常见问题
支持矩阵
混合集群支持
它支持混合部署Linux、Windows和macOS节点,以及x86_64和arm64架构。此外,还支持多种GPU,包括NVIDIA、Apple Metal、AMD、昇腾、海光和摩尔线程。
分布式推理支持
单节点多GPU
- llama-box(不支持图像生成模型)
- vLLM
- MindIE
- vox-box
多节点多GPU
- llama-box
- vLLM
- MindIE
异构节点多GPU
- llama-box
安装
如何更改GPUStack的默认端口?
默认情况下,GPUStack服务器使用80端口。您可以通过以下方法修改端口:
脚本安装
- Linux
sudo vim /etc/systemd/system/gpustack.service
添加 --port 参数:
ExecStart=/root/.local/bin/gpustack start --port 9090
保存并重启GPUStack:
sudo systemctl daemon-reload && sudo systemctl restart gpustack
- macOS
sudo launchctl bootout system /Library/LaunchDaemons/ai.gpustack.plist
sudo vim /Library/LaunchDaemons/ai.gpustack.plist
添加 --port 参数:
<array>
<string>/Users/gpustack/.local/bin/gpustack</string>
<string>start</string>
<string>--port</string>
<string>9090</string>
</array>
保存并启动GPUStack:
sudo launchctl bootstrap system /Library/LaunchDaemons/ai.gpustack.plist
- Windows
nssm edit GPUStack
在 start 后添加参数:
start --port 9090
保存并重启GPUStack:
Restart-Service -Name "GPUStack"
Docker安装
在docker run命令末尾添加--port参数,如下所示:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack \
--port 9090
如果不使用主机网络,只需修改映射的主机端口:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
-p 9090:80 \
-p 10150:10150 \
-p 40064-40131:40064-40131 \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack \
--worker-ip your_host_ip
pip 安装
在gpustack start命令末尾添加--port参数:
gpustack start --port 9090
如何更改已注册的工作节点名称?
在运行GPUStack时,您可以使用--worker-name参数设置自定义名称:
脚本安装
- Linux
sudo vim /etc/systemd/system/gpustack.service
添加 --worker-name 参数:
ExecStart=/root/.local/bin/gpustack start --worker-name New-Name
保存并重启GPUStack:
sudo systemctl daemon-reload && sudo systemctl restart gpustack
- macOS
sudo launchctl bootout system /Library/LaunchDaemons/ai.gpustack.plist
sudo vim /Library/LaunchDaemons/ai.gpustack.plist
添加 --worker-name 参数:
<array>
<string>/Users/gpustack/.local/bin/gpustack</string>
<string>start</string>
<string>--worker-name</string>
<string>New-Name</string>
</array>
保存并启动GPUStack:
sudo launchctl bootstrap system /Library/LaunchDaemons/ai.gpustack.plist
- Windows
nssm edit GPUStack
在 start 后添加参数:
start --worker-name New-Name
保存并重启GPUStack:
Restart-Service -Name "GPUStack"
Docker安装
在docker run命令的末尾添加--worker-name参数,如下所示:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack \
--worker-name New-Name
pip安装指南
在gpustack start命令末尾添加--worker-name参数:
gpustack start --worker-name New-Name
如何更改已注册工作节点的IP地址?
您可以在运行GPUStack时使用--worker-ip参数将其设置为自定义IP:
脚本安装
- Linux
sudo vim /etc/systemd/system/gpustack.service
添加 --worker-ip 参数:
ExecStart=/root/.local/bin/gpustack start --worker-ip xx.xx.xx.xx
保存并重启GPUStack:
sudo systemctl daemon-reload && sudo systemctl restart gpustack
- macOS
sudo launchctl bootout system /Library/LaunchDaemons/ai.gpustack.plist
sudo vim /Library/LaunchDaemons/ai.gpustack.plist
添加 --worker-ip 参数:
<array>
<string>/Users/gpustack/.local/bin/gpustack</string>
<string>start</string>
<string>--worker-ip</string>
<string>xx.xx.xx.xx</string>
</array>
保存并启动GPUStack:
sudo launchctl bootstrap system /Library/LaunchDaemons/ai.gpustack.plist
- Windows
nssm edit GPUStack
在 start 后添加参数:
start --worker-ip xx.xx.xx.xx
保存并重启GPUStack:
Restart-Service -Name "GPUStack"
Docker安装
在docker run命令末尾添加--worker-ip参数,如下所示:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack \
--worker-ip xx.xx.xx.xx
pip 安装
在 gpustack start 命令末尾添加 --worker-ip 参数:
gpustack start --worker-ip xx.xx.xx.xx
GPUStack的数据存储在哪里?
脚本安装
- Linux
默认路径如下:
/var/lib/gpustack
在运行GPUStack时,您可以使用--data-dir参数将其设置为自定义路径:
sudo vim /etc/systemd/system/gpustack.service
添加 --data-dir 参数:
ExecStart=/root/.local/bin/gpustack start --data-dir /data/gpustack-data
保存并重启GPUStack:
sudo systemctl daemon-reload && sudo systemctl restart gpustack
- macOS
默认路径如下:
/var/lib/gpustack
在运行GPUStack时,您可以使用--data-dir参数将其设置为自定义路径:
sudo launchctl bootout system /Library/LaunchDaemons/ai.gpustack.plist
sudo vim /Library/LaunchDaemons/ai.gpustack.plist
<array>
<string>/Users/gpustack/.local/bin/gpustack</string>
<string>start</string>
<string>--data-dir</string>
<string>/Users/gpustack/data/gpustack-data</string>
</array>
保存并启动GPUStack:
sudo launchctl bootstrap system /Library/LaunchDaemons/ai.gpustack.plist
- Windows
默认路径如下:
"$env:APPDATA\gpustack"
在运行GPUStack时,您可以通过--data-dir参数将其设置为自定义路径:
nssm edit GPUStack
在 start 后添加参数:
start --data-dir D:\gpustack-data
保存并重启GPUStack:
Restart-Service -Name "GPUStack"
Docker安装
在运行GPUStack容器时,Docker卷通过-v参数挂载。默认数据路径位于Docker数据目录下,具体是在volumes子目录中,默认路径为:
/var/lib/docker/volumes/gpustack-data/_data
您可以通过以下方法进行检查:
docker volume ls
docker volume inspect gpustack-data
如果需要修改为自定义路径,请在运行容器时调整挂载配置。例如,将主机目录/data/gpustack挂载到容器中:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v /data/gpustack:/var/lib/gpustack \
gpustack/gpustack
pip安装指南
在 gpustack start 命令末尾添加 --data-dir 参数:
gpustack start --data-dir /data/gpustack-data
模型文件存储在哪里?
脚本安装
- Linux
默认路径如下:
/var/lib/gpustack/cache
在运行GPUStack时,您可以通过--cache-dir参数将其设置为自定义路径:
sudo vim /etc/systemd/system/gpustack.service
添加 --cache-dir 参数:
ExecStart=/root/.local/bin/gpustack start --cache-dir /data/model-cache
保存并重启GPUStack:
sudo systemctl daemon-reload && sudo systemctl restart gpustack
- macOS
默认路径如下:
/var/lib/gpustack/cache
在运行GPUStack时,您可以通过--cache-dir参数将其设置为自定义路径:
sudo launchctl bootout system /Library/LaunchDaemons/ai.gpustack.plist
sudo vim /Library/LaunchDaemons/ai.gpustack.plist
<array>
<string>/Users/gpustack/.local/bin/gpustack</string>
<string>start</string>
<string>--cache-dir</string>
<string>/Users/gpustack/data/model-cache</string>
</array>
保存并启动GPUStack:
sudo launchctl bootstrap system /Library/LaunchDaemons/ai.gpustack.plist
- Windows
默认路径如下:
"$env:APPDATA\gpustack\cache"
您可以在运行GPUStack时使用--cache-dir参数将其设置为自定义路径:
nssm edit GPUStack
在 start 后添加参数:
start --cache-dir D:\model-cache
保存并重启GPUStack:
Restart-Service -Name "GPUStack"
Docker安装
在运行GPUStack容器时,Docker卷通过-v参数挂载。默认缓存路径位于Docker数据目录下,具体是在volumes子目录中,默认路径为:
/var/lib/docker/volumes/gpustack-data/_data/cache
您可以通过以下方法进行检查:
docker volume ls
docker volume inspect gpustack-data
如果需要更改为自定义路径,请在运行容器时修改挂载配置。
注意:如果数据目录已挂载,则不应将缓存目录挂载在数据目录内。您需要使用
--cache-dir参数指定不同的路径。
例如,要挂载主机目录 /data/model-cache:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v /data/gpustack:/var/lib/gpustack \
-v /data/model-cache:/data/model-cache \
gpustack/gpustack \
--cache-dir /data/model-cache
pip安装指南
在gpustack start命令末尾添加--cache-dir参数:
gpustack start --cache-dir /data/model-cache
启动GPUStack时可以设置哪些参数?
请参考:gpustack start
升级
如何升级内置的vLLM?
GPUStack支持多种推理后端版本。在部署模型时,您可以在Edit Model → Advanced → Backend Version中指定后端版本,以使用新发布的vLLM版本。GPUStack将自动通过pipx创建虚拟环境进行安装:

如果仍需升级内置的vLLM,您可以通过以下方法在所有工作节点上升级vLLM:
脚本安装
pipx runpip gpustack list | grep vllm
pipx runpip gpustack install -U vllm
Docker安装
docker exec -it gpustack bash
pip list | grep vllm
pip install -U vllm
pip安装指南
pip list | grep vllm
pip install -U vllm
如何升级内置的Transformers?
脚本安装
pipx runpip gpustack list | grep transformers
pipx runpip gpustack install -U transformers
Docker安装
docker exec -it gpustack bash
pip list | grep transformers
pip install -U transformers
pip安装指南
pip list | grep transformers
pip install -U transformers
如何升级内置的llama-box?
GPUStack支持多种版本的推理后端。在部署模型时,您可以在Edit Model → Advanced → Backend Version中指定后端版本,以使用新发布的llama-box版本。GPUStack将自动下载并配置它:

如果您正在使用分布式推理,您应该通过以下方法在所有工作节点上升级llama-box:
从llama-box releases下载最新发布的llama-box二进制文件。
你需要先停止GPUStack,然后替换二进制文件,最后重新启动GPUStack。你可以通过一些目录来检查文件位置,例如:
脚本与pip安装
ps -ef | grep llama-box
Docker安装
docker exec -it gpustack bash
ps -ef | grep llama-box
查看日志
如何查看GPUStack日志?
GPUStack日志提供了有关启动状态、计算模型资源需求等信息。请参阅故障排除查看GPUStack日志。
如何在GPUStack中启用调试模式?
您可以临时启用调试模式而不会中断GPUStack服务。请参考故障排除获取指导。
如果想持久启用调试模式,服务器和工作节点在运行GPUStack时都可以添加--debug参数:
脚本安装
- Linux
sudo vim /etc/systemd/system/gpustack.service
ExecStart=/root/.local/bin/gpustack start --debug
保存并重启GPUStack:
sudo systemctl daemon-reload && sudo systemctl restart gpustack
- macOS
sudo launchctl bootout system /Library/LaunchDaemons/ai.gpustack.plist
sudo vim /Library/LaunchDaemons/ai.gpustack.plist
<array>
<string>/Users/gpustack/.local/bin/gpustack</string>
<string>start</string>
<string>--debug</string>
</array>
sudo launchctl bootstrap system /Library/LaunchDaemons/ai.gpustack.plist
- Windows
nssm edit GPUStack
在 start 后添加参数:
start --debug
保存并重启GPUStack:
Restart-Service -Name "GPUStack"
Docker安装
在docker run命令末尾添加--debug参数,如下所示:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack \
--debug
pip安装指南
在gpustack start命令末尾添加--debug参数:
gpustack start --debug
如何查看RPC服务器日志?
RPC服务器用于GGUF模型的分布式推理。如果模型启动异常或分布式推理出现问题,您可以在相应节点上查看RPC服务器日志:
脚本安装
- Linux & macOS
默认路径如下。如果设置了--data-dir或--log-dir参数,请修改为您实际配置的路径:
tail -200f /var/lib/gpustack/log/rpc_server/gpu-0.log
每个GPU对应一个RPC服务器。对于其他GPU索引,请修改为实际索引:
tail -200f /var/lib/gpustack/log/rpc_server/gpu-n.log
- Windows
默认路径如下。如果设置了--data-dir或--log-dir参数,请修改为您实际配置的路径:
Get-Content "$env:APPDATA\gpustack\log\rpc_server\gpu-0.log" -Tail 200 -Wait
每个GPU对应一个RPC服务器。对于其他GPU索引,请修改为实际索引:
Get-Content "$env:APPDATA\gpustack\log\rpc_server\gpu-n.log" -Tail 200 -Wait
Docker安装
默认路径如下。如果设置了--data-dir或--log-dir参数,请修改为您实际配置的路径:
docker exec -it gpustack tail -200f /var/lib/gpustack/log/rpc_server/gpu-0.log
每个GPU对应一个RPC服务器。对于其他GPU索引,请修改为实际索引:
docker exec -it gpustack tail -200f /var/lib/gpustack/log/rpc_server/gpu-n.log
模型日志存储在何处?
模型实例日志存储在对应工作节点或工作容器的/var/lib/gpustack/log/serve/目录中,日志文件名为id.log,其中id是模型实例ID。如果设置了--data-dir或--log-dir参数,日志将存储在参数指定的实际路径中。
如何启用后端调试模式?
llama-box 后端 (GGUF 模型)
在Edit Model → Advanced → Backend Parameters中添加--verbose参数并重新创建模型实例:

vLLM后端(Safetensors模型)
在Edit Model → Advanced → Environment Variables中添加环境变量VLLM_LOGGING_LEVEL=DEBUG并重新创建模型实例:

管理工作节点
如果worker卡在Unreachable状态该怎么办?
尝试从服务器访问错误中显示的URL。如果服务器运行在容器中,您需要进入服务器容器来执行命令:
curl http://10.10.10.1:10150/healthz
如果worker卡在NotReady状态该怎么办?
检查对应工作节点上的GPUStack日志此处。如果日志中没有异常,请确认所有节点上的时区和系统时钟保持一致。
检测GPU
为什么未能检测到昇腾NPU?
检查容器中是否可以执行npu-smi:
docker exec -it gpustack bash
npu-smi info
当出现以下错误时,表明其他容器也在挂载NPU设备,而当前不支持共享:
dcmi model initialized failed, because the device is used. ret is -8020
检查主机上是否有容器挂载了NPU设备:
if [ $(docker ps | wc -l) -gt 1 ]; then docker ps | grep -v CONT | awk '{print $1}' | xargs docker inspect --format='{{printf "%.5s" .ID}} {{range .HostConfig.Devices}}{{.PathOnHost}} {{end}}' | sort -k2; fi; echo ok
仅挂载未被其他容器使用的NPU设备,通过--device参数指定:
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack:latest-npu
模型管理
如何部署模型?
如何部署来自Hugging Face的模型?
要从Hugging Face部署模型,调度模型实例的服务器节点和工作节点必须能够访问Hugging Face,或者您可以使用镜像。
例如,配置 hf-mirror.com 镜像:
脚本安装
- Linux
在所有节点上创建或编辑/etc/default/gpustack文件,添加HF_ENDPOINT环境变量以使用https://hf-mirror.com作为Hugging Face镜像:
vim /etc/default/gpustack
HF_ENDPOINT=https://hf-mirror.com
保存并重启GPUStack:
systemctl restart gpustack
Docker安装
在运行容器时添加HF_ENDPOINT环境变量,如下所示:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
-e HF_ENDPOINT=https://hf-mirror.com \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack
pip安装指南
HF_ENDPOINT=https://hf-mirror.com gpustack start
如何从本地路径部署模型?
从本地路径部署模型时,建议将模型文件上传至每个节点并保持相同的绝对路径。或者,应通过手动调度或标签选择的方式,将模型实例手动调度到已包含模型文件的节点上。另一种选择是在多个节点间挂载共享存储。
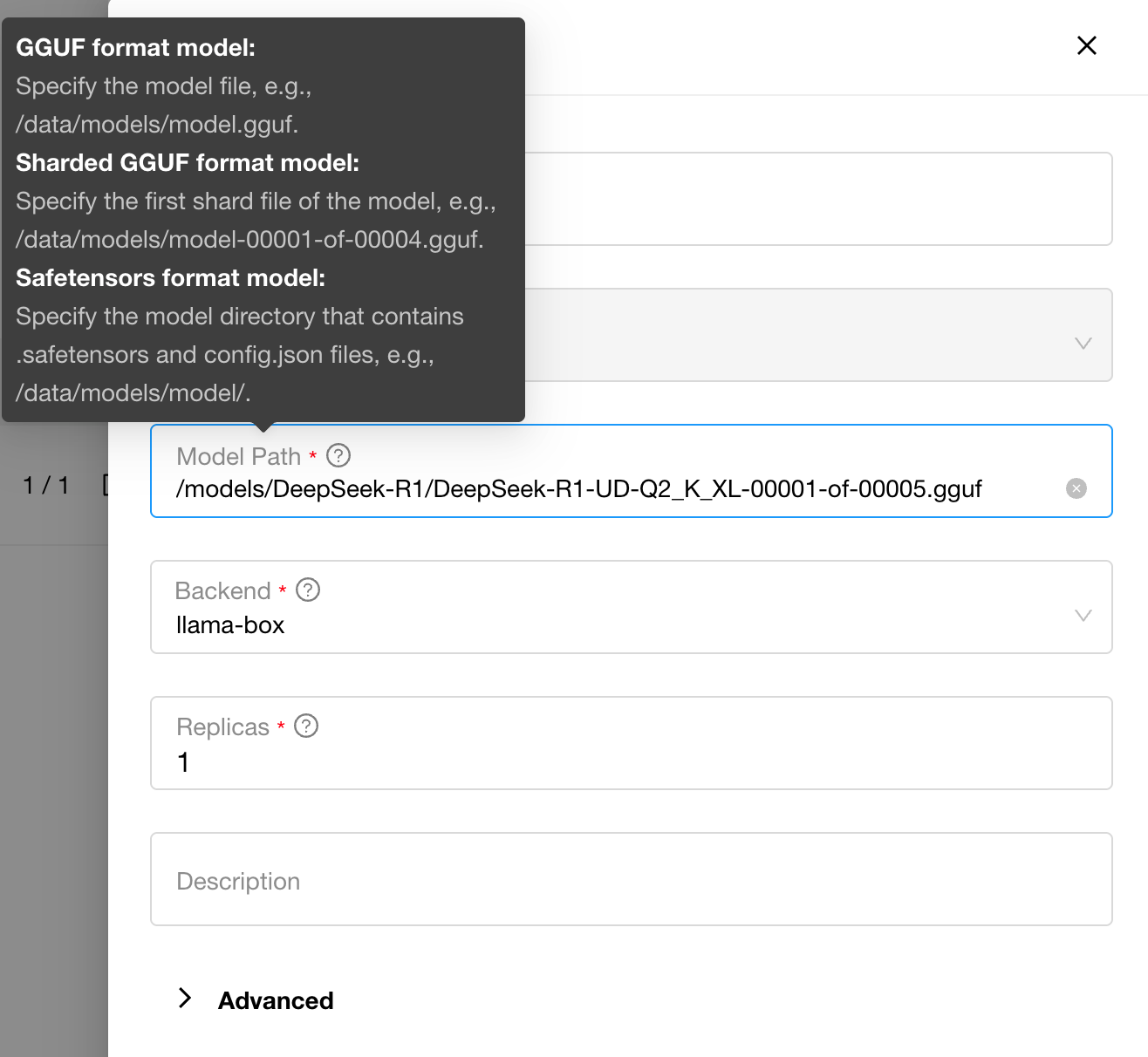
从本地路径部署GGUF模型时,路径必须指向.gguf文件的绝对路径。对于分片模型文件,请使用第一个.gguf文件(00001)的绝对路径。如果使用容器安装,模型文件必须挂载到容器中,且路径应指向容器内的路径,而非宿主机的路径。
从本地路径部署Safetensors模型时,路径必须指向包含*.safetensors、config.json和其他文件的模型目录的绝对路径。如果使用容器安装,模型文件必须挂载到容器中,且路径应指向容器内的路径,而非宿主机的路径。
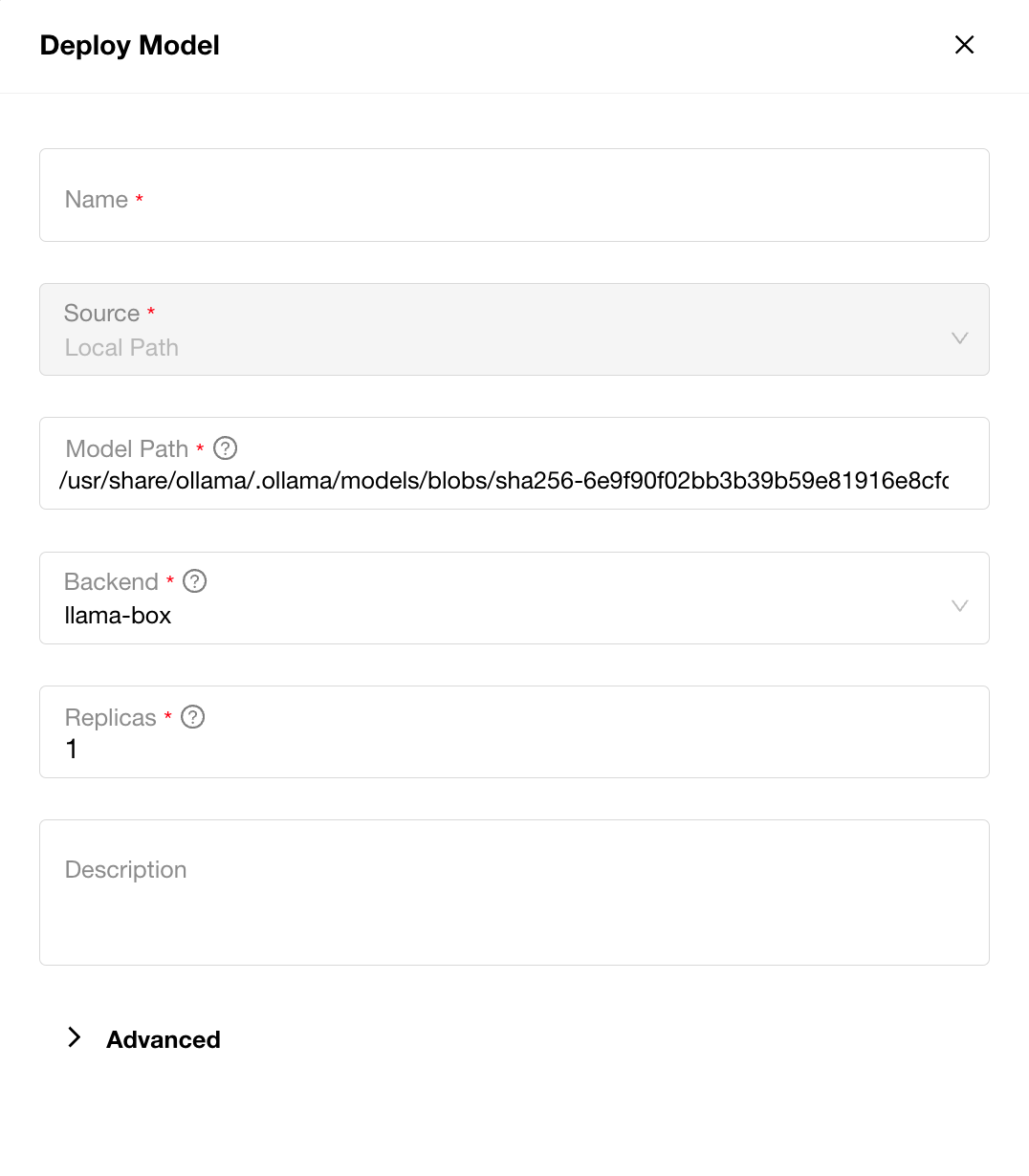
如何部署本地下载的Ollama模型?
使用以下命令查找模型文件的完整路径,并通过本地路径进行部署。以下示例使用deepseek-r1:14b-qwen-distill-q4_K_M,请确保将其替换为您实际的Ollama模型名称:
ollama show deepseek-r1:14b-qwen-distill-q4_K_M --modelfile | grep FROM | grep blobs | sed 's/^FROM[[:space:]]*//'
如果模型卡在Pending状态该怎么办?
Pending 表示当前没有满足模型要求的工作节点,将鼠标悬停在 Pending 状态上可查看具体原因。
首先,检查Resources-Workers部分,确保工作节点状态为就绪。
然后,针对不同的后端:
- llama-box
llama-box 使用 GGUF Parser 来计算模型的内存需求。您需要确保可分配内存大于模型的计算内存需求。请注意,即使其他模型处于 Error 或 Downloading 状态,GPU 内存也已经被分配。如果您不确定模型需要多少 GPU 内存,可以使用 GGUF Parser 来计算。
模型的上下文长度也会影响所需的GPU内存。您可以通过调整--ctx-size参数来设置较小的上下文。在GPUStack中,如果未设置此参数,其默认值为8192。如果在后端参数中指定了该值,则以实际设置为准。
您可以根据需要在Edit Model → Advanced → Backend Parameters中将其调整为较小的上下文,例如--ctx-size=2048。但请注意,每个推理请求的最大token数同时受--ctx-size和--parallel参数影响:
max tokens = context size / parallel
--parallel的默认值为4,因此在这种情况下,最大token数将为512。如果token计数超过最大值,推理输出将被截断。
另一方面,--parallel参数表示并行解码的序列数量,可以大致视为模型并发请求处理的设置。
因此,正确设置--ctx-size和--parallel参数非常重要,确保单个请求的最大token数在限制范围内,并且可用GPU内存能够支持指定的上下文大小。
如果需要与Ollama的配置保持一致,可以参考以下示例:
在Edit Model → Advanced → Backend Parameters中设置以下参数:
--ctx-size=8192
--parallel=4
If your GPU memory is insufficient, try launching with a lower configuration:
--ctx-size=2048
--parallel=1
- vLLM
vLLM默认要求所有GPU的可用内存超过90%(由--gpu-memory-utilization参数控制)。请确保可分配的GPU内存超过90%。请注意,即使其他模型处于Error或Downloading状态,GPU内存也已经被分配。
If all GPUs have more than 90% available memory but still show Pending, it indicates insufficient memory. For safetensors models in BF16 format, the required GPU memory (GB) can be estimated as:
GPU Memory (GB) = Number of Parameters (B) * 2 * 1.2 + 2
If the allocatable GPU memory is less than 90%, but you are sure the model can run with a lower allocation, you can adjust the --gpu-memory-utilization parameter. For example, add --gpu-memory-utilization=0.5 in Edit Model → Advanced → Backend Parameters to allocate 50% of the GPU memory.
Note: If the model encounters an error after running and the logs show CUDA: out of memory, it means the allocated GPU memory is insufficient. You will need to further adjust --gpu-memory-utilization, add more resources, or deploy a smaller model.
模型的上下文长度也会影响所需的GPU内存。您可以通过调整--max-model-len参数来设置较小的上下文。在GPUStack中,如果未设置此参数,其默认值为8192。如果在后端参数中指定了该值,则以实际设置为准。
您可以根据需要将其调整为较小的上下文长度,例如--max-model-len=2048。但请注意,每个推理请求的最大token数不能超过--max-model-len的值。因此,设置过小的上下文长度可能会导致推理截断。
--enforce-eager参数也有助于减少GPU内存使用。然而,vLLM中的这个参数会强制模型以即时执行模式运行,这意味着操作在被调用时会立即执行,而不是延迟到基于图的执行(如惰性执行)中进行优化。这可能会使执行速度变慢,但更容易调试。不过,由于缺少图执行提供的优化,这也可能会降低性能。
如果模型卡在Scheduled状态该怎么办?
尝试重启调度该模型的GPUStack服务。如果问题仍然存在,请检查工作节点日志此处以分析原因。
如果模型卡在Error状态该怎么办?
将鼠标悬停在Error状态上可查看原因。如果出现View More按钮,点击它检查模型日志中的错误信息并分析错误原因。
如何解决错误 *.so: 无法打开共享对象文件: 没有该文件或目录?
如果在模型启动过程中出现错误,提示无法打开任何.so文件,例如:
llama-box: error while loading shared libraries: libcudart.so.12: cannot open shared object file: No such file or directory
原因是GPUStack无法识别LD_LIBRARY_PATH环境变量,这可能是因为在GPUStack安装过程中缺少环境变量或未配置工具包(如CUDA、CANN等)。
检查环境变量是否已设置:
echo $LD_LIBRARY_PATH
如果未配置,这里有一个CUDA的示例配置。
确保nvidia-smi可执行且NVIDIA驱动版本为550或更高:
nvidia-smi
配置CUDA环境变量。如果未安装,请安装CUDA 12.4或更高版本:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/targets/x86_64-linux/lib
export PATH=$PATH:/usr/local/cuda/bin
echo $LD_LIBRARY_PATH
echo $PATH
创建或编辑/etc/default/gpustack文件,添加PATH和LD_LIBRARY_PATH环境变量:
vim /etc/default/gpustack
LD_LIBRARY_PATH=......
PATH=......
保存并重启GPUStack:
systemctl restart gpustack
为什么使用本地路径时加载模型失败?
当使用本地路径部署模型并遇到failed to load model错误时,您需要检查模型实例所调度的节点上是否存在模型文件,以及绝对路径是否正确。
对于GGUF模型,您需要指定.gguf文件的绝对路径。对于分片模型,请使用第一个.gguf文件(通常是00001)的绝对路径。
如果使用Docker安装,必须将模型文件挂载到容器中。请确保提供的路径是容器内部的路径,而非宿主机的路径。
为什么删除模型后磁盘空间没有释放?
这是为了避免在重新部署时重复下载模型。您需要手动在Resources → Model Files中清理它。
为什么每个GPU默认都有一个llama-box进程?
该进程是用于llama-box分布式推理的RPC服务器。如果您确定不需要使用llama-box进行分布式推理,可以在运行GPUStack时添加--disable-rpc-servers参数来禁用RPC服务器服务。
后端参数
如何了解后端参数的作用?
如何设置模型的上下文长度?
llama-box 后端 (GGUF 模型)
GPUStack 默认将模型的上下文长度设置为8K。您可以使用--ctx-size参数自定义上下文长度,但不能超过模型的最大上下文长度:

如果进行编辑,请保存更改后重新创建模型实例以使更改生效。
vLLM 后端(Safetensors 模型)
GPUStack默认将模型的上下文长度设置为8K。您可以使用--max-model-len参数自定义上下文长度,但不能超过模型的最大上下文长度:

MindIE后端(Safetensors模型)
GPUStack 默认将模型的上下文长度设置为8K。您可以使用--max-seq-len参数自定义上下文长度,但不能超过模型的最大上下文长度:

如果进行编辑,请保存更改后重新创建模型实例以使其生效。
使用模型
使用视觉语言模型
如何解决错误"每次请求最多只能提供1张图片"?
这是vLLM的一个限制。您可以根据需要在Edit Model → Advanced → Backend Parameters中调整--limit-mm-per-prompt参数。例如,--limit-mm-per-prompt=image=4表示每个推理请求最多支持4张图像,详情请参阅此处。
管理GPUStack
如何管理GPUStack服务?
脚本安装
- Linux
停止GPUStack:
sudo systemctl stop gpustack
启动 GPUStack:
sudo systemctl start gpustack
重启GPUStack:
sudo systemctl restart gpustack
- macOS
停止 GPUStack:
sudo launchctl bootout system /Library/LaunchDaemons/ai.gpustack.plist
启动GPUStack:
sudo launchctl bootstrap system /Library/LaunchDaemons/ai.gpustack.plist
重启GPUStack:
sudo launchctl bootout system /Library/LaunchDaemons/ai.gpustack.plist
sudo launchctl bootstrap system /Library/LaunchDaemons/ai.gpustack.plist
- Windows
以管理员身份运行PowerShell(避免使用PowerShell ISE)。
停止GPUStack:
Stop-Service -Name "GPUStack"
启动GPUStack:
Start-Service -Name "GPUStack"
重启GPUStack:
Restart-Service -Name "GPUStack"
Docker安装
重启GPUStack容器:
docker restart gpustack
如何在使用代理的情况下使用GPUStack?
脚本安装
- Linux & macOS
创建或编辑 /etc/default/gpustack 并添加代理配置:
vim /etc/default/gpustack
http_proxy="http://username:password@proxy-server:port"
https_proxy="http://username:password@proxy-server:port"
all_proxy="socks5://username:password@proxy-server:port"
no_proxy="localhost,127.0.0.1,192.168.0.0/24,172.16.0.0/16,10.0.0.0/8"
保存并重启GPUStack:
systemctl restart gpustack
Docker安装
运行GPUStack时传递环境变量:
docker run -e http_proxy="http://username:password@proxy-server:port" \
-e https_proxy="http://username:password@proxy-server:port" \
-e all_proxy="socks5://username:password@proxy-server:port" \
-e no_proxy="localhost,127.0.0.1,192.168.0.0/24,172.16.0.0/16,10.0.0.0/8" \
……