Ray 数据概述#
Ray Data 是一个适用于 ML 工作负载的可扩展数据处理库,特别适合以下工作负载:
它为分布式数据处理提供了灵活且高效的API。更多详情,请参见 转换数据。
Ray Data 构建在 Ray 之上,因此它可以有效地扩展到大型集群,并提供对 CPU 和 GPU 资源的调度支持。Ray Data 使用 流式执行 来高效处理大型数据集。
为什么选择 Ray Data?#
现代深度学习应用更快更便宜
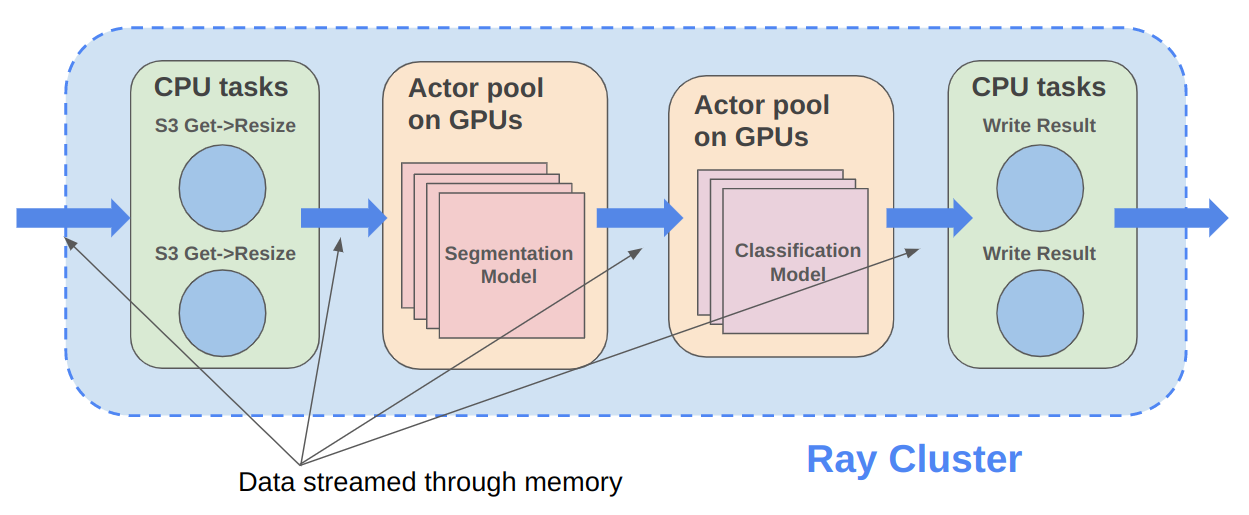
Ray Data 是为涉及CPU预处理和GPU推理的深度学习应用设计的。Ray Data 将工作数据从CPU预处理任务流式传输到GPU推理或训练任务,使您能够同时利用这两组资源。
通过使用 Ray Data,您的 GPU 在 CPU 计算期间不再处于空闲状态,从而降低了批量推理作业的总体成本。
云、框架和数据格式无关
Ray Data 对云提供商、ML框架或数据格式没有限制。
你可以在AWS、GCP或Azure云上启动Ray集群。你可以使用任何你选择的ML框架,包括PyTorch、HuggingFace或Tensorflow。Ray Data也不需要特定的文件格式,并支持包括Parquet、图像、JSON、文本、CSV等在内的 多种格式。
异构集群的开箱即用扩展
Ray Data 建立在 Ray 之上,因此它可以轻松地在异构集群上扩展,该集群具有不同类型的 CPU 和 GPU 机器。在一台机器上运行的代码也可以在大型集群上运行,无需任何更改。
Ray Data 可以轻松扩展到数百个节点,以处理数百 TB 的数据。
用于批量推理和机器学习训练的统一API和后端
使用 Ray Data,您可以直接在相同的 Ray Dataset API 下表达批量推理和机器学习训练任务。
离线批量推理#
离线批量推理是在一组固定的输入数据上生成模型预测的过程。Ray Data 提供了一种高效且可扩展的批量推理解决方案,为深度学习应用提供了更快的执行速度和成本效益。有关如何使用 Ray Data 进行离线批量推理的更多详细信息,请参阅 批量推理用户指南。
Ray Data 与其他离线推理解决方案相比如何?#
批处理服务:AWS Batch、GCP Batch
像AWS、GCP和Azure这样的云服务提供商为您提供批处理服务来管理计算基础设施。每个服务使用相同的过程:您提供代码,服务在集群的每个节点上运行您的代码。然而,尽管基础设施管理是必要的,但它通常是不够的。这些服务有局限性,例如缺乏软件库来解决优化的并行化、高效的数据传输和简单的调试问题。这些解决方案仅适用于能够编写自己的优化批处理推理代码的有经验用户。
Ray Data 不仅抽象了基础设施管理,还抽象了数据集的分片、在这些分片上的推理并行化,以及数据从存储到CPU再到GPU的传输。
在线推理解决方案:Bento ML, Sagemaker 批量转换
像 Bento ML、Sagemaker Batch Transform 或 Ray Serve 这样的解决方案提供了API,使得编写高性能的推理代码变得容易,并且可以抽象掉基础设施的复杂性。但它们是为在线推理而不是离线批量推理设计的,这两者是具有不同需求的不同问题。这些解决方案引入了额外的复杂性,如HTTP,并且无法有效处理大型数据集,导致推理服务提供商如 Bento ML 与 Apache Spark 集成 以进行离线推理。
Ray Data 是为离线批处理作业构建的,无需启动服务器或发送HTTP请求的所有额外复杂性。
有关 Ray Data 和 Sagemaker Batch Transform 之间更详细的性能比较,请参阅 离线批量推理:比较 Ray、Apache Spark 和 SageMaker。
分布式数据处理框架:Apache Spark
Ray Data 处理许多与 Apache Spark 相同的批处理工作负载,但采用更适合深度学习推理GPU工作负载的流处理范式。
Ray Data 没有 SQL 接口,也不旨在替代 Spark 这样的通用 ETL 管道。
有关 Ray Data 和 Apache Spark 之间更详细的性能比较,请参阅 离线批量推理:比较 Ray、Apache Spark 和 SageMaker。
批量推理案例研究#
ML训练的预处理和摄取#
使用 Ray Data 以流式方式加载和预处理数据,用于分布式 机器学习训练管道。分布式训练的关键支持功能包括:
快速内存外恢复
异构集群支持
在分布式数据集迭代期间没有丢弃行
Ray Data 作为从存储或 ETL 管道输出到 Ray 中的分布式应用和库的最后一英里桥梁。用于非结构化数据处理。有关如何使用 Ray Data 进行预处理和为机器学习训练摄取数据的更多详细信息,请参阅 机器学习训练的数据加载。

Ray Data 与其他用于机器学习训练摄取的解决方案相比如何?#
PyTorch 数据集和数据加载器
框架无关: Datasets 是框架无关的,并且可以在不同的分布式训练框架之间移植,而 Torch datasets 是特定于 Torch 的。
无内置IO层: Torch数据集没有为常见文件格式或与其他框架的内存交换提供IO层;用户需要引入其他库并自行实现这种集成。
通用分布式数据处理: Datasets 更加通用:它可以处理通用的分布式操作,包括全局每轮洗牌,否则这些操作必须通过将两个独立的系统拼接在一起来实现。Torch datasets 需要这样的拼接来处理任何比基于批处理的预处理更复杂的事情,并且不原生支持跨工作节点分片的洗牌。请参阅我们关于为什么这种共享基础设施对第三代机器学习架构很重要的 博客文章。
低开销: Datasets 具有较低的开销:它支持进程间的零拷贝交换,这与基于多处理的 Torch datasets 管道形成对比。
TensorFlow 数据集
框架无关: Datasets 是框架无关的,可以在不同的分布式训练框架之间移植,而 TensorFlow datasets 是特定于 TensorFlow 的。
统一的单节点和分布式: Datasets 在同一抽象下统一了单节点和多节点训练。TensorFlow datasets 为分布式数据加载提供了 独立的概念 ,并防止代码无缝扩展到更大的集群。
通用分布式数据处理: 数据集更为通用:它可以处理通用的分布式操作,包括每个epoch的全局洗牌,否则这些操作必须通过将两个独立的系统拼接在一起来实现。TensorFlow数据集需要这样的拼接来处理比基本预处理更复杂的任务,并且不原生支持跨工作分片的全洗牌;只支持文件交错。请参阅我们关于为什么这种共享基础设施对第三代机器学习架构重要的 博客文章。
低开销: Datasets 具有较低的开销:它支持进程间的零拷贝交换,这与 TensorFlow datasets 基于多进程的管道形成对比。
Petastorm
支持的数据类型: Petastorm 仅支持 Parquet 数据,而 Ray Data 支持多种文件格式。
低开销: Datasets 具有较低的开销:它支持进程间的零拷贝交换,这与 Petastorm 使用的基于多处理的管道形成对比。
无数据处理: Petastorm 不提供任何数据处理API。
NVTabular
支持的数据类型: NVTabular 仅支持表格数据(Parquet、CSV、Avro),而 Ray Data 支持许多其他文件格式。
低开销: Datasets 具有较低的开销:它支持进程间的零拷贝交换,这与 NVTabular 使用的基于多进程的管道形成对比。
异构计算: NVTabular 不支持在数据集转换中混合使用异构资源(例如同时使用 CPU 和 GPU 转换),而 Ray Data 支持这一点。