Autologging
自动日志记录
MLflow 自动日志记录 允许您记录指标、参数和模型,而无需显式的日志语句。 SynapseML 支持库中每个模型的自动日志记录。
要启用SynapseML的自动日志记录:
- 下载这个定制的log_model_allowlist文件并将其放在您的代码可以访问的地方。 例如:
- 在 Synapse 中
wasb://@ .blob.core.windows.net/PATH_TO_YOUR/log_model_allowlist.txt - 在Databricks中
/dbfs/FileStore/PATH_TO_YOUR/log_model_allowlist.txt。
- 设置spark配置
spark.mlflow.pysparkml.autolog.logModelAllowlistFile为你的log_model_allowlist.txt文件的路径。 - 在你的训练代码之前调用
mlflow.pyspark.ml.autolog()以启用所有支持模型的自动日志记录。
注意:
- 如果您想支持不在log_model_allowlist文件中的PySpark模型的自动记录,您可以将这些模型添加到文件中。
- 如果您已启用自动日志记录,则不要显式编写
with mlflow.start_run(),因为这可能会导致一个模型有多个运行或多个模型共享一个运行。
以Databricks中的配置过程为例
- 通过
%pip install mlflow安装最新版本的MLflow - 通过点击Databricks UI上的文件/上传数据按钮,将您自定义的
log_model_allowlist.txt文件上传到dbfs。 - 按照此文档设置集群Spark配置
spark.mlflow.pysparkml.autolog.logModelAllowlistFile /dbfs/FileStore/PATH_TO_YOUR/log_model_allowlist.txt
- 在您的训练代码执行之前运行以下行。
mlflow.pyspark.ml.autolog()
您可以通过提供适当的参数来自定义自动记录的工作方式。
- 通过MLFlow UI的
Experiments选项卡查找您的实验结果。
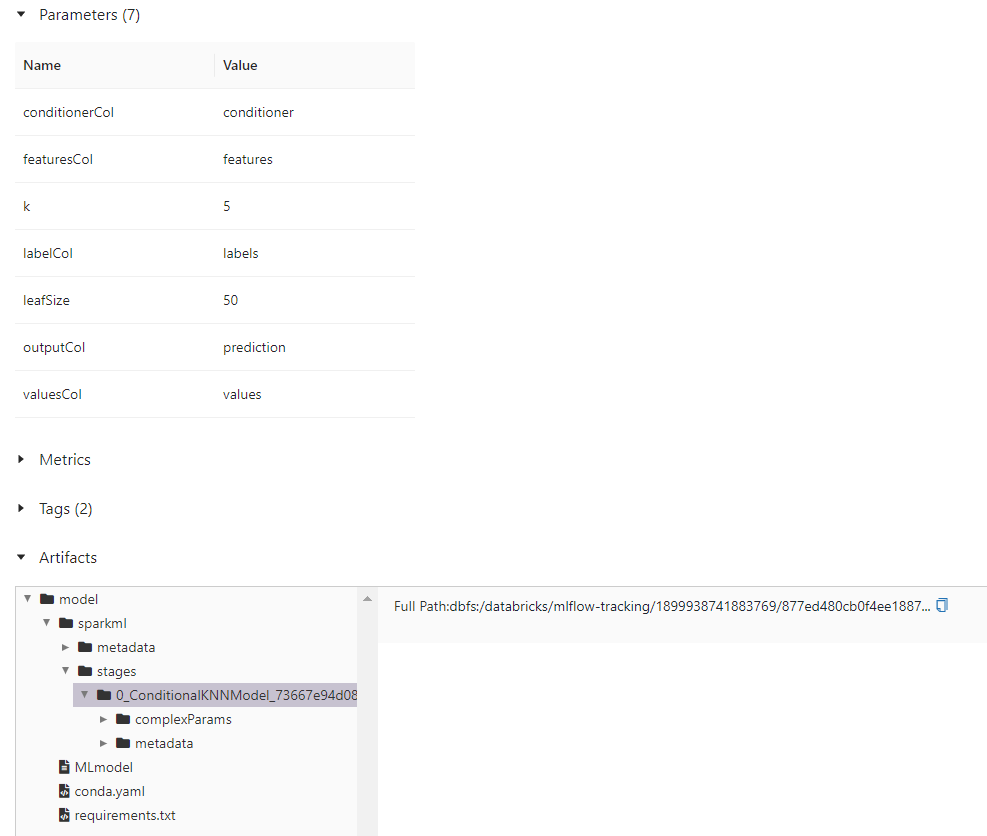
ConditionalKNNModel 示例
from pyspark.ml.linalg import Vectors
from synapse.ml.nn import *
df = spark.createDataFrame([
(Vectors.dense(2.0,2.0,2.0), "foo", 1),
(Vectors.dense(2.0,2.0,4.0), "foo", 3),
(Vectors.dense(2.0,2.0,6.0), "foo", 4),
(Vectors.dense(2.0,2.0,8.0), "foo", 3),
(Vectors.dense(2.0,2.0,10.0), "foo", 1),
(Vectors.dense(2.0,2.0,12.0), "foo", 2),
(Vectors.dense(2.0,2.0,14.0), "foo", 0),
(Vectors.dense(2.0,2.0,16.0), "foo", 1),
(Vectors.dense(2.0,2.0,18.0), "foo", 3),
(Vectors.dense(2.0,2.0,20.0), "foo", 0),
(Vectors.dense(2.0,4.0,2.0), "foo", 2),
(Vectors.dense(2.0,4.0,4.0), "foo", 4),
(Vectors.dense(2.0,4.0,6.0), "foo", 2),
(Vectors.dense(2.0,4.0,8.0), "foo", 2),
(Vectors.dense(2.0,4.0,10.0), "foo", 4),
(Vectors.dense(2.0,4.0,12.0), "foo", 3),
(Vectors.dense(2.0,4.0,14.0), "foo", 2),
(Vectors.dense(2.0,4.0,16.0), "foo", 1),
(Vectors.dense(2.0,4.0,18.0), "foo", 4),
(Vectors.dense(2.0,4.0,20.0), "foo", 4)
], ["features","values","labels"])
cnn = (ConditionalKNN().setOutputCol("prediction"))
cnnm = cnn.fit(df)
test_df = spark.createDataFrame([
(Vectors.dense(2.0,2.0,2.0), "foo", 1, [0, 1]),
(Vectors.dense(2.0,2.0,4.0), "foo", 4, [0, 1]),
(Vectors.dense(2.0,2.0,6.0), "foo", 2, [0, 1]),
(Vectors.dense(2.0,2.0,8.0), "foo", 4, [0, 1]),
(Vectors.dense(2.0,2.0,10.0), "foo", 4, [0, 1])
], ["features","values","labels","conditioner"])
display(cnnm.transform(test_df))
此代码应记录一次运行,包含一个ConditionalKNNModel工件及其参数。