复合查询
edit复合查询
edit复合查询包裹其他复合或叶子查询,用于组合它们的结果和分数,改变它们的行为,或从查询上下文切换到过滤上下文。
本组中的查询包括:
-
boolquery -
用于组合多个叶子或复合查询子句的默认查询,如
must、should、must_not或filter子句。must和should子句的分数会被合并——匹配的子句越多,分数越高——而must_not和filter子句则在过滤上下文中执行。 -
boostingquery -
返回匹配
positive查询的文档,但降低也匹配negative查询的文档的分数。 -
constant_scorequery -
一个包装了另一个查询的查询,但在过滤上下文中执行它。所有匹配的文档都被赋予相同的“常量”
_score。 -
dis_maxquery -
一个接受多个查询的查询,并返回任何与查询子句匹配的文档。虽然
bool查询结合了所有匹配查询的分数,但dis_max查询使用单个最佳匹配查询子句的分数。 -
function_scorequery - 使用函数修改主查询返回的分数,以考虑流行度、时效性、距离或使用脚本实现的定制算法等因素。
布尔查询
edit匹配布尔组合的其他查询的文档的查询。bool查询映射到Lucene BooleanQuery。它使用一个或多个布尔子句构建,每个子句都有一个类型化的出现。出现类型包括:
| Occur | Description |
|---|---|
|
该子句(查询)必须出现在匹配的文档中,并将对得分产生贡献。 |
|
该子句(查询)必须出现在匹配的文档中。然而,与 |
|
子句(查询)应出现在匹配的文档中。 |
|
该子句(查询)不得出现在匹配的文档中。子句在过滤上下文中执行,这意味着评分被忽略,并且子句被考虑用于缓存。由于评分被忽略,所有文档的得分为 |
The bool query采用匹配越多越好的方法,因此每个匹配的must或should子句的分数将被加在一起,以提供每个文档的最终_score。
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
使用 minimum_should_match
edit您可以使用 minimum_should_match 参数来指定返回文档必须匹配的 should 子句的数量或百分比。
如果 bool 查询包含至少一个 should 子句且没有 must 或
filter 子句,默认值为 1。
否则,默认值为 0。
有关其他有效值,请参阅
minimum_should_match 参数。
使用bool.filter进行评分
edit在filter元素下指定的查询对评分没有影响——评分将返回为0。评分仅受已指定的查询影响。例如,以下三个查询都会返回status字段包含术语active的所有文档。
第一个查询将所有文档的分数分配为 0,因为没有指定评分查询:
GET _search
{
"query": {
"bool": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}
这个 bool 查询包含一个 match_all 查询,它为所有文档分配了 1.0 的分数。
GET _search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"status": "active"
}
}
}
}
}
这个 constant_score 查询的行为与上面的第二个示例完全相同。
constant_score 查询为过滤器匹配的所有文档分配一个 1.0 的分数。
GET _search
{
"query": {
"constant_score": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}
命名查询
edit每个查询在其顶级定义中接受一个_name。您可以使用命名查询来跟踪哪些查询匹配了返回的文档。如果使用了命名查询,响应中会为每个命中结果包含一个matched_queries属性。
在同一请求中提供重复的 _name 值会导致未定义的行为。具有重复名称的查询可能会相互覆盖。查询名称在单个请求中被假定为唯一的。
GET /_search
{
"query": {
"bool": {
"should": [
{ "match": { "name.first": { "query": "shay", "_name": "first" } } },
{ "match": { "name.last": { "query": "banon", "_name": "last" } } }
],
"filter": {
"terms": {
"name.last": [ "banon", "kimchy" ],
"_name": "test"
}
}
}
}
}
名为 include_named_queries_score 的请求参数控制是否返回与匹配查询相关的分数。当设置时,响应包括一个 matched_queries 映射,该映射包含作为键的匹配查询的名称及其关联的分数作为值。
请注意,分数可能没有对文档的最终分数做出贡献,例如在过滤器或must_not上下文中出现的命名查询,或者在忽略或修改分数的子句内部,如constant_score或function_score_query。
GET /_search?include_named_queries_score
{
"query": {
"bool": {
"should": [
{ "match": { "name.first": { "query": "shay", "_name": "first" } } },
{ "match": { "name.last": { "query": "banon", "_name": "last" } } }
],
"filter": {
"terms": {
"name.last": [ "banon", "kimchy" ],
"_name": "test"
}
}
}
}
}
此功能在搜索响应中的每个命中上重新运行每个命名查询。通常,这会给请求增加少量开销。然而,在大量命中上使用计算成本高的命名查询可能会增加显著的开销。例如,与在许多桶上使用top_hits聚合结合的命名查询可能会导致响应时间变长。
提升查询
edit返回匹配positive查询的文档,同时降低也匹配negative查询的文档的相关性分数。
您可以使用boosting查询来降低某些文档的权重,而不将它们从搜索结果中排除。
示例请求
editGET /_search
{
"query": {
"boosting": {
"positive": {
"term": {
"text": "apple"
}
},
"negative": {
"term": {
"text": "pie tart fruit crumble tree"
}
},
"negative_boost": 0.5
}
}
}
常量分数查询
edit包装一个过滤查询,并返回每个匹配文档的相关性分数等于boost参数值。
GET /_search
{
"query": {
"constant_score": {
"filter": {
"term": { "user.id": "kimchy" }
},
"boost": 1.2
}
}
}
析取最大查询
edit返回匹配一个或多个包装查询的文档,称为查询子句或子句。
如果返回的文档匹配多个查询子句,dis_max 查询将文档分配为来自任何匹配子句的最高相关性分数,再加上任何其他匹配子查询的平局决胜增量。
示例请求
editGET /_search
{
"query": {
"dis_max": {
"queries": [
{ "term": { "title": "Quick pets" } },
{ "term": { "body": "Quick pets" } }
],
"tie_breaker": 0.7
}
}
}
用于dis_max的顶级参数
edit-
queries - (必需,查询对象数组) 包含一个或多个查询子句。返回的文档必须匹配一个或多个这些查询。如果一个文档匹配多个查询,Elasticsearch 使用最高的 相关性分数。
-
tie_breaker -
(可选, 浮点数) 介于
0和1.0之间的浮点数,用于增加 匹配多个查询子句的文档的 相关性分数。默认为0.0。您可以使用
tie_breaker值来为在多个字段中包含相同术语的文档分配更高的相关性分数,而不是仅在那些多个字段中包含此术语的最佳字段中的文档,而不会将此与多个字段中包含两个不同术语的更好情况混淆。如果一个文档匹配了多个子句,
dis_max查询会按照以下方式计算文档的相关性得分:- 取匹配子句中得分最高的相关性分数。
-
将其他匹配子句的得分乘以
tie_breaker值。 - 将最高得分与乘积得分相加。
如果
tie_breaker值大于0.0,所有匹配的子句都会计入,但得分最高的子句权重最大。
函数评分查询
editThe function_score 允许你修改由查询检索到的文档的分数。这在某些情况下非常有用,例如,如果一个评分函数在计算上非常昂贵,并且只需要对过滤后的文档集计算分数就足够了。
要使用 function_score,用户需要定义一个查询和一个或多个函数,这些函数用于计算查询返回的每个文档的新分数。
function_score 可以只使用一个函数,如下所示:
GET /_search
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"random_score": {},
"boost_mode": "multiply"
}
}
}
|
请参阅函数评分以获取支持的函数列表。 |
此外,多个函数可以组合使用。在这种情况下,可以选择仅在文档匹配给定的过滤查询时应用该函数
GET /_search
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"functions": [
{
"filter": { "match": { "test": "bar" } },
"random_score": {},
"weight": 23
},
{
"filter": { "match": { "test": "cat" } },
"weight": 42
}
],
"max_boost": 42,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 42
}
}
}
|
整个查询的提升。 |
|
|
查看函数评分以获取支持的函数列表。 |
每个函数的过滤查询产生的分数并不重要。
如果没有给函数指定过滤器,这等同于指定"match_all": {}
首先,每个文档由定义的函数进行评分。参数score_mode指定如何组合计算的分数:
|
|
分数被乘以(默认) |
|
|
分数被累加 |
|
|
分数被平均 |
|
|
第一个具有匹配过滤器的函数 被应用 |
|
|
最大分数被使用 |
|
|
最低分数被使用 |
因为分数可能处于不同的量表上(例如,衰减函数在0到1之间,但field_value_factor可以是任意的),并且有时希望函数对分数有不同的影响,所以可以使用用户定义的weight来调整每个函数的分数。weight可以在functions数组中为每个函数定义(如上例所示),并与相应函数计算的分数相乘。
如果给出了weight而没有其他函数声明,weight将作为一个函数,简单地返回weight。
如果 score_mode 设置为 avg,则各个分数将通过 加权 平均值进行组合。
例如,如果两个函数返回分数 1 和 2,并且它们的相应权重分别为 3 和 4,那么它们的分数将组合为
(1*3+2*4)/(3+4) 而不是 (1*3+2*4)/2。
通过设置max_boost参数,可以将新分数限制在不超过某个上限。max_boost的默认值为FLT_MAX。
新计算的分数与查询的分数相结合。参数boost_mode定义了如何结合:
|
|
查询分数和函数分数相乘(默认) |
|
|
仅使用函数得分,忽略查询得分 |
|
|
查询分数和函数分数已添加 |
|
|
平均值 |
|
|
查询分数和函数分数的最大值 |
|
|
查询分数和函数分数的最小值 |
默认情况下,修改分数不会改变哪些文档匹配。要排除不满足特定分数阈值的文档,可以将 min_score 参数设置为所需的分数阈值。
为了使min_score生效,查询返回的所有文档都需要进行评分,然后逐一过滤。
The function_score 查询提供了几种评分函数。
-
script_score -
weight -
random_score -
field_value_factor -
衰减函数:
gauss,linear,exp
脚本评分
editThe script_score 函数允许你包装另一个查询并自定义其评分,可以选择使用从文档中其他数值字段派生的计算结果,通过脚本表达式来实现。以下是一个简单的示例:
GET /_search
{
"query": {
"function_score": {
"query": {
"match": { "message": "elasticsearch" }
},
"script_score": {
"script": {
"source": "Math.log(2 + doc['my-int'].value)"
}
}
}
}
}
在Elasticsearch中,所有文档分数都是正的32位浮点数。
如果 script_score 函数生成的分数具有更高的精度,它将被转换为最接近的32位浮点数。
同样,分数必须是非负的。否则,Elasticsearch 会返回一个错误。
除了不同的脚本字段值和表达式之外,还可以使用_score脚本参数来检索基于包装查询的分数。
脚本编译会被缓存以加快执行速度。如果脚本需要考虑参数,最好重用相同的脚本,并为其提供参数:
GET /_search
{
"query": {
"function_score": {
"query": {
"match": { "message": "elasticsearch" }
},
"script_score": {
"script": {
"params": {
"a": 5,
"b": 1.2
},
"source": "params.a / Math.pow(params.b, doc['my-int'].value)"
}
}
}
}
}
请注意,与custom_score查询不同,查询的分数会乘以脚本评分的结果。如果你希望抑制这一点,请设置"boost_mode": "replace"
随机
editThe random_score 生成从0到1之间均匀分布的分数,但不包括1。默认情况下,它使用内部Lucene文档ID作为随机性来源,这非常高效,但不幸的是,由于文档可能会在合并过程中重新编号,因此无法重现。
如果您希望分数是可重复的,可以提供一个seed和field。最终的分数将基于这个种子、所考虑文档的field的最小值以及基于索引名称和分片ID计算的盐值来计算,以便具有相同值但存储在不同索引中的文档获得不同的分数。请注意,位于同一分片中且具有相同field值的文档将获得相同的分数,因此通常希望使用一个对所有文档具有唯一值的字段。一个好的默认选择可能是使用_seq_no字段,其唯一缺点是如果文档被更新,分数将会改变,因为更新操作也会更新_seq_no字段的值。
可以不设置字段而设置种子,但这种方式已被弃用,因为它需要在_id字段上加载fielddata,这会消耗大量内存。
GET /_search
{
"query": {
"function_score": {
"random_score": {
"seed": 10,
"field": "_seq_no"
}
}
}
}
字段值因子
editThe field_value_factor 函数允许您使用文档中的一个字段来影响得分。它类似于使用 script_score 函数,但是,它避免了脚本的开销。如果在多值字段上使用,则仅使用字段的第一个值进行计算。
例如,假设您有一个带有数值字段 my-int 的文档,并且希望使用该字段影响文档的分数,一个实现此目的的示例如下:
GET /_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "my-int",
"factor": 1.2,
"modifier": "sqrt",
"missing": 1
}
}
}
}
这将转化为以下评分公式:
sqrt(1.2 * doc['my-int'].value)
关于 field_value_factor 函数,有多种选项可供选择:
|
|
要从文档中提取的字段。 |
|
|
可选的因子,用于乘以字段值,默认为 |
|
|
应用于字段值的修饰符,可以是以下之一: |
| Modifier | Meaning |
|---|---|
|
不对字段值应用任何乘数 |
|
取字段值的常用对数。
由于此函数在用于0到1之间的值时会返回负值并导致错误,因此建议改用 |
|
将字段值加1并取常用对数 |
|
将字段值加2并取常用对数 |
|
取字段值的自然对数。
因为此函数在用于0到1之间的值时会返回负值并导致错误,建议改用 |
|
将字段值加1并取自然对数 |
|
将字段值加2并取自然对数 |
|
将字段值平方(将其乘以自身) |
|
取字段值的平方根 |
|
取倒数 字段值,与 |
-
missing - 如果文档没有该字段时使用的值。修饰符和因子仍然会像从文档中读取一样应用于它。
由 field_value_score 函数生成的分数必须为非负数,否则将抛出错误。如果对介于 0 和 1 之间的值使用 log 和 ln 修饰符,将会产生负值。请确保使用范围过滤器限制字段值以避免这种情况,或者使用 log1p 和 ln1p。
请记住,对0取对数或对负数取平方根是非法操作,并且会抛出异常。请确保使用范围过滤器限制字段的值以避免这种情况,或者使用log1p和ln1p。
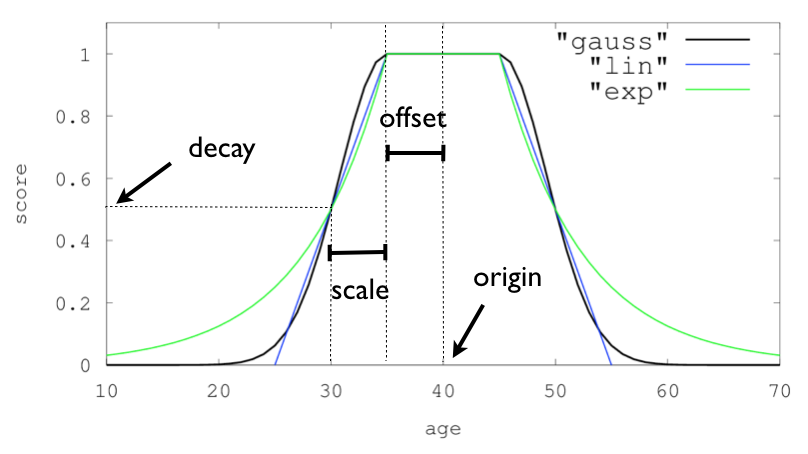
衰减函数
edit衰减函数根据文档的数值字段值与用户给定原点之间的距离,使用一个衰减函数对文档进行评分。这与范围查询类似,但边缘是平滑的,而不是方形的。
要在包含数值字段的查询上使用距离评分,用户必须为每个字段定义一个origin和一个scale。origin用于定义计算距离的“中心点”,而scale用于定义衰减速率。衰减函数指定为
"DECAY_FUNCTION": {
"FIELD_NAME": {
"origin": "11, 12",
"scale": "2km",
"offset": "0km",
"decay": 0.33
}
}
在上面的示例中,字段是一个geo_point,并且原点可以以地理格式提供。scale和offset必须在此情况下以单位给出。如果你的字段是日期字段,你可以将scale和offset设置为天、周等。示例:
GET /_search
{
"query": {
"function_score": {
"gauss": {
"@timestamp": {
"origin": "2013-09-17",
"scale": "10d",
"offset": "5d",
"decay": 0.5
}
}
}
}
}
|
原点的日期格式取决于映射中定义的 |
|
|
参数 |
|
|
用于计算距离的原点。必须为数值字段提供数字,为日期字段提供日期,为地理字段提供地理点。地理字段和数值字段是必需的。对于日期字段,默认值为 |
|
|
所有类型的必需项。定义了从原点 + 偏移量开始,计算得分将等于 |
|
|
如果定义了 |
|
|
|
在第一个示例中,您的文档可能代表酒店并包含地理位置字段。您希望根据酒店与给定位置的距离计算衰减函数。您可能不会立即看到为高斯函数选择什么尺度,但您可以说:“在距离所需位置2公里的地方,分数应减少到三分之一。”参数“scale”将自动调整,以确保分数函数为距离所需位置2公里的酒店计算出0.33的分数。
在第二个示例中,字段值在2013-09-12和2013-09-22之间的文档将获得1.0的权重,而距离该日期15天的文档将获得0.5的权重。
支持的衰减函数
editThe DECAY_FUNCTION 决定了衰减的形状:
-
gauss -
正常衰减,计算公式为:

其中
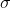 的计算是为了确保分数在距离
的计算是为了确保分数在距离 origin+-offset的scale处取值为decay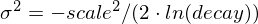
参见正常衰减,关键字
gauss,了解展示由gauss函数生成的曲线的图表。 -
exp -
指数衰减,计算公式为:
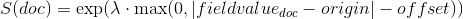
再次计算参数
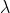 以确保分数在距离
以确保分数在距离 origin+-offset的scale处取值为decay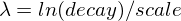
参见指数衰减,关键字
exp,了解展示由exp函数生成的曲线的图表。 -
linear -
线性衰减,计算公式为:
 。
。再次计算参数
s以确保分数在距离origin+-offset的scale处取值为decay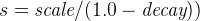
与正常和指数衰减不同,如果字段值超过用户给定比例值的两倍,此函数实际上会将分数设置为0。
对于单个函数,三个衰减函数及其参数可以像这样可视化(在这个例子中,字段称为“age”):
多值字段
edit如果用于计算衰减的字段包含多个值,默认情况下会选择最接近原点的值来确定距离。
可以通过设置multi_value_mode来改变这一行为。
|
|
距离是最小距离 |
|
|
距离是最大距离 |
|
|
距离是平均距离 |
|
|
距离是所有距离的总和 |
示例:
"DECAY_FUNCTION": {
"FIELD_NAME": {
"origin": ...,
"scale": ...
},
"multi_value_mode": "avg"
}
详细示例
edit假设你在某个城镇寻找一家酒店。你的预算有限。此外,你希望酒店靠近市中心,因此酒店离理想位置越远,你入住的可能性就越小。
您希望查询结果符合您的条件(例如,“酒店,南希,非吸烟者”)根据距离市中心和价格进行评分。
直观地,您可能希望将城镇中心定义为原点,并且您可能愿意从酒店步行2公里到达城镇中心。
在这种情况下,位置字段的原点是城镇中心,而比例约为2公里。
如果你的预算较低,你可能会更喜欢便宜的东西而不是昂贵的东西。对于价格字段,原点将是0欧元,而尺度取决于你愿意支付多少,例如20欧元。
在这个例子中,字段可能被称为“price”用于酒店的价格,以及“location”用于该酒店的坐标。
在这种情况下,price 的函数将是
和对于位置:
假设你想将这两个函数乘以原始分数,请求将如下所示:
GET /_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"price": {
"origin": "0",
"scale": "20"
}
}
},
{
"gauss": {
"location": {
"origin": "11, 12",
"scale": "2km"
}
}
}
],
"query": {
"match": {
"properties": "balcony"
}
},
"score_mode": "multiply"
}
}
}
接下来,我们展示如何为每种可能的衰减函数计算得分。
正常衰减,关键字 gauss
edit当在上面的例子中选择gauss作为衰减函数时,乘数的等高线和表面图看起来像这样:


假设您的原始搜索结果匹配了三家酒店:
- "背包小憩"
- "边喝边开"
- "贝尔维尤民宿".
“Drink n Drive”离您定义的位置相当远(近2公里),而且价格也不算便宜(约13欧元),因此它的因子较低,为0.56。“BnB Bellevue”和“Backpack Nap”都离定义的位置很近,但“BnB Bellevue”更便宜,因此它的乘数为0.86,而“Backpack Nap”的值为0.66。




衰减函数支持的字段
edit仅支持数值、日期和地理位置字段。
如果缺少一个字段怎么办?
edit如果文档中缺少数值字段,该函数将返回 1。