模型介绍
TTS 系统主要包括三个模块: Text Frontend、Acoustic model 和 Vocoder。我们在 cn_text_frontend.md 中介绍了基于规则的中文文本前端。在这里,我们将介绍可以训练的声学模型和声码器。
语音合成的主要过程包括:
通过
text frontend模块将原始文本转换为字符/音素。通过
Acoustic models将字符/音素转换为声学特征,例如线性声谱图、梅尔声谱图、LPC特征等。通过
Vocoders将声学特征转换为波形。
简单的文本前端模块可以通过规则实现。需要训练声学模型和声码器。PaddleSpeech TTS 提供的模型是声学模型和声码器。
声学模型
声学模型的建模目标
建模文本序列与语音特征之间的映射关系:
text X = {x1,...,xM}
specch Y = {y1,...yN}
建模目标:
Ω = argmax p(Y|X,Ω)
声学模型的建模过程
目前,有两种主流的声学模型结构。
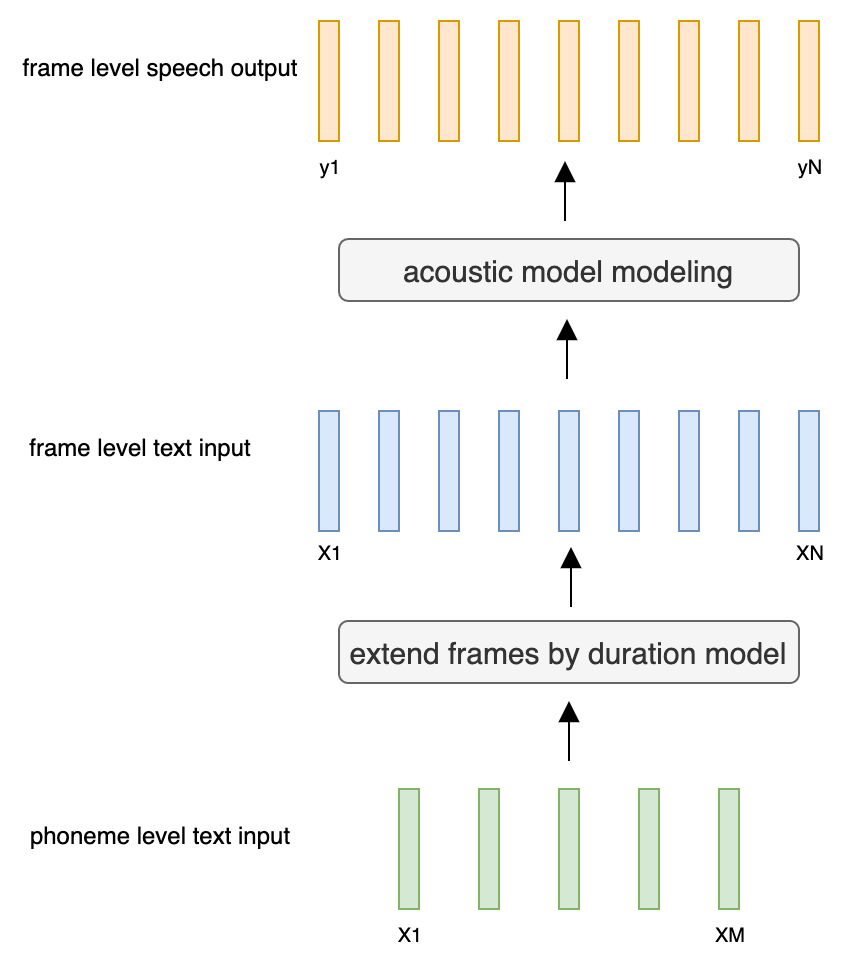
帧级声学模型:
持续时间模型 (M 令牌 -> N 桢)。
声学解码器 (帧数 - > 帧数).
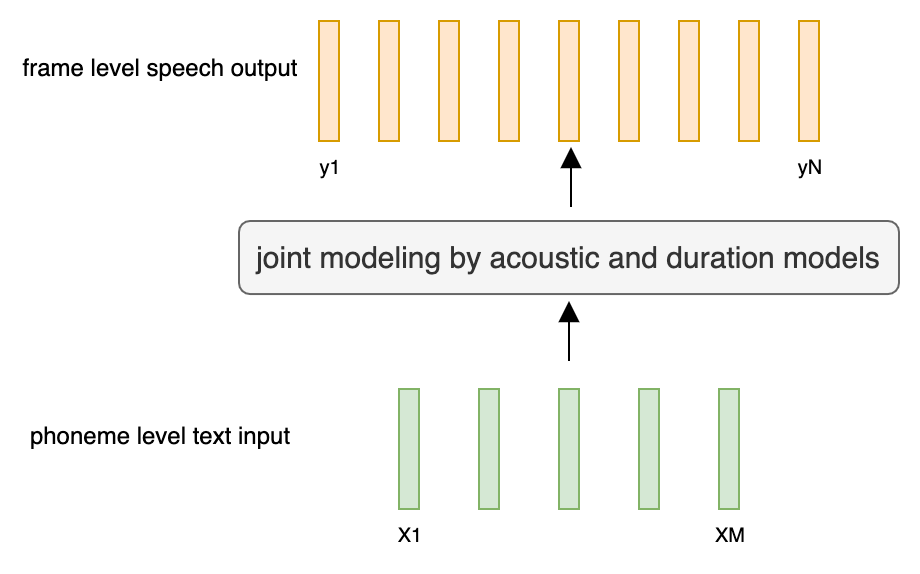
序列到序列的声学模型:
M Tokens - > N Frames.
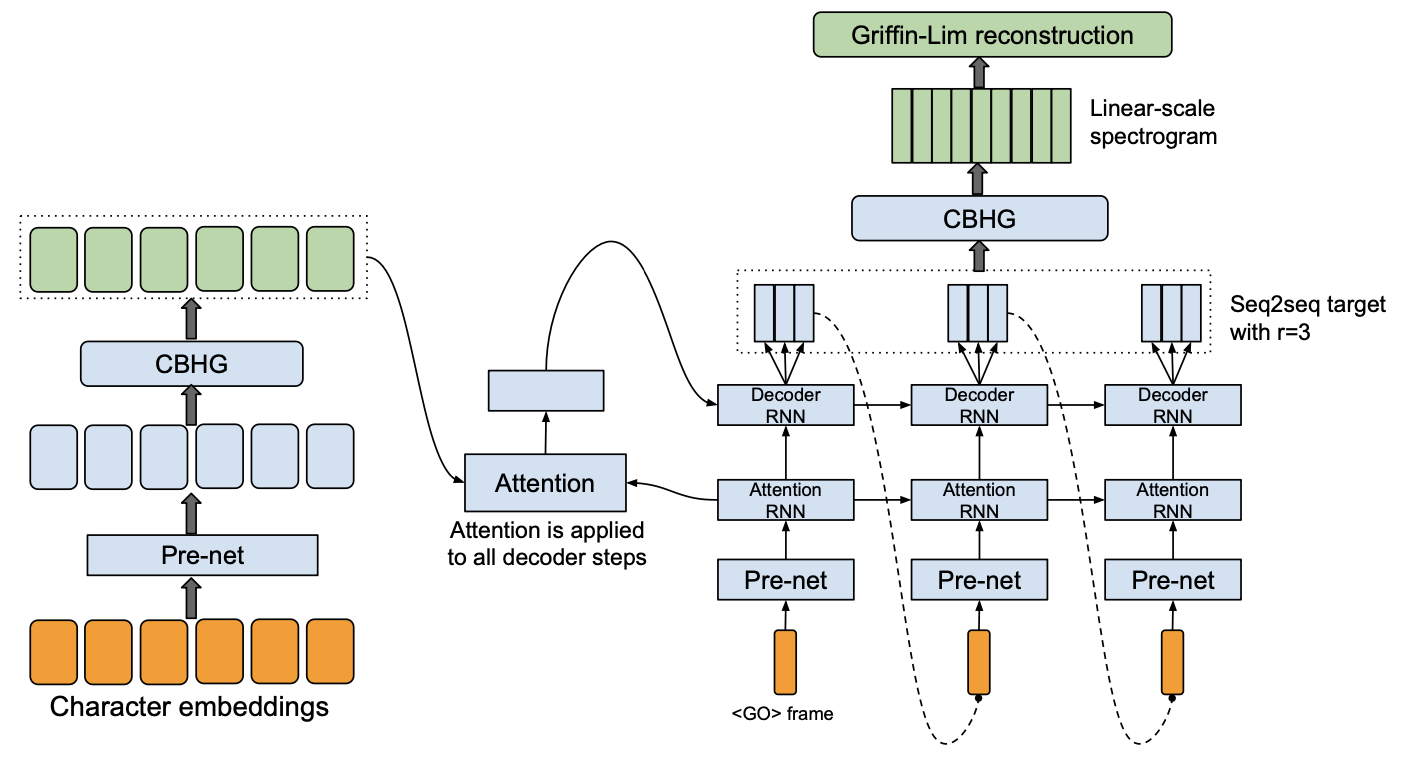
Tacotron2
Tacotron 是第一个基于深度学习的端到端声学模型,也是最广泛使用的声学模型。
Tacotron2 是 Tacotron 的改进版。
Tacotron
Tacotron 的特点:
编码器。
中央银行货币管理局。
输入:字符序列。
解码器。
全局软注意力。
单向 RNN。
自回归教师强制训练(输入真实语音特征)。
多帧预测。
CBHG 后处理。
声码器: Griffin-Lim.
Tacotron的优势:
不需要复杂的文本前端分析模块。
无需额外的持续时间模型。
大大简化了声学模型构建过程,减少了语音合成任务对领域知识的依赖。
Tacotron的缺点:
CBHG 是复杂的,参数的数量相对较大。
全局软注意力。
语音合成任务的稳定性差。
在训练中,每个时刻预测的语音帧数量越少,训练就越困难。
Griffin-Lim中的相位问题导致波形重建过程中出现语音失真。
自回归解码器在生成过程中无法停止。
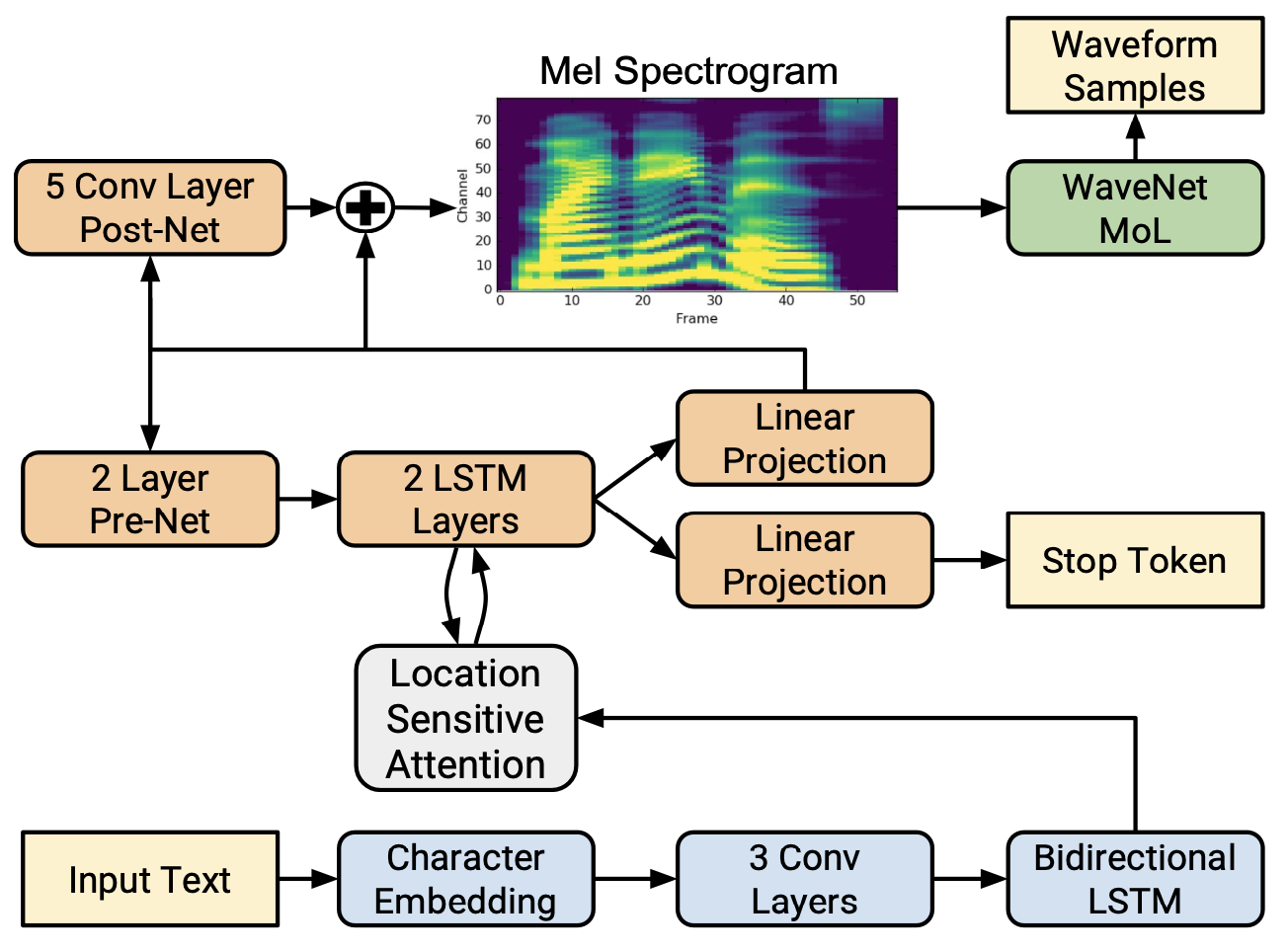
Tacotron2
Tacotron2的特点:
参数的减少。
CBHG -> PostNet (3 个卷积层 + BLSTM 或 5 个卷积层).
移除注意力 RNN。
由Griffin-Lim引起的语音失真。
WaveNet.
PostNet的改进。
CBHG -> 5 卷积层。
PostNet计算与真实Mel谱图的
L2损失的输入和输出。残差连接。
自回归解码器中的错误停止。
预测在解码的每个时刻是否应该停止(停止标记)。
设置一个阈值来决定在解码时是否停止生成。
注意力的稳定性。
位置感知的注意力。
在解码器的第
t步中考虑前一次的对齐矩阵。
您可以在 examples/ljspeech/tts0 找到 PaddleSpeech TTS 的 tacotron2 和 LJSpeech 数据集示例。
变换器文本到语音
Tacotron的缺点:
编码器和解码器在全球信息建模方面相对较弱
RNN的消失梯度。
在CNN内核中的固定长度上下文建模问题。
训练相对低效。
注意力不够强健,稳定性差。
Transformer TTS 是 Tacotron2 和 Transformer 的结合。
变压器
Transformer 是一个完全基于注意力机制的序列到序列模型。
变压器的特点:
编码器。
N基于自注意力机制的块。位置编码。
解码器。
N块基于自注意力机制。在区块中的自注意力上添加掩码,以覆盖
t步骤之后的信息。编码器和解码器之间的注意事项。
位置编码。
变换器 TTS
Transformer TTS 是一个基于 Transformer 和 Tacotron2 的 seq2seq 声学模型。
动机:
Tacotron2中的RNN使训练效率低下。
RNN的消失梯度使得模型对长期上下文的建模能力较弱。
自注意力不包含任何可以并行训练的递归结构。
自注意力可以很好地建模全球上下文信息。
转换器 TTS 的特点:
在编码器和解码器中添加基于卷积的PreNet。
解码器中的停止令牌控制何时停止自回归生成。
在解码器后添加PostNet以提高合成语音的质量。
缩放位置编码。
均匀尺度位置编码可能对输入或输出序列产生负面影响。
变压器TTS的缺点:
位置编码对时间信息的能力仍然相对较弱。
感知本地信息的能力较弱,本地信息与发音联系更大。
稳定性比Tacotron2差。
您可以在 examples/ljspeech/tts1 找到 PaddleSpeech TTS 的 Transformer TTS 及 LJSpeech 数据集示例。
FastSpeech2
seq2seq模型的缺点:
在基于注意力的seq2seq模型中,无论如何改进注意力机制,都会在解码阶段难以避免生成错误。
帧级声学模型使用持续时间模型来确定音素的发音持续时间,帧级映射没有序列生成的不确定性。
在seq2saq模型中,持续时间模型的概念被用作两个序列的对齐模块,以替代注意力,这可以避免注意力中的不确定性,并显著提高seq2saq模型的稳定性。
快速演讲
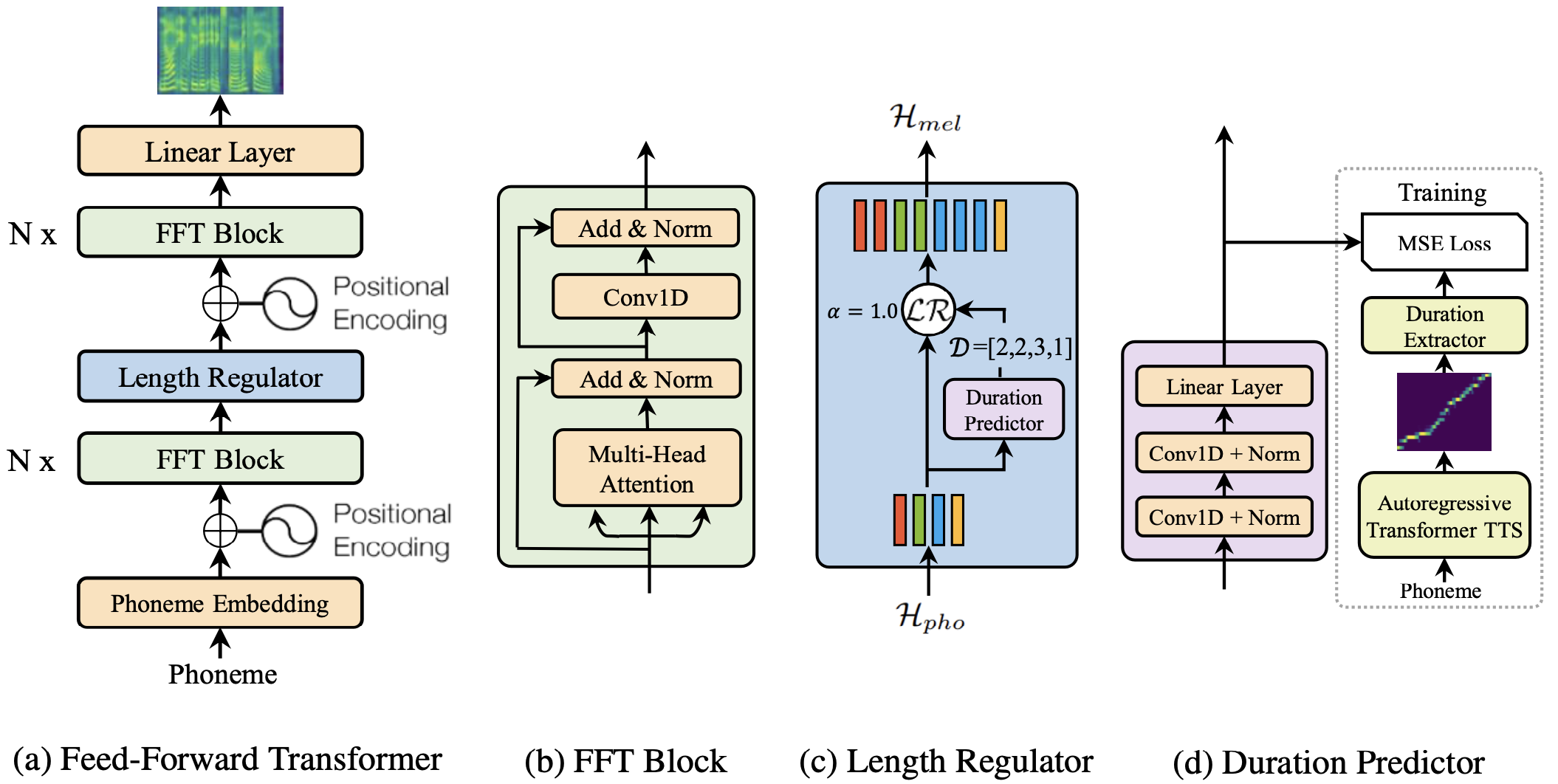
与大多数基于seq2seq的自回归和非自回归生成所采用的编码器-注意力-解码器架构不同, FastSpeech 是一种新型的前馈结构,可以并行生成目标mel频谱图序列。
FastSpeech 的特点:
编码器:基于变换器。
在自注意力中将
FFN更改为CNN。模型本地依赖。
长度调节器。
在训练期间使用真实的音素时长来扩展编码器的输出帧。
非自回归解码。
提高生成效率。
长度预测器:
预训练一个TransformerTTS模型。
获取训练数据的对齐矩阵。
根据对齐矩阵的概率计算音素持续时间。
使用编码器的输出预测音素时长并计算均方误差损失。
使用真实音素时长在训练期间扩展编码器的输出帧。
在预测期间使用持续时间模型预测的音素持续时间来扩展帧。
注意,注意力无法控制音素持续时间。显式持续时间建模可以通过持续时间系数控制持续时间(持续时间系数在训练期间为
1)。
非自回归解码器的优点:
seq2seq模型的内置持续时间模型已将输入长度
M转换为输出长度N。输出的长度是已知的,
stop token不再使用,避免了无法停止的问题。
• 可以并行生成(解码时间不太受序列长度的影响)
快速投球
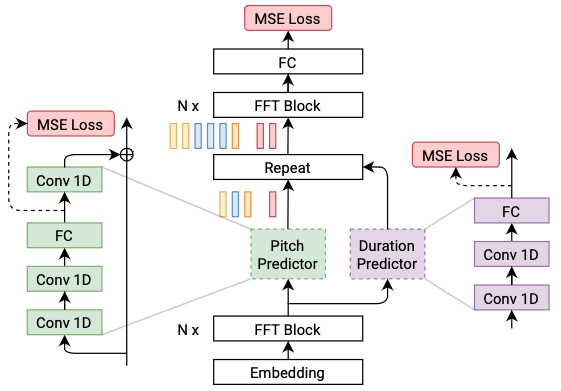
FastPitch 跟随 FastSpeech。为每个时间位置预测一个单一的音高值,这提高了合成语音的整体质量。
FastSpeech2
FastSpeech的缺点:
师生蒸馏流程复杂且耗时。
从教师模型提取的持续时间不够准确。
从教师模型提取的目标梅尔谱图由于数据简化而遭受信息损失。
FastSpeech2 解决了 FastSpeech 中的问题,并更好地解决了 TTS 中的一对多映射问题。
FastSpeech2 的特点:
直接使用真实目标训练模型,而不是使用教师的简化输出。
引入更多的语音变化信息作为条件输入,从语音波形中提取
duration,pitch,和energy,并直接将它们作为训练中的条件输入,在推理中使用预测值。
FastSpeech2 类似于 FastPitch,但引入了更多的语音变异信息。
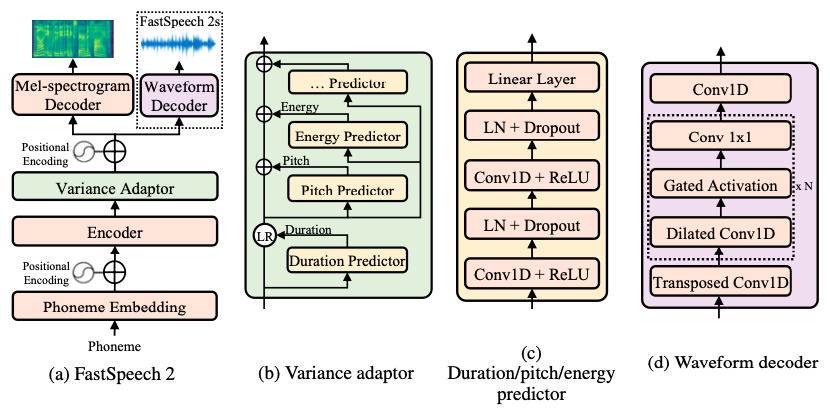
您可以在 examples/csmsc/tts3 找到 PaddleSpeech TTS 的 FastSpeech2/FastPitch 与 CSMSC 数据集的示例,我们使用了在 FastPitch 中引入的按令牌平均的音高和能量值,而不是 FastSpeech2 中的帧级值。
快速语音
SpeedySpeech 简化了 FastSpeech 的师生架构,并提供了快速稳定的训练过程。
SpeedySpeech 的特点:
使用一个更简单、更小、更快训练的卷积教师模型(Deepvoice3 和 DCTTS),而不是在 FastSpeech 中使用的 Transformer,采用单个注意力层。
证明学生网络中的自注意力层对高质量语音合成不是必需的。
描述一种简单的数据增强技术,可以在训练早期使用,以使教师网络对序列误差传播具有鲁棒性。
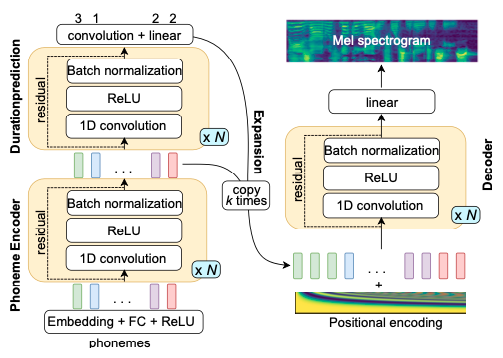
您可以在 examples/csmsc/tts2 找到 PaddleSpeech TTS 的 SpeedySpeech 与 CSMSC 数据集示例。
声码器
在语音合成中,声码器的主要任务是将声学模型预测的谱参数转换为最终的语音波形。
考虑到波形的短期变化频率,声学模型通常避免直接对语音波形进行建模,而是首先对从语音波形中提取的谱特征进行建模,然后通过编码器的解码部分重建波形。
声码器通常由一对用于语音分析和合成的编码器和解码器组成。编码器估计参数,然后解码器恢复语音。
基于神经网络的音频编码器通常是语音合成,它通过训练数据学习从光谱特征到波形的映射关系。
神经声码器的类别
自回归
波网
波形递归神经网络
LPCNet
流
波流
波光
FloWaveNet
并行WaveNet
对抗生成网络
波动生成对抗网络
并行波GAN
MelGAN
风格 MelGAN
多频带 MelGAN
高保真生成对抗网络
变分自编码器
波动变分自编码器
扩散
波动渐变
DiffWave
基于GAN的语音合成器的动机:
通过估计概率分布对语音信号进行建模通常对模型自身的表达能力有较高的要求。此外,需要对波形的分布做出特定的假设。
尽管自回归神经声码器可以获得高质量的合成语音,但这类模型通常具有较慢的生成速度。
逆自回归流声码器的训练是复杂的,并且它们还需要对长期上下文信息的建模能力。
基于双向变换的编码器收敛缓慢且复杂。
基于GAN的声码器不需要对语音分布做假设,并通过对抗学习进行训练。
在这里,我们介绍了一种基于流的声码器WaveFlow和一种基于GAN的声码器Parallel WaveGAN。
波动流
WaveFlow 是由百度研究提出的。
WaveFlow的特点:
它可以在Nvidia V100 GPU上以比实时快约40倍的速度合成22.05 kHz的高保真语音,而无需工程化的推理内核,这比WaveGlow更快,并且比WaveNet快几个数量级。
这是一个用于原始音频的小型基于流的模型。它只有5.9M的参数,比WaveGlow(87.9M)小15倍。
它是直接通过最大似然进行训练,而不使用在Parallel WaveNet和ClariNet中使用的概率密度蒸馏和辅助损失,这简化了训练流程并降低了开发成本。
您可以在 examples/ljspeech/voc0 找到 PaddleSpeech TTS 的 WaveFlow 与 LJSpeech 数据集的示例。
并行WaveGAN
Parallel WaveGAN 训练一个非自回归的 WaveNet 变体作为 GAN 基础训练方法中的生成器。
Parallel WaveGAN的特征:
使用非因果卷积代替因果卷积。
输入是随机高斯白噪声。
该模型在训练和预测中都是非自回归的,因此速度较快
多分辨率STFT损失。
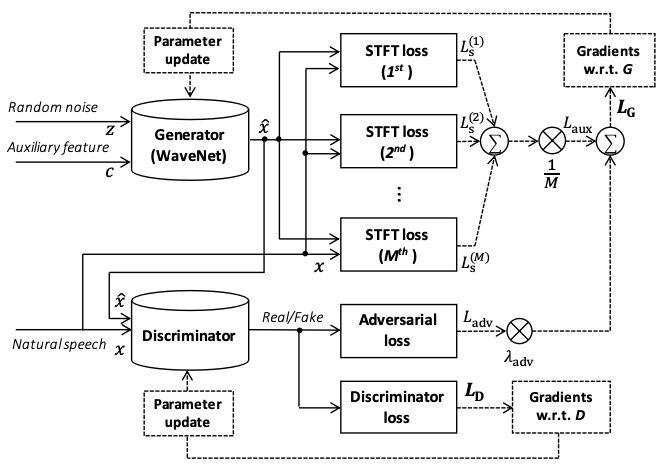
您可以在 examples/csmsc/voc1 找到 PaddleSpeech TTS 的 Parallel WaveGAN 和 CSMSC 示例。