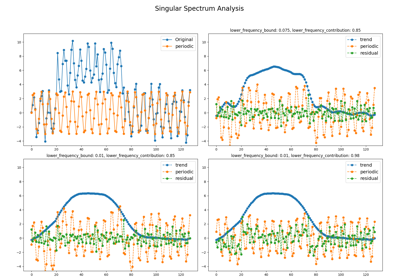
pyts.decomposition.SingularSpectrumAnalysis¶
-
class
pyts.decomposition.SingularSpectrumAnalysis(window_size=4, groups=None, lower_frequency_bound=0.075, lower_frequency_contribution=0.85, chunksize=None, n_jobs=1)[来源]¶ 奇异谱分析。
Parameters: - window_size : int or float (default = 4)
滑动窗口的大小(即每个词的长度)。如果是浮点数,则表示每个时间序列长度的百分比,必须在0到1之间。窗口大小将计算为
max(2, ceil(window_size * n_timestamps))。- groups : None, int, ‘auto’, or array-like (default = None)
基本矩阵的分组方式。如果为None,则不进行分组。如果是一个整数,它表示组的数量,组的边界计算为
np.linspace(0, window_size, groups + 1).astype('int64')。如果为'auto',则确定三个组,分别包含趋势、季节性和残差。如果是类数组,每个元素必须是类数组并包含每个组的索引。- lower_frequency_bound : float (default = 0.075)
用于表征趋势、季节性和残差分量的周期图边界。该值必须在0到0.5之间。当
groups未设置为'auto'时此参数将被忽略。- lower_frequency_contribution : float (default = 0.85)
通过考虑周期图来表征趋势、季节性和残差分量的相对阈值。该值必须在0到1之间。如果
groups未设置为'auto',则忽略此参数。- chunksize : int or None (default = None)
如果为整数,则使用分块(批次)对整个数据集执行转换,
chunksize对应每个分块(批次)的最大大小。如果为None,则一次性对整个数据集执行转换。使用分块执行转换可能会稍慢一些,但需要更少的内存。- n_jobs : None or int (default = None)
用于计算的作业数量。仅在
chunksize设置为整数时使用。
参考文献
[1] N. Golyandina 和 A. Zhigljavsky,《时间序列的奇异谱分析》。Springer-Verlag Berlin Heidelberg (2013)。 [2] T. Alexandrov, "使用奇异谱分析进行趋势提取的方法", REVSTAT (2008). 示例
>>> from pyts.datasets import load_gunpoint >>> from pyts.decomposition import SingularSpectrumAnalysis >>> X, _, _, _ = load_gunpoint(return_X_y=True) >>> transformer = SingularSpectrumAnalysis(window_size=5) >>> X_new = transformer.transform(X) >>> X_new.shape (50, 5, 150)
方法
__init__([window_size, groups, …])Initialize self. fit([X, y])Pass. fit_transform(X[, y])Fit to data, then transform it. get_params([deep])Get parameters for this estimator. set_params(**params)Set the parameters of this estimator. transform(X)Transform the provided data. -
__init__(window_size=4, groups=None, lower_frequency_bound=0.075, lower_frequency_contribution=0.85, chunksize=None, n_jobs=1)[来源]¶ 初始化自身。查看 help(type(self)) 获取准确的签名信息。
-
fit_transform(X, y=None, **fit_params)¶ 拟合数据,然后进行转换。
使用可选参数fit_params将转换器适配到X和y,并返回转换后的X版本。
参数: - X : array-like, shape = (n_samples, n_timestamps)
单变量时间序列。
- y : None or array-like, shape = (n_samples,) (default = None)
目标值(无监督转换时为None)。
- **fit_params : dict
额外的拟合参数。
返回值: - X_new : array
转换后的数组。
-
get_params(deep=True)¶ 获取此估计器的参数。
参数: - deep : bool, default=True
如果为True,将返回此估计器及其包含的子估计器的参数。
返回值: - params : dict
参数名称映射到对应的值。
-
set_params(**params)¶ 设置此估计器的参数。
该方法不仅适用于简单的估计器,也适用于嵌套对象(如
Pipeline)。后者采用<component>__<parameter>形式的参数,从而可以更新嵌套对象的每个组件。参数: - **params : dict
估计器参数。
返回值: - self : 估计器实例
估计器实例。
-
transform(X)[来源]¶ 转换提供的数据。
参数: - X : 类数组, 形状 = (n_samples, n_timestamps)
Returns: - X_new : array-like, shape = (n_samples, n_splits, n_timestamps)
转换后的数据。
n_splits的值取决于groups的值。如果groups=None,则n_splits等于window_size。如果groups是整数,则n_splits等于groups。如果groups='auto',则n_splits等于3。如果groups是类数组对象,则n_splits等于groups的长度。如果n_splits=1,则X_new会被压缩,其形状为(n_samples, n_timestamps)。