Chroma的单节点版本旨在易于部署和维护,同时仍提供满足广泛生产应用需求的强大性能。
为了帮助您了解单节点Chroma何时适合您的使用场景,我们进行了一系列压力测试和性能实验,以探究系统的功能并发现其限制和边缘情况。我们分析了这些边界在不同硬件配置下的表现,以确定何种部署适合不同的工作负载。
本文档描述了这些发现,以及一些充分利用Chroma部署的一般原则。
结果总结#
大致来说,以下是您可以在不同EC2实例类型上从Chroma获得的性能,使用非常典型的工作负载:
- 1024维嵌入
- 小文档(100-200字)
- 每条记录三个元数据字段
| 实例类型 | 系统内存 | 最大集合大小(近似) | 平均延迟(插入) | 99.9%延迟(插入) | 平均延迟(查询) | 99.9%延迟(查询) | 每月成本 |
|---|---|---|---|---|---|---|---|
| t3.small | 2 | 250,000 | 55ms | 250ms | 22ms | 72ms | $15.936 |
| t3.medium | 4 | 700,000 | 37ms | 120ms | 14ms | 41ms | $31.072 |
| t3.large | 8 | 1,700,000 | 30ms | 100ms | 13ms | 35ms | $61.344 |
| t3.xlarge | 16 | 3,600,000 | 30ms | 100ms | 13ms | 30ms | $121.888 |
| t3.2xlarge | 32 | 7,500,000 | 30ms | 100ms | 13ms | 30ms | $242.976 |
| r7i.2xlarge | 64 | 15,000,000 | 13ms | 50ms | 7ms | 13ms | $386.944 |
不建议在系统内存小于2GB的系统上部署Chroma。
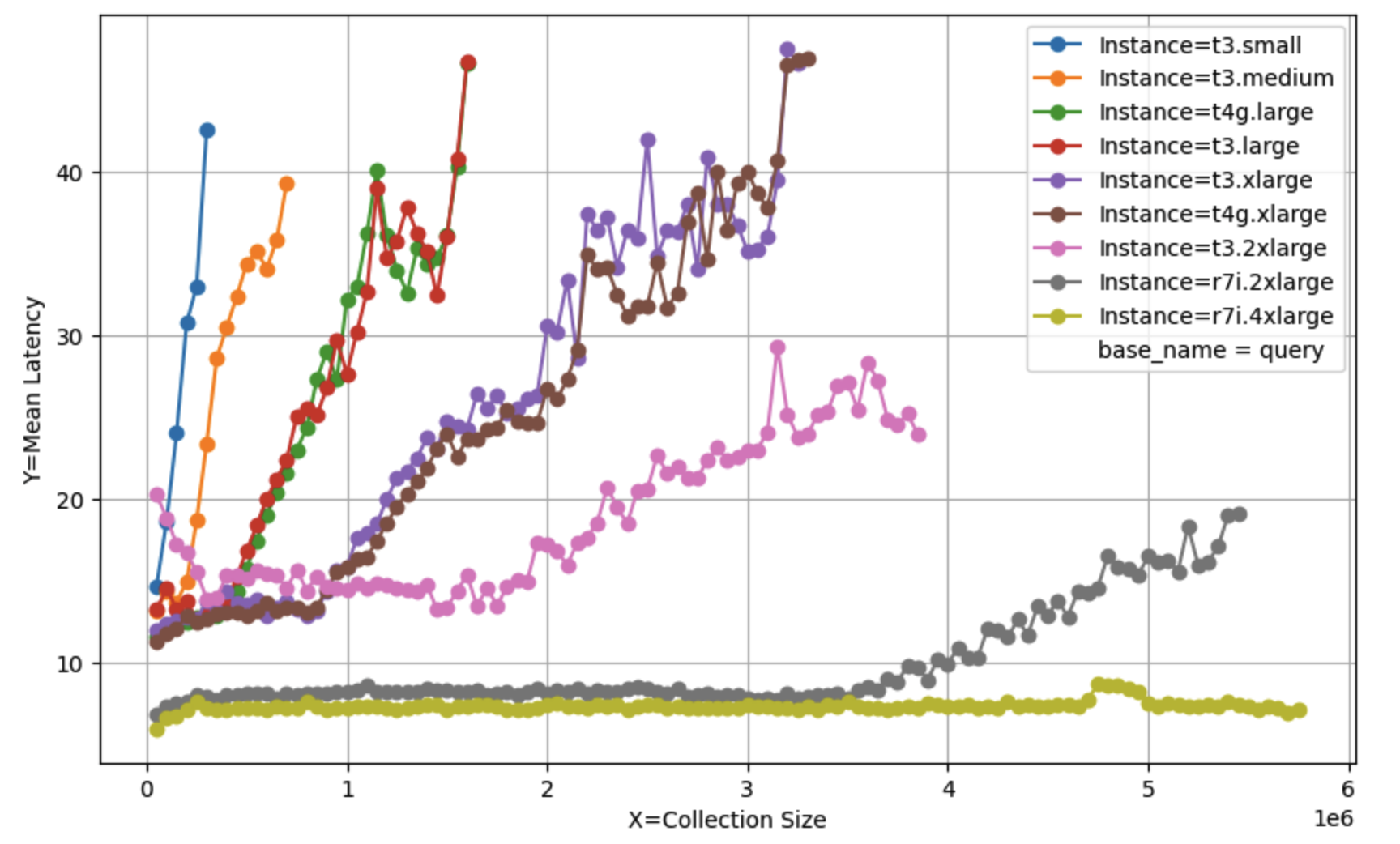
请注意,此表中的延迟数据适用于小集合。随着集合的增长,延迟会增加:请参见下文的延迟与集合大小以获取完整分析。
内存与集合大小#
Chroma使用hnswlib的一个分支来高效地索引和搜索嵌入向量。HNSW算法要求嵌入索引驻留在系统内存中以进行查询或更新。
因此,可用系统内存的数量定义了Chroma集合(或多个集合,如果它们同时使用)大小的上限。如果集合增长超过可用内存,插入和查询延迟会迅速飙升,因为操作系统开始将内存交换到磁盘。索引的内存布局不利于交换,系统很快变得不可用。
因此,用户应始终计划提供足够的RAM来容纳预期的嵌入总数。
为了分析需要多少RAM,我们在不同大小的EC2实例上启动了Chroma实例,然后插入嵌入,直到每个系统变得无响应。正如预期的那样,这个失败点与RAM和嵌入数量线性相关。
对于1024维嵌入,每个嵌入有三个元数据记录和一个小文档,这相当于N = R * 0.245,其中N是最大集合大小(以百万计),R是所需的系统内存量(以GB计)。请记住,除了Chroma所需的内存外,您还需要为系统的其他需求至少保留一GB内存。
这种模式在约700万嵌入之前都成立,这是我们测试的极限。此时Chroma仍然快速且稳定,我们没有发现Chroma数据库大小的严格上限。
磁盘空间与集合大小#
Chroma将每个集合持久化到磁盘。所需的空间是保存HNSW嵌入索引所需的空间与存储文档和嵌入元数据的sqlite数据库所需空间的组合。
持久化HNSW索引的计算与计算RAM大小类似。作为经验法则,只需确保系统的存储至少与其RAM一样大,再加上几GB以考虑操作系统和其它应用程序的开销。 sqlite数据库所需的空间大小变化很大,完全取决于是否在Chroma中保存文档和元数据,以及如果保存,它们的大小如何。全面探索所有可能的排列组合超出了我们能够进行的实验范围。
然而,作为一个单一数据点,一个包含约4万份每份1000字的文档和约60万个元数据条目的集合的sqlite数据库大约为1.7GB。
元数据数据库的大小没有严格的限制:sqlite本身支持达到TB级别的数据库,并且能够有效地分页到磁盘。
在大多数实际使用场景中,HNSW索引在RAM中的大小和性能很可能成为Chroma集合大小的限制因素,远在元数据数据库成为限制因素之前。
延迟与集合大小#
随着集合变大和索引规模增长,插入和查询的完成时间都会变长。增加的速率起初相当平缓,然后大致呈线性增长,拐点和斜率取决于可用CPU的数量和速度。
查询延迟#
插入延迟#
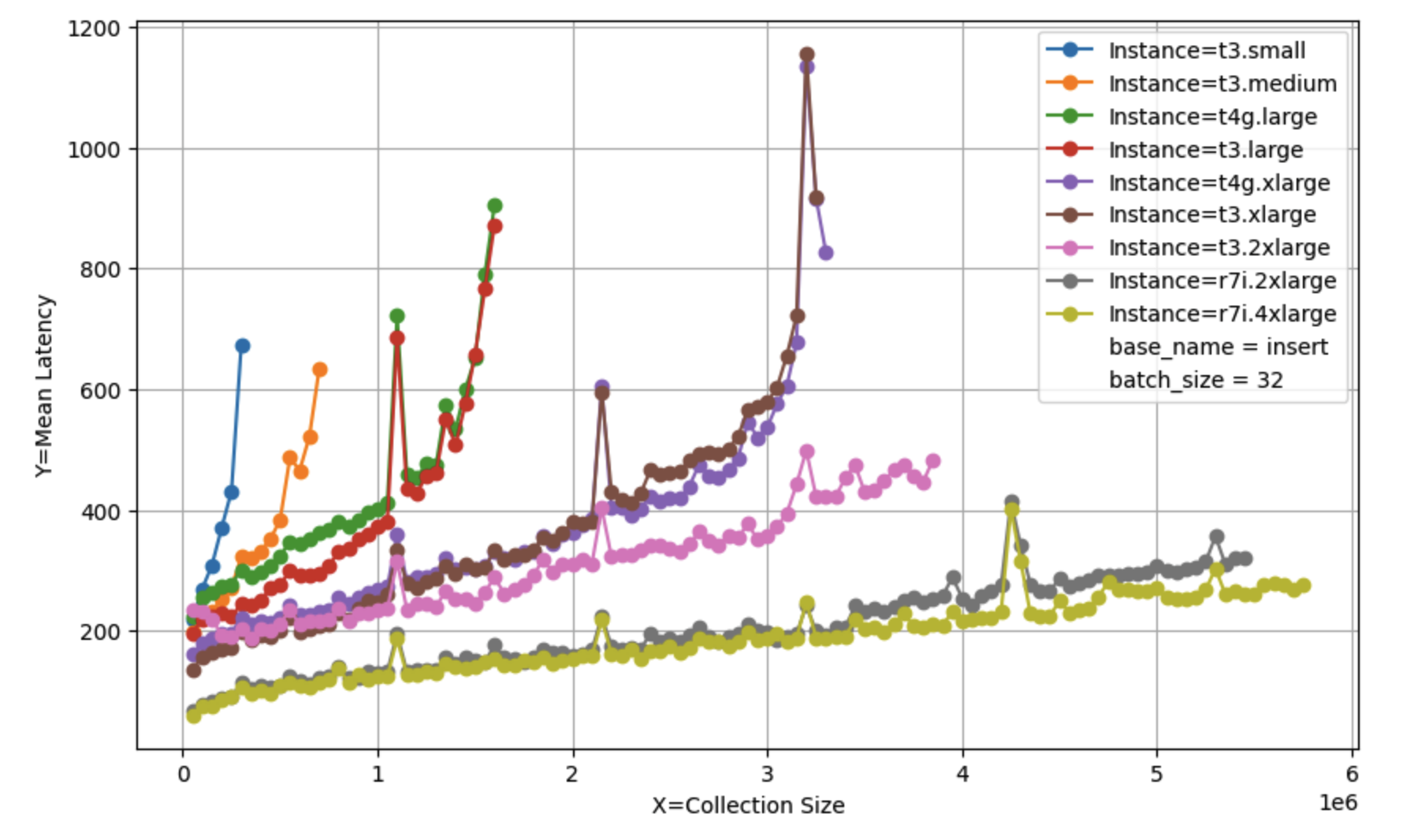
如果你使用多个集合,性能看起来非常相似,基于集合中嵌入的总数。将集合拆分为多个较小的集合并没有帮助,但只要它们都能一次性装入内存,也不会造成伤害。
并发性#
尽管HNSW算法的某些方面是多线程的,但在任何时候只有一个线程可以读取或写入给定的索引。在大多数情况下,单节点Chroma本质上是一个单线程系统。如果在一个操作仍在进行时执行另一个操作,它会阻塞直到第一个操作完成。
这意味着在并发负载下,每个请求的平均延迟会增加。
在写入时,随着批量大小的增加,延迟的增加更为明显,因为系统更加饱和。我们已经通过实验验证了这一点:随着并发写入者数量的增加,平均延迟线性增加。
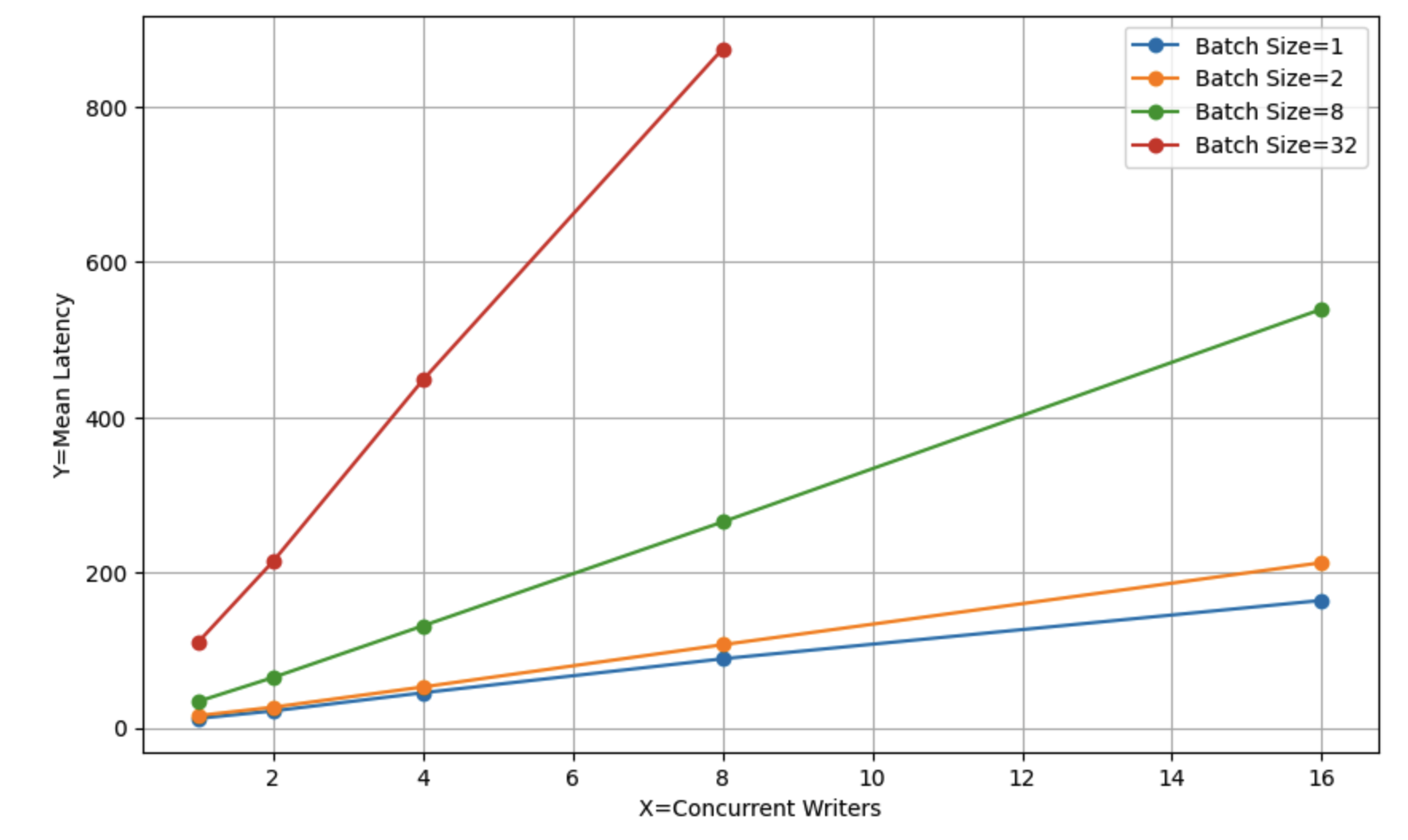
尽管延迟受到影响,Chroma在高并发负载下仍然保持稳定。过多的并发用户最终可能会增加延迟到系统无法接受的程度,但这通常只发生在较大的批量大小下。如上图所示,系统在每秒几十到几百个操作的情况下仍然可用。
请参阅下面的插入吞吐量部分,讨论在并发性受控的情况下(例如在插入批量数据时),如何优化用户数量以实现最大吞吐量。
CPU速度、核心数量与类型#
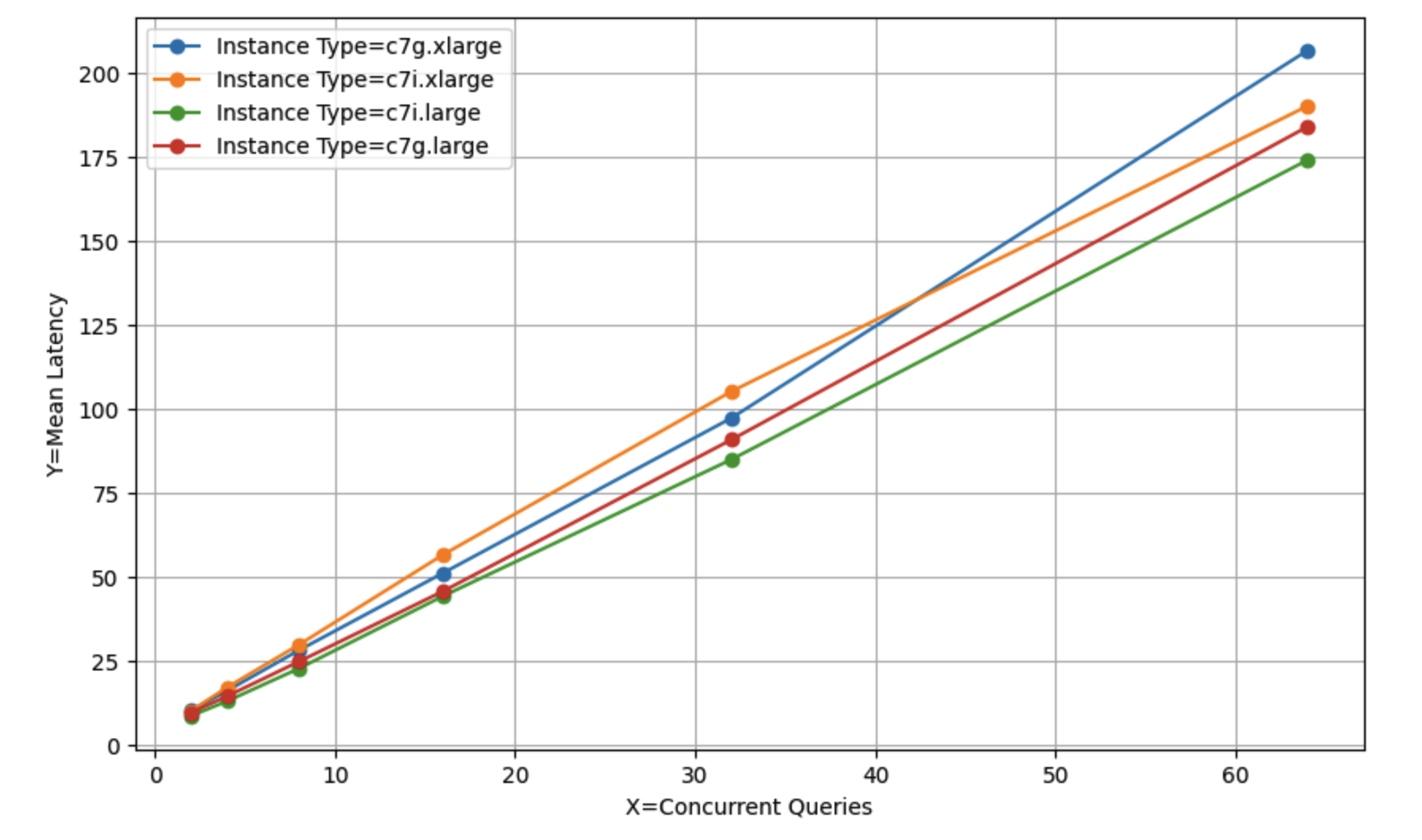
作为一个CPU密集型应用,CPU速度和类型对平均延迟的影响并不令人惊讶。
数据表明,尽管Chroma并未完全并行化,但它仍然可以利用多个CPU核心来提高吞吐量。
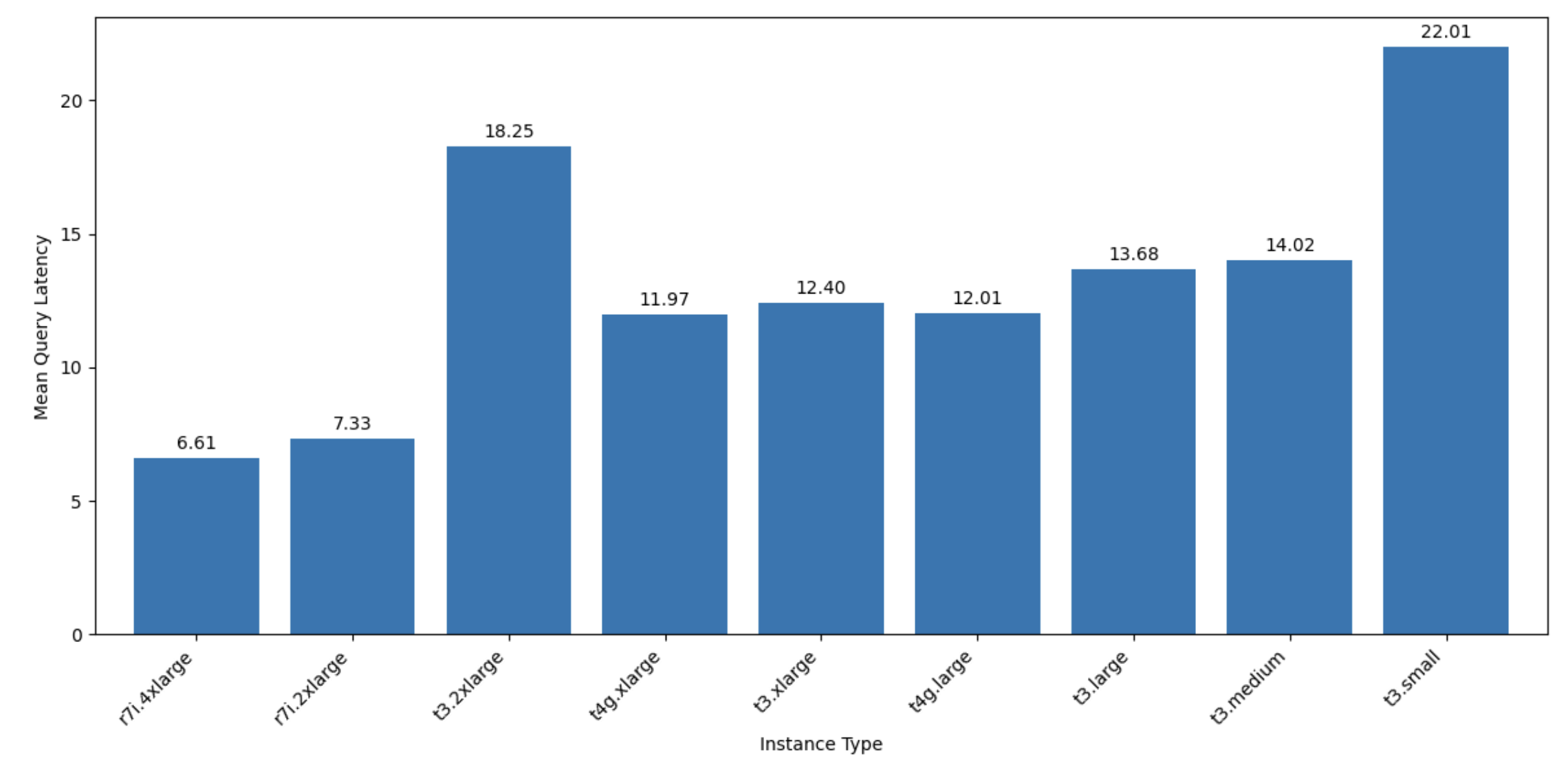
注意t3.2xlarge实例的延迟略有增加。从逻辑上讲,它应该比其他t3系列实例更快,因为它具有相同类型的CPU,并且数量更多。
这个数据点被保留下来作为一个重要的提醒,即EC2实例的性能略有变化,完全有可能遇到一个性能差异无法解释的实例。
插入吞吐量#
一个经常相关的问题是:给定要插入的批量数据,插入的速度有多快,以及快速插入大量数据的最佳方式是什么?
首先要考虑的重要因素是并发插入请求的数量。
如上文并发性部分所述,实际插入吞吐量并不会从并发性中受益。然而,存在一定量的网络和HTTP开销,这些开销可以并行化。因此,为了在保持尽可能低的延迟的同时使Chroma饱和,我们建议使用2个并发客户端进程或线程尽可能快地插入。
第二个要考虑的因素是每个请求的批量大小。性能与批量大小大致呈线性关系,处理HTTP请求本身有一个固定的开销。
实验证实了这一点:总体吞吐量(跨批量大小和请求数量的嵌入总数)在批量大小为100-500之间保持相当平稳:
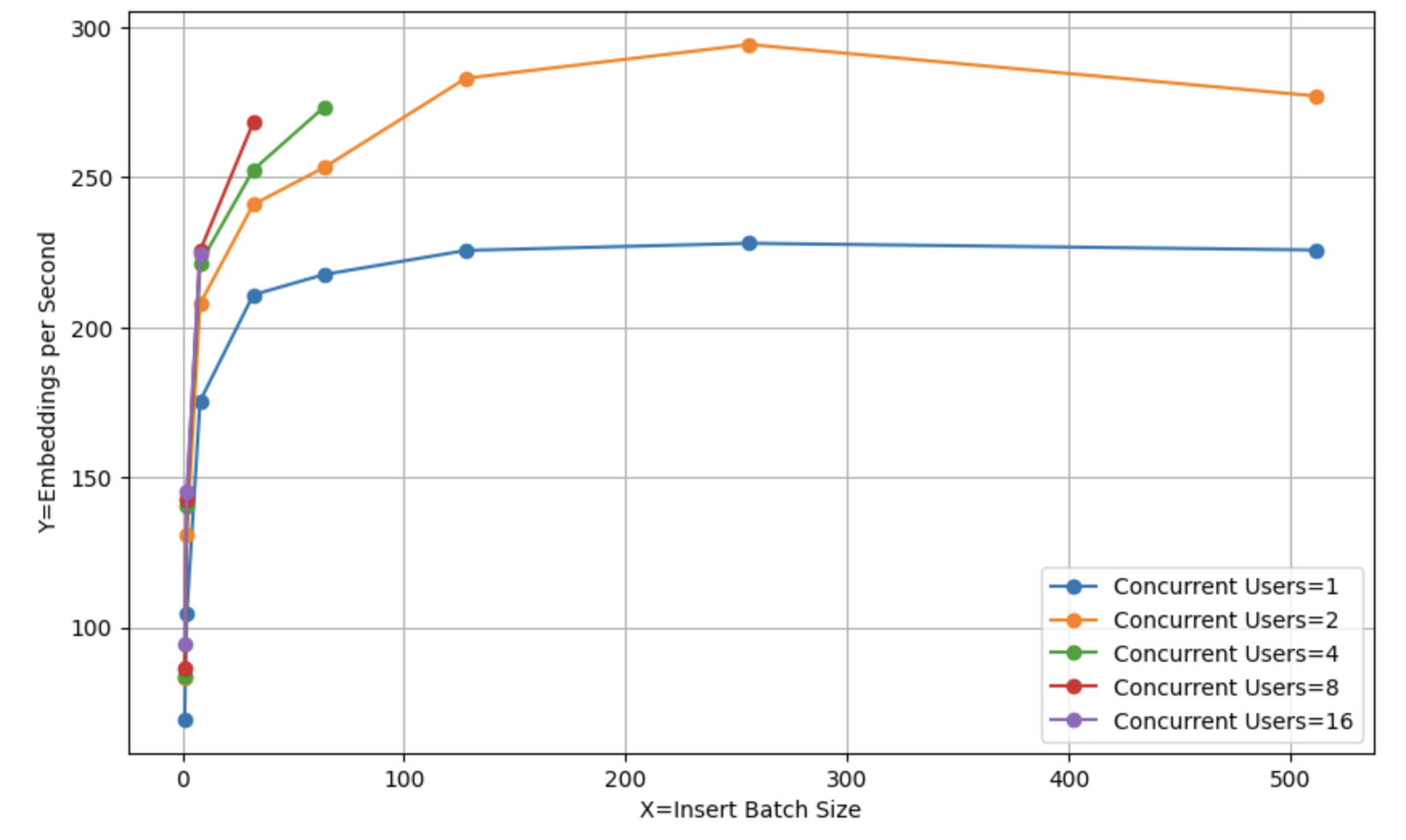
鉴于较小的批量具有更低、更一致的延迟,并且不太可能导致超时错误,我们建议选择此曲线中较小一侧的批量:任何介于50到250之间的批量都是一个合理的选择。
结论#
用户在使用适当硬件部署的情况下,应能放心地依赖Chroma处理接近数千万嵌入向量的用例。其读写的平均和上限延迟使其成为适用于除最大规模AI应用之外的良好平台,能够支持潜在的数千名同时在线用户(具体取决于应用的后端访问模式)。
然而,作为一个单节点解决方案,它并非无限扩展。若您发现需求超出了本分析所列参数,我们非常希望听取您的反馈。请填写此表单,我们将把您加入专门支持生产用户的Slack工作区。我们乐于协助您思考系统设计,无论Chroma是否适合其中,或您是否适合我们即将推出的分布式云服务。