Faiss
Faiss 是一个高效处理稠密向量(dense vectors)相似性搜索(similarity search)和聚类(clustering)的开源库。无论数据量有多大,即使全部数据无法装入内存(RAM),Faiss 都能高效处理。Faiss 还包含评估方法和参数调优的辅助代码。主要以 C++ 编写,同时为 Python(2和3)提供完整的接口封装。其中部分核心算法也实现了 GPU 加速。Faiss 主要由 Meta AI Research 维护,并有外部 贡献者参与开发。
什么是相似性搜索(similarity search)?
假设有一组 维向量 ,Faiss 会在内存中构建一个数据结构。当你有新的 维向量 时,可以高效地执行如下操作:
这里的 表示欧氏距离(欧几里得距离,L2 距离)。
在 Faiss 的术语中,这个数据结构叫做 索引(index),它是一个能通过 add 方法添加 向量的对象。注意:所有 的维度必须固定。
寻找 使距离最小的操作称为搜索(search)。
这就是 Faiss 的核心功能。此外,Faiss 还可以:
- 查询最近邻的同时返回第 2、3、...、第 k 个最近邻(即 top-k 搜索)
- 一次处理多个查询向量(批量处理 batch processing),很多索引类型下同时处理多条查询比逐条更快
- 可以精度和速度进行权衡,比如只正确返回 90% 的结果,却能提速 10 倍或减少 10 倍内存占用
- 支持最大内积搜索(maximum inner product search),即寻找
$\mathrm{argmax}_i\langle x, x_i \rangle$,即最大点积的索引结果。此外还有限度地支持其他距离类型,比如 L1、L∞ 等 - 支持范围搜索(range search),即返回所有在给定查询半径内的样本
- 支持索引持久化到磁盘,而不仅仅放在内存
- 支持二进制向量(binary vectors)而不仅仅是浮点向量(float vectors)
- 支持通过向量 id 的条件忽略部分向量
Faiss 的许多操作都支持批量处理,多向量同时搜索可以极大提升效率。
Faiss 的研究基础
Faiss 基于多年的学术研究,最著名的核心实现包括:
-
倒排文件(inverted file),参考 “Video google: A text retrieval approach to object matching in videos.”,Sivic & Zisserman, ICCV 2003。这是大规模数据集下高效非穷举搜索的关键,否则只能遍历全部向量,哪怕每次操作很快,总体耗时仍难以承受。
-
乘积量化(Product Quantization, PQ)方法,参考 “Product quantization for nearest neighbor search”,Jégou 等, PAMI 2011。PQ 是一种高维向量有损压缩技术,在压缩域中可以近似还原和距离计算。
-
三层量化(Three-level quantization,IVFADC-R aka
IndexIVFPQR),参考 "Searching in one billion vectors: re-rank with source coding",Tavenard 等, ICASSP'11。 -
倒排多重索引(inverted multi-index),参考 “The inverted multi-index”,Babenko & Lempitsky, CVPR 2012。该方法极大提升了倒排索引在快速、低精度设置下的速度。
-
优化乘积量化(Optimized PQ),参考 “Optimized product quantization”,He 等, CVPR 2013。可以看作对向量空间的线性变换,使其更适合用 PQ 做索引。
-
量化距离预过滤(Pre-filtering of product quantizer distances),参考 “Polysemous codes”,Douze 等, ECCV 2016。该技术在计算 PQ 距离前做二值过滤,提高效率。
-
GPU 实现与快速 k 选择(fast k-selection),参考 “Billion-scale similarity search with GPUs”,Johnson 等, ArXiv 1702.08734, 2017。
-
HNSW 层次小世界图索引(Hierarchical Navigable Small World)方法,参考 "Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs",Malkov 等, ArXiv 1603.09320, 2016。
-
寄存器内矢量比较(in-register vector comparisons),参考 "Quicker ADC : Unlocking the Hidden Potential of Product Quantization with SIMD",André 等, PAMI'19,以及 "Accelerating Large-Scale Inference with Anisotropic Vector Quantization",Guo, Sun 等, ICML'20。
-
二进制多重索引哈希(Binary multi-index hashing),参考 "Fast Search in Hamming Space with Multi-Index Hashing",Norouzi 等, CVPR’12。
-
基于图的 NSG 索引(graph-based indexing, NSG),参考 "Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Graph",Cong Fu 等, VLDB 2019。
-
局部搜索量化(Local search quantization),参考 "Revisiting additive quantization", Julieta Martinez 等, ECCV 2016;以及 "LSQ++: Lower running time and higher recall in multi-codebook quantization", Julieta Martinez 等, ECCV 2018。
-
残差量化器实现(Residual quantizer),参考 "Improved Residual Vector Quantization for High-dimensional Approximate Nearest Neighbor Search",Shicong Liu 等, AAAI'15。
有一篇关于乘积量化和相关方法的综述论文推荐阅读:"A Survey of Product Quantization",Yusuke Matsui, Yusuke Uchida, Hervé Jégou, Shin’ichi Satoh, ITE transactions on MTA, 2018。
下图来自上述论文,直观体现了各类 PQ 变体(点击图片可放大查看):
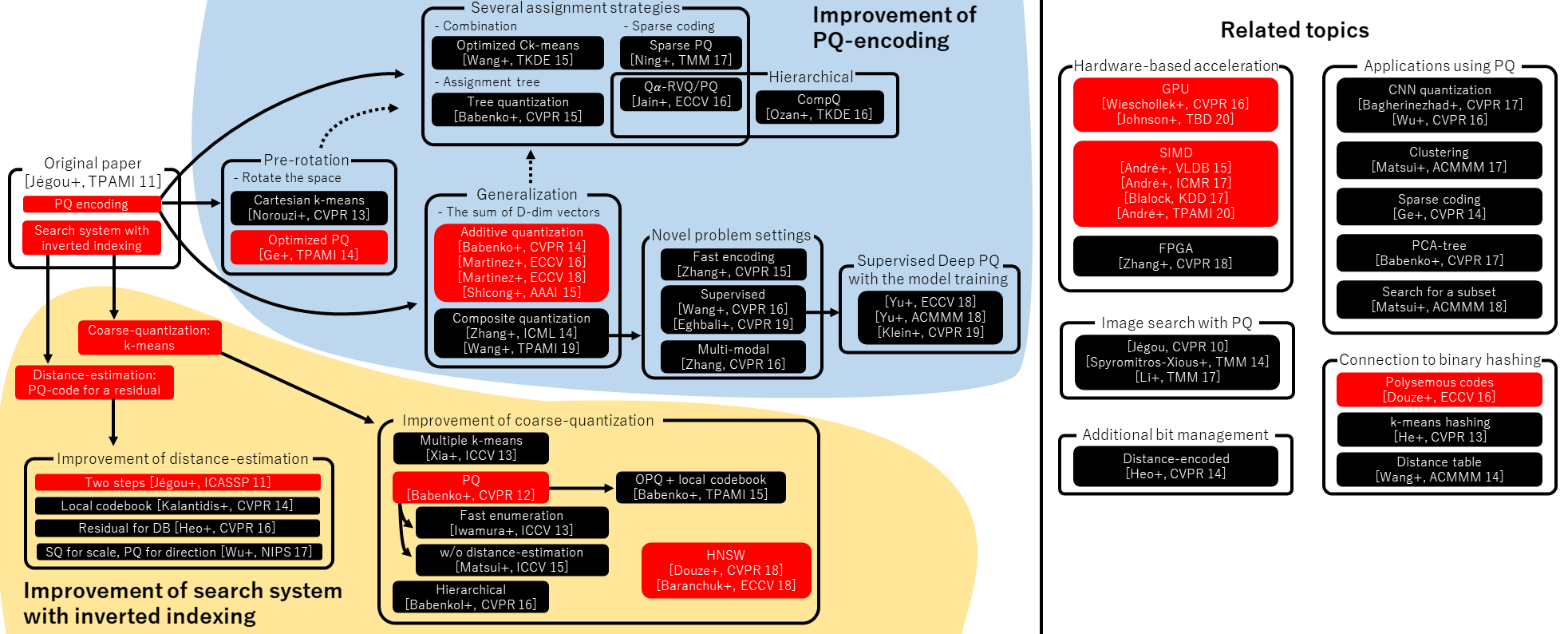
2021-08-19 注:图中红框标注为 Faiss 已实现的方法(另外添加了 SIMD 选项和加法量化方法)。
参考文献索引说明
André+, “Cache Locality is not Enough: High-performance Nearest Neighbor Search with Product Quantization Fast Scan”, VLDB 15
André+, “Accelerated Nearest Neighbor Search with Quick ADC”, ICMR 17
André+, “Quicker ADC : Unlocking the Hidden Potential of Product Quantization with SIMD”, IEEE TPAMI 20
Babenko and Lempitsky, “The Inverted Multi-index”, CVPR 12
Babenko and Lempitsky, “Additive Quantization for Extreme Vector Compression”, CVPR 14
Babenko and Lempitsky, “The Inverted Multi-index”, IEEE TPAMI 15
Babenko and Lempitsky, “Tree Quantization for Large-scale Similarity Search and Classification”, CVPR 15
Babenko and Lempitsky, “Efficient Indexing of Billion-scale Datasets of Deep Descriptors”, CVPR 16
Babenko and Lempitsky, “Product Split Trees”, CVPR 17
Bagherinezhad+, “LCNN: Lookup-based Convolutional Neural Network”, CVPR 17
Baranchuk+, “Revisiting the Inverted Indices for Billion-Scale Approximate Nearest Neighbors”, ECCV 18
Blalock and Guttag, “Bolt: Accelerated Data Mining with Fast Vector Compression”, KDD 17
Eghbali and Tahvildari, “Deep Spherical Quantization for Image Search”, CVPR 19
Douze+, “Polysemous Codes”, ECCV 16
Douze+, “Link and code: Fast Indexing with Graphs and Compact Regression Codes”, CVPR 18
Ge+, “Optimized Product Quantization”, IEEE TPAMI 14
Ge+, “Product Sparse Coding”, CVPR 14
He+, “K-means Hashing: An Affinity-preserving Quantization Method for Learning Binary Compact Codes”, CVPR 13
Heo+, “Short-list Selection with Residual-aware Distance Estimator for K-nearest Neighbor Search”, CVPR 16
Heo+, “Distance Encoded Product Quantization”, CVPR 14
Iwamura+, “What is the Most Efficient Way to Select Nearest Neighbor Candidates for Fast Approximate Nearest Neighbor Search?”, ICCV 13
Jain+, “Approximate Search with Quantized Sparse Representations”, ECCV 16
Jégou+, “Product Quantization for Nearest Neighbor Search”, IEEE TPAMI 11
Jégou+, “Aggregating Local Descriptors into a Compact Image Representation”, CVPR 10
Jégou+, “Searching in One Billion Vectors: Re-rank with Source Coding”, ICASSP 11
Johnson+, “Billion-scale Similarity Search with GPUs”, IEEE TBD 20
Klein and Wolf, “End-to-end Supervised Product Quantization for Image Search and Retrieval”, CVPR 19
Kalantidis and Avrithis, “Locally Optimized Product Quantization for Approximate Nearest Neighbor Search”, CVPR 14
Li+, “Online Variable Coding Length Product Quantization for Fast Nearest Neighbor Search in Mobile Retrieval”, IEEE TMM 17
Martinez+, “Revisiting Additive Quantization”, ECCV 16
Martinez+, “LSQ++: Lower Running Time and Higher Recall in Multi-codebook Quantization”, ECCV 18
Matsui+, “PQTable: Fast Exact Asymmetric Distance Neighbor Search for Product Quantization using Hash Tables”, ICCV 15
Matsui+, “PQk-means: Billion-scale Clustering for Product-quantized Codes”, ACMMM 17
Matsui+, “Reconfigurable Inverted Index”, ACMMM 18
Ning+, “Scalable Image Retrieval by Sparse Product Quantization”, IEEE TMM 17
Norouzi and Fleet, “Cartesian k-means”, CVPR 13
Ozan+, “Competitive Quantization for Approximate Nearest Neighbor Search”, IEEE TKDE 16
Shicong+, “Improved Residual Vector Quantization for High-dimensional Approximate Nearest Neighbor Search”, AAAI 15
Spyromitros-Xious+, “A Comprehensive Study over VLAD and Product Quantization in Large-scale Image Retrieval”, IEEE TMM 14
Yu+, “Product Quantization Network for Fast Image Retrieval”, ECCV 18
Yu+, “Generative Adversarial Product Quantization”, ACMMM 18
Wang+, “Optimized Distances for Binary Code Ranking”, ACMMM 14
Wang+, “Optimized Cartesian k-means”, IEEE TKDE 15
Wang+, “Supervised Quantization for Similarity Search”, CVPR 16
Wang and Zhang, “Composite Quantization”, IEEE TPAMI 19
Wieschollek+, “Efficient Large-scale Approximate Nearest Neighbor Search on the GPU”, CVPR 16
Wu+, “Multiscale Quantization for Fast Similarity Search”, NIPS 17
Wu+, “Quantized Convolutional Neural Networks for Mobile Devices”, CVPR 16
Xia+, “Joint Inverted Indexing”, ICCV 13
Zhang+, “Composite Quantization for Approximate Nearest Neighbor Search”, ICML 14
Zhang+, “Sparse Composite Quantization”, CVPR 15.
Zhang+, “Collaborative Quantization for Crossmodal Similarity Search”, CVPR 16
Zhang+, “Efficient Large-scale Approximate Nearest Neighbor Search on OpenCL FPGA”, CVPR 18
图片来源:Yusuke Matsui,特别感谢其授权使用!
本 Wiki 说明
本 Wiki 提供了 Faiss 的高层次信息和教程内容。可通过侧边栏导航浏览。
大部分示例以 Python 呈现(简洁明了),但 C++ 接口基本相同,二者相互转换非常容易。
如果需要基于 C++ 的使用实例,可参考 Python 示例并直接在 C++ 代码中实现,API 设计高度一致。