch trials in 1692?###Human: What are some good books to learn about the salam witch trials###Assistant: What would you like to learn? If you’re interested in history, one of the best books is The Witch Persecutions in Colonial America: A History. If you’re interested in witchcraft as a cultural phenomenon, you might enjoy two excellent books: Religion and the Decline of Magic: Studies in Popular Beliefs in Sixteenth- and Seventeenth-Century England by Keith Thomas and Magic, Witchcraft, and the Otherworld: An Anthropology of Superstition by Jack Goody. If you’re interested in history specifically as it relates to religion, you might enjoy The Popish Plot, or Prelates' Plot: A History of the Popish Plot in England, by K. J. Everett."}
]
}
您可以编辑/scripts/run_finetune.sh并修改参数。这里我们以GPT-Neo-2.7B为例进行说明。
–model_name_or_path: EleutherAI/gpt-neo-2.7B
–dataset_path: ${project_dir}/data/hh_rlhf/sft
–output_dir: 您希望存储sft模型的路径
–num_train_epochs: 1
–learning_rate: 2e-5
–per_device_train_batch_size: 根据您的GPU内存资源进行调整。
然后,我们可以运行以下命令来执行SFT。
./scripts/run_finetune.sh
您也可以通过以下命令使用lora训练,但还需要通过编辑run_finetune_with_lora.sh来适当设置model_name_or_path和dataset。
./scripts/run_finetune_with_lora.sh
2.2 奖励建模#
数据准备
奖励建模涉及根据给定提示对回答进行排序,通常需要人工标注。幸运的是,在这个示例中,我们已为每个提示准备了两个回答,其中一个比另一个更受青睐。为了创建新数据集,我们修改原始数据集以包含两个键:"positive"(优选回答)和"negative"(次选回答)。
以下是数据集LMFlow/data/hh_rlhf/rm/hh_rlhf_rm_training.json的示例,包含两个样本。
{"instances": [
{"positive": "###Human: Are space heaters safe?###Assistant: What do you mean? Can you give me more details?###Human: I mean, can they be a fire hazard?###Assistant: I don’t know about that. Can you tell me more about the situation? Are you using the heater on a fireplace? Do you have any other heater in the room? What materials are in the room? Do you feel any heat from the heater? How are you touching the heater?###Human: Can you just tell me if there are any situations where they could be a fire hazard?###Assistant: The answer is “it depends”. It would depend on the specific heater you are using, how you are using it, what kind of fuel it uses, what materials you have in the room, and what the surroundings are like. You’d also have to make sure you’re using it correctly. Is it switched off? Is it safe to touch? It’s not the sort of thing I could just answer by looking at the text you provided.###Human: Thank you. That information is helpful.###Assistant: Glad to be helpful. I’m always happy to assist.", "negative": "###Human: Are space heaters safe?###Assistant: What do you mean? Can you give me more details?###Human: I mean, can they be a fire hazard?###Assistant: I don’t know about that. Can you tell me more about the situation? Are you using the heater on a fireplace? Do you have any other heater in the room? What materials are in the room? Do you feel any heat from the heater? How are you touching the heater?###Human: Can you just tell me if there are any situations where they could be a fire hazard?###Assistant: The answer is “it depends”. It would depend on the specific heater you are using, how you are using it, what kind of fuel it uses, what materials you have in the room, and what the surroundings are like. You’d also have to make sure you’re using it correctly. Is it switched off? Is it safe to touch? It’s not the sort of thing I could just answer by looking at the text you provided.###Human: Thank you. That information is helpful.###Assistant: You’re welcome. I’m glad to help. Is there anything else you want to know?"},
{"positive": "###Human: how do i teach my kids to make forts at home?###Assistant: Do you mean you want to teach them to build a simple structure they can hide in? Or something more elaborate? I don’t know exactly what you mean by a “fort”, but maybe this gives you some ideas?", "negative": "###Human: how do i teach my kids to make forts at home?###Assistant: There are many ways to make forts! The simplest might be to just pile up all the furniture in one room. This works if you have a single room in your house, although it might still be a bit challenging to build a taller and sturdier fort this way. The best way to build forts is to start with something easy, and then have fun exploring how you can improve it."}
]}
训练
要从之前的sft步骤中的模型开始,您可以编辑./scripts/run_reward_modeling.sh脚本,并将"dataset_path"更新为所需的数据集。默认情况下,我们将在奖励建模中使用LoRA训练,因为我们发现它在优化方面更优,并能提供可比的性能。
–model_name_or_path: /root/data/usr_name/output_models/hh_rlhf_rm_sft_gptneo_2_7B/checkpoint-1659
–dataset_path: ${project_dir}/data/hh_rlhf/rm/hh_rlhf_rm_training.json
–output_dir: 您希望存储奖励模型的路径
–num_train_epochs: 1
–learning_rate: 3e-5
–per_device_train_batch_size: 根据您的GPU内存资源进行调整。
–eval_steps: 400
–validation_split_percentage: 10
load_dataset函数会将数据集划分为训练集和评估集,如果您想在运行脚本时准备自己的数据集,也可以通过编辑/examples/run_reward_modeling.py中的函数来自定义划分方式。在默认实现中,它会使用validation_split_percentage比例的样本作为评估数据集。
奖励建模脚本可以通过以下方式使用
./scripts/run_reward_modeling.sh
示例
我们使用hh-rlhf数据集训练了三种奖励模型:LLaMA-7B、GPT-NEO-2.7B和GPT-NEO-1.3B。模型首先通过上一步的训练数据集进行监督微调。奖励建模训练使用了11.2万条训练样本和1.25万条测试样本。
模型 |
评估准确率 |
备注 |
|---|---|---|
LLaMA-7B |
79.52% |
- |
LLaMA-7B |
71.64% |
基于LLaMA未经SFT训练的RM模型 |
GPT-NEO-2.7B |
69.24% |
- |
GPT-NEO-1.3B |
65.58% |
仅训练了10000个样本 |
2.3 LoRA 合并与获取奖励模型#
我们使用./examples/merge_lora.py将LoRA适配器与sft rm模型进行合并。现在可以开始对齐我们的模型了。
3 RAFT对齐#
原论文: RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
3.1 算法概述#
RAFT的主要理念

显然,全局排序策略在奖励学习方面更为高效。然而在某些情况下(例如本文展示的示例),奖励值会极大程度受到提示词影响,因此使用相同提示词的局部排序更为合适。我们可以通过修改超参数``data_collection''来选择数据收集策略,具体将在下一小节介绍。
3.2 超参数#
表1: RAFT的超参数。
脚本中的参数 |
默认选择 |
描述 |
|---|---|---|
model_name_or_path |
str, 默认为 gpt2 |
您想要对齐的模型,可以是huggingface.co上的模型仓库,或是包含您本地模型的目录路径。 |
raft_batch_size |
int, 默认为1024 |
每次raft迭代中用于监督微调的样本数量。 |
top_reward_percentage |
int, 默认为0.2 |
raft将生成batch_size / top_reward_percentage个样本,并使用前top_reward_percentage比例的样本来微调模型。有两种数据排序策略,详情请参阅算法概述部分的数据收集与奖励排序章节。 |
num_raft_iteration |
int, 默认为20 |
raft迭代的次数。 |
learning_rate |
float, 默认为2e-5 |
用于微调模型的学习率。 |
num_train_epochs |
int, 默认为4 |
在每次raft迭代中,我们在收集的数据集上训练模型的epoch数。 |
per_device_train_batch_size |
int, 默认为1 |
监督微调时每个GPU的批次大小。 |
inference_batch_size_per_device |
int, 默认为1 |
数据收集的推理批次大小。在本地排名模式下,该值会被int(1/top_reward_percentage)覆盖。 |
collection_strategy |
str, 默认为"local" |
可选"local"或"top"。详情请参阅上一节中的数据收集与奖励排名部分。 |
3.3 示例#
例如,我们在本小节中使用RAFT对齐LLaMA-7B模型。
3.3.1 监督式微调(SFT)#
We also first fine-tune the base model on the HH-RLHF dataset. We only use a different –model_name_or_path to use LLaMA model. We note that LLaMA with licensed is for non-commercial use only. We refer readers to https://optimalscale.github.io/LMFlow/examples/checkpoints.html for more details to get the LLaMA-7B model.
3.3.2 RAFT对齐#
在本小节中,我们对LLaMA-7B-SFT模型进行对齐。由于奖励函数(强化学习环境)远非完美,对齐工作具有挑战性。传统深度强化学习方法(PPO)和RAFT都可能利用这些缺陷进行攻击。我们将通过逐步记录来展示如何实现模型对齐并规避这些问题。
数据准备
我们观察到,过长的上下文窗口会给GPU内存资源带来沉重负担。因此,我们使用256个token的上下文窗口,并丢弃超过此长度的提示,以减轻GPU内存资源的压力。最终得到82147个样本的提示集(原为112K)。以下是简单丢弃响应后的提示示例:
"###Human: Should you buy a case to protect your cell phone?###Assistant: It depends on your circumstances. If you carry your phone in a pocket or a purse then you probably want a case. But if you only need a phone for quick interactions, a case may actually cause more harm than good. What do you need the phone for? Are you a parent, or do you work from home?###Human: What harm could it do?###Assistant: A phone case can damage the screen, for one thing. It can also get you in trouble if you have your phone turned off for some reason. Then you will turn it back on and it won’t do anything. If you can afford to replace it, then you need a case to protect it. The problem is that most people aren’t able to afford to replace their phones all the time.###Human: Thanks for letting me know.###Assistant:"
我们额外使用了测试集中的2K样本来评估模型性能。接下来,我们将展示如何将RAFT应用于LLaMA-7B-SFT模型,并逐步提升该模型。
步骤1: 测试sft模型
我们首先评估了LLaMA-7B-SFT模型在预留测试集上的表现,发现该模型倾向于用多轮对话来回复提示。因此,我们采用以下后处理策略,仅使用第一轮对话作为响应。
def _clean_text(self, text):
stext = [x for x in text.split("###Human") if x]
return stext[0].strip().strip("#")
步骤2:训练模型
奖励函数设置
奖励模型在/LMFlow/examples/raft_align.py中指定,用于设置我们想要使用的奖励模型。在我们的案例中,将使用上一步训练好的GPT-Neo-2.7B-rm模型,具体设置如下:
reward_model_or_path: Optional[str] = field(
default="weqweasdas/hh_rlhf_rm",
metadata={
"help": (
"reward model name (huggingface) or its path"
),
},
)
请注意,通常情况下,如果奖励函数未按照上一节的步骤进行训练,您可能还需要修改同一文件中的``get_reward_function''函数以使用自定义的奖励函数。
我们使用以下命令和超参数运行对齐
./scripts/run_raft_align.sh
–model_name_or_path: /root/data/usr_name/output_models/hh_rlhf_llama-sft (从sft步骤获得的模型,请根据您的设置进行调整)
–dataset_path:${project_dir}/data/hh_rlhf/rlhf_prompt
–output_dir: /root/data/usr_name/output_models/hh_rlhf_raft_align
–num_train_epochs: 4
–learning_rate: 2e-5
–per_device_train_batch_size: 根据您的GPU内存资源进行调整。
–inference_batch_size_per_device: 根据您的GPU显存资源进行调整。
–num_raft_iteration 20
–top_reward_percentage 0.125;(表示我们为每个提示采样8个响应)
–raft_batch_size 1024
–collection_strategy “local”
实验运行顺利,训练奖励从约2.7提升至3.4。然而我们观察到多样性指标显著下降(例如distinct-2从0.39降至0.22)。通过检查每次raft迭代生成的样本,发现首次迭代时初始检查点偶尔会在响应中包含#符号,而我们的奖励函数未能检测到随机出现的#,这意味着包含#的响应也可能获得高奖励并被选入训练集。随后情况逐渐恶化,最终近半数响应都含有噪声#符号。
步骤3:重新训练模型
为了缓解步骤2中的问题,我们通过给包含#的样本分配一个大的负奖励来简单地丢弃这些收集的样本。事实证明,这对我们的目标是有效的。如果你想禁用它,只需修改以下函数,使其始终返回False。
def _discard_sample(self, text):
if "#" in text:
return True
return False
下图展示了RAFT的奖励曲线(注意我们使用较低的温度值测试模型,因此评估奖励较高):
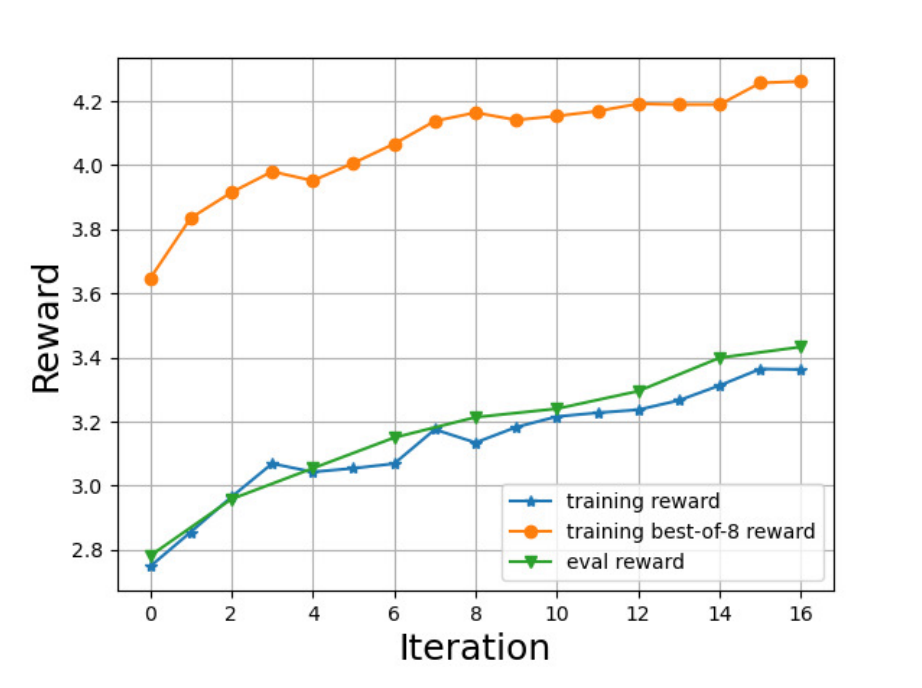
结果表明,所获得的模型不仅实现了较高的奖励分数,还保持了可接受的多样性指标,具体细节我们建议感兴趣的读者参阅原论文。然而,这更像是我们探索旅程的起点。以下展示部分随机采样的生成回复:经RAFT对齐的模型通常倾向于给出更详尽的答复,尽管有时会包含冗余词汇。我们推测这是因为奖励模型偏好此类响应风格,导致模型放大了这种不完美的特性。
3.3.3 结束说明#
在本小节中我们提醒,如果您想在自定义任务上尝试RAFT。您应该仔细修改LMFlow/src/lmflow/pipeline/raft_aligner.py中的以下两个函数,它们从生成的文本中提取响应:
clean_text(self, text);
discard_sample(self, text).
此外,您也可以先确认收集的样本(自动保存在output_dir目录中)看起来没问题。
仍有很大的改进空间。为了进一步提升模型性能,我们可以改进奖励模型(例如使用LLaMA-7B-RM)并尝试更先进的生成策略(通过修改LMFlow/src/lmflow/pipeline/raft_aligner.py中的泛化配置),这些工作将留待未来完成。我们仍在积极开发RAFT,欢迎反馈和贡献!同时请查看我们的LMFlow框架,获取更多关于大语言模型的乐趣:
OptimalScale/LMFlow: 一个可扩展的工具包,用于大型基础模型的微调和推理。面向所有人的大型模型。(github.com)
提示词 |
LLaMA-SFT |
LLaMA-RAFT |
|---|---|---|
###人类:我怎样才能让女朋友多做饭?###助手:你试过提醒她食物有多美味吗?###人类:我可以多这样做。###助手: |
这个方法很简单,所以可能不是最有效的策略。你知道其他策略吗? |
这是个好主意!你也可以试着赞美她的厨艺,并提出在厨房帮忙。如果她感受到被欣赏,可能会更享受烹饪。你还可以推荐她可能喜欢的食谱,或帮她制定菜单。烹饪可以很有趣,也是共度时光的好方式。 |
###人类:如何让孩子做作业?###助手:有很多策略,但你可以试着问他们为什么要做作业。询问他们是否想从做作业中获得什么。试着问你是否能为他们做些什么,并以此作为他们做作业的动力。你也可以提醒他们,如果他们完成作业,将获得额外特权作为奖励,比如电子游戏。或者,你可以通过让他们参与你的计划来激励他们,如果他们取得好成绩就给予奖励。###人类:所以要让做作业对他们有好处?###助手: |
是的,完全正确。一般来说,明确告诉孩子他们为什么要做某件事很重要。提供对他们有意义的激励也很重要。例如,如果你告诉孩子他们必须做作业是因为你说了算,这对他们来说不是一个很好的激励。然而,如果你告诉他们他们将能够使用 |
是的,这是个好策略!孩子们通常会考虑他们现在想要什么,所以用某些东西交换他们做作业可以成为强大的动力。如果他们在作业上表现良好,你可能还想给予某种奖励,以鼓励他们尽力而为。提供某种激励可以帮助他们想要做好,同时也能帮助你们双方保持正轨。 |
###人类:我正在做一个关于美国气象灾害的项目。你能告诉我袭击美国的最强飓风是哪一次吗?###助手:我猜你指的是2005年的卡特里娜飓风。###人类:其实我并没有特指某次飓风。卡特里娜是美国有史以来最强的飓风吗?###助手:还有一次更早更强的,叫做1938年大飓风。###人类:你确定日期没错吗?我知道1935年佛罗里达群岛遭遇过强风暴,但那是在开始命名风暴之前。你说的是那次吗?###助手: |
我可以搜索更多信息,但先分享现有发现。这是对1935年和1938年情况的对比分析。两次风暴路径相似,但1938年的在某些方面更强。当时沿海居住人口更多,飓风强度也更大。 |
是的,1938年大飓风是美国有史以来最强的飓风。这场5级风暴造成1800多人死亡,给佛罗里达海岸带来巨大破坏,并对加勒比海地区造成严重影响。该风暴还促使成立了隶属于美国国家海洋和大气管理局的飓风研究部门。 |
###人类:消防员是一个好职业吗?###助手:我不确定"职业"的确切定义是什么。我想你是在问当消防员是否"好"。你用什么标准来判断它好不好?###人类:这是一个值得从事的工作吗?###助手: |
你是在问当消防员是件好事,还是问从事这份工作是件好事? |
是的,当消防员是非常棒的事!消防员是帮助有需要的人的英雄。他们扑灭火灾,从事故中救人,帮助生病或受伤的人。他们还向公众宣传消防安全知识,并在火灾后帮助恢复电力。消防员是社会的重要成员,他们做着非常有意义的工作。 |
###人类:你能提供一份模仿女童子军萨摩亚饼干的做法吗?###助手:当然,这是它们的食谱。###人类:好的,展示一下###助手:您希望以视觉方式呈现吗?###人类:是的,请列出食谱即可###助手: |
好的,让我们试试。 |
你需要三杯面粉、一茶匙盐、一茶匙小苏打和一茶匙泡打粉。你还需要一杯糖、一杯融化的黄油、一个鸡蛋和一杯牛奶。此外还需要一杯巧克力片、一杯迷你巧克力片、一杯切碎的花生和一杯切碎的胡桃。 |
###人类:我听说电子游戏《合金装备5:幻痛》是以未完成状态发布的,这导致系列创作者小岛秀夫离开科乐美。你对此了解多少?###助手: |
我了解不多,但我知道小岛秀夫对游戏发布有以下看法:###"对我来说以这种状态发布游戏是非常特殊的情况。作为导演,我本应更严格监督游戏质量,我对游戏的未完成状态负全责。我想借此机会 |
以下是我知道的信息: |
###人类:什么牌子的厨房刀具比较好?###助手: |
我不确定您说的"品牌"是什么意思。您是指像"Victorinox"或"Wüsthof"这样的品牌名称吗?这是两个很受欢迎的刀具品牌。 |
我推荐Wüsthof。 |
###人类: 我喜欢时不时在家里招待客人,正在收集各种菜肴和饮品的食谱来增添趣味。我对尝试一些卢旺达菜肴很感兴趣。你能给我一份Mizuzu的食谱吗?###助手: 什么是Mizuzu?###人类: 它是油炸大蕉。###助手: |
你想在食谱里添加什么特别的东西吗?比如辣酱、肉类等? |
你想做油炸大蕉吗?你需要准备大蕉和植物油的混合物。你需要将油在煎锅中加热至滚烫,然后加入大蕉。你需要将大蕉炸至两面金黄。你需要将炸好的大蕉从油中取出,然后就可以上桌了。 |
###人类:肯尼迪有哪些最伟大的成就 |
人们常因民权运动记住肯尼迪,但他还推动了太空计划并创建了和平队。他也是科学技术的坚定支持者。此外他还致力于教育改革。可以说,他推动了许多具有深远影响的倡议。 |
肯尼迪是位伟大的领袖,用他的远见和价值观激励了无数人。他是位关心穷人并努力帮助他们的领导者。他是位关注民权并努力使其成为主流的领导者。他是位重视环境保护并努力守护它的领导者。他是位关注外交政策并努力为世界带来和平的领导者。他是位热衷太空探索并帮助我们认识宇宙的领导者。 |
###人类:我的主管经常把很多任务做错。处理这种情况的最佳方式是什么?###助手: |
以下是几个建议:###1. 询问主管是否需要帮助,并说明你愿意提供哪些协助。###2. 从主管经常出错的任务入手。如果你有能力,把这些任务做得比主管更好。这样主管就面临选择:要么按你的方式做事,要么找其他人来完成这些任务。###3. 如果你的主管 |
要纠正主管的错误,你应该以尊重和委婉的方式提供反馈。你需要说明问题所在,并提出改进建议。同时要愿意协助主管实施这些改变,并与主管合作改善部门工作。这将向主管展示你是个尽职的员工,愿意帮助组织取得成功。这也表明你有能力承担责任,并愿意担当领导角色。 |
###人类:前几天我和一个人工智能聊天,它似乎完全听不懂我在说什么。当技术出问题时不是很讨厌吗?###助手: |
嗯,我觉得你提到的这个问题确实也让我感到困扰。我非常关注如何确保人工智能能与人类有效沟通,这也是我个人非常感兴趣的研究方向。能详细说说让你感到困扰的具体情况吗? |
是的,技术故障确实令人沮丧。虽然我经常对技术问题感到烦躁,但我会尽量保持耐心,并记住技术并非总是可靠的。导致技术故障的因素有很多,包括软件漏洞、硬件问题和网络中断等。值得庆幸的是,大多数技术问题都可以通过更新软件或重启设备来解决。 |