摄取处理器参考
edit摄取处理器参考
edit一个摄取管道由一系列处理器组成,这些处理器在文档被摄取到索引中时应用。每个处理器执行特定的任务,例如过滤、转换或丰富数据。
每个后续处理器都依赖于前一个处理器的输出,因此处理器的顺序非常重要。 所有处理器应用后,修改后的文档会被索引到Elasticsearch中。
Elasticsearch 包含超过 40 个可配置的处理器。 本节中的子页面包含每个处理器的参考文档。 要获取可用处理器的列表,请使用 nodes info API。
GET _nodes/ingest?filter_path=nodes.*.ingest.processors
按类别分类的摄取处理器
edit我们已将本页面上可用的处理器进行了分类,并总结了它们的功能。这将帮助您找到适合您使用场景的处理器。
数据丰富处理器
edit一般结果
edit-
appendprocessor - 向字段追加一个值。
-
date_index_nameprocessor - 根据日期或时间戳字段将文档指向正确的时间基准索引。
-
enrichprocessor - 使用另一个索引中的数据丰富文档。
请参阅 Enrich your data 以获取如何使用 enrich 处理器在摄取过程中将现有索引中的数据添加到传入文档的详细示例。
-
inferenceprocessor - 使用机器学习对文本字段进行分类和标记。
特定成果
edit-
attachmentprocessor - 解析并索引二进制数据,如PDF和Word文档。
-
circleprocessor - 将位置字段转换为地理点字段。
-
community_idprocessor - 计算网络流数据的社区ID。
-
fingerprintprocessor - 计算文档内容的哈希值。
-
geo_gridprocessor - 将地理网格定义的网格瓦片或单元格转换为描述其形状的常规边界框或多边形。
-
geoipprocessor - 添加有关IPv4或IPv6地址的地理位置信息。
-
network_directionprocessor - 计算给定源IP地址、目标IP地址和内部网络列表的网络方向。
-
registered_domainprocessor - 从完全限定域名(FQDN)中提取注册域(也称为有效顶级域或eTLD)、子域和顶级域。
-
set_security_userprocessor -
设置与用户相关的详细信息(例如
username、roles、email、full_name、metadata、api_key、realm和authentication_type),通过预处理摄取将当前经过身份验证的用户信息设置到当前文档中。 -
uri_partsprocessor - 解析统一资源标识符(URI)字符串并将其组件提取为对象。
-
urldecodeprocessor - 对字符串进行URL解码。
-
user_agentprocessor - 解析用户代理字符串以提取有关网络客户端的信息。
数据转换处理器
edit一般结果
edit-
convertprocessor - 将当前正在摄取的文档中的字段转换为不同类型,例如将字符串转换为整数。
-
dissectprocessor - 从文档中的单个文本字段中提取结构化字段。 与grok processor不同,dissect 不使用正则表达式。 这使得 dissect 成为一种更简单且通常更快的替代方案。
-
grokprocessor - 从文档中的单个文本字段中提取结构化字段,使用支持可重用别名表达式的Grok正则表达式方言。
-
gsubprocessor - 通过应用正则表达式和替换来转换字符串字段。
-
redactprocessor - 使用Grok规则引擎来模糊输入文档中与给定Grok模式匹配的文本。
-
renameprocessor - 重命名现有字段。
-
setprocessor - 在字段上设置一个值。
特定成果
edit-
bytesprocessor -
将人类可读的字节值转换为其字节值(例如
1kb变为1024)。 -
csvprocessor - 从文本字段中提取单行CSV数据。
-
dateprocessor - 提取并转换日期字段。
-
dot_expandprocessor - 将带有点的字段扩展为对象字段。
-
html_stripprocessor - 移除字段中的HTML标签。
-
joinprocessor - 将数组中的每个元素连接成一个字符串,并在每个元素之间使用分隔符。
-
kvprocessor - 解析包含键值对的消息(或特定事件字段)。
-
lowercaseprocessor anduppercaseprocessor - 将字符串字段转换为小写或大写。
-
splitprocessor - 将一个字段拆分为一个值数组。
-
trimprocessor - 去除字段中的空白。
数据过滤处理器
edit-
dropprocessor - 删除文档而不引发任何错误。
-
removeprocessor - 从文档中移除字段。
管道处理处理器
edit-
failprocessor - 引发异常。当你期望一个管道失败并希望向请求者传递特定消息时,这非常有用。
-
pipelineprocessor - 执行另一个管道。
-
rerouteprocessor - 将文档重新路由到另一个目标索引或数据流。
-
terminateprocessor - 终止当前的摄取管道,导致不再运行更多的处理器。
数组/JSON处理处理器
edit-
for_eachprocessor - 对数组或对象的每个元素运行一个摄取处理器。
-
jsonprocessor - 将JSON字符串转换为结构化的JSON对象。
-
scriptprocessor -
对传入的文档运行内联或存储的脚本。
脚本在无痛
ingest上下文中运行。 -
sortprocessor - 将数组的元素按升序或降序排序。
添加额外的处理器
edit您可以安装额外的处理器作为插件。
您必须在集群中的所有节点上安装任何插件处理器。否则,Elasticsearch将无法创建包含该处理器的管道。
通过在 elasticsearch.yml 中设置 plugin.mandatory 将插件标记为强制性。如果未安装强制性插件,节点将无法启动。
plugin.mandatory: my-ingest-plugin
追加处理器
edit如果字段已存在且为数组,则将一个或多个值追加到现有数组中。 如果字段存在且为标量,则将其转换为数组并追加一个或多个值。 如果字段不存在,则创建一个包含所提供值的数组。 接受单个值或值数组。
表3. 追加选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要附加的字段。支持 模板片段。 |
|
是 |
- |
要附加的值。支持 模板片段。 |
|
否 |
真 |
如果 |
|
否 |
|
用于编码 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
{
"append": {
"field": "tags",
"value": ["production", "{{{app}}}", "{{{owner}}}"]
}
}
附件处理器
edit附件处理器允许 Elasticsearch 使用 Apache 文本提取库 Tika 提取常见格式(如 PPT、XLS 和 PDF)的文件附件。
源字段必须是base64编码的二进制数据。如果您不想承担在base64之间来回转换的开销,您可以使用CBOR格式代替JSON,并将字段指定为字节数组而不是字符串表示。处理器将跳过base64解码。
在管道中使用附件处理器
edit表4. 附件选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
获取base64编码字段的字段 |
|
否 |
附件 |
将保存附件信息的字段 |
|
否 |
100000 |
用于防止字段过大的提取字符数。使用 |
|
否 |
|
可以从该字段名称覆盖用于提取的字符数。请参阅 |
|
否 |
所有属性 |
要存储的属性数组。可以是 |
|
否 |
|
如果 |
|
否 |
|
如果 |
|
否 |
包含要解码的资源名称的字段。如果指定,处理器将此资源名称传递给底层的Tika库,以启用基于资源名称的检测。 |
示例
edit如果将文件附加到JSON文档,您必须首先将文件编码为base64字符串。在类Unix系统上,您可以使用base64命令来完成此操作:
base64 -in myfile.rtf
该命令返回文件的base64编码字符串。以下base64字符串是包含文本Lorem ipsum dolor sit amet的.rtf文件的编码:
e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=。
使用附件处理器来解码字符串并提取文件的属性:
PUT _ingest/pipeline/attachment
{
"description" : "Extract attachment information",
"processors" : [
{
"attachment" : {
"field" : "data",
"remove_binary": false
}
}
]
}
PUT my-index-000001/_doc/my_id?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0="
}
GET my-index-000001/_doc/my_id
文档的 attachment 对象包含文件的提取属性:
{
"found": true,
"_index": "my-index-000001",
"_id": "my_id",
"_version": 1,
"_seq_no": 22,
"_primary_term": 1,
"_source": {
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=",
"attachment": {
"content_type": "application/rtf",
"language": "ro",
"content": "Lorem ipsum dolor sit amet",
"content_length": 28
}
}
}
将二进制文件作为文档中的一个字段可能会消耗大量资源。强烈建议从文档中删除该字段。将 remove_binary 设置为 true 以自动删除该字段。
导出的字段
edit可以从文档中提取的字段包括:
-
内容, -
标题, -
作者, -
关键词, -
日期, -
内容类型, -
内容长度, -
语言, -
修改时间, -
格式, -
标识符, -
贡献者, -
覆盖范围, -
修改者, -
创建工具, -
发布者, -
关系, -
权限, -
来源, -
类型, -
描述, -
打印日期, -
元数据日期, -
纬度, -
经度, -
海拔, -
评分, -
评论
要提取特定的attachment字段,请指定properties数组:
PUT _ingest/pipeline/attachment
{
"description" : "Extract attachment information",
"processors" : [
{
"attachment" : {
"field" : "data",
"properties": [ "content", "title" ],
"remove_binary": false
}
}
]
}
从二进制数据中提取内容是一项资源密集型操作,会消耗大量资源。强烈建议在专用摄取节点中运行使用此处理器的管道。
使用附件处理器与CBOR
edit为了避免对JSON进行编码和解码为base64,您可以将CBOR数据传递给附件处理器。例如,以下请求创建了cbor-attachment管道,该管道使用了附件处理器。
PUT _ingest/pipeline/cbor-attachment
{
"description" : "Extract attachment information",
"processors" : [
{
"attachment" : {
"field" : "data",
"remove_binary": false
}
}
]
}
以下Python脚本将CBOR数据传递给包含cbor-attachment管道的HTTP索引请求。HTTP请求头使用content-type为application/cbor。
并非所有 Elasticsearch 客户端都支持自定义 HTTP 请求头。
import cbor2
import requests
file = 'my-file'
headers = {'content-type': 'application/cbor'}
with open(file, 'rb') as f:
doc = {
'data': f.read()
}
requests.put(
'http://localhost:9200/my-index-000001/_doc/my_id?pipeline=cbor-attachment',
data=cbor2.dumps(doc),
headers=headers
)
限制提取字符的数量
edit为了防止提取过多的字符并导致节点内存过载,默认情况下用于提取的字符数限制为 100000。您可以通过设置 indexed_chars 来更改此值。使用 -1 表示无限制,但在设置此值时,请确保您的节点有足够的堆内存来提取非常大的文档内容。
您还可以通过从给定字段中提取要设置的限制来为每个文档定义此限制。如果文档包含该字段,它将覆盖 indexed_chars 设置。要设置此字段,请定义 indexed_chars_field 设置。
例如:
PUT _ingest/pipeline/attachment
{
"description" : "Extract attachment information",
"processors" : [
{
"attachment" : {
"field" : "data",
"indexed_chars" : 11,
"indexed_chars_field" : "max_size",
"remove_binary": false
}
}
]
}
PUT my-index-000001/_doc/my_id?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0="
}
GET my-index-000001/_doc/my_id
返回这个:
{
"found": true,
"_index": "my-index-000001",
"_id": "my_id",
"_version": 1,
"_seq_no": 35,
"_primary_term": 1,
"_source": {
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=",
"attachment": {
"content_type": "application/rtf",
"language": "is",
"content": "Lorem ipsum",
"content_length": 11
}
}
}
PUT _ingest/pipeline/attachment
{
"description" : "Extract attachment information",
"processors" : [
{
"attachment" : {
"field" : "data",
"indexed_chars" : 11,
"indexed_chars_field" : "max_size",
"remove_binary": false
}
}
]
}
PUT my-index-000001/_doc/my_id_2?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=",
"max_size": 5
}
GET my-index-000001/_doc/my_id_2
返回这个:
{
"found": true,
"_index": "my-index-000001",
"_id": "my_id_2",
"_version": 1,
"_seq_no": 40,
"_primary_term": 1,
"_source": {
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=",
"max_size": 5,
"attachment": {
"content_type": "application/rtf",
"language": "sl",
"content": "Lorem",
"content_length": 5
}
}
}
使用带有数组的附件处理器
edit要在附件数组中使用附件处理器,需要使用foreach处理器。这使得附件处理器可以对数组的各个元素进行处理。
例如,给定以下源代码:
{
"attachments" : [
{
"filename" : "ipsum.txt",
"data" : "dGhpcyBpcwpqdXN0IHNvbWUgdGV4dAo="
},
{
"filename" : "test.txt",
"data" : "VGhpcyBpcyBhIHRlc3QK"
}
]
}
在这种情况下,我们希望处理每个元素中的数据字段,并将其属性插入到文档中,因此使用了以下foreach处理器:
PUT _ingest/pipeline/attachment
{
"description" : "Extract attachment information from arrays",
"processors" : [
{
"foreach": {
"field": "attachments",
"processor": {
"attachment": {
"target_field": "_ingest._value.attachment",
"field": "_ingest._value.data",
"remove_binary": false
}
}
}
}
]
}
PUT my-index-000001/_doc/my_id?pipeline=attachment
{
"attachments" : [
{
"filename" : "ipsum.txt",
"data" : "dGhpcyBpcwpqdXN0IHNvbWUgdGV4dAo="
},
{
"filename" : "test.txt",
"data" : "VGhpcyBpcyBhIHRlc3QK"
}
]
}
GET my-index-000001/_doc/my_id
返回这个:
{
"_index" : "my-index-000001",
"_id" : "my_id",
"_version" : 1,
"_seq_no" : 50,
"_primary_term" : 1,
"found" : true,
"_source" : {
"attachments" : [
{
"filename" : "ipsum.txt",
"data" : "dGhpcyBpcwpqdXN0IHNvbWUgdGV4dAo=",
"attachment" : {
"content_type" : "text/plain; charset=ISO-8859-1",
"language" : "en",
"content" : "this is\njust some text",
"content_length" : 24
}
},
{
"filename" : "test.txt",
"data" : "VGhpcyBpcyBhIHRlc3QK",
"attachment" : {
"content_type" : "text/plain; charset=ISO-8859-1",
"language" : "en",
"content" : "This is a test",
"content_length" : 16
}
}
]
}
}
请注意,需要设置target_field,否则将使用默认值,即顶级字段attachment。此顶级字段的属性将仅包含第一个附件的值。但是,通过将target_field指定为_ingest._value上的值,它将正确地将属性与正确的附件关联起来。
字节处理器
edit将人类可读的字节值(例如 1kb)转换为其字节值(例如 1024)。如果该字段是字符串数组,则数组的所有成员都将被转换。
支持的人类可读单位有 "b", "kb", "mb", "gb", "tb", "pb",不区分大小写。如果字段不是支持的格式或结果值超过 2^63,将会发生错误。
{
"bytes": {
"field": "file.size"
}
}
圆形处理器
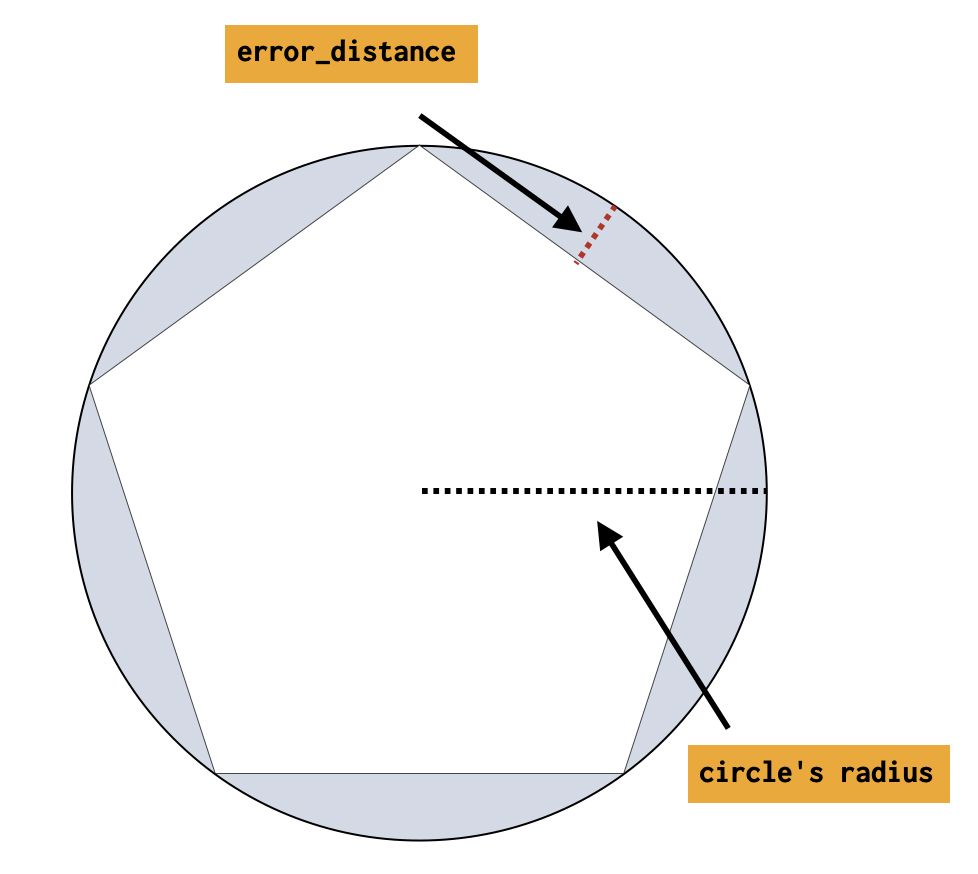
edit将形状的圆形定义转换为近似它们的正多边形。
表6. 圆形处理器选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要解释为圆的字段。可以是WKT格式的字符串或GeoJSON的地图。 |
|
否 |
|
要分配多边形形状的字段,默认情况下 |
|
否 |
|
如果 |
|
是 |
- |
从中心到边的内接距离与圆的半径之间的差异(对于 |
|
是 |
- |
处理圆形时应使用哪种字段映射类型: |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
PUT circles
{
"mappings": {
"properties": {
"circle": {
"type": "geo_shape"
}
}
}
}
PUT _ingest/pipeline/polygonize_circles
{
"description": "translate circle to polygon",
"processors": [
{
"circle": {
"field": "circle",
"error_distance": 28.0,
"shape_type": "geo_shape"
}
}
]
}
使用上述管道,我们可以尝试将文档索引到 circles 索引中。
圆形可以表示为 WKT 圆形或 GeoJSON 圆形。生成的多边形将使用与输入圆形相同的格式表示和索引。WKT 将被转换为 WKT 多边形,而 GeoJSON 圆形将被转换为 GeoJSON 多边形。
包含极点的圆不被支持。
示例:以熟知文本定义的圆
edit在这个例子中,一个以WKT格式定义的圆被索引
PUT circles/_doc/1?pipeline=polygonize_circles
{
"circle": "CIRCLE (30 10 40)"
}
GET circles/_doc/1
上述索引请求的响应:
{
"found": true,
"_index": "circles",
"_id": "1",
"_version": 1,
"_seq_no": 22,
"_primary_term": 1,
"_source": {
"circle": "POLYGON ((30.000365257263184 10.0, 30.000111397193788 10.00034284530941, 29.999706043744222 10.000213571721195, 29.999706043744222 9.999786428278805, 30.000111397193788 9.99965715469059, 30.000365257263184 10.0))"
}
}
示例:在GeoJSON中定义的圆
edit在这个例子中,一个以GeoJSON格式定义的圆被索引
PUT circles/_doc/2?pipeline=polygonize_circles
{
"circle": {
"type": "circle",
"radius": "40m",
"coordinates": [30, 10]
}
}
GET circles/_doc/2
上述索引请求的响应:
{
"found": true,
"_index": "circles",
"_id": "2",
"_version": 1,
"_seq_no": 22,
"_primary_term": 1,
"_source": {
"circle": {
"coordinates": [
[
[30.000365257263184, 10.0],
[30.000111397193788, 10.00034284530941],
[29.999706043744222, 10.000213571721195],
[29.999706043744222, 9.999786428278805],
[30.000111397193788, 9.99965715469059],
[30.000365257263184, 10.0]
]
],
"type": "Polygon"
}
}
}
关于准确性的说明
edit表示圆的多边形的精度定义为error_distance。这个差值越小,多边形就越接近一个完美的圆。
下表旨在帮助捕捉圆的半径如何影响给定不同输入的多边形的边数。
最小的边数是 4,最大的是 1000。
社区 ID 处理器
edit计算网络流数据的社区ID,如社区ID规范中所定义。您可以使用社区ID来关联与单个流相关的网络事件。
社区ID处理器默认从相关的Elastic Common Schema (ECS)字段读取网络流量数据。如果您使用ECS,则无需进行配置。
表8. 社区ID选项
| Name | Required | Default | Description |
|---|---|---|---|
|
否 |
|
包含源IP地址的字段。 |
|
否 |
|
包含源端口的字段。 |
|
否 |
|
包含目标IP地址的字段。 |
|
否 |
|
包含目标端口的字段。 |
|
否 |
|
包含IANA号码的字段。 |
|
否 |
|
包含ICMP类型的字段。 |
|
否 |
|
包含ICMP代码的字段。 |
|
否 |
|
包含传输协议名称或编号的字段。
仅在 |
|
否 |
|
社区ID的输出字段。 |
|
否 |
|
社区ID哈希的种子。必须在0到65535(包含)之间。种子可以防止网络域之间的哈希冲突,例如使用相同寻址方案的暂存和生产网络。 |
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
以下是社区ID处理器的一个示例定义:
{
"description" : "...",
"processors" : [
{
"community_id": {
}
}
]
}
当上述处理器在以下文档上执行时:
{
"_source": {
"source": {
"ip": "123.124.125.126",
"port": 12345
},
"destination": {
"ip": "55.56.57.58",
"port": 80
},
"network": {
"transport": "TCP"
}
}
}
它产生以下结果:
"_source" : {
"destination" : {
"port" : 80,
"ip" : "55.56.57.58"
},
"source" : {
"port" : 12345,
"ip" : "123.124.125.126"
},
"network" : {
"community_id" : "1:9qr9Z1LViXcNwtLVOHZ3CL8MlyM=",
"transport" : "TCP"
}
}
转换处理器
edit将当前正在摄取的文档中的字段转换为不同类型,例如将字符串转换为整数。 如果字段值是数组,则所有成员都将被转换。
支持的类型包括:integer、long、float、double、string、boolean、ip 和 auto。
指定 boolean 将设置字段为 true,如果其字符串值等于 true(忽略大小写),为 false 如果其字符串值等于 false(忽略大小写),否则将抛出异常。
指定 ip 将设置目标字段为 field 的值,如果它包含一个可以索引到 IP field type 的有效 IPv4 或 IPv6 地址。
指定 auto 将尝试将字符串值的 field 转换为最接近的非字符串、非IP类型。例如,值为 "true" 的字段将被转换为其对应的布尔类型:true。请注意,在 auto 中,浮点数优先于双精度数。值为 "242.15" 的值将“自动”转换为类型为 float 的 242.15。如果提供的字段无法适当地转换,处理器仍将成功处理并保留字段值不变。在这种情况下,target_field 将被更新为未转换的字段值。
表9. 转换选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要转换其值的字段 |
|
否 |
|
要分配转换值的字段,默认情况下 |
|
是 |
- |
要转换现有值的类型 |
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
PUT _ingest/pipeline/my-pipeline-id
{
"description": "converts the content of the id field to an integer",
"processors" : [
{
"convert" : {
"field" : "id",
"type": "integer"
}
}
]
}
CSV 处理器
edit从文档中的单个文本字段提取CSV行中的字段。CSV中的任何空字段都将被跳过。
表10. CSV选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要从中提取数据的字段 |
|
是 |
- |
要分配提取值的字段数组 |
|
否 |
, |
CSV中使用的分隔符,必须是单个字符的字符串 |
|
否 |
“ |
CSV中使用的引号,必须是单字符字符串 |
|
否 |
|
如果 |
|
否 |
|
修剪未引号字段中的空白字符 |
|
否 |
- |
用于填充空字段的值,如果未提供此值,空字段将被跳过。空字段是指没有值的字段(两个连续的分隔符)或空引号( |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
{
"csv": {
"field": "my_field",
"target_fields": ["field1", "field2"]
}
}
如果启用了trim选项,则每个未引用的字段开头和结尾的任何空白字符都将被修剪。
例如,使用上述配置,值为A, B将导致字段field2
具有值{nbsp}B(开头有空格)。如果启用了trim,A, B将导致字段field2
具有值B(无空白字符)。引用的字段将保持不变。
日期处理器
edit解析字段中的日期,然后使用日期或时间戳作为文档的时间戳。默认情况下,日期处理器会将解析的日期添加为名为 @timestamp 的新字段。您可以通过设置 target_field 配置参数来指定不同的字段。支持在同一日期处理器定义中使用多种日期格式。它们将按照处理器定义中的顺序依次用于尝试解析日期字段。
表11. 日期选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
获取日期的字段。 |
|
否 |
@时间戳 |
将保存解析日期的字段。 |
|
是 |
- |
预期的日期格式的数组。可以是Java时间模式或以下格式之一:ISO8601、UNIX、UNIX_MS或TAI64N。 |
|
否 |
协调世界时 |
解析日期时使用的时区。支持模板片段。 |
|
否 |
英语 |
解析日期时使用的区域设置,在解析月份名称或星期几时相关。支持模板片段。 |
|
否 |
|
将日期写入 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
这里是一个示例,根据initial_date字段将解析的日期添加到timestamp字段中:
{
"description" : "...",
"processors" : [
{
"date" : {
"field" : "initial_date",
"target_field" : "timestamp",
"formats" : ["dd/MM/yyyy HH:mm:ss"],
"timezone" : "Europe/Amsterdam"
}
}
]
}
处理器参数 timezone 和 locale 是模板化的。这意味着它们的值可以从文档中的字段中提取。下面的示例展示了如何从现有字段 my_timezone 和 my_locale 中提取区域设置/时区详细信息,这些字段包含摄取文档中的时区和区域设置值。
{
"description" : "...",
"processors" : [
{
"date" : {
"field" : "initial_date",
"target_field" : "timestamp",
"formats" : ["ISO8601"],
"timezone" : "{{{my_timezone}}}",
"locale" : "{{{my_locale}}}"
}
}
]
}
日期索引名称处理器
edit此处理器的目的在于,通过使用日期数学索引名称支持,根据文档中的日期或时间戳字段,将文档指向正确的时间基准索引。
处理器根据提供的索引名称前缀、正在处理的文档中的日期或时间戳字段以及提供的日期舍入,使用日期数学索引名称表达式设置_index元数据字段。
首先,此处理器从正在处理的文档中的字段获取日期或时间戳。可选地,可以配置日期格式以确定如何将字段的值解析为日期。然后,此日期、提供的索引名称前缀和提供的日期舍入将被格式化为日期数学索引名称表达式。同样,在此处可以选择性地指定日期格式,以确定如何将日期格式化为日期数学索引名称表达式。
一个示例管道,根据date1字段中的日期,将文档指向以my-index-前缀开头的月度索引:
PUT _ingest/pipeline/monthlyindex
{
"description": "monthly date-time index naming",
"processors" : [
{
"date_index_name" : {
"field" : "date1",
"index_name_prefix" : "my-index-",
"date_rounding" : "M"
}
}
]
}
使用该管道进行索引请求:
PUT /my-index/_doc/1?pipeline=monthlyindex
{
"date1" : "2016-04-25T12:02:01.789Z"
}
{
"_index" : "my-index-2016-04-01",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 55,
"_primary_term" : 1
}
上述请求不会将此文档索引到my-index索引中,而是索引到my-index-2016-04-01索引中,因为它按月进行了舍入。这是因为日期索引名称处理器覆盖了文档的_index属性。
要查看在实际索引请求中提供的索引的日期数学值,该请求导致上述文档被索引到 my-index-2016-04-01,我们可以使用模拟请求来检查处理器的效果。
POST _ingest/pipeline/_simulate
{
"pipeline" :
{
"description": "monthly date-time index naming",
"processors" : [
{
"date_index_name" : {
"field" : "date1",
"index_name_prefix" : "my-index-",
"date_rounding" : "M"
}
}
]
},
"docs": [
{
"_source": {
"date1": "2016-04-25T12:02:01.789Z"
}
}
]
}
结果如下:
{
"docs" : [
{
"doc" : {
"_id" : "_id",
"_index" : "<my-index-{2016-04-25||/M{yyyy-MM-dd|UTC}}>",
"_version" : "-3",
"_source" : {
"date1" : "2016-04-25T12:02:01.789Z"
},
"_ingest" : {
"timestamp" : "2016-11-08T19:43:03.850+0000"
}
}
}
]
}
上面的示例显示了 _index 被设置为 2016-04-01,正如在 日期数学索引名称文档 中所解释的那样
表12. 日期索引名称选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
获取日期或时间戳的字段。 |
|
否 |
- |
在打印日期前要添加的索引名称的前缀。支持模板片段。 |
|
是 |
- |
在将日期格式化为索引名称时如何进行日期舍入。有效值为: |
|
否 |
yyyy-MM-dd'T'HH:mm:ss.SSSXX |
用于解析预处理文档中日期/时间戳的预期日期格式的数组。可以是java时间模式或以下格式之一:ISO8601、UNIX、UNIX_MS或TAI64N。 |
|
否 |
协调世界时 |
解析日期时使用的时区,以及日期数学索引支持将表达式解析为具体索引名称时使用的时区。 |
|
否 |
英语 |
解析文档中的日期时使用的区域设置,在解析月份名称或星期几时相关。 |
|
否 |
年-月-日 |
打印解析日期到索引名称时要使用的格式。这里需要一个有效的java时间模式。支持模板片段。 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
解剖处理器
edit类似于Grok处理器,dissect也从文档中的单个文本字段中提取结构化字段。然而,与Grok处理器不同,dissect不使用正则表达式。这使得dissect的语法更简单,并且在某些情况下比Grok处理器更快。
Dissect 将单个文本字段与定义的模式进行匹配。
例如,以下模式:
%{clientip} %{ident} %{auth} [%{@timestamp}] \"%{verb} %{request} HTTP/%{httpversion}\" %{status} %{size}
将匹配这种格式的日志行:
1.2.3.4 - - [30/Apr/1998:22:00:52 +0000] \"GET /english/venues/cities/images/montpellier/18.gif HTTP/1.0\" 200 3171
并生成包含以下字段的文档:
"doc": {
"_index": "_index",
"_type": "_type",
"_id": "_id",
"_source": {
"request": "/english/venues/cities/images/montpellier/18.gif",
"auth": "-",
"ident": "-",
"verb": "GET",
"@timestamp": "30/Apr/1998:22:00:52 +0000",
"size": "3171",
"clientip": "1.2.3.4",
"httpversion": "1.0",
"status": "200"
}
}
解剖模式由将被丢弃的字符串部分定义。在前面的示例中,第一个要丢弃的部分是单个空格。解剖找到这个空格,然后将clientip的值分配给直到该空格之前的所有内容。
接下来,解剖匹配[,然后是],然后将@timestamp分配给[和]之间的所有内容。
特别注意要丢弃的字符串部分将有助于构建成功的解剖模式。
成功的匹配需要模式中的所有键都有值。如果在模式中定义的任何%{keyname}没有值,则会抛出异常,并且可以通过on_failure指令来处理。
一个空的键%{}或命名跳过键可以用来匹配值,但排除最终文档中的值。所有匹配的值都表示为字符串数据类型。可以使用转换处理器将其转换为预期的数据类型。
Dissect 还支持 键修饰符,这些修饰符可以改变 dissect 的默认行为。例如,您可以指示 dissect 忽略某些字段、附加字段、跳过填充等。有关更多信息,请参见 下方。
表13. 解析选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要解析的字段 |
|
是 |
- |
应用于字段的格式 |
|
否 |
"" (空字符串) |
分隔附加字段的字符。 |
|
否 |
假 |
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
{
"dissect": {
"field": "message",
"pattern" : "%{clientip} %{ident} %{auth} [%{@timestamp}] \"%{verb} %{request} HTTP/%{httpversion}\" %{status} %{size}"
}
}
解剖键修饰符
edit键修饰符可以改变解剖的默认行为。键修饰符可能位于%{keyname}的左侧或右侧,始终位于%{和}内。例如,%{+keyname ->}具有追加和右填充修饰符。
表14. 解剖键修饰符
| Modifier | Name | Position | Example | Description | Details |
|---|---|---|---|---|---|
|
跳过右侧填充 |
(远)右边 |
|
跳过任何重复的字符到右侧 |
|
|
追加 |
左 |
|
将两个或更多字段连接在一起 |
|
|
按顺序追加 |
左和右 |
|
按指定顺序将两个或更多字段连接在一起 |
|
|
命名跳过键 |
左 |
|
跳过输出中的匹配值。与 |
|
|
引用键 |
左 |
|
将输出键设置为 |
右填充修饰符 (->)
edit执行分解的算法非常严格,因为它要求模式中的所有字符都与源字符串匹配。例如,模式 %{fookey} %{barkey}(1 个空格),将匹配字符串 "foo bar"(1 个空格),但不会匹配字符串 "foo bar"(2 个空格),因为模式只有 1 个空格,而源字符串有 2 个空格。
右填充修饰符有助于解决这种情况。将右填充修饰符添加到模式 %{fookey->} %{barkey} 中,
它现在将匹配 "foo bar"(1个空格)和 "foo bar"(2个空格)
甚至 "foo bar"(10个空格)。
使用正确的填充修饰符,以允许在%{keyname->}之后重复字符。
右填充修饰符可以放置在任何带有其他修饰符的键上。它应该始终是最右边的修饰符。例如:%{+keyname/1->} 和 %{->}
右侧填充修改器示例
模式 |
|
输入 |
1998-08-10T17:15:42,466 警告 |
结果 |
|
可以使用空的右填充修饰符来帮助跳过不需要的数据。例如,相同的输入字符串,但用括号包裹时,需要使用空的右填充键来实现相同的结果。
右侧填充修饰符与空键示例
模式 |
|
输入 |
[1998-08-10T17:15:42,466] [警告] |
结果 |
|
追加修饰符 (+)
editDissect 支持将两个或更多结果一起附加到输出中。 值从左到右附加。可以指定附加分隔符。 在此示例中,append_separator 定义为一个空格。
附加修饰符示例
模式 |
|
输入 |
约翰·雅各布·金格海默·施密特 |
结果 |
|
附加顺序修饰符(+ 和 /n)
editDissect 支持将两个或多个结果一起附加到输出中。
值根据定义的顺序(/n)进行附加。可以指定附加分隔符。
在这个例子中,附加分隔符定义为逗号。
附加顺序修饰符示例
模式 |
|
输入 |
约翰·雅各布·金格海默·施密特 |
结果 |
|
命名跳过键 (?)
editDissect 支持在最终结果中忽略匹配项。这可以通过使用空键 %{} 来实现,但为了提高可读性,可能希望为该空键指定一个名称。
命名跳过键修饰符示例
模式 |
|
输入 |
1.2.3.4 - - [30/4月/1998:22:00:52 +0000] |
结果 |
|
引用键 (* 和 &)
editDissect 支持使用解析的值作为结构化内容的关键/值对。想象一个系统,它部分以键/值对的形式记录日志。引用键允许你保持这种键/值关系。
引用键修饰符示例
模式 |
|
输入 |
[2018-08-10T17:15:42,466] [错误] ip:1.2.3.4 错误:REFUSED |
结果 |
|
点扩展处理器
edit将带有点的字段扩展为对象字段。此处理器允许名称中带有点的字段在管道中的其他处理器中可访问。否则,这些字段将无法被任何处理器访问。
表15. 点展开选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要扩展为对象字段的字段。如果设置为 |
|
否 |
- |
包含要展开字段的字段。仅当要展开的字段是另一个对象字段的一部分时才需要,因为 |
|
否 |
假 |
当扩展字段与现有的嵌套对象冲突时,控制其行为。当 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
{
"dot_expander": {
"field": "foo.bar"
}
}
例如,点扩展处理器会将此文档转换为:
{
"foo.bar" : "value"
}
转换为:
{
"foo" : {
"bar" : "value"
}
}
如果foo下已经有一个bar字段,那么这个处理器会将foo.bar字段合并到其中。如果该字段是一个标量值,那么它会将该字段转换为数组字段。
例如,以下文档:
{
"foo.bar" : "value2",
"foo" : {
"bar" : "value1"
}
}
被 dot_expander 处理器转换为:
{
"foo" : {
"bar" : ["value1", "value2"]
}
}
与之相比,当override选项设置为true时。
{
"dot_expander": {
"field": "foo.bar",
"override": true
}
}
在这种情况下,扩展字段的值会覆盖嵌套对象的值。
{
"foo" : {
"bar" : "value2"
}
}
可以将 field 的值设置为 * 以展开所有顶级点字段名称:
{
"dot_expander": {
"field": "*"
}
}
点展开处理器会将此文档转换为:
{
"foo.bar" : "value",
"baz.qux" : "value"
}
转换为:
{
"foo" : {
"bar" : "value"
},
"baz" : {
"qux" : "value"
}
}
如果点字段嵌套在非点结构中,则使用path选项来导航非点结构:
{
"dot_expander": {
"path": "foo"
"field": "*"
}
}
点展开处理器会将此文档转换为:
{
"foo" : {
"bar.one" : "value",
"bar.two" : "value"
}
}
转换为:
{
"foo" : {
"bar" : {
"one" : "value",
"two" : "value"
}
}
}
如果任何非叶子字段与同名的预先存在的字段冲突,则需要首先重命名该字段。
考虑以下文档:
{
"foo": "value1",
"foo.bar": "value2"
}
然后,在应用 dot_expander 处理器之前,需要先将 foo 重命名。因此,为了将 foo.bar 字段正确地扩展为 foo 字段下的 bar 字段,应使用以下管道:
{
"processors" : [
{
"rename" : {
"field" : "foo",
"target_field" : "foo.bar"
}
},
{
"dot_expander": {
"field": "foo.bar"
}
}
]
}
原因是Ingest不知道如何自动将标量字段转换为对象字段。
删除处理器
edit删除文档而不引发任何错误。这在某些条件下防止文档被索引时非常有用。
{
"drop": {
"if" : "ctx.network_name == 'Guest'"
}
}
丰富处理器
editThe enrich processor 可以通过另一个索引的数据来丰富文档。
有关如何设置此功能的更多信息,请参阅丰富数据部分。
表17. 富集选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要使用的丰富策略的名称。 |
|
是 |
- |
输入文档中与策略的 match_field 匹配的字段,用于检索增强数据。支持 模板片段。 |
|
是 |
- |
添加到传入文档中的字段,用于包含丰富数据。此字段包含在丰富策略中指定的 |
|
否 |
假 |
如果 |
|
否 |
真 |
如果处理器将更新具有预先存在的非空值字段的字段。当设置为 |
|
否 |
1 |
在配置的目标字段下包含的最大匹配文档数。如果 |
|
否 |
|
用于将传入文档的地理形状与丰富索引中的文档进行匹配的空间关系运算符。此选项仅用于 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
失败处理器
edit引发异常。这在期望管道失败并向请求者传递特定消息时非常有用。
{
"fail": {
"if" : "ctx.tags.contains('production') != true",
"message": "The production tag is not present, found tags: {{{tags}}}"
}
}
指纹处理器
edit计算文档内容的哈希值。您可以使用此哈希值进行 内容指纹识别。
表19. 指纹选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
不适用 |
要包含在指纹中的字段数组。对于对象,处理器会对字段键和值进行哈希处理。对于其他字段,处理器仅对字段值进行哈希处理。 |
|
否 |
|
指纹的输出字段。 |
|
否 |
<无> |
|
|
否 |
|
用于计算指纹的哈希方法。必须是以下之一: |
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
示例
edit以下示例说明了指纹处理器(fingerprint processor)的使用:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"fingerprint": {
"fields": ["user"]
}
}
]
},
"docs": [
{
"_source": {
"user": {
"last_name": "Smith",
"first_name": "John",
"date_of_birth": "1980-01-15",
"is_active": true
}
}
}
]
}
这将产生以下结果:
{
"docs": [
{
"doc": {
...
"_source": {
"fingerprint" : "WbSUPW4zY1PBPehh2AA/sSxiRjw=",
"user" : {
"last_name" : "Smith",
"first_name" : "John",
"date_of_birth" : "1980-01-15",
"is_active" : true
}
}
}
}
]
}
Foreach 处理器
edit对数组或对象的每个元素运行一个摄取处理器。
所有摄取处理器都可以在数组或对象元素上运行。然而,如果元素的数量未知,以相同的方式处理每个元素可能会很麻烦。
The foreach processor 允许你指定一个包含数组或对象值的 field,以及一个在字段中每个元素上运行的 processor。
访问键和值
edit当遍历数组或对象时,foreach 处理器将当前元素的值存储在 _ingest._value ingest
metadata 字段中。_ingest._value 包含整个元素值,包括任何子字段。您可以使用点表示法访问 _ingest._value 字段上的子字段值。
当遍历一个对象时,foreach 处理器还会将当前元素的键作为字符串存储在 _ingest._key 中。
您可以在processor中访问和更改_ingest._key和_ingest._value。有关示例,请参阅对象示例。
失败处理
edit如果foreach处理器无法处理某个元素且未指定on_failure处理器,foreach处理器将静默退出。这将使整个数组或对象值保持不变。
示例
edit以下示例展示了如何使用 foreach 处理器与不同的数据类型和选项:
数组
edit假设有以下文档:
{
"values" : ["foo", "bar", "baz"]
}
当这个foreach处理器处理这个示例文档时:
{
"foreach" : {
"field" : "values",
"processor" : {
"uppercase" : {
"field" : "_ingest._value"
}
}
}
}
处理后文档将如下所示:
{
"values" : ["FOO", "BAR", "BAZ"]
}
对象数组
edit假设有以下文档:
{
"persons" : [
{
"id" : "1",
"name" : "John Doe"
},
{
"id" : "2",
"name" : "Jane Doe"
}
]
}
在这种情况下,需要移除id字段,因此使用以下foreach处理器:
{
"foreach" : {
"field" : "persons",
"processor" : {
"remove" : {
"field" : "_ingest._value.id"
}
}
}
}
处理后的结果是:
{
"persons" : [
{
"name" : "John Doe"
},
{
"name" : "Jane Doe"
}
]
}
有关另一个对象数组示例,请参阅附件处理器文档。
对象
edit您也可以在对象字段上使用 foreach 处理器。例如,
以下文档包含一个 products 字段,其值为对象。
{
"products" : {
"widgets" : {
"total_sales" : 50,
"unit_price": 1.99,
"display_name": ""
},
"sprockets" : {
"total_sales" : 100,
"unit_price": 9.99,
"display_name": "Super Sprockets"
},
"whizbangs" : {
"total_sales" : 200,
"unit_price": 19.99,
"display_name": "Wonderful Whizbangs"
}
}
}
以下 foreach 处理器将 products.display_name 的值更改为大写。
{
"foreach": {
"field": "products",
"processor": {
"uppercase": {
"field": "_ingest._value.display_name"
}
}
}
}
当在文档上运行时,foreach 处理器返回:
{
"products" : {
"widgets" : {
"total_sales" : 50,
"unit_price" : 1.99,
"display_name" : ""
},
"sprockets" : {
"total_sales" : 100,
"unit_price" : 9.99,
"display_name" : "SUPER SPROCKETS"
},
"whizbangs" : {
"total_sales" : 200,
"unit_price" : 19.99,
"display_name" : "WONDERFUL WHIZBANGS"
}
}
}
以下 foreach 处理器将每个元素的键设置为 products.display_name 的值。如果 products.display_name 包含空字符串,处理器将删除该元素。
{
"foreach": {
"field": "products",
"processor": {
"set": {
"field": "_ingest._key",
"value": "{{_ingest._value.display_name}}"
}
}
}
}
当在前一个文档上运行时,foreach 处理器返回:
{
"products" : {
"Wonderful Whizbangs" : {
"total_sales" : 200,
"unit_price" : 19.99,
"display_name" : "Wonderful Whizbangs"
},
"Super Sprockets" : {
"total_sales" : 100,
"unit_price" : 9.99,
"display_name" : "Super Sprockets"
}
}
}
失败处理
edit包装的处理器可以有一个on_failure定义。
例如,id字段可能并不存在于所有person对象中。
与其让索引请求失败,你可以使用一个on_failure
块将文档发送到failure_index索引以供后续检查:
{
"foreach" : {
"field" : "persons",
"processor" : {
"remove" : {
"field" : "_value.id",
"on_failure" : [
{
"set" : {
"field": "_index",
"value": "failure_index"
}
}
]
}
}
}
}
在这个例子中,如果 remove 处理器失败了,那么到目前为止已处理过的数组元素将会被更新。
地理网格处理器
edit将地理网格定义的网格瓦片或单元格转换为描述其形状的常规边界框或多边形。
如果有必要将瓦片形状作为空间可索引字段进行交互,这是非常有用的。
例如,geotile 字段值 "4/8/3" 可以作为字符串字段进行索引,但这不会启用
任何空间操作。
相反,将其转换为值
"POLYGON ((0.0 40.979898069620134, 22.5 40.979898069620134, 22.5 55.77657301866769, 0.0 55.77657301866769, 0.0 40.979898069620134))",
可以将其索引为 geo_shape 字段。
表21. geo_grid处理器选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
解释为地理切片的字段。字段格式由 |
|
是 |
- |
理解三种瓦片格式: |
|
否 |
|
要分配多边形形状的字段,默认情况下 |
|
否 |
- |
如果指定且存在父级图块,则将该图块地址保存到此字段中。 |
|
否 |
- |
如果指定且存在子瓦片,将这些瓦片地址保存到此字段中,作为字符串数组。 |
|
否 |
- |
如果指定且存在相交的非子瓦片,请将它们的地址保存到此字段中,作为字符串数组。 |
|
否 |
- |
如果指定,将瓦片精度(缩放级别)作为整数保存到此字段。 |
|
否 |
- |
如果 |
|
否 |
"GeoJSON" |
生成的多边形保存的格式。可以是 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
为了演示这个摄取处理器的使用,考虑一个名为 geocells 的索引,
其中包含一个类型为 geo_shape 的字段 geocell。
为了使用 geotile 和 geohex 字段填充该索引,定义
两个摄取处理器:
PUT geocells
{
"mappings": {
"properties": {
"geocell": {
"type": "geo_shape"
}
}
}
}
PUT _ingest/pipeline/geotile2shape
{
"description": "translate rectangular z/x/y geotile to bounding box",
"processors": [
{
"geo_grid": {
"field": "geocell",
"tile_type": "geotile"
}
}
]
}
PUT _ingest/pipeline/geohex2shape
{
"description": "translate H3 cell to polygon",
"processors": [
{
"geo_grid": {
"field": "geocell",
"tile_type": "geohex",
"target_format": "wkt"
}
}
]
}
这两个管道可以用于将文档索引到 geocells 索引中。
geocell 字段将是矩形瓦片格式 z/x/y 或 H3 单元地址的字符串版本,
具体取决于我们在索引文档时使用的摄取处理器。
生成的几何图形将表示并索引为 geo_shape 字段,格式为
GeoJSON 或 Well-Known Text。
示例:带有GeoJSON信封的矩形地理瓦片
edit在这个例子中,一个以 z/x/y 格式定义值的 geocell 字段被索引为 GeoJSON Envelope,因为上面的 ingest-processor 是使用默认的 target_format 定义的。
PUT geocells/_doc/1?pipeline=geotile2shape
{
"geocell": "4/8/5"
}
GET geocells/_doc/1
响应显示了ingest-processor如何将geocell字段替换为可索引的geo_shape:
{
"_index": "geocells",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"geocell": {
"type": "Envelope",
"coordinates": [
[ 0.0, 55.77657301866769 ],
[ 22.5, 40.979898069620134 ]
]
}
}
}

示例:带有WKT格式多边形的六边形geohex
edit在这个例子中,一个带有H3字符串地址的geocell字段被索引为一个
WKT Polygon,因为此摄取处理器明确
定义了target_format。
PUT geocells/_doc/1?pipeline=geohex2shape
{
"geocell": "811fbffffffffff"
}
GET geocells/_doc/1
响应显示了ingest-processor如何将geocell字段替换为可索引的geo_shape:
{
"_index": "geocells",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"geocell": "POLYGON ((1.1885095294564962 49.470279179513454, 2.0265689212828875 45.18424864858389, 7.509948452934623 43.786609335802495, 12.6773177459836 46.40695743262768, 12.345747342333198 50.55427505169064, 6.259687012061477 51.964770150370896, 3.6300085578113794 50.610463307239115, 1.1885095294564962 49.470279179513454))"
}
}

示例:丰富的图块详细信息
edit如geo_grid处理器选项中所述, 可以设置许多其他字段,这些字段将丰富可用信息。 例如,使用H3瓦片时,有7个子瓦片,但只有第一个完全包含在父瓦片中。 其余六个仅部分与父瓦片重叠,并且存在另外六个非子瓦片 与父瓦片重叠。 这可以通过向摄取处理器添加父级和子级附加字段来研究:
PUT _ingest/pipeline/geohex2shape
{
"description": "translate H3 cell to polygon with enriched fields",
"processors": [
{
"geo_grid": {
"description": "Ingest H3 cells like '811fbffffffffff' and create polygons",
"field": "geocell",
"tile_type": "geohex",
"target_format": "wkt",
"target_field": "shape",
"parent_field": "parent",
"children_field": "children",
"non_children_field": "nonChildren",
"precision_field": "precision"
}
}
]
}
索引文档以查看不同的结果:
PUT geocells/_doc/1?pipeline=geohex2shape
{
"geocell": "811fbffffffffff"
}
GET geocells/_doc/1
此索引请求的响应:
{
"_index": "geocells",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"parent": "801ffffffffffff",
"geocell": "811fbffffffffff",
"precision": 1,
"shape": "POLYGON ((1.1885095294564962 49.470279179513454, 2.0265689212828875 45.18424864858389, 7.509948452934623 43.786609335802495, 12.6773177459836 46.40695743262768, 12.345747342333198 50.55427505169064, 6.259687012061477 51.964770150370896, 3.6300085578113794 50.610463307239115, 1.1885095294564962 49.470279179513454))",
"children": [
"821f87fffffffff",
"821f8ffffffffff",
"821f97fffffffff",
"821f9ffffffffff",
"821fa7fffffffff",
"821faffffffffff",
"821fb7fffffffff"
],
"nonChildren": [
"821ea7fffffffff",
"82186ffffffffff",
"82396ffffffffff",
"821f17fffffffff",
"821e37fffffffff",
"82194ffffffffff"
]
}
}
这些附加信息将能够实现,例如,创建一个H3单元格的可视化,包括其子单元格和与其相交的非子单元格。

GeoIP 处理器
editThe geoip processor 添加有关 IPv4 或 IPv6 地址的地理位置信息。
默认情况下,处理器使用来自 MaxMind 的 GeoLite2 City、GeoLite2 Country 和 GeoLite2 ASN IP 地理位置数据库,这些数据库在 CC BY-SA 4.0 许可下共享。如果您的节点可以连接到 storage.googleapis.com 域名,并且满足以下任一条件,它将自动下载这些数据库:
-
ingest.geoip.downloader.eager.download设置为 true -
您的集群至少有一个包含
geoip处理器的管道
Elasticsearch 会自动从 Elastic GeoIP 端点下载这些数据库的更新: https://geoip.elastic.co/v1/database。 要获取这些更新的下载统计信息,请使用 GeoIP 统计 API。
如果您的集群无法连接到 Elastic GeoIP 端点,或者您希望管理自己的更新,请参阅 管理您自己的 IP 地理位置数据库更新。
如果您希望 Elasticsearch 使用您提供的许可证密钥直接从 Maxmind 下载数据库文件,请参阅 创建或更新 geoip 数据库配置。
如果Elasticsearch在30天内无法连接到端点,所有更新的数据库将变为无效。Elasticsearch将停止使用geoip数据丰富文档,并将改为添加tags: ["_geoip_expired_database"]字段。
在管道中使用geoip处理器
edit表22. geoip 选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
用于地理查找的IP地址字段。 |
|
否 |
geoip |
将保存从MaxMind数据库中查找的地理信息字段。 |
|
否 |
GeoLite2-City.mmdb |
数据库文件名,指向自动下载的GeoLite2数据库之一(GeoLite2-City.mmdb、GeoLite2-Country.mmdb或GeoLite2-ASN.mmdb),或 |
|
否 |
[ |
控制基于geoip查找将哪些属性添加到 |
|
否 |
|
如果 |
|
否 |
|
如果 |
|
否 |
|
如果为 |
*取决于database_file中可用的内容:
-
如果使用GeoLite2 City或GeoIP2 City数据库,则可以在
target_field下添加以下字段:ip、country_iso_code、country_name、continent_code、continent_name、region_iso_code、region_name、city_name、timezone、 和location。实际添加的字段取决于找到的内容以及在properties中配置的属性。 -
如果使用GeoLite2 Country或GeoIP2 Country数据库,则可以在
target_field下添加以下字段:ip、country_iso_code、country_name、continent_code、和continent_name。实际添加的字段取决于找到的内容以及在properties中配置的属性。 -
如果使用GeoLite2 ASN数据库,则可以在
target_field下添加以下字段:ip、asn、organization_name和network。实际添加的字段取决于找到的内容以及在properties中配置的属性。 -
如果使用GeoIP2 Anonymous IP数据库,则可以在
target_field下添加以下字段:ip、hosting_provider、tor_exit_node、anonymous_vpn、anonymous、public_proxy和residential_proxy。实际添加的字段取决于找到的内容以及在properties中配置的属性。 -
如果使用GeoIP2 Connection Type数据库,则可以在
target_field下添加以下字段:ip和connection_type。实际添加的字段取决于找到的内容以及在properties中配置的属性。 -
如果使用GeoIP2 Domain数据库,则可以在
target_field下添加以下字段:ip和domain。 实际添加的字段取决于找到的内容以及在properties中配置的属性。 -
如果使用GeoIP2 ISP数据库,则可以在
target_field下添加以下字段:ip、asn、organization_name、network、isp、isp_organization_name、mobile_country_code和mobile_network_code。实际添加的字段取决于找到的内容以及在properties中配置的属性。 -
如果使用GeoIP2 Enterprise数据库,则可以在
target_field下添加以下字段:ip、country_iso_code、country_name、continent_code、continent_name、region_iso_code、region_name、city_name、timezone、location、asn、organization_name、network、hosting_provider、tor_exit_node、anonymous_vpn、anonymous、public_proxy、residential_proxy、domain、isp、isp_organization_name、mobile_country_code、mobile_network_code、user_type和connection_type。实际添加的字段取决于找到的内容以及在properties中配置的属性。
请勿在生产环境中使用 GeoIP2 Anonymous IP、GeoIP2 Connection Type、GeoIP2 Domain、GeoIP2 ISP 和 GeoIP2 Enterprise 数据库。此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
这是一个使用默认城市数据库并将地理信息添加到基于ip字段的geoip字段的示例:
PUT _ingest/pipeline/geoip
{
"description" : "Add geoip info",
"processors" : [
{
"geoip" : {
"field" : "ip"
}
}
]
}
PUT my-index-000001/_doc/my_id?pipeline=geoip
{
"ip": "89.160.20.128"
}
GET my-index-000001/_doc/my_id
返回结果:
{
"found": true,
"_index": "my-index-000001",
"_id": "my_id",
"_version": 1,
"_seq_no": 55,
"_primary_term": 1,
"_source": {
"ip": "89.160.20.128",
"geoip": {
"continent_name": "Europe",
"country_name": "Sweden",
"country_iso_code": "SE",
"city_name" : "Linköping",
"region_iso_code" : "SE-E",
"region_name" : "Östergötland County",
"location": { "lat": 58.4167, "lon": 15.6167 }
}
}
}
这是一个使用默认国家数据库的示例,并根据ip字段将地理信息添加到geo字段中。请注意,此数据库会自动下载。因此,如下所示:
PUT _ingest/pipeline/geoip
{
"description" : "Add geoip info",
"processors" : [
{
"geoip" : {
"field" : "ip",
"target_field" : "geo",
"database_file" : "GeoLite2-Country.mmdb"
}
}
]
}
PUT my-index-000001/_doc/my_id?pipeline=geoip
{
"ip": "89.160.20.128"
}
GET my-index-000001/_doc/my_id
返回如下内容:
{
"found": true,
"_index": "my-index-000001",
"_id": "my_id",
"_version": 1,
"_seq_no": 65,
"_primary_term": 1,
"_source": {
"ip": "89.160.20.128",
"geo": {
"continent_name": "Europe",
"country_name": "Sweden",
"country_iso_code": "SE"
}
}
}
并非所有IP地址都能从数据库中找到地理位置信息,当这种情况发生时,文档中不会插入target_field。
以下是当无法找到“80.231.5.0”的信息时,文档将被索引的示例:
PUT _ingest/pipeline/geoip
{
"description" : "Add geoip info",
"processors" : [
{
"geoip" : {
"field" : "ip"
}
}
]
}
PUT my-index-000001/_doc/my_id?pipeline=geoip
{
"ip": "80.231.5.0"
}
GET my-index-000001/_doc/my_id
返回结果:
{
"_index" : "my-index-000001",
"_id" : "my_id",
"_version" : 1,
"_seq_no" : 71,
"_primary_term": 1,
"found" : true,
"_source" : {
"ip" : "80.231.5.0"
}
}
管理您自己的IP地理位置数据库更新
edit如果你无法从Elastic端点自动更新你的IP地理位置数据库,你还有其他几个选项:
如果你无法直接连接到 Elastic GeoIP 端点,请考虑设置一个安全代理。然后,你可以在每个节点的 elasticsearch.yml 文件中指定代理端点 URL。
在严格的设置中,可能需要将以下域名添加到允许的域名列表中:
-
geoip.elastic.co -
storage.googleapis.com
您可以创建一个模拟 Elastic GeoIP 端点的服务。然后,您可以从该服务获取自动更新。
-
从 MaxMind 网站 下载您的
.mmdb数据库文件。 - 将您的数据库文件复制到一个目录中。
-
从您的 Elasticsearch 目录中,运行:
./bin/elasticsearch-geoip -s my/source/dir [-t target/directory]
-
从您的目录中提供静态数据库文件。例如,您可以使用 Docker 从 nginx 服务器提供文件:
docker run -v my/source/dir:/usr/share/nginx/html:ro nginx
-
在每个节点的
elasticsearch.yml文件中,指定服务的端点 URL 在ingest.geoip.downloader.endpoint设置中。默认情况下,Elasticsearch 每三天检查一次端点的更新。要使用其他轮询间隔,请使用 集群更新设置 API 来设置
ingest.geoip.downloader.poll.interval。
-
使用 集群更新设置 API 将
ingest.geoip.downloader.enabled设置为false。这将禁用可能覆盖您的数据库更改的自动更新。这还会删除所有已下载的数据库。 -
从 MaxMind 网站 下载您的
.mmdb数据库文件。您还可以使用自定义的城市、国家/地区和 ASN
.mmdb文件。这些文件必须是未压缩的。类型(城市、国家/地区或 ASN)将从文件元数据中提取,因此文件名无关紧要。 - 在 Elasticsearch Service 部署上,使用 自定义捆绑包 上传数据库。
-
在自管理的部署上,将数据库文件复制到
$ES_CONFIG/ingest-geoip。 -
在您的
geoip处理器中,配置database_file参数以使用自定义数据库文件。
节点设置
editThe geoip 处理器支持以下设置:
-
ingest.geoip.cache_size -
应缓存的最大结果数。默认为
1000。
请注意,这些设置是节点设置,适用于所有geoip处理器,即所有定义的geoip处理器共享一个缓存。
集群设置
edit-
ingest.geoip.downloader.enabled -
(动态, 布尔值)
如果
true,Elasticsearch 会自动下载并管理从ingest.geoip.downloader.endpoint获取的 IP 地理位置数据库的更新。如果false,Elasticsearch 不会下载更新并删除所有已下载的数据库。默认为true。
-
ingest.geoip.downloader.eager.download -
(动态, 布尔值)
如果
true,Elasticsearch 会立即下载 IP 地理位置数据库,无论是否存在包含 geoip 处理器的管道。如果false,Elasticsearch 仅在存在包含 geoip 处理器的管道或添加此类管道时才开始下载数据库。默认为false。
-
ingest.geoip.downloader.endpoint -
(静态, 字符串)
用于下载IP地理位置数据库更新的端点URL。例如,
https://myDomain.com/overview.json。 默认为https://geoip.elastic.co/v1/database。Elasticsearch将下载的数据库文件存储在每个节点的临时目录中,路径为$ES_TMPDIR/geoip-databases/。 请注意,Elasticsearch将向${ingest.geoip.downloader.endpoint}?elastic_geoip_service_tos=agree发出GET请求,期望获取通常在overview.json中找到的数据库元数据列表。
GeoIP 下载器使用 JDK 的内置 cacerts。如果您使用的是自定义端点,请将自定义 https 端点的 cacert(s) 添加到 JDK 的信任库中。
Grok 处理器
edit从文档中的单个文本字段中提取结构化字段。您可以选择从哪个字段提取匹配的字段,以及您期望匹配的grok模式。grok模式类似于支持可重用别名表达式的正则表达式。
此处理器附带了许多 可重用的模式。
如果您需要帮助构建模式以匹配您的日志,您会发现 Grok Debugger 工具非常有用! Grok Constructor 也是一个有用的工具。
在管道中使用 Grok 处理器
edit表23. Grok 选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
用于grok表达式解析的字段 |
|
是 |
- |
一个有序的grok表达式列表,用于匹配和提取命名捕获。返回列表中第一个匹配的表达式。 |
|
否 |
- |
定义当前处理器使用的自定义模式的名称和模式元组的映射。匹配现有名称的模式将覆盖预先存在的定义。 |
|
否 |
|
必须是 |
|
否 |
假 |
当为真时, |
|
否 |
假 |
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
这是一个使用提供的模式从文档中的字符串字段提取并命名结构化字段的示例。
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description" : "...",
"processors": [
{
"grok": {
"field": "message",
"patterns": ["%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes:int} %{NUMBER:duration:double}"]
}
}
]
},
"docs":[
{
"_source": {
"message": "55.3.244.1 GET /index.html 15824 0.043"
}
}
]
}
此管道将把这些命名捕获插入到文档中的新字段中,如下所示:
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source" : {
"duration" : 0.043,
"request" : "/index.html",
"method" : "GET",
"bytes" : 15824,
"client" : "55.3.244.1",
"message" : "55.3.244.1 GET /index.html 15824 0.043"
},
"_ingest": {
"timestamp": "2016-11-08T19:43:03.850+0000"
}
}
}
]
}
自定义模式
editGrok 处理器预先打包了一组基础模式。这些模式可能并不总是包含您所需的内容。模式具有非常基本的格式。每个条目都有一个名称和模式本身。
您可以在处理器定义下的 pattern_definitions 选项中添加自己的模式。
以下是一个指定自定义模式定义的管道的示例:
{
"description" : "...",
"processors": [
{
"grok": {
"field": "message",
"patterns": ["my %{FAVORITE_DOG:dog} is colored %{RGB:color}"],
"pattern_definitions" : {
"FAVORITE_DOG" : "beagle",
"RGB" : "RED|GREEN|BLUE"
}
}
}
]
}
提供多个匹配模式
edit有时一个模式不足以捕捉字段的潜在结构。假设我们想要匹配所有包含你最喜欢的宠物品种的消息,无论是猫还是狗。一种实现方法是提供两个不同的模式进行匹配,而不是使用一个非常复杂的表达式来捕捉相同的或行为。
这是一个针对模拟API执行的此类配置的示例:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description" : "parse multiple patterns",
"processors": [
{
"grok": {
"field": "message",
"patterns": ["%{FAVORITE_DOG:pet}", "%{FAVORITE_CAT:pet}"],
"pattern_definitions" : {
"FAVORITE_DOG" : "beagle",
"FAVORITE_CAT" : "burmese"
}
}
}
]
},
"docs":[
{
"_source": {
"message": "I love burmese cats!"
}
}
]
}
响应:
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"message": "I love burmese cats!",
"pet": "burmese"
},
"_ingest": {
"timestamp": "2016-11-08T19:43:03.850+0000"
}
}
}
]
}
两种模式都会将字段 pet 设置为适当的匹配项,但如果我们想要追踪是哪种模式匹配并填充了我们的字段呢?我们可以通过 trace_match 参数来实现这一点。以下是相同的管道输出,但配置了 "trace_match": true:
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"message": "I love burmese cats!",
"pet": "burmese"
},
"_ingest": {
"_grok_match_index": "1",
"timestamp": "2016-11-08T19:43:03.850+0000"
}
}
}
]
}
在上述响应中,你可以看到匹配的模式的索引是"1"。这意味着它是patterns中第二个(索引从零开始)匹配的模式。
此跟踪元数据有助于调试匹配的模式。此信息存储在摄取元数据中,不会被索引。
从REST端点检索模式
editGrok 处理器自带一个 REST 端点,用于检索处理器中包含的模式。
GET _ingest/processor/grok
上述请求将返回一个响应体,其中包含内置模式字典的键值表示。
{
"patterns" : {
"BACULA_CAPACITY" : "%{INT}{1,3}(,%{INT}{3})*",
"PATH" : "(?:%{UNIXPATH}|%{WINPATH})",
...
}
默认情况下,API 返回一组传统的 Grok 模式。这些传统模式早于 Elastic Common Schema (ECS),并且不使用 ECS 字段名称。要返回提取 ECS 字段名称的模式,请在可选的 ecs_compatibility 查询参数中指定 v1。
GET _ingest/processor/grok?ecs_compatibility=v1
默认情况下,API 返回的模式是按照从磁盘读取的顺序排列的。这种排序方式保留了相关模式的组合。例如,所有与解析 Linux syslog 行相关的模式都保持在一起。
您可以使用可选的布尔值s查询参数来按键名对返回的模式进行排序。
GET _ingest/processor/grok?s
API返回以下响应。
{
"patterns" : {
"BACULA_CAPACITY" : "%{INT}{1,3}(,%{INT}{3})*",
"BACULA_DEVICE" : "%{USER}",
"BACULA_DEVICEPATH" : "%{UNIXPATH}",
...
}
这在内置模式随版本变化时作为参考很有用。
Grok 看门狗
edit执行时间过长的Grok表达式会被中断,并且Grok处理器会抛出异常。Grok处理器有一个看门狗线程,用于确定Grok表达式的评估时间是否过长,并由以下设置控制:
Grok 调试
edit建议使用Grok Debugger来调试grok模式。在那里,您可以在UI中针对示例数据测试一个或多个模式。在底层,它使用与ingest节点处理器相同的引擎。
此外,建议为 Grok 启用调试日志记录,以便在 Elasticsearch 服务器日志中也能看到任何附加消息。
PUT _cluster/settings
{
"persistent": {
"logger.org.elasticsearch.ingest.common.GrokProcessor": "debug"
}
}
Gsub 处理器
edit通过应用正则表达式和替换来转换字符串字段。 如果该字段是字符串数组,则数组的所有成员都将被转换。如果遇到任何非字符串值,处理器将抛出异常。
表25. Gsub 选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要应用替换的字段 |
|
是 |
- |
要替换的模式 |
|
是 |
- |
用于替换匹配模式的字符串 |
|
否 |
|
要分配转换值的字段,默认情况下 |
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
{
"gsub": {
"field": "field1",
"pattern": "\\.",
"replacement": "-"
}
}
HTML 剥离处理器
edit从字段中移除HTML标签。如果字段是字符串数组,则将从数组的所有成员中移除HTML标签。
每个HTML标签都被替换为一个\n字符。
{
"html_strip": {
"field": "foo"
}
}
推理处理器
edit使用预训练的数据框分析模型或部署用于自然语言处理任务的模型,对正在管道中摄取的数据进行推断。
表27. 推理选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
(字符串) 训练模型的ID或别名,或者是部署的ID。 |
|
否 |
- |
(列表) 用于推理的输入字段和用于推理结果的输出(目标)字段。此选项与 |
|
否 |
|
(字符串) 添加到传入文档中的字段,用于包含结果对象。 |
|
否 |
如果定义了模型的默认字段映射 |
(对象) 将文档字段名称映射到模型已知的字段名称。此映射优先于模型配置中提供的任何默认映射。 |
|
否 |
模型中定义的默认设置 |
(对象) 包含推理类型及其选项。 |
|
否 |
|
(布尔值) 如果为 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
配置输入和输出字段
edit选择content字段进行推理,并将结果写入content_embedding。
如果指定的output_field已经存在于摄取文档中,它将不会被覆盖。
推理结果将被追加到output_field中的现有字段,这可能导致重复字段和潜在错误。
为避免这种情况,请使用一个与任何现有字段不冲突的唯一output_field字段名称。
{
"inference": {
"model_id": "model_deployment_for_inference",
"input_output": [
{
"input_field": "content",
"output_field": "content_embedding"
}
]
}
}
配置多个输入
edit将从传入文档中读取content和title字段,并发送到模型进行推理。推理输出分别写入content_embedding和title_embedding。
{
"inference": {
"model_id": "model_deployment_for_inference",
"input_output": [
{
"input_field": "content",
"output_field": "content_embedding"
},
{
"input_field": "title",
"output_field": "title_embedding"
}
]
}
}
选择带有 input_output 的输入字段与 target_field 和 field_map 选项不兼容。
数据框分析模型必须使用target_field来指定结果写入的根位置,并可选择使用field_map来映射输入文档中的字段名称到模型输入字段。
{
"inference": {
"model_id": "model_deployment_for_inference",
"target_field": "FlightDelayMin_prediction_infer",
"field_map": {
"your_field": "my_field"
},
"inference_config": { "regression": {} }
}
}
分类配置选项
edit推理的分类配置。
-
num_top_classes - (可选, 整数) 指定要返回的顶级类别预测的数量。默认为 0。
-
num_top_feature_importance_values - (可选,整数) 指定每个文档的 特征重要性值的最大数量。默认为0,表示不进行特征重要性计算。
-
results_field -
(可选,字符串)
添加到传入文档中的字段,用于包含推理预测。默认为用于训练模型的数据框分析作业的
results_field值,该值默认为_prediction -
top_classes_results_field -
(可选,字符串)
指定写入顶级类别的字段。默认为
top_classes。 -
prediction_field_type -
(可选, 字符串)
指定要写入的预测字段类型。
有效值为:
string,number,boolean。当提供boolean时1.0转换为true,0.0转换为false。
填充掩码配置选项
edit-
num_top_classes - (可选, 整数) 指定要返回的顶级类别预测的数量。默认为 0。
-
results_field -
(可选, 字符串)
添加到传入文档中的字段,用于包含推理预测。默认为用于训练模型的数据框分析作业的
results_field值,该值默认为_prediction -
tokenization -
(可选, 对象) 指示要执行的分词以及所需的设置。 默认的分词配置是
bert。有效的分词值包括-
bert: 用于BERT风格的模型 -
deberta_v2: 用于DeBERTa v2和v3风格的模型 -
mpnet: 用于MPNet风格的模型 -
roberta: 用于RoBERTa风格和BART风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
xlm_roberta: 用于XLMRoBERTa风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
bert_ja: 用于为日语训练的BERT风格模型
分词的属性
-
bert -
(可选, 对象) BERT风格的标记化将使用包含的设置进行。
bert的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
deberta_v2 -
(可选, 对象) DeBERTa风格的标记化将使用包含的设置进行。
deberta_v2的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
balanced: 可能会截断第一个和/或第二个序列,以便平衡从两个序列中包含的标记。 -
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
-
-
roberta -
(可选, 对象) 将使用封闭的设置执行RoBERTa风格的标记化。
roberta的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
mpnet -
(可选, 对象) MPNet 风格的标记化将使用包含的设置进行。
mpnet的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
NER 配置选项
edit-
results_field -
(可选, 字符串)
添加到传入文档中的字段,用于包含推理预测。默认为用于训练模型的数据框分析作业的
results_field值,该值默认为_prediction -
tokenization -
(可选, 对象) 指示要执行的分词以及所需的设置。 默认的分词配置是
bert。有效的分词值包括-
bert: 用于BERT风格的模型 -
deberta_v2: 用于DeBERTa v2和v3风格的模型 -
mpnet: 用于MPNet风格的模型 -
roberta: 用于RoBERTa风格和BART风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
xlm_roberta: 用于XLMRoBERTa风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
bert_ja: 用于为日语训练的BERT风格模型
分词的属性
-
bert -
(可选, 对象) BERT风格的标记化将使用包含的设置进行。
bert的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
deberta_v2 -
(可选, 对象) DeBERTa风格的标记化将使用包含的设置进行。
deberta_v2的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
balanced: 可能会截断第一个和/或第二个序列,以平衡两个序列中包含的标记。 -
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
-
-
roberta -
(可选, 对象) 将使用封闭的设置执行RoBERTa风格的标记化。
roberta的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
mpnet -
(可选, 对象) MPNet 风格的标记化将使用包含的设置进行。
mpnet的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
回归配置选项
edit推理的回归配置。
-
results_field -
(可选, 字符串)
添加到传入文档中的字段,用于包含推理预测。默认为用于训练模型的数据框分析作业的
results_field值,该值默认为_prediction -
num_top_feature_importance_values - (可选,整数) 指定每个文档的 特征重要性值的最大数量。 默认情况下,它为零,不进行特征重要性计算。
文本分类配置选项
edit-
classification_labels - (可选,字符串) 分类标签的数组。
-
num_top_classes - (可选, 整数) 指定要返回的顶级类别预测的数量。默认为 0。
-
results_field -
(可选, 字符串)
添加到传入文档中的字段,用于包含推理预测。默认为用于训练模型的数据框分析作业的
results_field值,该值默认为_prediction -
tokenization -
(可选, 对象) 指示要执行的分词以及所需的设置。 默认的分词配置是
bert。有效的分词值包括-
bert: 用于BERT风格的模型 -
deberta_v2: 用于DeBERTa v2和v3风格的模型 -
mpnet: 用于MPNet风格的模型 -
roberta: 用于RoBERTa风格和BART风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
xlm_roberta: 用于XLMRoBERTa风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
bert_ja: 用于为日语训练的BERT风格模型
分词的属性
-
bert -
(可选, 对象) BERT风格的标记化将使用包含的设置进行。
bert的属性
-
span -
(可选, 整数) 当
truncate为none时,您可以为推理划分较长的文本序列。该值表示每个子序列之间重叠的标记数量。默认值为
-1,表示不进行窗口化或跨度操作。当您的典型输入仅略大于
max_sequence_length时,最好直接截断;第二个子序列中的信息将非常少。 -
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
deberta_v2 -
(可选, 对象) DeBERTa风格的标记化将使用包含的设置进行。
deberta_v2的属性
-
span -
(可选, 整数) 当
truncate为none时,您可以为推理划分较长的文本序列。该值表示每个子序列之间重叠的标记数量。默认值为
-1,表示不进行窗口化或跨度操作。当您的典型输入仅略大于
max_sequence_length时,最好直接截断;第二个子序列中的信息将非常少。 -
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
balanced: 第一个和第二个序列中的一个或两个可能会被截断,以便平衡从两个序列中包含的标记。 -
none: 不发生截断;推理请求收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
-
-
roberta -
(可选, 对象) 将使用封闭的设置执行RoBERTa风格的标记化。
roberta的属性
-
span -
(可选, 整数) 当
truncate为none时,您可以为推理划分较长的文本序列。该值表示每个子序列之间重叠的标记数量。默认值为
-1,表示不进行窗口化或跨度操作。当您的典型输入仅略大于
max_sequence_length时,最好直接截断;第二个子序列中的信息将非常少。 -
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
mpnet -
(可选, 对象) MPNet 风格的标记化将使用包含的设置进行。
mpnet的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
文本嵌入配置选项
edit-
results_field -
(可选, 字符串)
添加到传入文档中的字段,用于包含推理预测。默认为用于训练模型的数据框分析作业的
results_field值,该值默认为_prediction -
tokenization -
(可选, 对象) 指示要执行的分词以及所需的设置。 默认的分词配置是
bert。有效的分词值包括-
bert: 用于BERT风格的模型 -
deberta_v2: 用于DeBERTa v2和v3风格的模型 -
mpnet: 用于MPNet风格的模型 -
roberta: 用于RoBERTa风格和BART风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
xlm_roberta: 用于XLMRoBERTa风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
bert_ja: 用于为日语训练的BERT风格模型
分词的属性
-
bert -
(可选, 对象) BERT风格的标记化将使用包含的设置进行。
bert的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
deberta_v2 -
(可选, 对象) DeBERTa风格的标记化将使用包含的设置进行。
deberta_v2的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
balanced: 可能会截断第一个和/或第二个序列,以便平衡从两个序列中包含的标记。 -
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
-
-
roberta -
(可选, 对象) 将使用封闭的设置执行RoBERTa风格的标记化。
roberta的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
mpnet -
(可选, 对象) MPNet 风格的标记化将使用包含的设置进行。
mpnet的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
文本扩展配置选项
edit-
results_field -
(可选, 字符串)
添加到传入文档中的字段,用于包含推理预测。默认为用于训练模型的数据框分析作业的
results_field值,该值默认为_prediction -
tokenization -
(可选, 对象) 指示要执行的分词以及所需的设置。 默认的分词配置是
bert。有效的分词值包括-
bert: 用于BERT风格的模型 -
deberta_v2: 用于DeBERTa v2和v3风格的模型 -
mpnet: 用于MPNet风格的模型 -
roberta: 用于RoBERTa风格和BART风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
xlm_roberta: 用于XLMRoBERTa风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
bert_ja: 用于为日语训练的BERT风格模型
分词的属性
-
bert -
(可选, 对象) BERT风格的标记化将使用包含的设置进行。
bert的属性
-
span -
(可选, 整数) 当
truncate为none时,您可以为推理划分较长的文本序列。该值表示每个子序列之间重叠的标记数量。默认值为
-1,表示不进行窗口化或跨度操作。当您的典型输入仅略大于
max_sequence_length时,最好直接截断;第二个子序列中的信息将非常少。 -
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
deberta_v2 -
(可选, 对象) DeBERTa风格的标记化将使用包含的设置进行。
deberta_v2的属性
-
span -
(可选, 整数) 当
truncate为none时,您可以为推理划分较长的文本序列。该值表示每个子序列之间重叠的标记数量。默认值为
-1,表示不进行窗口化或跨度操作。当您的典型输入仅略大于
max_sequence_length时,最好直接截断;第二个子序列中的信息将非常少。 -
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
balanced: 第一个和第二个序列中的一个或两个可能会被截断,以便平衡从两个序列中包含的标记。 -
none: 不发生截断;推理请求收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
-
-
roberta -
(可选, 对象) 将使用封闭的设置执行RoBERTa风格的标记化。
roberta的属性
-
span -
(可选, 整数) 当
truncate为none时,您可以为推理划分较长的文本序列。该值表示每个子序列之间重叠的标记数量。默认值为
-1,表示不进行窗口化或跨度操作。当您的典型输入仅略大于
max_sequence_length时,最好直接截断;第二个子序列中的信息将非常少。 -
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
mpnet -
(可选, 对象) MPNet 风格的标记化将使用包含的设置进行。
mpnet的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
文本相似度配置选项
edit-
text_similarity -
(对象, 可选) 文本相似度接受一个输入序列并将其与另一个输入序列进行比较。这通常被称为交叉编码。当比较文档文本与提供的另一个文本输入时,此任务对于对文档文本进行排序非常有用。
文本相似度推理的属性
-
span_score_combination_function -
(可选,字符串) 标识当提供的文本段落长度超过
max_sequence_length且必须自动分隔以进行多次调用时,如何组合最终的相似度分数。这仅在truncate为none且span为非负数时适用。默认值为max。可用选项包括:-
max: 返回所有跨度中的最大分数。 -
mean: 返回所有跨度的平均分数。
-
-
tokenization -
(可选, 对象) 指示要执行的分词以及所需的设置。 默认的分词配置是
bert。有效的分词值包括-
bert: 用于BERT风格的模型 -
deberta_v2: 用于DeBERTa v2和v3风格的模型 -
mpnet: 用于MPNet风格的模型 -
roberta: 用于RoBERTa风格和BART风格的模型 -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
xlm_roberta: 用于XLMRoBERTa风格的模型 -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
bert_ja: 用于为日语训练的BERT风格模型
请参阅分词的属性以查看
tokenization对象的属性。 -
-
零样本分类配置选项
edit-
labels - (可选, 数组) 要分类的标签。可以在创建时设置默认标签,然后在推理过程中更新。
-
multi_label -
(Optional, boolean)
Indicates if more than one
truelabel is possible given the input. This is useful when labeling text that could pertain to more than one of the input labels. Defaults tofalse. -
results_field -
(可选, 字符串)
添加到传入文档中的字段,用于包含推理预测。默认为用于训练模型的数据框分析作业的
results_field值,该值默认为_prediction -
tokenization -
(可选, 对象) 指示要执行的分词以及所需的设置。 默认的分词配置是
bert。有效的分词值包括-
bert: 用于BERT风格的模型 -
deberta_v2: 用于DeBERTa v2和v3风格的模型 -
mpnet: 用于MPNet风格的模型 -
roberta: 用于RoBERTa风格和BART风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
xlm_roberta: 用于XLMRoBERTa风格的模型 -
[preview]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic将努力修复任何问题,但技术预览中的功能不受官方GA功能的SLA支持。
bert_ja: 用于为日语训练的BERT风格模型
分词的属性
-
bert -
(可选, 对象) BERT风格的标记化将使用包含的设置进行。
bert的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
deberta_v2 -
(可选, 对象) DeBERTa风格的标记化将使用包含的设置进行。
deberta_v2的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
balanced: 可能会截断第一个和/或第二个序列,以便平衡从两个序列中包含的标记。 -
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
-
-
roberta -
(可选, 对象) 将使用封闭的设置执行RoBERTa风格的标记化。
roberta的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
mpnet -
(可选, 对象) MPNet 风格的标记化将使用包含的设置进行。
mpnet的属性
-
truncate -
(可选,字符串) 指示当标记超过
max_sequence_length时如何截断它们。 默认值是first。-
none: 不发生截断;推理请求会收到错误。 -
first: 仅截断第一个序列。 -
second: 仅截断第二个序列。如果只有一个序列,则截断该序列。
-
对于
zero_shot_classification,假设序列始终是第二个序列。因此,在这种情况下不要使用second。 -
-
推理处理器示例
edit"inference":{
"model_id": "my_model_id",
"field_map": {
"original_fieldname": "expected_fieldname"
},
"inference_config": {
"regression": {
"results_field": "my_regression"
}
}
}
此配置指定了一个回归推理,结果被写入到目标字段结果对象中的我的回归字段。字段映射配置将源文档中的字段原始字段名映射到模型所期望的字段。
"inference":{
"model_id":"my_model_id"
"inference_config": {
"classification": {
"num_top_classes": 2,
"results_field": "prediction",
"top_classes_results_field": "probabilities"
}
}
}
此配置指定了一个分类推理。报告的预测概率的类别数量为2(num_top_classes)。结果写入预测字段,并将顶级类别写入概率字段。这两个字段都包含在目标字段结果对象中。
有关使用自然语言处理训练模型的示例,请参阅 将NLP推理添加到摄取管道。
特征重要性对象映射
edit为了充分利用聚合和搜索特征重要性,请按照以下所示更新特征重要性结果字段的索引映射:
"ml.inference.feature_importance": {
"type": "nested",
"dynamic": true,
"properties": {
"feature_name": {
"type": "keyword"
},
"importance": {
"type": "double"
}
}
}
特征重要性的映射字段名称(如上例中的 ml.inference.feature_importance)如下所示:
feature_importance
-
ml.inference。 -
例如,如果您在定义中提供了一个标签 foo,如下所示:
{
"tag": "foo",
...
}
然后,特征重要性值被写入到ml.inference.foo.feature_importance字段中。
您也可以如下指定目标字段:
{
"tag": "foo",
"target_field": "my_field"
}
在这种情况下,特征重要性在
my_field.foo.feature_importance 字段中暴露。
连接处理器
edit使用分隔符字符将数组中的每个元素连接成一个字符串。 当字段不是数组时,会抛出错误。
{
"join": {
"field": "joined_array_field",
"separator": "-"
}
}
JSON 处理器
edit将JSON字符串转换为结构化的JSON对象。
表29. Json选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要解析的字段。 |
|
否 |
|
转换后的结构化对象将被写入的字段。该字段中的任何现有内容将被覆盖。 |
|
否 |
假 |
强制将解析的JSON添加到文档的顶层。选择此选项时, |
|
否 |
|
当设置为 |
|
否 |
假 |
当设置为 |
|
否 |
真 |
当设置为 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
所有支持的JSON类型都将被解析(null、布尔值、数字、数组、对象、字符串)。
假设您提供了这个 json 处理器的配置:
{
"json" : {
"field" : "string_source",
"target_field" : "json_target"
}
}
如果处理以下文档:
{
"string_source": "{\"foo\": 2000}"
}
在经过json处理器处理后,它将看起来像:
{
"string_source": "{\"foo\": 2000}",
"json_target": {
"foo": 2000
}
}
如果提供了以下配置,省略可选的 target_field 设置:
{
"json" : {
"field" : "source_and_target"
}
}
然后在这个文档上操作json处理器之后:
{
"source_and_target": "{\"foo\": 2000}"
}
它将显示为:
{
"source_and_target": {
"foo": 2000
}
}
这说明了,除非在处理器配置中明确命名,否则target_field
与在必需的field配置中提供的字段是相同的。
KV 处理器
edit此处理器帮助自动解析消息(或特定事件字段),这些消息属于foo=bar类型。
例如,如果你有一个包含 ip=1.2.3.4 error=REFUSED 的日志消息,你可以通过配置来自动解析这些字段:
{
"kv": {
"field": "message",
"field_split": " ",
"value_split": "="
}
}
使用KV处理器可能会导致您无法控制的字段名称。考虑使用Flattened数据类型,它将整个对象映射为一个单一字段,并允许对其内容进行简单搜索。
表30. KV选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要解析的字段。支持 模板片段。 |
|
是 |
- |
用于拆分键值对的正则表达式模式 |
|
是 |
- |
用于从键值对中拆分键和值的正则表达式模式 |
|
否 |
|
要插入提取键的字段。默认为文档的根。支持模板片段。 |
|
否 |
|
用于过滤和插入文档的键列表。默认包括所有键 |
|
否 |
|
要从文档中排除的键的列表 |
|
否 |
|
如果 |
|
否 |
|
要添加到提取键的前缀 |
|
否 |
|
从提取的键中修剪的字符串 |
|
否 |
|
从提取的值中修剪的字符串 |
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
网络方向处理器
edit计算给定源IP地址、目标IP地址和内部网络列表的网络方向。
网络方向处理器默认从
Elastic Common Schema (ECS) 字段中读取 IP 地址。如果您使用 ECS,
只需指定 internal_networks 选项。
表32. 网络方向选项
| Name | Required | Default | Description |
|---|---|---|---|
|
否 |
|
包含源IP地址的字段。 |
|
否 |
|
包含目标IP地址的字段。 |
|
否 |
|
网络方向的输出字段。 |
|
是的 * |
内部网络列表。支持IPv4和IPv6地址以及CIDR表示法的范围。还支持以下命名的范围。这些可以通过模板片段构建。* 必须仅指定 |
|
|
否 |
从给定文档中读取 |
|
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
必须指定 internal_networks 或 internal_networks_field 中的一个。如果指定了 internal_networks_field,它将遵循 ignore_missing 指定的行为。
支持的命名网络范围
edit支持的internal_networks选项的命名范围有:
-
loopback- 匹配环回地址,范围为127.0.0.0/8或::1/128。 -
unicast或global_unicast- 匹配在 RFC 1122、RFC 4632 和 RFC 4291 中定义的全球单播地址,但不包括 IPv4 广播 地址 (255.255.255.255)。这包括私有地址范围。 -
multicast- 匹配多播地址。 -
interface_local_multicast- 匹配 IPv6 接口本地多播地址。 -
link_local_unicast- 匹配链路本地单播地址。 -
link_local_multicast- 匹配链路本地多播地址。 -
private- 匹配在 RFC 1918 (IPv4) 和 RFC 4193 (IPv6) 中定义的私有地址范围。 -
public- 匹配不是环回、未指定、IPv4 广播、链路本地单播、链路本地多播、接口本地 多播或私有的地址。 -
unspecified- 匹配未指定地址(IPv4 地址 "0.0.0.0" 或 IPv6 地址 "::")。
示例
edit以下示例说明了网络方向处理器的使用:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"network_direction": {
"internal_networks": ["private"]
}
}
]
},
"docs": [
{
"_source": {
"source": {
"ip": "128.232.110.120"
},
"destination": {
"ip": "192.168.1.1"
}
}
}
]
}
这将产生以下结果:
{
"docs": [
{
"doc": {
...
"_source": {
"destination": {
"ip": "192.168.1.1"
},
"source": {
"ip": "128.232.110.120"
},
"network": {
"direction": "inbound"
}
}
}
}
]
}
管道处理器
edit执行另一个管道。
{
"pipeline": {
"name": "inner-pipeline"
}
}
当前管道的名称可以从 _ingest.pipeline 摄取元数据键中访问。
使用此处理器进行嵌套管道的示例如下:
定义一个内部管道:
PUT _ingest/pipeline/pipelineA
{
"description" : "inner pipeline",
"processors" : [
{
"set" : {
"field": "inner_pipeline_set",
"value": "inner"
}
}
]
}
定义另一个使用之前定义的内部管道的管道:
PUT _ingest/pipeline/pipelineB
{
"description" : "outer pipeline",
"processors" : [
{
"pipeline" : {
"name": "pipelineA"
}
},
{
"set" : {
"field": "outer_pipeline_set",
"value": "outer"
}
}
]
}
现在在应用外部管道时索引文档将看到内部管道从外部管道执行:
PUT /my-index-000001/_doc/1?pipeline=pipelineB
{
"field": "value"
}
索引请求的响应:
{
"_index": "my-index-000001",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 66,
"_primary_term": 1
}
索引文档:
{
"field": "value",
"inner_pipeline_set": "inner",
"outer_pipeline_set": "outer"
}
编辑处理器
editRedact 处理器使用 Grok 规则引擎来模糊输入文档中匹配给定 Grok 模式的文本。该处理器可以通过配置来检测已知的模式,例如电子邮件或 IP 地址,从而模糊个人身份信息(PII)。匹配 Grok 模式的文本将被替换为可配置的字符串,例如
Elasticsearch 自带了许多有用的预定义 模式, 可以方便地被 Redact 处理器引用。 如果这些模式不符合您的需求,可以使用自定义模式定义创建一个新模式。Redact 处理器会替换每个匹配项。如果有多个匹配项,所有匹配项都将被替换为模式名称。
Redact 处理器与 Elastic Common Schema (ECS) 模式兼容。不支持传统的 Grok 模式。
在管道中使用Redact处理器
edit表34. 编辑选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
需要被编辑的字段 |
|
是 |
- |
用于匹配和隐藏命名捕获的grok表达式列表 |
|
否 |
- |
定义自定义模式的pattern-name和pattern元组的映射,处理器将使用这些自定义模式。匹配现有名称的模式将覆盖预先存在的定义 |
|
否 |
< |
使用此标记开始一个编辑部分 |
|
否 |
> |
以这个标记结束编辑部分 |
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
|
否 |
|
如果 |
|
否 |
|
如果 |
在这个示例中,预定义的 IP Grok 模式用于匹配并从 message 文本字段中删除 IP 地址。该管道使用 Simulate API 进行测试。
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description" : "Hide my IP",
"processors": [
{
"redact": {
"field": "message",
"patterns": ["%{IP:client}"]
}
}
]
},
"docs":[
{
"_source": {
"message": "55.3.244.1 GET /index.html 15824 0.043"
}
}
]
}
响应中的文档仍然包含message字段,但现在IP地址55.3.244.1被替换为文本
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"message": "<client> GET /index.html 15824 0.043"
},
"_ingest": {
"timestamp": "2023-02-01T16:08:39.419056008Z"
}
}
}
]
}
IP地址被替换为单词client,因为这是在Grok模式%{IP:client}中指定的。包围模式名称的<和>标记可以通过prefix和suffix选项进行配置。
下一个示例定义了多个模式,这两个模式都被替换为单词 REDACTED,并且前缀和后缀标记设置为 *
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "Hide my IP",
"processors": [
{
"redact": {
"field": "message",
"patterns": [
"%{IP:REDACTED}",
"%{EMAILADDRESS:REDACTED}"
],
"prefix": "*",
"suffix": "*"
}
}
]
},
"docs": [
{
"_source": {
"message": "55.3.244.1 GET /index.html 15824 0.043 test@elastic.co"
}
}
]
}
在响应中,IP地址55.3.244.1和电子邮件地址test@elastic.co
已被替换为*REDACTED*。
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"message": "*REDACTED* GET /index.html 15824 0.043 *REDACTED*"
},
"_ingest": {
"timestamp": "2023-02-01T16:53:14.560005377Z"
}
}
}
]
}
自定义模式
edit如果现有的 Grok 模式
不符合您的需求,可以使用
pattern_definitions 选项添加自定义模式。新模式的定义由
模式名称和模式本身组成。该模式可以是正则表达式或引用现有的 Grok 模式。
此示例定义了自定义模式 GITHUB_NAME 以匹配 GitHub 用户名。模式定义使用了现有的 USERNAME Grok 模式,并在其前缀加上字面量 @。
The Grok Debugger 是一个非常 有用的工具,用于构建自定义模式。
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"redact": {
"field": "message",
"patterns": [
"%{GITHUB_NAME:GITHUB_NAME}"
],
"pattern_definitions": {
"GITHUB_NAME": "@%{USERNAME}"
}
}
}
]
},
"docs": [
{
"_source": {
"message": "@elastic-data-management the PR is ready for review"
}
}
]
}
响应中的用户名已被屏蔽。
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_version": "-3",
"_source": {
"message": "<GITHUB_NAME> the PR is ready for review"
},
"_ingest": {
"timestamp": "2023-02-01T16:53:14.560005377Z"
}
}
}
]
}
许可
editThe redact processor 是一个需要适当许可证的商业功能。更多信息,请参考
https://www.elastic.co/subscriptions。
可以在 redact 处理器上设置 skip_if_unlicensed 选项,以控制当集群的许可证不足以运行此类处理器时的行为。skip_if_unlicensed 默认为 false,并且如果集群的许可证不足,redact 处理器将抛出异常。但是,如果您将 skip_if_unlicensed 选项设置为 true,那么在许可证不足的情况下,redact 处理器将不会抛出异常(它将完全不执行任何操作)。
注册域处理器
edit从完全限定域名(FQDN)中提取注册域(也称为有效顶级域或eTLD)、子域和顶级域。使用Mozilla Public Suffix List中定义的注册域。
表35. 注册域名选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
包含源完全限定域名(FQDN)的字段。 |
|
|
否 |
|
包含提取的域组件的对象字段。如果是一个 |
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
示例
edit以下示例说明了注册域处理器的使用:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"registered_domain": {
"field": "fqdn",
"target_field": "url"
}
}
]
},
"docs": [
{
"_source": {
"fqdn": "www.example.ac.uk"
}
}
]
}
这将产生以下结果:
{
"docs": [
{
"doc": {
...
"_source": {
"fqdn": "www.example.ac.uk",
"url": {
"subdomain": "www",
"registered_domain": "example.ac.uk",
"top_level_domain": "ac.uk",
"domain": "www.example.ac.uk"
}
}
}
}
]
}
移除处理器
edit移除现有字段。如果一个字段不存在,将抛出异常。
这是一个删除单个字段的示例:
{
"remove": {
"field": "user_agent"
}
}
要删除多个字段,可以使用以下查询:
{
"remove": {
"field": ["user_agent", "url"]
}
}
您也可以选择移除除指定列表外的所有字段:
{
"remove": {
"keep": ["url"]
}
}
重命名处理器
edit重命名现有字段。如果该字段不存在或新名称已被使用,将抛出异常。
表37. 重命名选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要重命名的字段。支持 模板片段。 |
|
是 |
- |
字段的新名称。支持 模板片段。 |
|
否 |
|
如果 |
|
否 |
|
如果设置为 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
{
"rename": {
"field": "provider",
"target_field": "cloud.provider"
}
}
重路由处理器
editThe reroute 处理器允许将文档路由到另一个目标索引或数据流。
它有两种主要模式:
当设置destination选项时,目标被明确指定,并且不能设置dataset和namespace选项。
当未设置destination选项时,此处理器处于数据流模式。
请注意,在此模式下,reroute处理器只能用于遵循数据流命名方案的数据流。
尝试在不符合命名方案的数据流上使用此处理器将引发异常。
数据流的名称由三个部分组成:
此处理器可以使用静态值或引用文档中的字段来确定新目标的dataset和namespace组件。
有关更多详细信息,请参见表38,“Reroute选项”。
无法使用 reroute 处理器更改数据流的 type。
在执行了reroute处理器之后,当前管道中的所有其他处理器(包括最终管道)都会被跳过。
如果当前管道是在Pipeline的上下文中执行的,调用管道也会被跳过。
这意味着在一个管道中最多只会执行一个reroute处理器,
允许定义互斥的路由条件,
类似于if、else-if、else-if、…条件。
重定向处理器确保根据新目标设置 data_stream. 字段。
如果文档包含 event.dataset 值,它将被更新以反映与 data_stream.dataset 相同的值。
请注意,客户端需要对最终目标具有权限。 否则,文档将被拒绝,并出现如下所示的安全异常:
{"type":"security_exception","reason":"action [indices:admin/auto_create] is unauthorized for API key id [8-dt9H8BqGblnY2uSI--] of user [elastic/fleet-server] on indices [logs-foo-default], this action is granted by the index privileges [auto_configure,create_index,manage,all]"}
表38. 重路由选项
| Name | Required | Default | Description |
|---|---|---|---|
|
否 |
- |
目标的静态值。当设置了 |
|
否 |
|
数据流名称中数据集部分的字段引用或静态值。除了索引名称的标准外,不能包含 支持使用类似 mustache 语法(表示为 |
|
否 |
|
数据流名称的命名空间部分的字段引用或静态值。请参阅索引名称的允许字符标准。长度不得超过100个字符。 支持使用类似 mustache 语法(表示为 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
可以使用 if 选项来定义文档应在何种条件下被重定向到新的目标。
{
"reroute": {
"tag": "nginx",
"if" : "ctx?.log?.file?.path?.contains('nginx')",
"dataset": "nginx"
}
}
数据集和命名空间选项可以包含单个值或作为回退的值列表。
如果字段引用计算为null,或者在文档中不存在,则使用下一个值或字段引用。
如果字段引用计算为非String值,处理器将失败。
在以下示例中,处理器会首先尝试解析service.name字段的值,以确定dataset的值。
如果该字段解析为null、缺失或为非字符串值,它将尝试列表中的下一个元素。
在这种情况下,这是静态值"generic。
namespace选项配置为仅包含一个静态值。
{
"reroute": {
"dataset": [
"{{service.name}}",
"generic"
],
"namespace": "default"
}
}
脚本处理器
edit对传入的文档运行内联或存储的脚本。该脚本在ingest上下文中运行。
脚本处理器使用脚本缓存来避免对每个传入文档重新编译脚本。为了提高性能,在使用脚本处理器之前,请确保脚本缓存的大小适当。
访问源字段
edit脚本处理器将每个传入文档的JSON源字段解析为一组映射、列表和基本类型。要使用Painless脚本访问这些字段,请使用映射访问操作符:ctx['my-field']。您也可以使用简写语法ctx.。
脚本处理器不支持 ctx['_source']['my-field'] 或
ctx._source. 语法。
以下处理器使用 Painless 脚本来从 env 源字段中提取 tags 字段。
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"script": {
"description": "Extract 'tags' from 'env' field",
"lang": "painless",
"source": """
String[] envSplit = ctx['env'].splitOnToken(params['delimiter']);
ArrayList tags = new ArrayList();
tags.add(envSplit[params['position']].trim());
ctx['tags'] = tags;
""",
"params": {
"delimiter": "-",
"position": 1
}
}
}
]
},
"docs": [
{
"_source": {
"env": "es01-prod"
}
}
]
}
处理器生成:
{
"docs": [
{
"doc": {
...
"_source": {
"env": "es01-prod",
"tags": [
"prod"
]
}
}
}
]
}
访问元数据字段
edit您还可以使用脚本处理器来访问元数据字段。以下处理器使用Painless脚本来设置传入文档的_index。
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"script": {
"description": "Set index based on `lang` field and `dataset` param",
"lang": "painless",
"source": """
ctx['_index'] = ctx['lang'] + '-' + params['dataset'];
""",
"params": {
"dataset": "catalog"
}
}
}
]
},
"docs": [
{
"_index": "generic-index",
"_source": {
"lang": "fr"
}
}
]
}
处理器将文档的_index从generic-index更改为fr-catalog。
{
"docs": [
{
"doc": {
...
"_index": "fr-catalog",
"_source": {
"lang": "fr"
}
}
}
]
}
设置处理器
edit设置一个字段并将其与指定值关联。如果该字段已存在,其值将被替换为提供的值。
表40. 设置选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要插入、更新或更新的字段。支持 模板片段。 |
|
是的* |
- |
要为字段设置的值。支持 模板片段。只能指定 |
|
否 |
- |
将被复制到 |
|
否 |
|
如果设置为 |
|
否 |
|
如果 |
|
否 |
|
用于编码 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
{
"description" : "sets the value of count to 1",
"set": {
"field": "count",
"value": 1
}
}
此处理器还可用于将数据从一个字段复制到另一个字段。例如:
PUT _ingest/pipeline/set_os
{
"description": "sets the value of host.os.name from the field os",
"processors": [
{
"set": {
"field": "host.os.name",
"value": "{{{os}}}"
}
}
]
}
POST _ingest/pipeline/set_os/_simulate
{
"docs": [
{
"_source": {
"os": "Ubuntu"
}
}
]
}
结果:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_id" : "_id",
"_version" : "-3",
"_source" : {
"host" : {
"os" : {
"name" : "Ubuntu"
}
},
"os" : "Ubuntu"
},
"_ingest" : {
"timestamp" : "2019-03-11T21:54:37.909224Z"
}
}
}
]
}
此处理器也可以使用点表示法访问数组字段:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"set": {
"field": "my_field",
"value": "{{{input_field.1}}}"
}
}
]
},
"docs": [
{
"_index": "index",
"_id": "id",
"_source": {
"input_field": [
"Ubuntu",
"Windows",
"Ventura"
]
}
}
]
}
结果:
{
"docs": [
{
"doc": {
"_index": "index",
"_id": "id",
"_version": "-3",
"_source": {
"input_field": [
"Ubuntu",
"Windows",
"Ventura"
],
"my_field": "Windows"
},
"_ingest": {
"timestamp": "2023-05-05T16:04:16.456475214Z"
}
}
}
]
}
可以使用 copy_from 将包含数组和对象等复杂值的字段内容复制到另一个字段:
PUT _ingest/pipeline/set_bar
{
"description": "sets the value of bar from the field foo",
"processors": [
{
"set": {
"field": "bar",
"copy_from": "foo"
}
}
]
}
POST _ingest/pipeline/set_bar/_simulate
{
"docs": [
{
"_source": {
"foo": ["foo1", "foo2"]
}
}
]
}
结果:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_id" : "_id",
"_version" : "-3",
"_source" : {
"bar": ["foo1", "foo2"],
"foo": ["foo1", "foo2"]
},
"_ingest" : {
"timestamp" : "2020-09-30T12:55:17.742795Z"
}
}
}
]
}
设置安全用户处理器
edit设置与用户相关的详细信息(例如 username、roles、email、full_name、
metadata、api_key、realm 和 authentication_type),通过预处理摄取将当前
经过身份验证的用户信息设置到当前文档中。
api_key 属性仅在用户使用 API 密钥进行身份验证时存在。它是一个包含 id、name 和 metadata
(如果存在且非空)字段的对象。
realm 属性也是一个包含两个字段 name 和 type 的对象。
当使用 API 密钥身份验证时,realm 属性指的是创建 API 密钥的领域。
authentication_type 属性是一个字符串,其值可以是
REALM、API_KEY、TOKEN 和 ANONYMOUS。
需要为索引请求进行身份验证的用户。
表41. 设置安全用户选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
用于存储用户信息的字段。 |
|
否 |
[ |
控制哪些用户相关属性被添加到 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
以下示例将当前已认证用户的所有用户详细信息添加到此管道处理的所有文档的 user 字段中:
{
"processors" : [
{
"set_security_user": {
"field": "user"
}
}
]
}
排序处理器
edit对数组的元素进行升序或降序排序。数值的同质数组将按数值排序,而字符串数组或字符串与数值的异质数组将按字典顺序排序。当字段不是数组时,会抛出错误。
{
"sort": {
"field": "array_field_to_sort",
"order": "desc"
}
}
分割处理器
edit使用分隔符字符将字段拆分为数组。仅适用于字符串字段。
表43. 分割选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
要分割的字段 |
|
是 |
- |
匹配分隔符的正则表达式,例如 |
|
否 |
|
要分配分割值的字段,默认情况下 |
|
否 |
|
如果 |
|
否 |
|
保留任何空的后缀字段。 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
如果启用了 preserve_trailing 选项,输入中的任何尾随空字段都将被保留。例如,在下面的配置中,my_field 属性中的值 A,,B,, 将被拆分为一个包含五个元素的数组 ["A", "", "B", "", ""],其中包含两个空尾随字段。如果未启用 preserve_trailing 属性,则两个空尾随字段将被丢弃,结果是包含三个元素的数组 ["A", "", "B"]。
{
"split": {
"field": "my_field",
"separator": ",",
"preserve_trailing": true
}
}
终止处理器
edit终止当前的摄取管道,导致不再运行更多的处理器。
这通常会使用if选项有条件地执行。
如果此管道是从另一个管道调用的,调用管道不会终止。
{
"description" : "terminates the current pipeline if the error field is present",
"terminate": {
"if": "ctx.error != null"
}
}
修剪处理器
edit去除字段中的空白。如果字段是字符串数组,则数组的所有成员都将被去除空白。
这仅适用于前导和尾随空白。
{
"trim": {
"field": "foo"
}
}
URL解码处理器
edit对字符串进行URL解码。如果该字段是字符串数组,则数组中的所有成员都将被解码。
{
"urldecode": {
"field": "my_url_to_decode"
}
}
URI 部分处理器
edit解析一个统一资源标识符(URI)字符串,并将其组件提取为一个对象。这个URI对象包括URI的域、路径、片段、端口、查询、方案、用户信息、用户名和密码的属性。
表48. URI部分选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
包含URI字符串的字段。 |
|
否 |
|
URI对象的输出字段。 |
|
否 |
真 |
如果为 |
|
否 |
假 |
如果 |
|
否 |
|
如果 |
|
否 |
- |
处理器的描述。用于描述处理器的用途或其配置。 |
|
否 |
- |
有条件地执行处理器。参见有条件地运行处理器。 |
|
否 |
|
忽略处理器的失败。参见处理管道失败。 |
|
否 |
- |
处理器的失败处理。参见处理管道失败。 |
|
否 |
- |
处理器的标识符。对调试和指标很有用。 |
以下是URI部分处理器的示例定义:
{
"description" : "...",
"processors" : [
{
"uri_parts": {
"field": "input_field",
"target_field": "url",
"keep_original": true,
"remove_if_successful": false
}
}
]
}
当上述处理器在以下文档上执行时:
{
"_source": {
"input_field": "http://myusername:mypassword@www.example.com:80/foo.gif?key1=val1&key2=val2#fragment"
}
}
它产生以下结果:
"_source" : {
"input_field" : "http://myusername:mypassword@www.example.com:80/foo.gif?key1=val1&key2=val2#fragment",
"url" : {
"path" : "/foo.gif",
"fragment" : "fragment",
"extension" : "gif",
"password" : "mypassword",
"original" : "http://myusername:mypassword@www.example.com:80/foo.gif?key1=val1&key2=val2#fragment",
"scheme" : "http",
"port" : 80,
"user_info" : "myusername:mypassword",
"domain" : "www.example.com",
"query" : "key1=val1&key2=val2",
"username" : "myusername"
}
}
用户代理处理器
editThe user_agent processor extracts details from the user agent string a browser sends with its web requests.
This processor adds this information by default under the user_agent field.
ingest-user-agent 模块默认附带了由 uap-java 提供的 regexes.yaml,该文件采用 Apache 2.0 许可证。更多详情请参见 https://github.com/ua-parser/uap-core。
在管道中使用 user_agent 处理器
edit表49. 用户代理选项
| Name | Required | Default | Description |
|---|---|---|---|
|
是 |
- |
包含用户代理字符串的字段。 |
|
否 |
用户代理 |
将填充用户代理详细信息的字段。 |
|
否 |
- |
包含用于解析用户代理字符串的正则表达式的文件在 |
|
否 |
[ |
控制哪些属性被添加到 |
|
否 |
|
[测试版] 此功能处于测试阶段,可能会发生变化。设计和代码不如正式发布的功能成熟,并且是按原样提供的,不提供任何保证。测试版功能不受正式发布功能的SLA支持。 尽最大努力从用户代理字符串中提取设备类型。 |
|
否 |
|
如果 |
这里是一个示例,根据agent字段将用户代理详细信息添加到user_agent字段中:
PUT _ingest/pipeline/user_agent
{
"description" : "Add user agent information",
"processors" : [
{
"user_agent" : {
"field" : "agent"
}
}
]
}
PUT my-index-000001/_doc/my_id?pipeline=user_agent
{
"agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
}
GET my-index-000001/_doc/my_id
返回的是
{
"found": true,
"_index": "my-index-000001",
"_id": "my_id",
"_version": 1,
"_seq_no": 22,
"_primary_term": 1,
"_source": {
"agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"user_agent": {
"name": "Chrome",
"original": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"version": "51.0.2704.103",
"os": {
"name": "Mac OS X",
"version": "10.10.5",
"full": "Mac OS X 10.10.5"
},
"device" : {
"name" : "Mac"
}
}
}
}
使用自定义正则表达式文件
edit要使用自定义的正则表达式文件来解析用户代理,该文件必须放置在 config/ingest-user-agent 目录中,并且必须具有 .yml 文件扩展名。该文件必须在节点启动时存在,任何在节点运行时对其进行的更改或添加的新文件都不会产生任何效果。
在实践中,任何自定义的正则表达式文件最合理的情况是作为默认文件的变体,无论是更新的版本还是定制的版本。
默认包含在 ingest-user-agent 中的文件是来自 uap-core 的 regexes.yaml:https://github.com/ua-parser/uap-core/blob/master/regexes.yaml
节点设置
editThe user_agent 处理器支持以下设置:
-
ingest.user_agent.cache_size -
应缓存的最大结果数。默认为
1000。
请注意,这些设置是节点设置,适用于所有user_agent处理器,即所有定义的user_agent处理器共享一个缓存。