提取、过滤和转换内容
edit提取、过滤和转换内容
editElastic 连接器提供了多种工具,用于从第三方数据源中提取、过滤和转换内容。 每个连接器都有其特定的默认逻辑,适用于特定的数据源,并且每个 Elastic Search 部署都使用默认的摄取管道来提取和转换数据。 还提供了几种工具,用于更高级的使用场景。
以下图表概述了如何在连接器的数据管道中协调内容提取、同步规则和摄取管道。

默认情况下,只有连接器特定的逻辑(2)和默认的 ent-search-generic-ingestion 管道(6)会提取和转换您的数据,如在您的部署中配置的那样。
以下工具适用于更高级的使用场景:
- 高级同步规则 (1). 在数据到达连接器之前,在数据源级别进行远程过滤。
- 基本同步规则 (4) 或 提取服务 (3). 由连接器控制的集成过滤。
- 摄取管道 (6). 自定义管道过滤,Elasticsearch在索引之前过滤数据。
了解更多信息,请参阅以下文档链接。
内容提取
edit连接器有一个默认的内容提取服务,加上用于高级用例的自托管提取服务。
详情请参阅内容提取。
同步规则
edit使用同步规则来帮助控制哪些文档在第三方数据源和Elasticsearch之间同步。 同步规则使您能够在数据管道的早期阶段过滤数据,这样更高效且更安全。
- 基本同步规则对所有连接器都是相同的。
- 高级同步规则是数据源特定的。 它们涵盖了复杂的查询和过滤场景,定义在DSL JSON片段中。
详情请参阅同步规则。
摄取管道
edit摄取管道是用户定义的处理器序列,用于在文档被索引到Elasticsearch之前对其进行修改。 使用摄取管道进行数据增强、规范化等操作。
Elastic 连接器使用默认的摄取管道,您可以复制并自定义以满足您的需求。
请参阅 Elasticsearch 文档中的搜索中的摄取管道。
内容提取
edit连接器使用Elastic ingest attachment processor来提取文件内容。 处理器使用Apache Tika文本提取库来提取文件。 内容提取的逻辑定义在utils.py中。
虽然主要用于PDF和Microsoft Office格式,但您可以使用任何支持的格式。
企业搜索使用一个Elasticsearch 摄取管道来支持网络爬虫的二进制内容提取。
默认管道,ent-search-generic-ingestion,在企业搜索首次启动时自动创建。
您可以在 Kibana 中查看此管道。 自定义您的管道使用也是一个选项。 请参阅用于搜索索引的摄取管道。
对于高级用例,可以使用自托管提取服务来从大于10MB的文件中提取内容。
支持的文件类型
edit以下文件类型受支持:
-
.txt -
.py -
.rst -
.html -
.markdown -
.json -
.xml -
.csv -
.md -
.ppt -
.rtf -
.docx -
.odt -
.xls -
.xlsx -
.rb -
.paper -
.sh -
.pptx -
.pdf -
.doc
摄取附件处理器不支持压缩文件,例如包含一组PDF的存档文件。 请解压存档文件,并使各个未压缩的文件可供连接器处理。
提取服务
edit目前,通过提取服务从大文件中提取内容的功能仅适用于我们的一部分自管理连接器。 它不适用于在Elastic Cloud上运行的Elastic管理连接器。 此功能目前处于测试版。
标准内容提取通过附件处理器完成,使用 Elasticsearch Ingest Pipelines。 自管理连接器将管道提取的文件大小限制为每个文件 10MB(Elasticsearch 也有每个文件 100MB 的硬性限制)。
对于需要从超过这些限制的文件中提取内容的使用场景,可以使用自管理提取服务来自管理连接器。
与将文件作为附件发送到Elasticsearch不同,文件内容在摄取之前由提取服务在边缘提取。
提取的文本随后在摄取时作为文档的body字段包含在内。
要使用此功能,您需要执行以下操作:
- 运行自托管的内容提取服务
- 添加所需的配置设置
-
将可配置字段
use_text_extraction_service的值设置为true
数据提取服务代码现已在此公共仓库中提供:https://github.com/elastic/data-extraction-service。
可用的连接器
edit本地内容提取适用于以下自托管连接器:
运行提取服务
edit自托管的内容提取由一个独立的提取服务处理。
提取服务的版本与Elastic堆栈不一致。
对于8.11.x(包括9.0.0-beta1)之后的版本,您应该使用提取服务版本0.3.x。
您可以使用以下命令运行服务:
$ docker run \ -p 8090:8090 \ -it \ --name extraction-service \ docker.elastic.co/integrations/data-extraction-service:$EXTRACTION_SERVICE_VERSION
配置提取服务
edit您可以通过添加所需的配置,使您的自托管连接器使用自托管提取服务。 自托管连接器通过配置文件中是否存在这些字段来确定是否启用了提取服务。
-
打开你选择的文本编辑器中的
config.yml配置文件。 - 添加以下字段。它们可以添加到文件中的任何位置,只要它们从根级别开始。
# data-extraction-service settings extraction_service: host: http://localhost:8090
在自托管连接器和提取服务之间没有密码保护。 自托管提取仅应在两个服务运行在同一网络且位于同一防火墙后时使用。
| Field | Description |
|---|---|
|
提取服务的端点。如果自托管连接器与服务运行在同一台服务器上,可以使用 |
自托管连接器将在启动时对配置的host值执行预检。如果数据提取服务被找到并且正常运行,日志中将输出以下行。
Data extraction service found at <HOST>.
如果在启动时没有看到此日志,请参阅排查自托管内容提取服务问题。
高级配置
edit以下字段可以包含在配置文件中。它们是可选的,如果未指定,将回退到默认值。
# data-extraction-service settings extraction_service: host: http://localhost:8090 timeout: 30 use_file_pointers: false stream_chunk_size: 65536 shared_volume_dir: '/app/files'
| Advanced Field | Description |
|---|---|
|
内容提取的超时限制(以秒为单位)。如果未设置,默认为 |
|
是否使用文件指针而不是将文件发送到提取服务。默认为 |
|
文件被分块的大小,以便于流式传输到提取服务,单位为字节。默认为 65536(64 KB)。仅在 |
|
数据提取服务将从中提取文件的共享卷。默认为 |
使用文件指针
edit自托管的提取服务可以设置为使用文件指针而不是通过HTTP请求发送文件。 文件指针比发送文件更快且消耗更少的内存,但要求连接器框架和提取服务能够共享文件系统。 这可以通过docker化和非docker化的自管理连接器来设置。
非Docker化自管理连接器的配置
edit如果您正在运行非Docker化的自托管连接器版本,您需要确定用于下载文件进行提取的本地目录。 这个目录可以是您文件系统中任何您觉得合适的位置。 请注意,自托管连接器将下载具有随机文件名的文件到此目录,因此任何已存在的文件都有可能被覆盖。 因此,我们建议为自托管提取使用一个专用的目录。
-
在这个示例中,我们将使用
/app/files作为本地目录和容器目录。 当你运行提取服务 docker 容器时,你可以使用命令行选项-v /app/files:/app/files将目录挂载为卷。$ docker run \ -p 8090:8090 \ -it \ -v /app/files:/app/files \ --name extraction-service \ docker.elastic.co/integrations/data-extraction-service:$EXTRACTION_SERVICE_VERSION
由于此功能在非Docker化设置的代码库中的工作方式,本地文件路径和Docker容器的文件路径必须相同。 例如,如果使用
/app/files,则必须将目录挂载为-v /app/files:/app/files。 如果任一目录不同,自托管连接器将无法为提取服务提供准确的文件指针。在使用Docker化的自托管连接器时,这不是一个因素。 -
接下来,在运行自托管连接器之前,请确保使用正确的信息更新配置文件。
# data-extraction-service settings extraction_service: host: http://localhost:8090 use_file_pointers: true shared_volume_dir: '/app/files'
- 然后剩下的就是启动自托管连接器并运行同步。 如果你遇到任何意外错误,请参考 自托管内容提取服务的故障排除。
配置用于docker化的自管理连接器
edit在使用从docker化的自管理连接器进行自托管提取时,除了在docker中运行自管理连接器之外,还需要一些额外的步骤。
- 自托管的提取服务需要与自管理的连接器和Elasticsearch共享相同的网络。
- 自管理的连接器和提取服务还需要共享一个卷。你可以决定在这些docker容器中将卷挂载到哪个目录,但目录必须对两个docker容器相同。
-
首先,为两个 Docker 容器设置一个共享卷。这将用于下载文件并从中提取文件。
$ docker volume create --name extraction-service-volume
-
如果您还没有设置网络,您现在可以创建它。
$ docker network create elastic
-
在运行提取服务时,将docker卷名和网络作为参数包含进去。 在这个例子中,我们将使用
/app/files作为我们的容器目录。$ docker run \ -p 8090:8090 \ -it \ -v extraction-service-volume:/app/files \ --network "elastic" \ --name extraction-service \ docker.elastic.co/integrations/data-extraction-service:$EXTRACTION_SERVICE_VERSION
-
接下来,您可以按照在docker中运行自托管连接器的说明进行操作,直到步骤
4. 更新您的自托管连接器的配置文件。 在设置配置时,请务必为自托管内容提取服务添加以下设置。 请注意,host现在将指向内部docker端点,而不是localhost。# data-extraction-service settings extraction_service: host: http://host.docker.internal:8090 use_file_pointers: true shared_volume_dir: '/app/files'
-
接下来,在步骤
5. 运行 Docker 镜像中,我们只需要在运行命令中添加新的共享卷,使用-v extraction-service-volume:/app/files。$ docker run \ -v ~/connectors-config:/config \ -v extraction-service-volume:/app/files \ --network "elastic" \ --tty \ --rm \ docker.elastic.co/integrations/elastic-connectors:$CONNECTOR_CLIENT_VERSION \ /app/bin/elastic-ingest \ -c /config/config.yml
- 现在,自托管连接器和提取服务的 Docker 容器应该已经设置为共享文件。 运行测试同步以确保所有内容都配置正确。 如果您遇到任何意外错误,请参阅 排查自托管提取服务的问题。
自托管提取服务日志
edit提取服务生成两个不同的日志文件,这些文件在故障排除时可能会有所帮助。这些文件在docker容器内部保存在以下文件位置:
-
/var/log/openresty.log用于请求流量日志 -
/var/log/tika.log用于tikaserver jar日志
可以通过结合使用 docker exec 和 tail 命令从 Docker 外部查看日志。
$ docker exec extraction-service /bin/sh -c "tail /var/log/openresty.log" $ docker exec extraction-service /bin/sh -c "tail /var/log/tika.log"
排查自托管提取服务的故障
edit在使用自托管提取服务时,可能会出现以下警告日志。 本节中的每个日志后面都附有对其可能原因的描述以及建议的修复方法。
Extraction service is not configured, skipping its preflight check.
配置文件缺少extraction_service.host字段。
如果你想使用此服务,请检查配置是否格式正确,并确保所需字段存在。
Data extraction service found at <HOST>, but health-check returned <RESPONSE STATUS>.
/ping 端点返回了一个非 200 的响应。
这可能意味着提取服务不健康,可能需要重新启动,或者配置的 extraction_service.host 不正确。
您可以在 数据提取服务日志 中找到更多关于发生了什么的信息。
Expected to find a running instance of data extraction service at <HOST> but failed. <ERROR>.
健康检查返回了超时或客户端连接错误。
-
超时可能是由于提取服务服务器未运行,或者无法从配置文件中配置的
主机访问。 - 服务器连接错误是提取服务的内部错误。您需要调查数据提取服务日志。
Extraction service has been initialised but no extraction service configuration was found. No text will be extracted for this sync.
您已为连接器启用了自托管提取服务,但配置文件中缺少 extraction_service.host 字段。
请检查配置是否格式正确,并确保所需字段存在。
Extraction service could not parse <FILENAME>. Status: <RESPONSE STATUS>; <ERROR NAME>: <ERROR MESSAGE>.
每次文件无法提取时,都会出现此警告。
通常,body 字段中以空字符串进行索引。
连接器同步规则
edit使用连接器同步规则来帮助控制哪些文档在第三方数据源和Elasticsearch之间同步。
在Kibana UI中为每个连接器索引定义同步规则,位于索引的同步规则标签下。
可用性和先决条件
edit在 Elastic 版本 8.8.0 及更高版本 中,所有连接器都支持 基本 同步规则。
一些连接器支持高级同步规则。 了解更多信息,请参阅各个连接器的参考文档。
同步规则的类型
edit有两种同步规则:
- 基本同步规则 - 这些规则以表格视图的形式表示。 基本同步规则对所有连接器都是相同的。
- 高级同步规则 - 这些规则涵盖了无法用基本同步规则表达的复杂查询和过滤场景。 高级同步规则通过特定于源的DSL JSON片段定义。

通用数据过滤概念
edit在讨论同步规则之前,建立对数据过滤概念的基本理解是很重要的。 下图显示了数据过滤可以在几个不同的过程/位置发生。
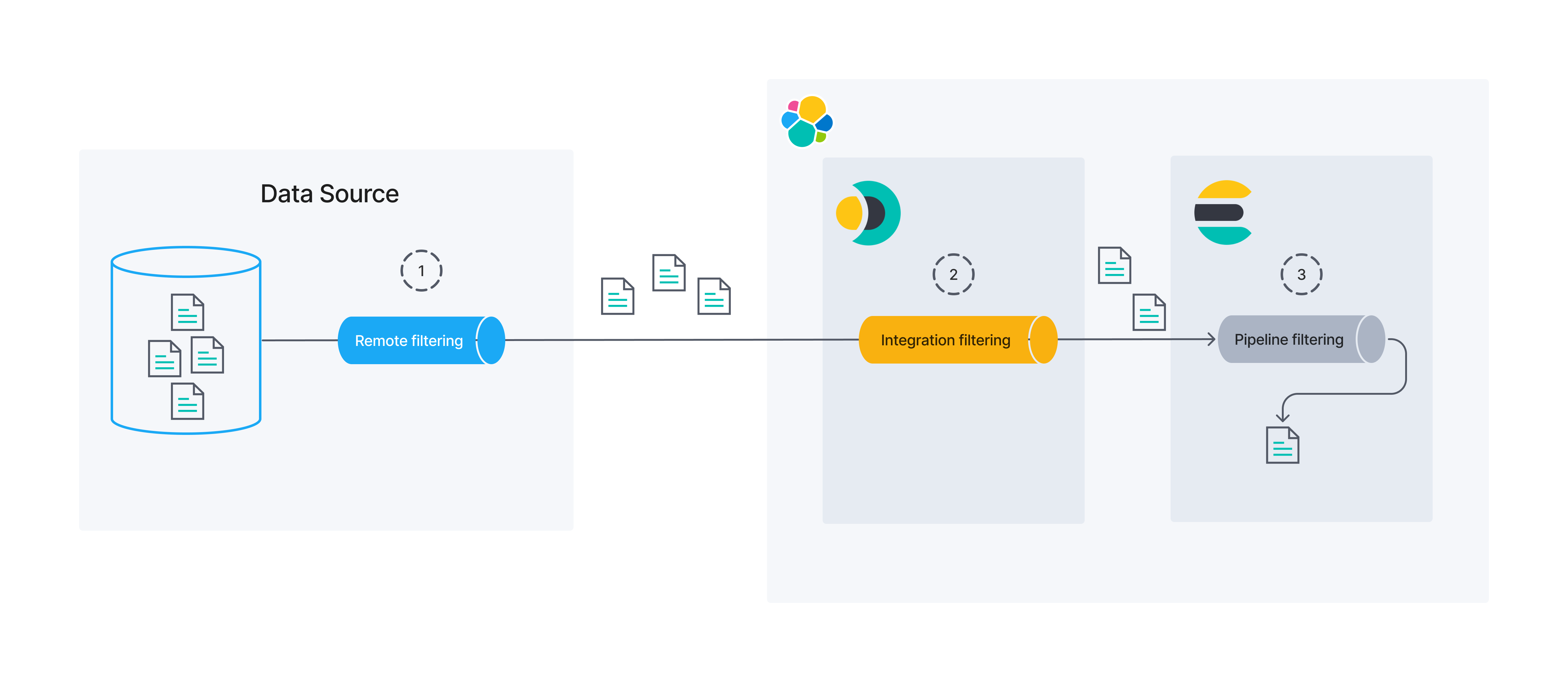
在本文档中,我们将重点介绍远程和集成过滤。 同步规则可以用于修改这两者。
远程过滤
edit数据可能在源头被过滤。 我们称之为远程过滤,因为过滤过程是在 Elastic 之外进行的。
集成过滤
edit集成过滤充当原始数据源和Elasticsearch之间的桥梁。 在连接器中进行的过滤是集成过滤的一个例子。
管道过滤
edit最后,Elasticsearch 可以在数据持久化之前使用 ingest pipelines 进行过滤。 本指南中我们将不重点讨论 ingest pipeline 过滤。
目前,基本同步规则是控制连接器集成过滤的唯一方法。 请记住,远程过滤的范围远远超出了连接器本身。 为了获得最佳效果,请与您的数据源的所有者和维护者合作。 确保源数据组织良好,并针对连接器进行的查询类型进行了优化。
同步规则概述
edit在大多数情况下,您的数据湖将包含远比您希望向最终用户公开的数据更多的数据。 例如,您可能希望搜索产品目录,但不包括供应商联系信息,即使这两者出于业务目的而共存。
过滤数据的最佳时间是在数据管道的早期阶段。主要有两个原因:
- 性能: 向后备数据源发送查询比获取所有数据然后在连接器中进行过滤更高效。 通过网络发送较小的数据集并在连接器端处理它更快。
- 安全性: 查询时过滤在数据源端应用,因此数据不会通过网络发送到连接器,从而限制了数据的暴露。
在一个理想的世界中,所有的过滤操作都将在远程进行。
然而,在实践中,这并不总是可能的。 一些数据源不允许进行强大的远程过滤。 另一些则允许,但需要特殊的设置(在特定字段上建立索引、调整设置等),这可能需要您组织中其他利益相关者的关注。
考虑到这一点,同步规则被设计为修改远程过滤和集成过滤。 您的目标应该是尽可能多地进行远程过滤,但集成是一个完全可行的备用方案。 根据定义,远程过滤是在从第三方源获取数据之前应用的。 集成过滤是在从第三方源获取数据之后,但在将其摄取到Elasticsearch索引之前应用的。
所有同步规则都应用于给定文档之前,任何摄取管道都在该文档上运行。 因此,您可以使用摄取管道进行任何必须在集成过滤发生后之后进行的处理。
如果添加、编辑或删除了同步规则,它只会在下一次完全同步后生效。
基本同步规则
edit每个基本同步规则可以是两种“策略”之一:include 和 exclude。
Include 规则用于包含“匹配”指定条件的文档。
Exclude 规则用于排除“匹配”指定条件的文档。
“匹配”是根据由“字段”、“规则”和“值”组合定义的条件来确定的。
应使用字段列来定义应考虑给定文档上的哪个字段。
以下规则可在规则列中使用:
-
equals- 字段值等于指定的值。 -
starts_with- 字段值以指定的(字符串)值开头。 -
ends_with- 字段值以指定的(字符串)值结尾。 -
contains- 字段值包含指定的(字符串)值。 -
regex- 字段值匹配指定的正则表达式。 -
>- 字段值大于指定的值。 -
<- 字段值小于指定的值。
最后,Value 列依赖于:
- 指定“字段”中的数据类型
- 选择了哪个“规则”。
例如,对于一个regex规则,[A-Z]{2}这样的值可能是有意义的,但对于一个>规则来说,意义就不大了。
同样,当你处理一个ip_address字段时,你可能不会使用espresso这样的值,但对于一个beverage字段,你可能会使用。
基本同步规则示例
edit示例 1
edit排除所有在ID字段中值大于1000的文档。

示例 2
edit排除所有在state字段中匹配指定正则表达式的文档。

性能影响
edit- 如果你在集成过滤阶段仅依赖于基本的同步规则,连接器将从数据源中获取所有数据
- 对于没有自动分页或类似优化的数据源,获取所有数据可能会导致内存问题。 例如,加载一次无法放入内存的大型数据集。
Elastic 提供的原生 MongoDB 连接器使用分页,因此具有优化的性能。 请记住,自定义的社区构建的自管理连接器可能没有这些性能优化。
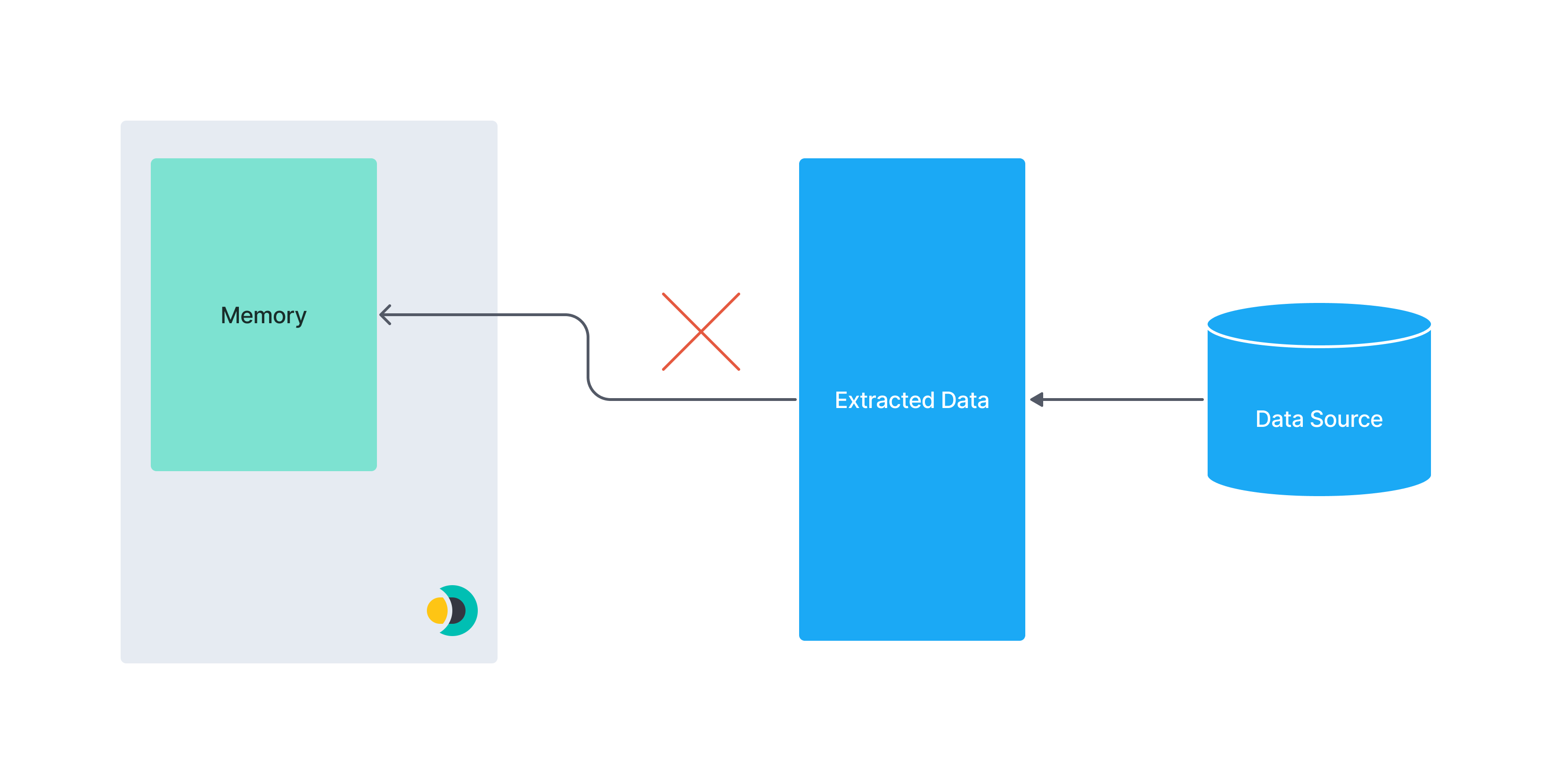
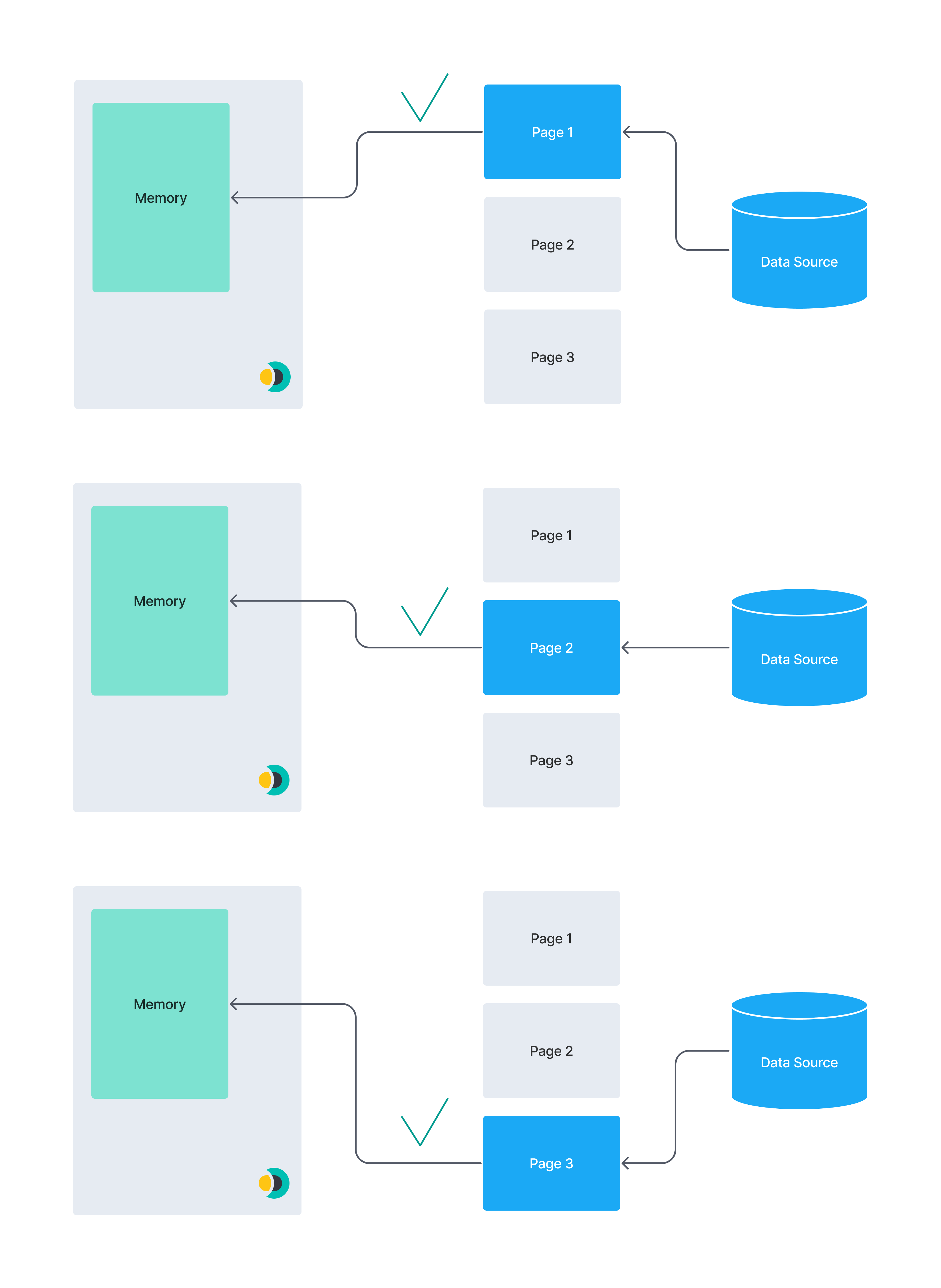
以下图表说明了分页的概念。 一个庞大的数据集可能无法完全加载到连接器实例的内存中。 将数据分割成更小的块可以降低内存不足错误的风险。
此图展示了一次性提取整个数据集的过程:
相比之下,此图展示了一个分页数据集:
高级同步规则
edit高级同步规则会覆盖任何可以从基本同步规则推断出的远程过滤查询。如果定义了高级同步规则,任何定义的基本同步规则将专门用于集成过滤。
高级同步规则仅用于远程过滤。 你可以将高级同步规则视为一种与语言无关的方式来表示对数据源的查询。 因此,这些规则具有高度的源特定性。
以下连接器支持高级同步规则:
每个支持高级同步规则的连接器都提供了自己的DSL来指定规则。 请参阅每个连接器的文档以获取详细信息。
结合基本和高级同步规则
edit您还可以同时使用基本同步规则和高级同步规则来过滤数据集。
以下图表概述了高级同步规则、基本同步规则和管道过滤器应用于您的文档的顺序:

示例
edit在下面的示例中,我们希望过滤一个包含公寓的数据集,使其仅包含具有特定属性的公寓。 我们将在整个示例中使用基本和高级同步规则。
一个示例公寓在 .json 格式中看起来像这样:
{
"id": 1234,
"bedrooms": 3,
"price": 1500,
"address": {
"street": "Street 123",
"government_area": "Area",
"country_information": {
"country_code": "PT",
"country": "Portugal"
}
}
}
目标数据集应满足以下条件:
- 每个公寓至少应有3间卧室
- 公寓的租金不应超过每月1500
- id为1234的公寓应被包括在内,不考虑前两个条件
- 每个公寓应位于葡萄牙或西班牙
前3个条件可以通过基本的同步规则来处理,但对于第4个条件,我们需要使用高级同步规则。
基本同步规则示例
edit要创建一个新的基本同步规则,请导航到同步规则标签页并选择起草新的同步规则:
之后,您需要按下保存并验证草稿按钮来验证这些规则。 请注意,保存后规则将处于草稿状态。除非它们被应用,否则它们不会在下次同步时执行。
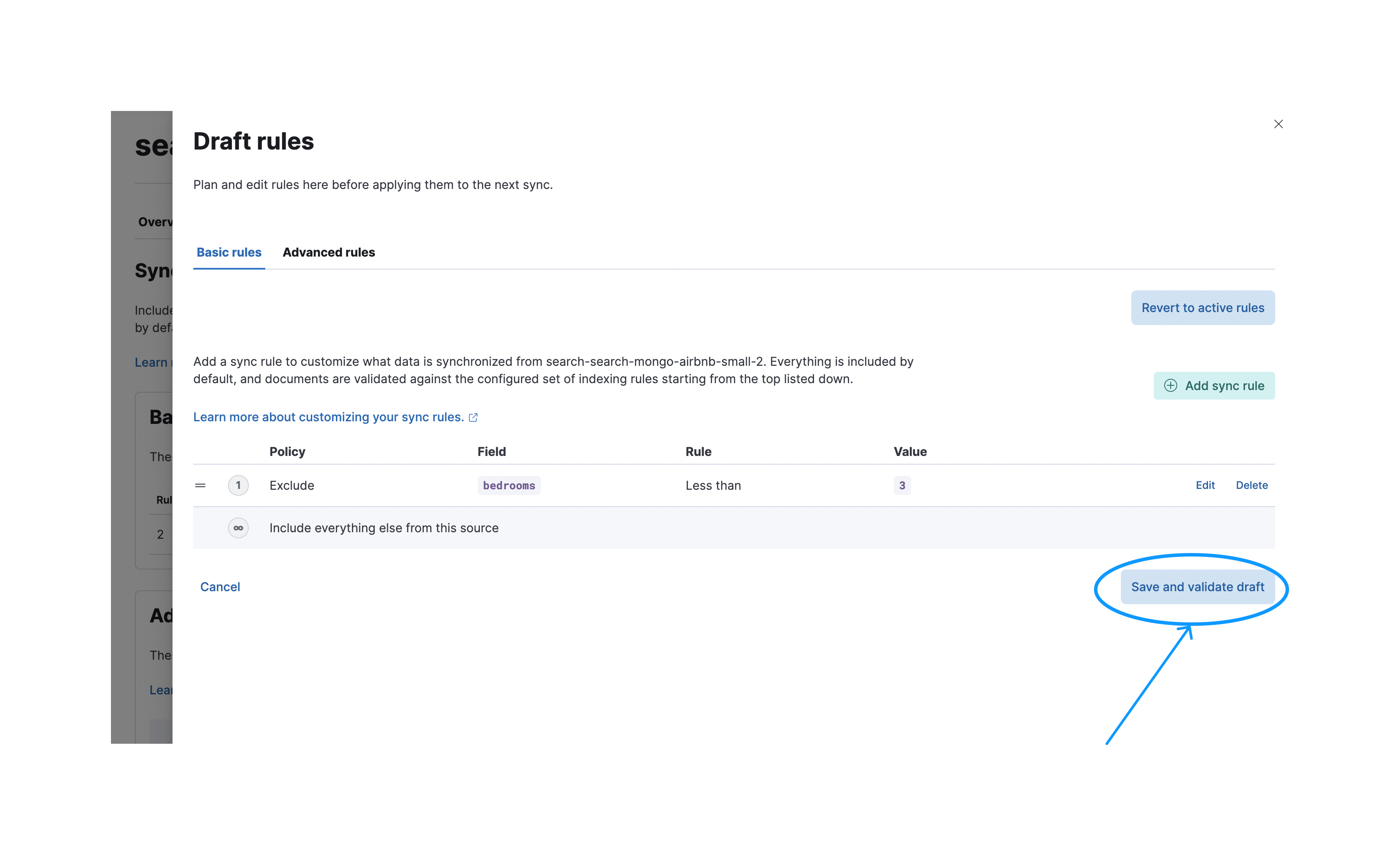
成功验证后,您可以应用您的规则,以便它们在下次同步时执行。
以下条件可以通过基本同步规则覆盖:
- id为1234的公寓应被包括在内,不考虑前两个条件
- 每套公寓应至少有三间卧室
- 公寓的租金不应超过1000/月
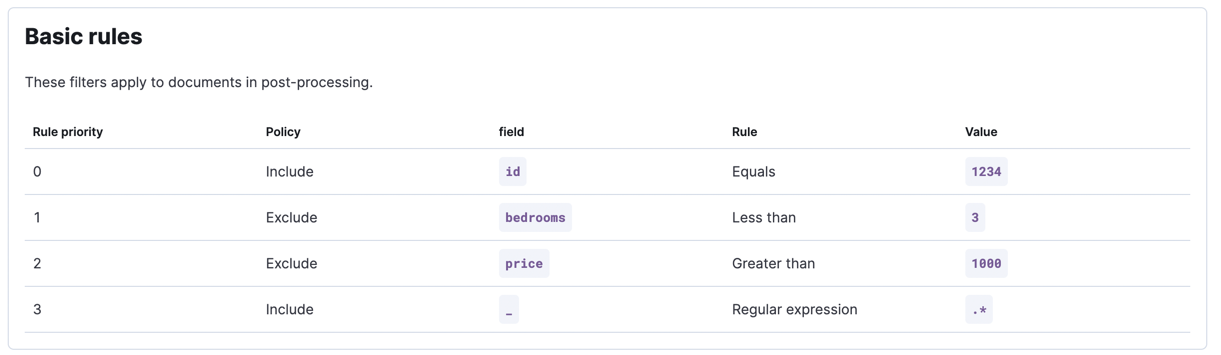
请记住,对于基本的同步规则,顺序很重要。 不同的顺序可能会导致不同的结果。
高级同步规则示例
edit您只想包括位于葡萄牙或西班牙的公寓。 我们需要在这里使用高级同步规则,因为我们处理的是深度嵌套的对象。
假设公寓数据存储在MongoDB实例中。 对于MongoDB,我们在高级同步规则中支持聚合管道等功能。 一个仅选择位于葡萄牙或西班牙的房产的聚合管道如下所示:
[
{
"$match": {
"$or": [
{
"address.country_information.country": "Portugal"
},
{
"address.country_information.country": "Spain"
}
]
}
}
]
要创建这些高级同步规则,请导航到同步规则创建对话框并选择高级规则选项卡。
您现在可以将聚合管道粘贴到aggregate.pipeline下的输入字段中:
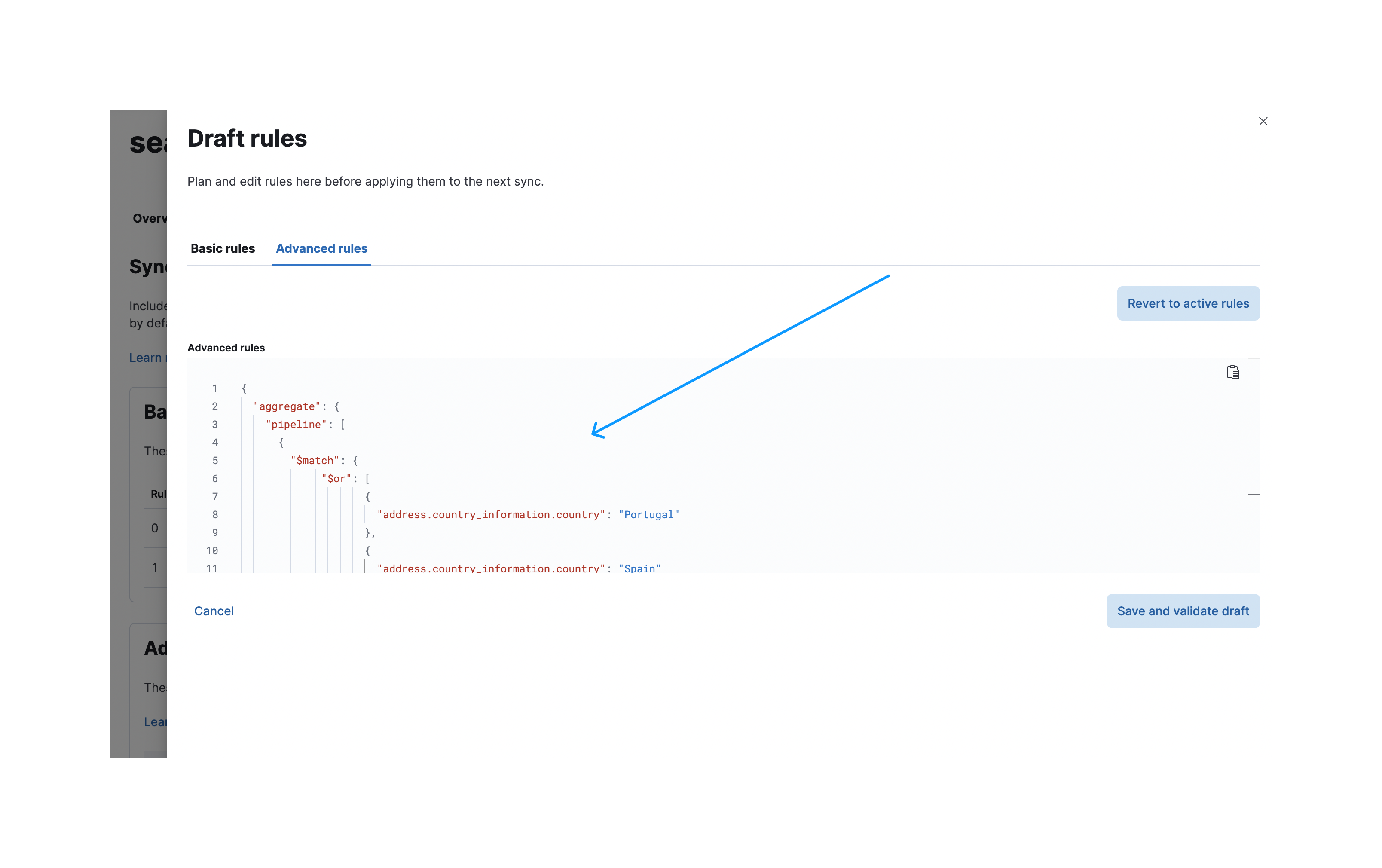
一旦验证通过,应用这些规则。 以下截图显示了已应用的同步规则,这些规则将在下一次同步中执行:

成功同步后,您可以展开同步详情以查看应用了哪些规则:
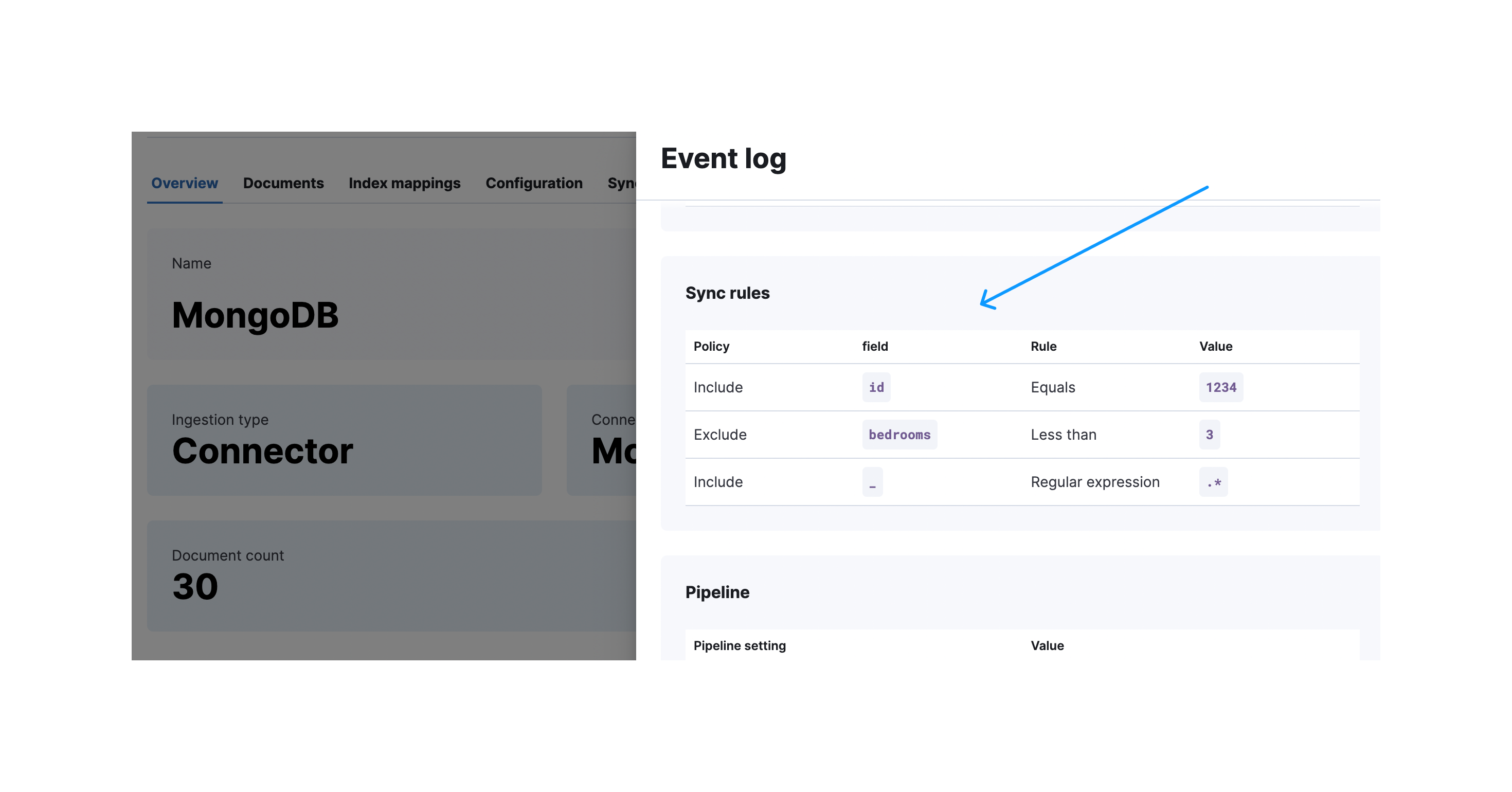
当在UI外部进行更改时,活动同步规则可能会变为无效。 具有无效规则的同步作业将会失败。 一种解决方法是重新验证草稿规则并覆盖无效的活动规则。