推理API
edit推理API
edit此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
推理API使您能够使用某些服务,例如内置的机器学习模型(ELSER、E5)、通过Eland上传的模型、Cohere、OpenAI、Azure、Google AI Studio或Hugging Face。对于内置模型和通过Eland上传的模型,推理API提供了一种替代方式来使用和管理训练好的模型。但是,如果您不打算使用推理API来使用这些模型,或者如果您想使用非NLP模型,请使用机器学习训练模型API。
推理API使您能够创建推理端点并使用不同提供商的机器学习模型 - 例如Amazon Bedrock、Anthropic、Azure AI Studio、Cohere、Google AI、Mistral、OpenAI或HuggingFace - 作为服务。使用以下API来管理推理模型并执行推理:
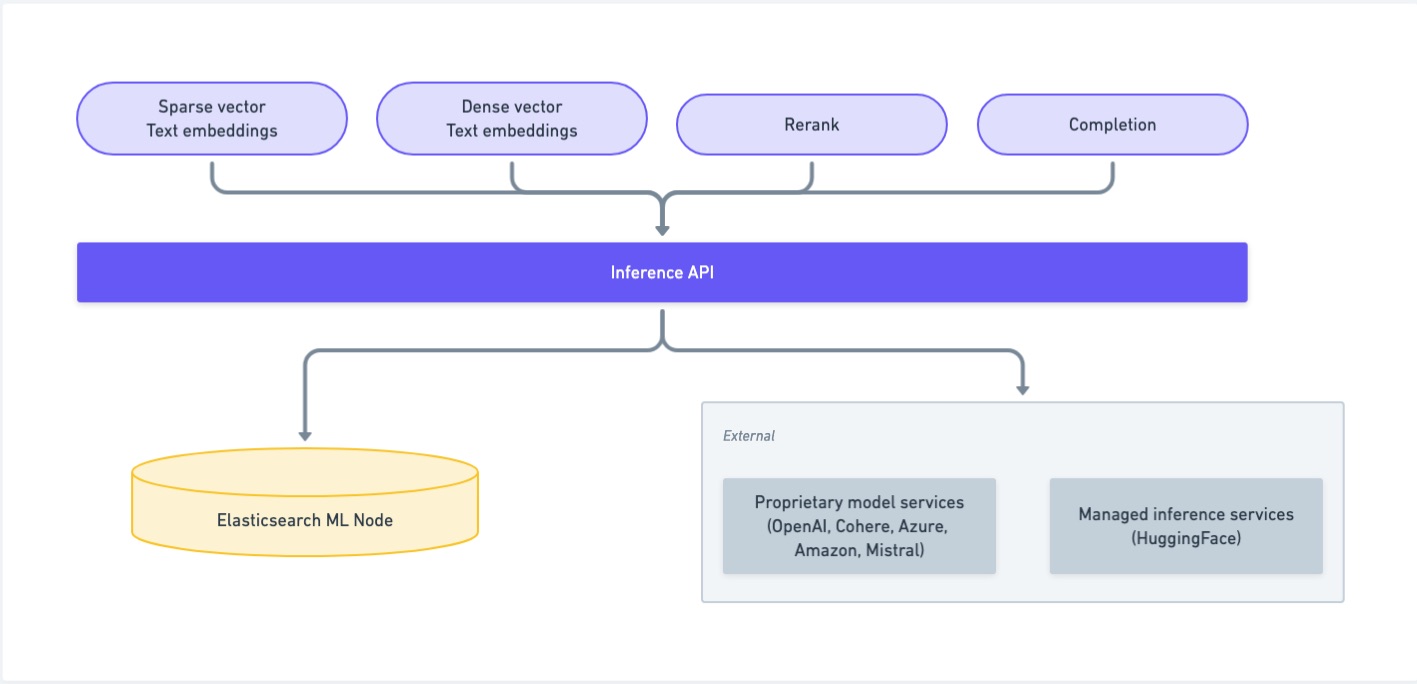
推理端点使您能够使用相应的机器学习模型,而无需手动部署,并通过语义文本在数据摄取时将其应用于您的数据。
从您的提供商中选择一个模型,或者使用由Elastic训练的检索模型ELSER,然后通过创建推理API创建一个推理端点。现在使用语义文本对您的数据执行语义搜索。
删除推理API
edit此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
删除一个推理端点。
推理API使您能够使用某些服务,例如内置的机器学习模型(ELSER、E5)、通过Eland上传的模型、Cohere、OpenAI、Azure、Google AI Studio、Google Vertex AI、Anthropic、Watsonx.ai或Hugging Face。 对于内置模型和通过Eland上传的模型,推理API提供了一种替代方式来使用和管理训练好的模型。 但是,如果您不打算使用推理API来使用这些模型,或者如果您想使用非NLP模型,请使用机器学习训练模型API。
请求
editDELETE /_inference/
DELETE /_inference/
前提条件
edit-
需要
manage_inference集群权限 (内置的inference_admin角色授予此权限)
路径参数
edit- <inference_id>
- (必需, 字符串) 要删除的推理端点的唯一标识符。
- <task_type>
- (可选, 字符串) 模型执行的推理任务的类型。
查询参数
edit-
dry_run -
(可选,布尔值)
当
true时,检查semantic_text字段和引用该端点的推理处理器,并将它们以列表形式返回,但不删除该端点。 默认为false。 -
force -
(可选, 布尔值)
无论端点是否在
semantic_text字段或推理管道中使用,都会删除该端点。
示例
edit以下 API 调用删除了可以执行 sparse_embedding 任务的 my-elser-model 推理模型。
DELETE /_inference/sparse_embedding/my-elser-model
API返回以下响应:
{
"acknowledged": true
}
获取推理API
edit此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
检索推理端点信息。
推理API使您能够使用某些服务,例如内置的机器学习模型(ELSER、E5)、通过Eland上传的模型、Cohere、OpenAI、Azure、Google AI Studio、Google Vertex AI、Anthropic、Watsonx.ai或Hugging Face。 对于内置模型和通过Eland上传的模型,推理API提供了一种替代方式来使用和管理训练好的模型。 但是,如果您不打算使用推理API来使用这些模型,或者如果您想使用非NLP模型,请使用机器学习训练模型API。
请求
editGET /_inference
GET /_inference/_all
GET /_inference/
GET /_inference/
GET /_inference/
前提条件
edit-
需要
monitor_inference集群权限 (内置的inference_admin和inference_user角色授予此权限)
描述
edit您可以通过单个API请求获取以下信息:
- 通过提供任务类型和推理ID来获取单个推理端点,
- 通过提供任务类型和通配符表达式来获取某个任务类型的所有推理端点,
- 通过使用通配符表达式来获取所有推理端点。
路径参数
edit-
<inference_id> - (可选, 字符串) 推理端点的唯一标识符。
-
<task_type> - (可选, 字符串) 模型执行的推理任务的类型。
示例
edit以下 API 调用检索有关可以执行 sparse_embedding 任务的 my-elser-model 推理模型的信息。
GET _inference/sparse_embedding/my-elser-model
API返回以下响应:
{
"inference_id": "my-elser-model",
"task_type": "sparse_embedding",
"service": "elser",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
},
"task_settings": {}
}
执行推理 API
edit此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
通过使用推理端点对输入文本执行推理任务。
推理API使您能够使用某些服务,例如内置的机器学习模型(ELSER、E5)、通过Eland上传的模型、Cohere、OpenAI、Azure、Google AI Studio、Google Vertex AI、Anthropic、Watsonx.ai或Hugging Face。 对于内置模型和通过Eland上传的模型,推理API提供了一种替代方式来使用和管理训练好的模型。 但是,如果您不打算使用推理API来使用这些模型,或者如果您想使用非NLP模型,请使用机器学习训练模型API。
请求
editPOST /_inference/
POST /_inference/
前提条件
edit-
需要
monitor_inference集群权限 (内置的inference_admin和inference_user角色授予此权限)
描述
editperform inference API 使您能够使用机器学习模型对您提供的输入数据执行特定任务。API 返回一个包含任务结果的响应。您使用的推理端点可以执行在创建端点时定义的特定任务,该端点是通过 Create inference API 创建的。
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> - (可选, 字符串) 模型执行的推理任务的类型。
查询参数
edit-
timeout - (可选,超时) 控制等待推理完成的时间量。默认为30秒。
请求体
edit-
input -
(必需,字符串或字符串数组) 您希望执行推理任务的文本。
input可以是一个单一字符串或一个数组。用于
completion任务类型的推理端点目前仅支持单个字符串作为输入。 -
query -
(必需, 字符串)
仅适用于
rerank推理端点。搜索查询文本。 -
task_settings -
(可选, 对象)
单个推理请求的任务设置。
这些设置是针对您指定的
示例
edit完成示例
edit以下示例对示例问题执行完成操作。
POST _inference/completion/openai_chat_completions
{
"input": "What is Elastic?"
}
API返回以下响应:
{
"completion": [
{
"result": "Elastic is a company that provides a range of software solutions for search, logging, security, and analytics. Their flagship product is Elasticsearch, an open-source, distributed search engine that allows users to search, analyze, and visualize large volumes of data in real-time. Elastic also offers products such as Kibana, a data visualization tool, and Logstash, a log management and pipeline tool, as well as various other tools and solutions for data analysis and management."
}
]
}
重排序示例
edit以下示例对示例输入执行重新排序。
POST _inference/rerank/cohere_rerank
{
"input": ["luke", "like", "leia", "chewy","r2d2", "star", "wars"],
"query": "star wars main character"
}
API返回以下响应:
{
"rerank": [
{
"index": "2",
"relevance_score": "0.011597361",
"text": "leia"
},
{
"index": "0",
"relevance_score": "0.006338922",
"text": "luke"
},
{
"index": "5",
"relevance_score": "0.0016166499",
"text": "star"
},
{
"index": "4",
"relevance_score": "0.0011695103",
"text": "r2d2"
},
{
"index": "1",
"relevance_score": "5.614787E-4",
"text": "like"
},
{
"index": "6",
"relevance_score": "3.7850367E-4",
"text": "wars"
},
{
"index": "3",
"relevance_score": "1.2508839E-5",
"text": "chewy"
}
]
}
稀疏嵌入示例
edit以下示例对示例句子执行稀疏嵌入。
POST _inference/sparse_embedding/my-elser-model
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}
API返回以下响应:
{
"sparse_embedding": [
{
"port": 2.1259406,
"sky": 1.7073475,
"color": 1.6922266,
"dead": 1.6247464,
"television": 1.3525393,
"above": 1.2425821,
"tuned": 1.1440028,
"colors": 1.1218185,
"tv": 1.0111054,
"ports": 1.0067928,
"poem": 1.0042328,
"channel": 0.99471164,
"tune": 0.96235967,
"scene": 0.9020516,
(...)
},
(...)
]
}
文本嵌入示例
edit以下示例使用Cohere集成对示例句子执行文本嵌入。
POST _inference/text_embedding/my-cohere-endpoint
{
"input": "The sky above the port was the color of television tuned to a dead channel.",
"task_settings": {
"input_type": "ingest"
}
}
API返回以下响应:
{
"text_embedding": [
{
"embedding": [
{
0.018569946,
-0.036895752,
0.01486969,
-0.0045204163,
-0.04385376,
0.0075950623,
0.04260254,
-0.004005432,
0.007865906,
0.030792236,
-0.050476074,
0.011795044,
-0.011642456,
-0.010070801,
(...)
},
(...)
]
}
]
}
创建推理API
edit此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
创建一个推理端点以执行推理任务。
- 推理API使您能够使用某些服务,例如内置的机器学习模型(ELSER、E5)、通过Eland、Cohere、OpenAI、Mistral、Azure OpenAI、Google AI Studio、Google Vertex AI、Anthropic、Watsonx.ai或Hugging Face上传的模型。
- 对于内置模型和通过Eland上传的模型,推理API提供了一种替代方式来使用和管理训练好的模型。但是,如果您不打算使用推理API来使用这些模型,或者如果您想使用非NLP模型,请使用机器学习训练模型API。
请求
editPUT /_inference/
先决条件
edit-
需要
manage_inference集群权限 (内置的inference_admin角色授予此权限)
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
请参阅API描述部分中的服务列表,了解可用的任务类型。
描述
edit创建推理API使您能够创建一个推理端点并配置一个机器学习模型以执行特定的推理任务。
以下服务可通过推理API获得。 您可以在服务名称旁边找到可用的任务类型。 点击链接查看服务的配置详情:
-
AlibabaCloud AI Search (
completion,rerank,sparse_embedding,text_embedding) -
Amazon Bedrock (
completion,text_embedding) -
Anthropic (
completion) -
Azure AI Studio (
completion,text_embedding) -
Azure OpenAI (
completion,text_embedding) -
Cohere (
completion,rerank,text_embedding) -
Elasticsearch (
rerank,sparse_embedding,text_embedding- 此服务适用于内置模型和通过 Eland 上传的模型) -
ELSER (
sparse_embedding) -
Google AI Studio (
completion,text_embedding) -
Google Vertex AI (
rerank,text_embedding) -
Hugging Face (
text_embedding) -
Mistral (
text_embedding) -
OpenAI (
completion,text_embedding) -
Watsonx inference service (
text_embedding)
Elasticsearch 和 ELSER 服务在您的 Elasticsearch 集群中的机器学习节点上运行。其余的服务连接到外部提供商。
更新推理API
edit此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
更新推理端点。
推理API使您能够使用某些服务,例如内置的机器学习模型(ELSER、E5)、通过Eland上传的模型、Cohere、OpenAI、Azure、Google AI Studio、Google Vertex AI、Anthropic、Watsonx.ai或Hugging Face。 对于内置模型和通过Eland上传的模型,推理API提供了一种替代方式来使用和管理训练好的模型。 但是,如果您不打算使用推理API来使用这些模型,或者如果您想使用非NLP模型,请使用机器学习训练模型API。
请求
editPOST _inference/
POST _inference/
前提条件
edit描述
edit更新推理 API 使您能够更新现有推理端点的 task_settings、secrets 和/或 num_allocations。
要使用更新 API,您可以根据您创建的特定端点服务和任务类型,修改 task_settings、机密(在 service_settings 内)或 num_allocations。
要查看可更新的 task_settings、机密的字段名称(特定于每个服务)以及适用 num_allocations 的服务(仅适用于 elasticsearch 服务),请参阅以下通过推理 API 提供的服务列表。
您将在每个服务名称旁边找到可用的任务类型。
点击链接以查看服务配置详情:
-
AlibabaCloud AI Search (
completion,rerank,sparse_embedding,text_embedding) -
Amazon Bedrock (
completion,text_embedding) -
Anthropic (
completion) -
Azure AI Studio (
completion,text_embedding) -
Azure OpenAI (
completion,text_embedding) -
Cohere (
completion,rerank,text_embedding) -
Elasticsearch (
rerank,sparse_embedding,text_embedding- 此服务适用于内置模型和通过 Eland 上传的模型) -
ELSER (
sparse_embedding) -
Google AI Studio (
completion,text_embedding) -
Google Vertex AI (
rerank,text_embedding) -
Hugging Face (
text_embedding) -
Mistral (
text_embedding) -
OpenAI (
completion,text_embedding)
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> - (可选, 字符串) 模型执行的推理任务类型。 有关可用任务类型的列表,请参阅API描述部分中的服务列表。
示例
edit以下示例展示了如何更新一个名为 my-inference-endpoint 的推理端点的 API 密钥:
POST _inference/my-inference-endpoint/_update
{
"service_settings": {
"api_key": "<API_KEY>"
}
}
阿里云AI搜索推理服务
edit创建一个推理端点以使用alibabacloud-ai-search服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
completion, -
rerank -
sparse_embedding, -
text_embedding.
-
请求体
edit-
service -
(必需,字符串) 指定任务类型支持的服务类型。
在这种情况下,
alibabacloud-ai-search。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
alibabacloud-ai-search服务的。-
api_key - (必需, 字符串) AlibabaCloud AI Search API 的有效 API 密钥。
-
service_id -
(必需,字符串) 用于推理任务的模型服务的名称。
可用于
completion任务的服务ID:-
ops-qwen-turbo -
qwen-turbo -
qwen-plus -
qwen-max÷qwen-max-longcontext
有关支持的
completionservice_ids,请参阅 文档。可用于
rerank任务的service_id是:-
ops-bge-reranker-larger
有关支持的
rerankservice_id,请参阅文档。可用的
sparse_embedding任务的 service_id:-
ops-text-sparse-embedding-001
有关支持的
sparse_embeddingservice_id,请参阅文档。可用的
text_embedding任务的服务ID:-
ops-text-embedding-001 -
ops-text-embedding-zh-001 -
ops-text-embedding-en-001 -
ops-text-embedding-002
有关支持的
text_embeddingservice_ids,请参阅文档。 -
-
host - (必需, 字符串) 用于推理任务的主机地址的名称。 您可以在文档的 API 密钥部分 找到主机地址。
-
workspace - (必需, 字符串) 用于推理任务的工作区的名称。
-
rate_limit -
(可选, 对象) 默认情况下,
alibabacloud-ai-search服务将每分钟允许的请求数设置为1000。 这有助于最小化从阿里云AI搜索返回的速率限制错误数量。 要修改此设置, 请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> }
-
-
task_settings -
(可选, 对象) 用于配置推理任务的设置。 这些设置是针对您指定的
task_settingsfor thetext_embeddingtask type-
input_type -
(可选, 字符串) 指定传递给模型的输入类型。 有效值为:
-
ingest: 用于在向量数据库中存储文档嵌入。 -
search: 用于存储针对向量数据库运行的搜索查询的嵌入,以查找相关文档。
-
task_settingsfor thesparse_embeddingtask type-
input_type -
(可选, 字符串) 指定传递给模型的输入类型。 有效值包括:
-
ingest: 用于在向量数据库中存储文档嵌入。 -
search: 用于存储针对向量数据库运行的搜索查询的嵌入,以查找相关文档。
-
-
return_token -
(可选, 布尔值)
如果为
true,则响应中将返回令牌名称。默认为false,这意味着响应中仅返回令牌ID。
-
阿里云AI搜索服务示例
edit以下示例展示了如何创建一个名为 alibabacloud_ai_search_completion 的推理端点,以执行 completion 任务类型。
PUT _inference/completion/alibabacloud_ai_search_completion
{
"service": "alibabacloud-ai-search",
"service_settings": {
"host" : "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com",
"api_key": "{{API_KEY}}",
"service_id": "ops-qwen-turbo",
"workspace" : "default"
}
}
下一个示例展示了如何创建一个名为 alibabacloud_ai_search_rerank 的推理端点来执行 rerank 任务类型。
PUT _inference/rerank/alibabacloud_ai_search_rerank
{
"service": "alibabacloud-ai-search",
"service_settings": {
"api_key": "<api_key>",
"service_id": "ops-bge-reranker-larger",
"host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com",
"workspace": "default"
}
}
以下示例展示了如何创建一个名为 alibabacloud_ai_search_sparse 的推理端点,以执行 sparse_embedding 任务类型。
PUT _inference/sparse_embedding/alibabacloud_ai_search_sparse
{
"service": "alibabacloud-ai-search",
"service_settings": {
"api_key": "<api_key>",
"service_id": "ops-text-sparse-embedding-001",
"host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com",
"workspace": "default"
}
}
以下示例展示了如何创建一个名为 alibabacloud_ai_search_embeddings 的推理端点,以执行 text_embedding 任务类型。
PUT _inference/text_embedding/alibabacloud_ai_search_embeddings
{
"service": "alibabacloud-ai-search",
"service_settings": {
"api_key": "<api_key>",
"service_id": "ops-text-embedding-001",
"host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com",
"workspace": "default"
}
}
Amazon Bedrock 推理服务
edit创建一个推理端点,以使用amazonbedrock服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
completion, -
text_embedding.
-
请求体
edit-
service -
(必需,字符串) 指定任务类型支持的服务类型。
在这种情况下,
amazonbedrock。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
amazonbedrock服务的。-
access_key - (必需, 字符串) 一个有效的AWS访问密钥,具有使用Amazon Bedrock和访问模型进行推理请求的权限。
-
secret_key -
(必需, 字符串)
一个有效的AWS秘密密钥,与
access_key配对。 要创建或管理访问密钥和秘密密钥,请参阅AWS文档中的管理IAM用户的访问密钥。
-
您只需在推理模型创建期间提供一次访问密钥和秘密密钥。 获取推理API不会检索您的访问密钥或秘密密钥。 创建推理模型后,您无法更改关联的密钥对。 如果您想使用不同的访问密钥和秘密密钥对,请删除推理模型并使用相同名称和更新后的密钥重新创建它。
-
provider -
(必需,字符串) 部署的模型提供者。 请注意,某些提供者可能仅支持特定任务类型。 支持的提供者包括:
-
amazontitan- 适用于text_embedding和completion任务类型 -
anthropic- 仅适用于completion任务类型 -
ai21labs- 仅适用于completion任务类型 -
cohere- 适用于text_embedding和completion任务类型 -
meta- 仅适用于completion任务类型 -
mistral- 仅适用于completion任务类型
-
-
model - (必需, 字符串) 基础模型的ID或基于基础模型的自定义模型的ARN。 基础模型ID可以在Amazon Bedrock模型ID文档中找到。 请注意,模型ID必须对所选的提供商可用,并且您的IAM用户必须有权访问该模型。
-
region - (必需, 字符串) 您的模型或ARN部署的区域。 每个模型的可用区域列表可以在按AWS区域划分的模型支持文档中找到。
-
rate_limit -
(可选, 对象) 默认情况下,
amazonbedrock服务将每分钟允许的请求数设置为240。 这有助于减少从 Amazon Bedrock 返回的速率限制错误数量。 要修改此设置, 请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> } -
task_settings -
(可选, 对象)
用于配置推理任务的设置。
这些设置特定于您指定的
task_settings用于completion任务类型-
max_new_tokens - (可选, 整数) 设置要生成的输出令牌的最大数量。 默认为 64。
-
temperature -
(可选, 浮点数)
一个介于 0.0 和 1.0 之间的数字,用于控制结果的明显创造力。在温度为 0.0 时,模型最为确定性,在温度为 1.0 时最为随机。
如果指定了
top_p或top_k,则不应使用。 -
top_p -
(可选, 浮点数)
temperature的替代方案。一个介于 0.0 到 1.0 之间的数字,用于消除低概率令牌。Top-p 使用核采样来选择其概率总和不超过某个值的顶级令牌,确保多样性和连贯性。 如果指定了temperature,则不应使用。 -
top_k -
(可选, 浮点数)
仅适用于
anthropic、cohere和mistral提供商。temperature的替代方案。将样本限制为最可能的前 K 个单词,平衡连贯性和多样性。 如果指定了temperature,则不应使用。
-
Amazon Bedrock 服务示例
edit以下示例展示了如何创建一个名为 amazon_bedrock_embeddings 的推理端点,以执行 text_embedding 任务类型。
选择您有权访问的聊天完成和嵌入模型,这些模型来自Amazon Bedrock基础模型。
PUT _inference/text_embedding/amazon_bedrock_embeddings
{
"service": "amazonbedrock",
"service_settings": {
"access_key": "<aws_access_key>",
"secret_key": "<aws_secret_key>",
"region": "us-east-1",
"provider": "amazontitan",
"model": "amazon.titan-embed-text-v2:0"
}
}
下一个示例展示了如何创建一个名为 amazon_bedrock_completion 的推理端点,以执行 completion 任务类型。
PUT _inference/completion/amazon_bedrock_completion
{
"service": "amazonbedrock",
"service_settings": {
"access_key": "<aws_access_key>",
"secret_key": "<aws_secret_key>",
"region": "us-east-1",
"provider": "amazontitan",
"model": "amazon.titan-text-premier-v1:0"
}
}
Anthropic 推理服务
edit创建一个推理端点,以使用anthropic服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
completion
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
anthropic。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
anthropic服务的。-
api_key - (必需, 字符串) Anthropic API 的有效 API 密钥。
-
model_id - (必需, 字符串) 用于推理任务的模型名称。 您可以在 Anthropic 模型 找到支持的模型。
-
rate_limit -
(可选, 对象) 默认情况下,
anthropic服务将每分钟允许的请求数设置为50。 这有助于最小化从 Anthropic 返回的速率限制错误数量。 要修改此设置, 请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> }
-
-
task_settings -
(必需,对象) 配置推理任务的设置。 这些设置是针对您指定的
task_settingsfor thecompletiontask type-
max_tokens - (必需, 整数) 在停止之前生成的最大令牌数。
-
temperature -
(可选, 浮点数) 注入到响应中的随机性量。
有关支持范围的更多详细信息,请参阅Anthropic messages API。
-
top_k -
(可选, 整数) 指定仅从每个后续令牌的前K个选项中进行采样。
仅推荐用于高级用例。通常您只需要使用
temperature。更多详情,请参阅Anthropic messages API。
-
top_p -
(可选, 浮点数) 指定使用Anthropic的核采样。
在核采样中,Anthropic计算每个后续标记的所有选项的累积分布,并按概率递减的顺序进行排序,一旦达到由
top_p指定的特定概率时,就会将其截断。你应该修改temperature或top_p中的一个,而不是同时修改两者。仅推荐用于高级用例。通常你只需要使用
temperature。更多详情,请参阅Anthropic messages API。
-
Anthropic 服务示例
edit以下示例展示了如何创建一个名为 anthropic_completion 的推理端点,以执行 completion 任务类型。
PUT _inference/completion/anthropic_completion
{
"service": "anthropic",
"service_settings": {
"api_key": "<api_key>",
"model_id": "<model_id>"
},
"task_settings": {
"max_tokens": 1024
}
}
Azure AI 工作室推理服务
edit创建一个推理端点,以使用azureaistudio服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
completion, -
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
azureaistudio。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
azureaistudio服务的。-
api_key -
(必需, 字符串) 您的 Azure AI Studio 模型部署的有效 API 密钥。 此密钥可以在您的 Azure AI Studio 账户的管理部分中,您的部署的概览页面上找到。
您只需在推理模型创建时提供一次API密钥。 获取推理API不会检索您的API密钥。 创建推理模型后,您无法更改关联的API密钥。 如果您想使用不同的API密钥,请删除推理模型并使用相同名称和更新后的API密钥重新创建。
-
target - (必需, 字符串) 您的 Azure AI Studio 模型部署的目标 URL。 这可以在您的 Azure AI Studio 账户的管理部分中,您的部署的概览页面上找到。
-
provider -
(必需,字符串) 部署的模型提供者。 请注意,某些提供者可能仅支持特定任务类型。 支持的提供者包括:
-
cohere- 适用于text_embedding和completion任务类型 -
databricks- 仅适用于completion任务类型 -
meta- 仅适用于completion任务类型 -
microsoft_phi- 仅适用于completion任务类型 -
mistral- 仅适用于completion任务类型 -
openai- 适用于text_embedding和completion任务类型
-
-
endpoint_type -
(必需, 字符串)
token或realtime之一。 指定在您的模型部署中使用的端点类型。 通过 Azure AI Studio 部署时,有 两种端点类型可用。 “按使用量付费”端点按令牌计费。 对于这些端点,您必须为您的endpoint_type指定token。 对于按使用小时数计费的“实时”端点,请指定realtime。 -
rate_limit -
(可选, 对象) 默认情况下,
azureaistudio服务将每分钟允许的请求数设置为240。 这有助于最小化从 Azure AI Studio 返回的速率限制错误数量。 要修改此设置, 请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> }
-
-
task_settings -
(可选, 对象) 用于配置推理任务的设置。 这些设置是针对您指定的
task_settingsfor thecompletiontask type-
do_sample -
(可选, 浮点数)
指示推理过程是否执行采样。
除非指定
temperature或top_p,否则无效。 -
max_new_tokens - (可选, 整数) 提供生成输出令牌的最大数量的提示。 默认为64。
-
temperature -
(可选, 浮点数)
指定采样温度的数值,范围为0.0到2.0,用于控制生成补全的明显创造力。
如果指定
top_p,则不应使用。 -
top_p -
(可选, 浮点数)
指定核采样概率的数值,范围为0.0到2.0,作为温度的替代值,使模型考虑具有核采样概率的令牌结果。
如果指定
temperature,则不应使用。
task_settingsfor thetext_embeddingtask type-
user - (可选, 字符串) 指定发出请求的用户,可用于滥用检测。
-
Azure AI Studio 服务示例
edit以下示例展示了如何创建一个名为 azure_ai_studio_embeddings 的推理端点,以执行 text_embedding 任务类型。
请注意,我们在这里没有指定模型,因为它已经通过我们的 Azure AI Studio 部署定义了。
您可以在 Azure AI Studio 模型浏览器 中找到您部署时可以选择的嵌入模型列表。
PUT _inference/text_embedding/azure_ai_studio_embeddings
{
"service": "azureaistudio",
"service_settings": {
"api_key": "<api_key>",
"target": "<target_uri>",
"provider": "<model_provider>",
"endpoint_type": "<endpoint_type>"
}
}
下一个示例展示了如何创建一个名为 azure_ai_studio_completion 的推理端点,以执行 completion 任务类型。
PUT _inference/completion/azure_ai_studio_completion
{
"service": "azureaistudio",
"service_settings": {
"api_key": "<api_key>",
"target": "<target_uri>",
"provider": "<model_provider>",
"endpoint_type": "<endpoint_type>"
}
}
您可以在 Azure AI Studio 模型浏览器 中找到您部署中可以选择的聊天完成模型列表。
Azure OpenAI 推理服务
edit创建一个推理端点,以使用azureopenai服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
completion, -
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
azureopenai。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
azureopenai服务的。-
api_key或entra_id -
(必需, 字符串) 你必须提供要么一个API密钥或一个Entra ID。 如果你两者都不提供,或者两者都提供,当你尝试创建模型时,你将会收到一个错误。 有关这些认证类型的更多详细信息,请参阅Azure OpenAI认证文档。
您只需在推理模型创建时提供一次API密钥。 获取推理API不会检索您的API密钥。 创建推理模型后,您无法更改关联的API密钥。 如果您想使用不同的API密钥,请删除推理模型并使用相同名称和更新后的API密钥重新创建。
-
resource_name - (必需, 字符串) 你的Azure OpenAI资源的名称。 你可以在你的订阅的资源列表中找到这个。
-
deployment_id - (必需, 字符串) 你部署的模型的部署名称。 你的Azure OpenAI部署可以通过链接到你的订阅的Azure OpenAI Studio门户找到。
-
api_version - (必需, 字符串) 要使用的Azure API版本ID。 我们建议使用最新的非预览支持版本。
-
rate_limit -
(可选, 对象)
azureopenai服务根据任务类型设置了每分钟允许的默认请求数量。 对于text_embedding,它设置为1440。 对于completion,它设置为120。 这有助于最小化从 Azure 返回的速率限制错误数量。 要修改此设置,请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> }
-
-
task_settings -
(可选, 对象) 用于配置推理任务的设置。 这些设置是针对您指定的
task_settingsfor thecompletiontask type-
user - (可选, 字符串) 指定发出请求的用户,可用于滥用检测。
task_settingsfor thetext_embeddingtask type-
user - (可选, 字符串) 指定发出请求的用户,可用于滥用检测。
-
Azure OpenAI 服务示例
edit以下示例展示了如何创建一个名为 azure_openai_embeddings 的推理端点,以执行 text_embedding 任务类型。请注意,我们在这里没有指定模型,因为它已经通过我们的 Azure OpenAI 部署定义了。
您可以在部署中选择的嵌入模型列表可以在Azure模型文档中找到。
PUT _inference/text_embedding/azure_openai_embeddings
{
"service": "azureopenai",
"service_settings": {
"api_key": "<api_key>",
"resource_name": "<resource_name>",
"deployment_id": "<deployment_id>",
"api_version": "2024-02-01"
}
}
下一个示例展示了如何创建一个名为 azure_openai_completion 的推理端点,以执行 completion 任务类型。
PUT _inference/completion/azure_openai_completion
{
"service": "azureopenai",
"service_settings": {
"api_key": "<api_key>",
"resource_name": "<resource_name>",
"deployment_id": "<deployment_id>",
"api_version": "2024-02-01"
}
}
您可以在以下位置找到可以在 Azure OpenAI 部署中选择的聊天完成模型列表:
Cohere 推理服务
edit创建一个推理端点,以使用cohere服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
completion, -
rerank, -
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
cohere。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
cohere服务的。-
api_key -
(必需, 字符串) 您的Cohere账户的有效API密钥。 您可以在API密钥设置页面找到您的Cohere API密钥或创建一个新的密钥。
您只需在推理模型创建时提供一次API密钥。 获取推理API不会检索您的API密钥。 创建推理模型后,您无法更改关联的API密钥。 如果您想使用不同的API密钥,请删除推理模型并使用相同名称和更新后的API密钥重新创建。
-
rate_limit -
(可选, 对象) 默认情况下,
cohere服务将每分钟允许的请求数设置为10000。 此值对所有任务类型都是相同的。 这有助于最大限度地减少从 Cohere 返回的速率限制错误数量。 要修改此设置,请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> } 关于Cohere的速率限制的更多信息可以在Cohere的生产密钥文档中找到。
service_settingsfor thecompletiontask type-
model_id -
(可选, 字符串)
用于推理任务的模型名称。
要查看可用的
completion模型,请参考 Cohere文档。
service_settingsfor thereranktask type-
model_id -
(可选, 字符串)
用于推理任务的模型名称。
要查看可用的
rerank模型,请参考 Cohere文档。
service_settingsfor thetext_embeddingtask type-
embedding_type -
(可选,字符串) 指定您希望返回的嵌入类型。 默认为
float。 有效值包括:-
byte: 用于有符号int8嵌入(这是int8的同义词)。 -
float: 用于默认的浮点嵌入。 -
int8: 用于有符号int8嵌入。
-
-
model_id -
(可选, 字符串)
用于推理任务的模型名称。
要查看可用的
text_embedding模型,请参考 Cohere文档。text_embedding的默认值是embed-english-v2.0。 -
similarity -
(可选, 字符串)
相似度度量。可以是
cosine、dot_product、l2_norm之一。 默认值基于embedding_type(float→dot_product,int8/byte→cosine)。
-
-
-
task_settings -
(可选, 对象) 用于配置推理任务的设置。 这些设置是针对您指定的
task_settingsfor thereranktask type-
return_documents - (可选, 布尔值) 指定是否在结果中返回文档文本。
-
top_n -
(可选, 整数)
要返回的最相关文档的数量,默认为文档的数量。
如果此推理端点用于
text_similarity_reranker检索器查询,并且设置了top_n,则必须大于或等于查询中的rank_window_size。
task_settingsfor thetext_embeddingtask type-
input_type -
(可选, 字符串) 指定传递给模型的输入类型。 有效值为:
-
classification: 用于通过文本分类器传递的嵌入。 -
clusterning: 用于通过聚类算法运行的嵌入。 -
ingest: 用于将文档嵌入存储在向量数据库中。 -
search: 用于存储针对向量数据库运行的搜索查询的嵌入,以查找相关文档。使用嵌入模型
v3及以上版本时,input_type字段是必需的。
-
-
truncate -
(可选,字符串) 指定API如何处理超过最大标记长度的输入。 默认为
END。 有效值为:-
NONE: 当输入超过最大输入标记长度时,返回错误。 -
START: 当输入超过最大输入标记长度时,丢弃输入的开头。 -
END: 当输入超过最大输入标记长度时,丢弃输入的结尾。
-
-
Cohere 服务示例
edit以下示例展示了如何创建一个名为 cohere-embeddings 的推理端点,以执行 text_embedding 任务类型。
PUT _inference/text_embedding/cohere-embeddings
{
"service": "cohere",
"service_settings": {
"api_key": "<api_key>",
"model_id": "embed-english-light-v3.0",
"embedding_type": "byte"
}
}
以下示例展示了如何创建一个名为 cohere-rerank 的推理端点,以执行 rerank 任务类型。
PUT _inference/rerank/cohere-rerank
{
"service": "cohere",
"service_settings": {
"api_key": "<API-KEY>",
"model_id": "rerank-english-v3.0"
},
"task_settings": {
"top_n": 10,
"return_documents": true
}
}
更多示例,请参阅 Cohere 文档。
Elasticsearch 推理服务
edit创建一个推理端点,以使用elasticsearch服务执行推理任务。
如果您通过 elasticsearch 服务使用 E5 模型,API 请求将自动下载并部署该模型(如果尚未下载)。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
rerank, -
sparse_embedding, -
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型的支持服务类型。在此情况下,
elasticsearch。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
elasticsearch服务的。-
adaptive_allocations -
(可选, 对象) 自适应分配配置对象。 如果启用,模型的分配数量将根据当前进程的负载进行设置。 当负载较高时,会自动创建新的模型分配(如果设置了
max_number_of_allocations,则需遵守其值)。 当负载较低时,会自动移除模型分配(如果设置了min_number_of_allocations,则需遵守其值)。 如果启用了adaptive_allocations,请勿手动设置分配数量。-
enabled -
(可选, 布尔值)
如果为
true,则启用adaptive_allocations。 默认为false。 -
max_number_of_allocations -
(可选, 整数)
指定可扩展到的最大分配数量。
如果设置,则必须大于或等于
min_number_of_allocations。 -
min_number_of_allocations -
(可选, 整数)
指定可扩展到的最小分配数量。
如果设置,则必须大于或等于
1。
-
-
model_id -
(必需, 字符串)
用于推理任务的模型名称。
它可以是内置模型的ID(例如,
.multilingual-e5-small用于E5)或已经 通过Eland上传的文本嵌入模型。 -
num_allocations -
(必需, 整数)
该模型在机器学习节点中分配的总数量。
增加此值通常会增加吞吐量。
如果启用了
adaptive_allocations,请勿设置此值,因为它会自动设置。 -
num_threads -
(必需, 整数)
设置每个模型分配在推理期间使用的线程数。这通常会增加每个推理请求的速度。推理过程是一个计算密集型过程;
threads_per_allocations不得超过每个节点可用的分配处理器数量。 必须是2的幂。最大允许值为32。
-
-
task_settings -
(可选, 对象) 用于配置推理任务的设置。 这些设置是针对您指定的
task_settingsfor thereranktask type-
return_documents -
(可选, 布尔值)
返回文档而不是仅返回索引。默认为
true。
-
通过 elasticsearch 服务进行 E5
edit以下示例展示了如何创建一个名为 my-e5-model 的推理端点,以执行 text_embedding 任务类型。
下面的API请求将自动下载E5模型(如果尚未下载),然后部署该模型。
PUT _inference/text_embedding/my-e5-model
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".multilingual-e5-small"
}
}
|
The |
在使用Kibana控制台时,您可能会在响应中看到502错误网关错误。
这个错误通常只是反映了超时,而模型在后台下载。
您可以在机器学习UI中检查下载进度。
如果使用Python客户端,可以将timeout参数设置为更高的值。
通过Elasticsearch服务上传的Eland模型
edit以下示例展示了如何创建一个名为 my-msmarco-minilm-model 的推理端点,以执行 text_embedding 任务类型。
PUT _inference/text_embedding/my-msmarco-minilm-model { "service": "elasticsearch", "service_settings": { "num_allocations": 1, "num_threads": 1, "model_id": "msmarco-MiniLM-L12-cos-v5" } }
通过elasticsearch服务为E5设置自适应分配
edit以下示例展示了如何创建一个名为 my-e5-model 的推理端点,以执行 text_embedding 任务类型并配置自适应分配。
下面的API请求将自动下载E5模型(如果尚未下载),然后部署该模型。
PUT _inference/text_embedding/my-e5-model
{
"service": "elasticsearch",
"service_settings": {
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 3,
"max_number_of_allocations": 10
},
"num_threads": 1,
"model_id": ".multilingual-e5-small"
}
}
ELSER 推理服务
edit创建一个推理端点,以使用elser服务执行推理任务。
如果尚未下载,API请求将自动下载并部署ELSER模型。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
sparse_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
elser。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是特定于
elser服务的。-
adaptive_allocations -
(可选, 对象) 自适应分配配置对象。 如果启用,模型的分配数量将根据当前进程的负载进行设置。 当负载较高时,会自动创建新的模型分配(如果设置了
max_number_of_allocations,则需遵守其值)。 当负载较低时,会自动移除模型分配(如果设置了min_number_of_allocations,则需遵守其值)。 如果启用了adaptive_allocations,请勿手动设置分配数量。-
enabled -
(可选, 布尔值)
如果为
true,则启用adaptive_allocations。 默认为false。 -
max_number_of_allocations -
(可选, 整数)
指定可扩展到的最大分配数量。
如果设置,则必须大于或等于
min_number_of_allocations。 -
min_number_of_allocations -
(可选, 整数)
指定可扩展到的最小分配数量。
如果设置,则必须大于或等于
1。
-
-
num_allocations -
(必需, 整数)
该模型在机器学习节点中分配的总数量。
增加此值通常会增加吞吐量。
如果启用了
adaptive_allocations,请勿设置此值,因为它会自动设置。 -
num_threads -
(必需, 整数)
设置每个模型分配在推理期间使用的线程数。这通常会增加每个推理请求的速度。推理过程是一个计算密集型过程;
threads_per_allocations不得超过每个节点可用的分配处理器数量。 必须是2的幂。最大允许值为32。
-
ELSER 服务示例
edit以下示例展示了如何创建一个名为 my-elser-model 的推理端点,以执行 sparse_embedding 任务类型。
有关更多信息,请参阅 ELSER 模型文档。
如果您想优化ELSER端点以进行数据摄取,请将线程数设置为1("num_threads": 1)。
如果您想优化ELSER端点以进行搜索,请将线程数设置为大于1。
下面的请求将自动下载ELSER模型(如果尚未下载),然后部署该模型。
PUT _inference/sparse_embedding/my-elser-model
{
"service": "elser",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
}
}
示例响应:
{
"inference_id": "my-elser-model",
"task_type": "sparse_embedding",
"service": "elser",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
},
"task_settings": {}
}
在使用Kibana控制台时,您可能会在响应中看到502错误网关错误。
这个错误通常只是反映了超时,而模型在后台下载。
您可以在机器学习UI中检查下载进度。
如果使用Python客户端,可以将timeout参数设置为更高的值。
为ELSER服务设置自适应分配
edit以下示例展示了如何创建一个名为 my-elser-model 的推理端点,以执行 sparse_embedding 任务类型并配置自适应分配。
下面的请求将自动下载ELSER模型(如果尚未下载),然后部署该模型。
PUT _inference/sparse_embedding/my-elser-model
{
"service": "elser",
"service_settings": {
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 3,
"max_number_of_allocations": 10
},
"num_threads": 1
}
}
Google AI Studio 推理服务
edit创建一个推理端点,以使用googleaistudio服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
completion, -
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
googleaistudio。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
googleaistudio服务的。-
api_key - (必需, 字符串) Google Gemini API 的有效 API 密钥。
-
model_id - (必需, 字符串) 用于推理任务的模型名称。 您可以在 Gemini API 模型 找到支持的模型。
-
rate_limit -
(可选, 对象) 默认情况下,
googleaistudio服务将每分钟允许的请求数设置为360. 这有助于最小化从 Google AI Studio 返回的速率限制错误数量. 要修改此设置, 请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> }
-
Google AI Studio 服务示例
edit以下示例展示了如何创建一个名为 google_ai_studio_completion 的推理端点,以执行 completion 任务类型。
PUT _inference/completion/google_ai_studio_completion
{
"service": "googleaistudio",
"service_settings": {
"api_key": "<api_key>",
"model_id": "<model_id>"
}
}
Google Vertex AI 推理服务
edit创建一个推理端点,以使用googlevertexai服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
rerank -
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
googlevertexai。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
googlevertexai服务的。-
service_account_json - (必需, 字符串) Google Vertex AI API 的有效服务账户,格式为 json。
-
model_id - (必需, 字符串) 用于推理任务的模型名称。 您可以在 文本嵌入 API 找到支持的模型。
-
location - (必需, 字符串) 用于推理任务的位置名称。 您可以在 Vertex AI 上的生成式 AI 位置 找到支持的位置。
-
project_id - (必需, 字符串) 用于推理任务的项目名称。
-
rate_limit -
(可选, 对象) 默认情况下,
googlevertexai服务将每分钟允许的请求数设置为30.000。 这有助于减少从 Google Vertex AI 返回的速率限制错误。 要修改此设置, 请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> } 关于 Google Vertex AI 的速率限制的更多信息可以在 Google Vertex AI 配额文档 中找到。
-
-
task_settings -
(可选, 对象) 用于配置推理任务的设置。 这些设置是针对您指定的
task_settingsfor thereranktask type-
top_n - (可选, 布尔值) 指定应返回的前n个文档的数量。
task_settingsfor thetext_embeddingtask type-
auto_truncate - (可选, 布尔值) 指定API是否自动截断超过最大标记长度的输入。
-
Google Vertex AI 服务示例
edit以下示例展示了如何创建一个名为 google_vertex_ai_embeddings 的推理端点,以执行 text_embedding 任务类型。
PUT _inference/text_embedding/google_vertex_ai_embeddings
{
"service": "googlevertexai",
"service_settings": {
"service_account_json": "<service_account_json>",
"model_id": "<model_id>",
"location": "<location>",
"project_id": "<project_id>"
}
}
下一个示例展示了如何创建一个名为 google_vertex_ai_rerank 的推理端点,以执行 rerank 任务类型。
PUT _inference/rerank/google_vertex_ai_rerank
{
"service": "googlevertexai",
"service_settings": {
"service_account_json": "<service_account_json>",
"project_id": "<project_id>"
}
}
HuggingFace 推理服务
edit创建一个推理端点,以使用hugging_face服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
hugging_face。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
hugging_face服务的。-
api_key -
(必需,字符串) 您的 Hugging Face 账户的有效访问令牌。 您可以在设置页面找到您的 Hugging Face 访问令牌或创建一个新的令牌。
您只需在推理模型创建时提供一次API密钥。 获取推理API不会检索您的API密钥。 创建推理模型后,您无法更改关联的API密钥。 如果您想使用不同的API密钥,请删除推理模型并使用相同名称和更新后的API密钥重新创建。
-
url - (必需, 字符串) 请求使用的URL端点。
-
rate_limit -
(可选, 对象) 默认情况下,
huggingface服务将每分钟允许的请求数设置为3000。 这有助于减少从 Hugging Face 返回的速率限制错误。 要修改此设置,请在服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> }
-
Hugging Face 服务示例
edit以下示例展示了如何创建一个名为 hugging-face-embeddings 的推理端点,以执行 text_embedding 任务类型。
PUT _inference/text_embedding/hugging-face-embeddings
{
"service": "hugging_face",
"service_settings": {
"api_key": "<access_token>",
"url": "<url_endpoint>"
}
}
|
一个有效的 Hugging Face 访问令牌。 你可以在 你的账户设置页面找到。 |
|
|
您在 Hugging Face 上创建的推理端点 URL。 |
在
Hugging Face 端点页面上创建一个新的推理端点以获取端点 URL。
在新端点创建页面上选择您想要使用的模型 - 例如 intfloat/e5-small-v2 - 然后在高级配置部分选择 句子嵌入 任务。
创建端点。
复制端点初始化完成后生成的 URL。
Mistral 推理服务
edit创建一个推理端点,以使用mistral服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
mistral。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
mistral服务的。-
api_key -
(必需,字符串) 您的Mistral账户的有效API密钥。 您可以在API密钥页面找到您的Mistral API密钥或创建一个新的密钥。
您只需在推理模型创建时提供一次API密钥。 获取推理API不会检索您的API密钥。 创建推理模型后,您无法更改关联的API密钥。 如果您想使用不同的API密钥,请删除推理模型并使用相同名称和更新后的API密钥重新创建。
-
model - (必需, 字符串) 用于推理任务的模型名称。 请参考Mistral模型文档 获取可用的文本嵌入模型列表。
-
max_input_tokens - (可选, 整数) 允许您在分块发生之前指定每个输入的最大令牌数。
-
rate_limit -
(可选, 对象) 默认情况下,
mistral服务将每分钟允许的请求数设置为240. 这有助于最小化从 Mistral API 返回的速率限制错误数量. 要修改此设置, 请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> }
-
Mistral 服务示例
edit以下示例展示了如何创建一个名为 mistral-embeddings-test 的推理端点,以执行 text_embedding 任务类型。
PUT _inference/text_embedding/mistral-embeddings-test
{
"service": "mistral",
"service_settings": {
"api_key": "<api_key>",
"model": "mistral-embed"
}
}
|
The |
OpenAI 推理服务
edit创建一个推理端点,以使用openai服务执行推理任务。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
completion, -
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
openai。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
openai服务的。-
api_key -
(必需, 字符串) 您的 OpenAI 账户的有效 API 密钥。 您可以在您的 OpenAI 账户的 API 密钥部分 找到您的 OpenAI API 密钥。
您只需在推理模型创建时提供一次API密钥。 获取推理API不会检索您的API密钥。 创建推理模型后,您无法更改关联的API密钥。 如果您想使用不同的API密钥,请删除推理模型并使用相同名称和更新后的API密钥重新创建。
-
model_id - (必需, 字符串) 用于推理任务的模型名称。 请参考 OpenAI 文档 以获取可用的文本嵌入模型列表。
-
organization_id - (可选, 字符串) 您组织的唯一标识符。 您可以在您的 OpenAI 账户的 设置 > 组织 中找到组织 ID。
-
url -
(可选, 字符串)
用于请求的 URL 端点。
可以更改以用于测试目的。
默认为
https://api.openai.com/v1/embeddings。 -
rate_limit -
(可选, 对象)
openai服务根据任务类型设置每分钟允许的默认请求数量。 对于text_embedding,它设置为3000。 对于completion,它设置为500。 这有助于减少从 OpenAI 返回的速率限制错误数量。 要修改此设置,请在服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> } 关于 OpenAI 的速率限制的更多信息可以在您的账户限制中找到。
-
-
task_settings -
(可选, 对象) 用于配置推理任务的设置。 这些设置是针对您指定的
task_settingsfor thecompletiontask type-
user - (可选, 字符串) 指定发出请求的用户,可用于滥用检测。
task_settingsfor thetext_embeddingtask type-
user - (可选, 字符串) 指定发出请求的用户,可用于滥用检测。
-
OpenAI 服务示例
edit以下示例展示了如何创建一个名为 openai-embeddings 的推理端点,以执行 text_embedding 任务类型。
PUT _inference/text_embedding/openai-embeddings
{
"service": "openai",
"service_settings": {
"api_key": "<api_key>",
"model_id": "text-embedding-ada-002"
}
}
下一个示例展示了如何创建一个名为 openai-completion 的推理端点,以执行 completion 任务类型。
PUT _inference/completion/openai-completion
{
"service": "openai",
"service_settings": {
"api_key": "<api_key>",
"model_id": "gpt-3.5-turbo"
}
}
Watsonx 推理服务
edit创建一个推理端点,以使用watsonxai服务执行推理任务。
您需要一个IBM Cloud® Databases for Elasticsearch 部署来使用 watsonxai 推理服务。
您可以通过IBM 目录、Cloud Databases CLI 插件、Cloud Databases API 或 Terraform 来配置一个。
请求
editPUT /_inference/
路径参数
edit-
<inference_id> - (必需, 字符串) 推理端点的唯一标识符。
-
<task_type> -
(必需,字符串) 模型将执行的推理任务的类型。
可用的任务类型:
-
text_embedding.
-
请求体
edit-
service -
(必需,字符串)
指定任务类型支持的服务类型。在此情况下,
watsonxai。 -
service_settings -
(必需, 对象) 用于安装推理模型的设置。
这些设置是针对
watsonxai服务的。-
api_key -
(必需, 字符串) 您的Watsonx账户的有效API密钥。 您可以在API密钥页面找到您的Watsonx API密钥或创建一个新的密钥。
您只需在推理模型创建时提供一次API密钥。 获取推理API不会检索您的API密钥。 创建推理模型后,您无法更改关联的API密钥。 如果您想使用不同的API密钥,请删除推理模型并使用相同名称和更新后的API密钥重新创建。
-
api_version -
(必需, 字符串)
版本参数,采用
YYYY-MM-DD格式的版本日期。 有关活动版本数据参数,请参阅文档。 -
model_id - (必需, 字符串) 用于推理任务的模型名称。 有关可用文本嵌入模型的列表,请参阅Watsonx文档中的IBM嵌入模型部分。
-
url - (必需, 字符串) 用于请求的URL端点。
-
project_id - (必需, 字符串) 用于推理任务的项目名称。
-
rate_limit -
(可选, 对象) 默认情况下,
watsonxai服务将每分钟允许的请求数设置为120。 这有助于减少从 Watsonx 返回的速率限制错误数量。 要修改此设置,请在您的服务设置中设置此对象的requests_per_minute设置:"rate_limit": { "requests_per_minute": <> }
-
Watsonx AI 服务示例
edit以下示例展示了如何创建一个名为 watsonx-embeddings 的推理端点,以执行 text_embedding 任务类型。
PUT _inference/text_embedding/watsonx-embeddings
{
"service": "watsonxai",
"service_settings": {
"api_key": "<api_key>",
"url": "<url>",
"model_id": "ibm/slate-30m-english-rtrvr",
"project_id": "<project_id>",
"api_version": "2024-03-14"
}
}
|
一个有效的Watsonx API密钥。 你可以在你的账户的API密钥页面找到。 |
|
|
您在Watsonx上创建的推理端点URL。 |
|
|
您的IBM Cloud项目的ID。 |
|
|
有效的API版本参数。您可以在此处找到活动版本数据参数这里。 |