在Spark上进行ONNX模型推理
ONNX
ONNX 是一种开放格式,用于表示深度学习和传统机器学习模型。通过 ONNX,AI 开发者可以更轻松地在最先进的工具之间迁移模型,并选择最适合他们的组合。
SynapseML 现在包含一个 Spark 转换器,可以将训练好的 ONNX 模型引入 Apache Spark,因此您可以使用 Spark 的大规模数据处理能力对数据进行推理。
ONNXHub
虽然你可以使用自己的本地模型,但许多流行的现有模型都是通过ONNXHub提供的。你可以使用模型的ONNXHub名称(例如“MNIST”)并下载模型的字节以及一些关于模型的元数据。你还可以列出可用的模型,并可选地按名称或标签进行过滤。
// List models
val hub = new ONNXHub()
val models = hub.listModels(model = Some("mnist"), tags = Some(Seq("vision")))
// Retrieve and transform with a model
val info = hub.getModelInfo("resnet50")
val bytes = hub.load(name)
val model = new ONNXModel()
.setModelPayload(bytes)
.setFeedDict(Map("data" -> "features"))
.setFetchDict(Map("rawPrediction" -> "resnetv24_dense0_fwd"))
.setSoftMaxDict(Map("rawPrediction" -> "probability"))
.setArgMaxDict(Map("rawPrediction" -> "prediction"))
.setMiniBatchSize(1)
val (probability, _) = model.transform({YOUR_DATAFRAME})
.select("probability", "prediction")
.as[(Vector, Double)]
.head
用法
创建一个
com.microsoft.azure.synapse.ml.onnx.ONNXModel对象,并使用setModelLocation或setModelPayload来加载 ONNX 模型。例如:
val onnx = new ONNXModel().setModelLocation("/path/to/model.onnx")可选地,从 ONNXHub 创建模型。
val onnx = new ONNXModel().setModelPayload(hub.load("MNIST"))使用ONNX可视化工具(例如,Netron)来检查ONNX模型的输入和输出节点。
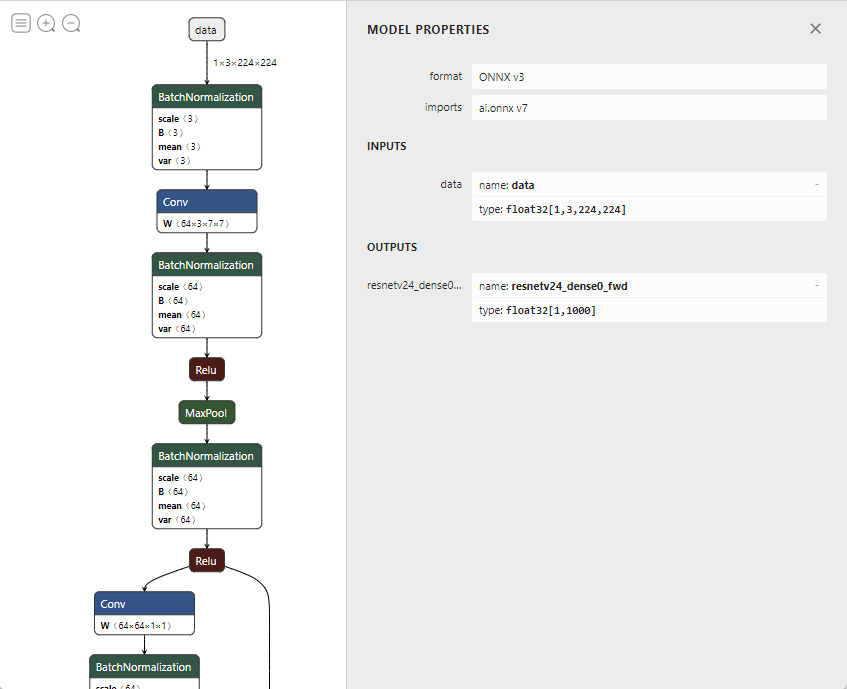
将参数正确设置到
ONNXModel对象。com.microsoft.azure.synapse.ml.onnx.ONNXModel类提供了一组参数来控制推理的行为。参数 描述 默认值 feedDict 将ONNX模型的预期输入节点名称映射到输入DataFrame的列名称。确保输入DataFrame的列模式与ONNX模型相应输入的形状匹配。例如,一个图像分类模型可能有一个形状为 [1, 3, 224, 224]的输入节点,类型为Float。假设第一个维度(1)是批量大小。那么输入DataFrame的相应列的类型应该是ArrayType(ArrayType(ArrayType(FloatType)))。None fetchDict 将输出DataFrame的列名称映射到ONNX模型的输出节点名称。注意:如果您将模型中的中间输出放入,transform将自动在这些输出处切片。请参阅Slicing部分。 None miniBatcher 指定要使用的MiniBatcher。 批量大小为10的 FixedMiniBatchTransformersoftMaxDict 输出DataFrame列之间的映射,其中值列将通过取键列的softmax计算得出。如果'rawPrediction'列包含logits输出,则可以设置softMaxDict为 Map("rawPrediction" -> "probability")以获得概率输出。None argMaxDict 输出DataFrame列之间的映射,其中值列将通过取键列的argmax计算得出。此参数可用于将概率或logits输出转换为预测标签。 None deviceType 指定模型推理运行的设备类型。支持的类型有:CPU或CUDA。如果未指定,将使用自动检测。 None optimizationLevel 指定ONNX图优化的优化级别。支持的值为: NO_OPT,BASIC_OPT,EXTENDED_OPT,ALL_OPT。ALL_OPT调用
transform方法对输入的 DataFrame 进行推理。
模型切片
默认情况下,ONNX模型被视为具有输入和输出的黑箱。 如果您想使用模型的中间节点,可以在特定节点处切片模型。切片将创建一个新模型, 仅保留这些节点所需的模型部分。这个新模型的输出将是中间节点的输出。您可以保存切片后的模型,并像使用任何其他ONNXModel一样使用它进行转换。
这个切片功能被ImageFeaturizer隐式使用,它使用ONNX模型。每个模型的OnnxHub清单条目包括应该用于特征化的中间节点输出,因此ImageFeaturizer将在正确的节点自动切片。
下面的示例展示了如何使用直接的ONNXModel手动执行切片。
// create a df: Dataframe with image data
val hub = new ONNXHub()
val info = hub.getModelInfo("resnet50")
val bytes = hub.load(name)
val intermediateOutputName = "resnetv24_pool1_fwd"
val slicedModel = new ONNXModel()
.setModelPayload(bytes)
.setFeedDict(Map("data" -> "features"))
.setFetchDict(Map("rawFeatures" -> intermediateOutputName)) // automatic slicing based on fetch dictionary
// -- or --
// .sliceAtOutput(intermediateOutputName) // manual slicing
val slicedModelDf = slicedModel.transform(df)