强化学习中的探索机制¶
本文主要参考了这篇关于强化学习中探索策略的评论 blog[14] 。
问题定义和研究动机¶
强化学习是通过环境给出的奖励信号来指导策略的更新,并努力获得最大的累积折扣奖励。但在许多现实世界的环境中,奖励是稀疏的,甚至不存在。在这种情况下,如何指导代理有效地探索状态和动作空间,然后找到完成任务的最优策略?
如果代理在有限数量的训练步骤后变得贪婪,即仅选择它当前认为在某个状态下最优的动作,它可能永远无法学习到最优策略,因为它很可能已经收敛到一个次优策略,永远不会达到真正有意义的奖励状态。这就是所谓的探索与利用困境。 通俗地说,所谓的探索:指的是为了期望更高的回报而做你以前从未做过的事情;所谓的利用:指的是做你目前知道能产生最大回报的事情。
参考Go-Explore [9],探索主要包括两个难点:
环境给予的奖励是稀疏的。代理需要执行一系列特定的动作才能获得非零奖励。如果在每一步仅使用随机探索,很可能在整个学习过程中都不会遇到非零奖励。例如,在《蒙特祖玛的复仇》中,代理需要执行一长串动作才能获得钥匙或进入新房间,只有那时才会有奖励。
环境给予的奖励具有误导性。例如,在Pitfall游戏中,不仅奖励非常稀少,而且代理的许多行为都会获得负奖励。在代理学会如何获得正奖励之前,由于这些负奖励的存在,它可能会停止在原地,导致缺乏探索。
在上述情况下,一个高效的探索机制对于代理完成任务至关重要。
方向¶
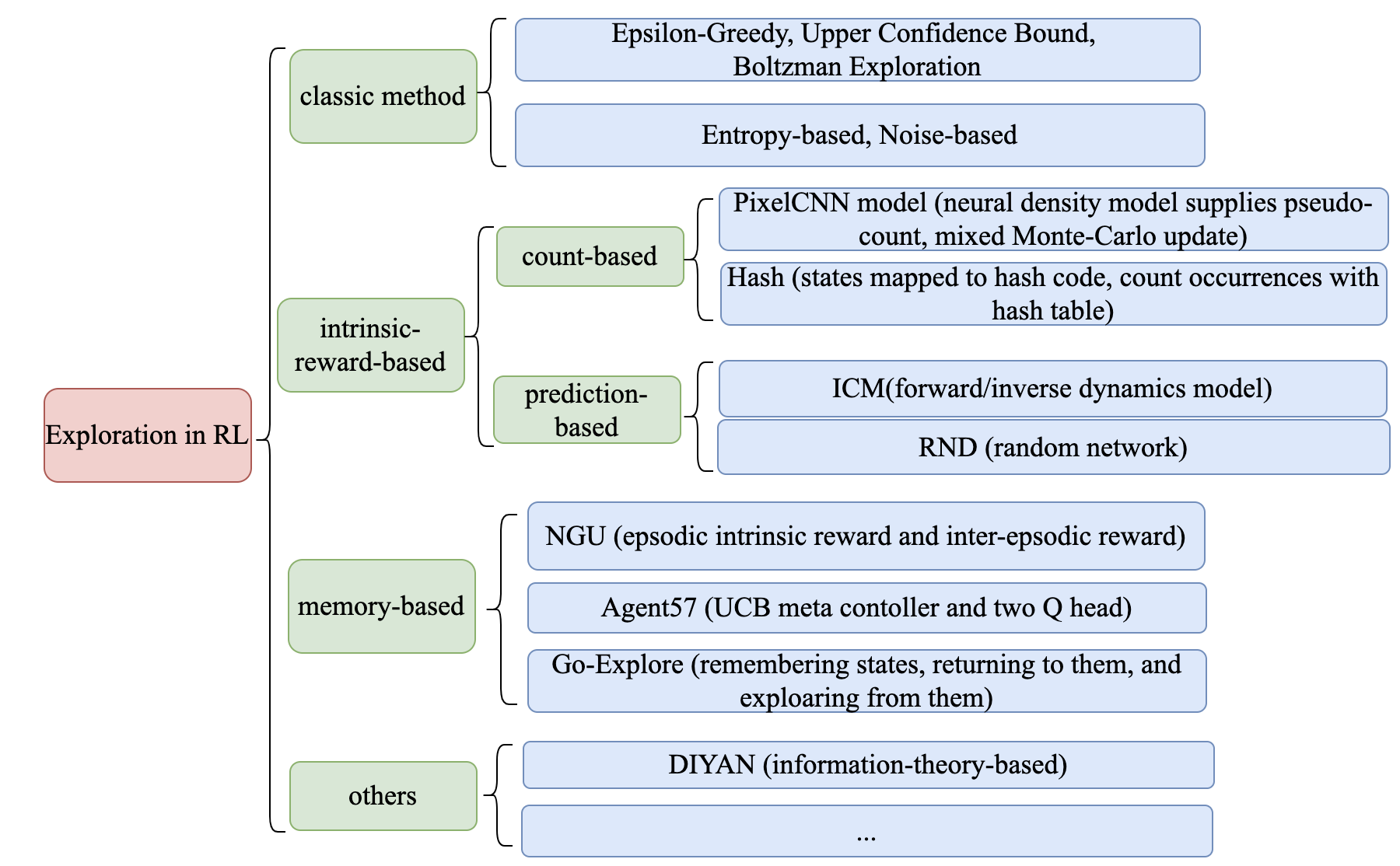
强化学习中的探索机制大致可以分为以下几个研究方向:
经典探索机制
基于内在奖励的探索
基于计数的内在奖励
基于预测误差的内在奖励
基于信息理论的内在奖励
基于内存的探索
情景记忆
直接探索
其他探索机制
每个研究方向的代表性算法及其关键点如下图所示:
经典探索机制¶
在传统的多臂赌博机问题中,常用的经典探索机制包括:
Epsilon-Greedy:在某个时刻,所有动作都有一个大于0的选择概率。代理以一个小概率\(\epsilon\)执行随机动作(探索),并以一个大概率\(1-\epsilon\)执行具有最大Q值的动作(利用)。
上置信度界限:代理贪婪地选择最大化置信度上界的动作 \(\hat{Q}_{t}(a)+\hat{U}_{t}(a)\),其中 \(\hat{Q}_{t}(a)\) 是在 \(t\) 时刻与动作 \(a\) 相关的平均奖励,\(\hat{U}_{t}(a)\) 是与采取动作 \(a\) 相关的奖励函数,该函数与次数成反比。
玻尔兹曼探索:代理从与学习到的Q值对应的玻尔兹曼分布中采样动作(即对Q值的logits执行softmax操作后获得的分布),探索程度可以通过温度参数进行调整。
当通过神经网络进行函数逼近时,以下机制可用于在深度强化学习训练中获得更好的探索性能:
熵损失:通过在损失函数中添加额外的熵正则化项,鼓励代理执行更多样化的动作。
基于噪声的探索:通过在观测、动作甚至网络的参数空间中添加噪声来实现探索。
基于内在奖励的探索¶
探索机制设计中更重要的方法之一是设计特殊的奖励来激发代理的“好奇心”。通常,我们将环境给予的奖励称为外在奖励,而探索机制给予的奖励称为内在奖励。
我们希望通过添加这个额外的内在奖励来实现两件事:
探索状态空间:激励代理探索更多新颖的状态。(需要评估状态\(s\)的新颖性)
探索状态-动作空间:激励代理执行有助于减少环境不确定性的动作。(需要评估状态-动作对 \(( s,a )\) 的新颖性)
首先给出新颖性的定性定义:
对于一个状态\(s\),在代理之前访问的所有状态中,如果与\(s\)相似的状态数量较少,我们称状态\(s\)更具新颖性(状态-动作对\(( s,a )\)的新颖性定义类似)。
某个状态\(s\)越新颖,相应的代理对该状态\(s\)的认知不足就越频繁,代理在后续与环境交互时需要更多地探索这个状态\(s\),因此这种特别设计的探索机制赋予该状态更大的内在奖励。如何衡量状态\(s\)的新颖性?主要有两种方式,一种是通过某种方式对状态进行计数来衡量,另一种是基于某个预测问题的预测误差来衡量,从而得到基于内在奖励的探索以下两大类算法:基于计数的内在奖励和基于预测误差的内在奖励。
基于计数的内在奖励¶
基于计数的内在奖励采用了最简单的通过计数来衡量新颖性的想法,即每个\(s\)对应一个访问计数\(N(s)\),值越大,代理之前访问它的次数越多,也就是说,对:math:s的探索更充分(或:math:s的新颖性更低)。探索模块给出一个与状态计数成反比的内在奖励。
统一基于计数的探索和内在动机 [1] 使用密度模型来近似状态访问的频率,并提出了一种从密度模型算法中得出的新颖伪计数。
探索:深度强化学习中基于计数的探索研究 [2] 提出使用局部敏感哈希(LSH)将连续的高维状态数据转换为离散的哈希码。因此,统计状态出现的频率变得可行。
然而,基于计数的方法来衡量新颖性有许多明显的局限性:
对于高维连续观测空间和连续动作空间,没有简单的计数方法。
访问次数并不能准确衡量代理对\(( s,a )\)的认知。
基于预测误差的内在奖励¶
基于预测误差的内在奖励是使用状态在预测问题(通常是有监督学习问题)上的预测误差来衡量新颖性。根据有监督学习中神经网络拟合数据集的特性,如果代理在某个状态\(s\)的预测误差较大,则大致意味着代理在该状态\(s\)附近的状态空间中的先前访问次数较少,因此状态\(s\)更具新颖性。
预测问题通常与环境动态相关,例如论文[3] Curiosity-driven Exploration by Self-supervised Prediction (ICM) 提出了一种基于预测误差的内在好奇心模块。模块,ICM),通过使用逆动力学模型和前向动力学模型在原始问题空间上学习一个新的特征空间,使得学习到的特征空间仅编码影响代理决策的部分,而忽略环境噪声和其他无关干扰。然后在这个更纯净的特征空间上,使用前向模型的预测误差为RL训练提供内在奖励。有关ICM的更多详细信息,请参阅博客。
但是ICM存在以下问题:
在大规模问题上,环境的复杂前向动力学模型,加上神经网络的有限容量,导致在状态-动作空间的某些区域被多次访问时,预测误差较大。
在某些环境中,环境的状态转移函数是一个随机函数,例如包含噪声电视属性的环境,代理无法通过通常的神经网络准确预测下一个状态。
为了缓解上述问题,论文[4] 通过随机网络蒸馏进行探索提出了RND算法,这也是一种基于预测问题的探索方法,但特别的是,RND算法中的预测问题仅与观察状态(observation)相关。相关的随机蒸馏问题与环境的前向或逆向动力学模型无关。具体来说,RND使用两个结构相同的神经网络:一个具有固定随机初始化参数的目标网络;一个预测网络,用于输出目标网络给出的状态编码。然后,RND内在探索奖励被定义为与预测网络预测的状态特征\(\hat{f}( s_t )\)和目标网络的状态特征\(f(s_t)\)成正比。有关RND的更多详细信息,请参阅博客。
基于信息论的内在奖励¶
为了鼓励探索,另一个想法是基于信息论设计内在奖励。 论文[11]介绍了变分信息最大化探索(VIME),其核心思想是通过在贝叶斯神经网络中使用变分推断,最大化关于代理对环境动态的信念的信息增益,这可以有效地处理连续的状态和动作空间。 论文[12]提出了EMI算法(基于互信息的探索),该算法不通过通常的编码/解码原始状态或动作空间来学习表示,而是通过最大化相关状态-动作表示之间的互信息来学习状态和动作之间的关系。 他们通过实验验证了在这种表示空间中提取的前向预测信号可以很好地指导探索。 此外,还有诸如DIYAN[13]等方法,该方法基于互信息的目标函数来学习技能变量,可以通过设置与互信息相关的内在奖励来自动学习状态和技能的分布,而无需外部奖励,从而用于后续任务,如分层学习、模仿学习和探索。
基于记忆的探索¶
基于内在奖励的探索方法,如ICM和RND,提出通过预测问题的误差来衡量状态的新颖性,并为具有高新颖性的状态提供大的内在奖励以促进探索。这些方法在许多稀疏奖励设置下的探索困难任务上取得了有希望的结果。但存在一个问题:随着代理训练步骤的增加,预测问题的预测误差开始减少,探索信号变小,即代理不再被鼓励访问某些状态,但这些状态可能是必须访问的以获得外在奖励。此外,可能还存在以下问题:
函数逼近速度相对较慢,有时无法跟上代理探索的速度,导致内在奖励不能很好地描述状态的新颖性。
探索的奖励是非平稳的。
基于存储的探索机制明确使用内存来维护历史状态,然后根据当前状态与历史状态之间的某种度量给出当前状态的内在奖励值。
情景记忆¶
NGU¶
为了解决上述探索信号逐渐衰减的问题,论文[5] Never Give Up (NGU): Learning Directed Exploration Strategies 设计了NGU算法,以在R2D2 [6]算法的基础上解决这一问题。 该代理采用了一种新的内在奖励生成机制,该机制整合了两个维度的新颖性:即游戏间内在奖励的终身维度和游戏内内在奖励的单游戏维度,并提出了同时学习一组具有不同探索程度的策略(定向探索策略)以收集更丰富的样本进行训练。其中,游戏间的内在奖励通过维护一个存储游戏状态的Episodic来维持,该状态通过计算当前状态与Memory中最相似的k个样本之间的距离来计算。有关NGU的更多详细信息可以在中文博客中找到。
Agent57¶
论文 [7] Agent57: 超越Atari人类基准 在NGU的基础上做出了以下改进:
Q函数的参数化:Q网络被分为两部分,分别学习内在奖励对应的Q值和外在奖励对应的Q值。
NGU 使用不同的 Q 函数(也称为策略)以相等的概率,并使用元控制器自适应地选择对应于不同奖励折扣因子和内在奖励权重系数的 Q 函数,以平衡探索和利用。
最终使用了更大的反向传播时间窗口大小。
直接探索¶
Go-Explore¶
Go-Explore [8] [9] 指出,目前有两个因素阻碍了代理的探索:忘记如何到达之前访问过的状态(脱离);代理无法首先返回到某个状态,然后从该状态开始探索(脱轨)。为此,作者提出了一种简单的机制,即记住一个状态,返回到该状态,并从该状态开始探索,以处理上述问题:通过维护感兴趣状态和导致这些状态的轨迹的记忆,代理可以返回到这些有希望的状态(假设模拟器是确定性的),并从那里继续进行随机探索。新颖性通过状态在预测问题(通常是一个监督学习问题)上的预测误差来衡量。
具体来说,首先将状态映射为一个简短的离散代码(称为单元)进行存储。如果出现新状态或找到更好/更短的轨迹,内存会更新相应的状态和轨迹。代理可以均匀且随机地在内存中选择一个状态返回,或者根据一些启发式规则,例如可以根据诸如新近度、访问次数、内存中其邻居的计数等相关指标来选择返回的状态。然后从这个状态开始探索。Go-Explore重复上述过程,直到任务解决,即至少找到一个成功的轨迹。
其他探索机制¶
未来研究¶
在当前基于内在奖励的探索方法中,如何自适应地设置内在奖励和环境给出的奖励的相对权重是一个值得研究的问题。
可以观察到,现有的探索机制通常考虑单个状态的新颖性,未来可能会扩展到序列状态的新颖性,以实现更高语义层次的探索。
目前,基于内在奖励的探索和基于记忆的探索在实践中仅能给出良好的结果,其理论收敛性和最优性仍需研究。
如何将传统的探索方法(如UCB)与最新的基于内在奖励或基于记忆的探索机制相结合,可能是一个值得研究的问题。