使用浏览器的开发者工具进行抓取¶
这里是一个关于如何使用浏览器的开发者工具来简化抓取过程的通用指南。如今,几乎所有浏览器都内置了开发者工具,尽管在本指南中我们将使用Firefox,但这些概念适用于任何其他浏览器。
在本指南中,我们将介绍如何使用浏览器的开发者工具来抓取quotes.toscrape.com。
检查实时浏览器DOM时的注意事项¶
由于开发者工具操作的是实时的浏览器DOM,因此在检查页面源代码时,您实际看到的不是原始的HTML,而是经过浏览器清理和执行JavaScript代码后修改的HTML。特别是Firefox,它会在表格中添加元素。另一方面,Scrapy不会修改原始页面的HTML,因此如果您在XPath表达式中使用,您将无法提取任何数据。
因此,你应该记住以下几点:
在检查DOM以寻找用于Scrapy的XPath时,禁用JavaScript(在开发者工具设置中点击禁用JavaScript)
永远不要使用完整的XPath路径,使用基于属性(如
id、class、width等)或任何识别特征(如contains(@href, 'image'))的相对和智能路径。除非你真的知道自己在做什么,否则不要在XPath表达式中包含
元素
检查网站¶
到目前为止,开发者工具中最方便的功能是检查器功能,它允许你检查任何网页的底层HTML代码。为了演示检查器,让我们看一下quotes.toscrape.com网站。
在网站上,我们有来自不同作者的十句引用,带有特定的标签,以及十大标签。假设我们想要提取此页面上的所有引用,而不需要任何关于作者、标签等的元信息。
与其查看整个页面的源代码,我们可以简单地右键点击引用并选择Inspect Element (Q),这将打开Inspector。在其中你应该会看到类似这样的内容:
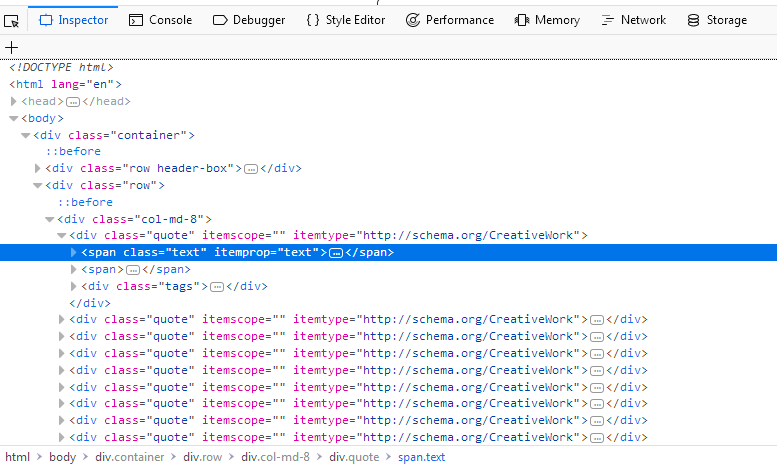
对我们来说有趣的部分是:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">(...)</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
如果您将鼠标悬停在截图高亮的span标签正上方的第一个div上,您会看到网页的相应部分也会被高亮显示。所以现在我们有了一个部分,但我们找不到我们的引用文本。
Inspector 的优势在于它能够自动展开和折叠网页的部分和标签,这大大提高了可读性。您可以通过点击标签前面的箭头或直接双击标签来展开和折叠标签。如果我们展开带有 class=
"text" 的 span 标签,我们将看到我们点击的引用文本。Inspector 允许您复制所选元素的 XPath。让我们试试看。
首先在终端中打开Scrapy shell,访问https://quotes.toscrape.com/:
$ scrapy shell "https://quotes.toscrape.com/"
然后,回到您的网页浏览器,右键点击span标签,选择
Copy > XPath并将其粘贴到Scrapy shell中,如下所示:
>>> response.xpath("/html/body/div/div[2]/div[1]/div[1]/span[1]/text()").getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
在末尾添加 text() 后,我们能够使用这个基本选择器提取第一个引用。但这个 XPath 并不是特别聪明。它所做的只是从 html 开始,沿着源代码中的所需路径向下走。所以让我们看看是否可以稍微改进一下我们的 XPath:
如果我们再次检查Inspector,我们会看到在我们展开的div标签下面有九个相同的div标签,每个标签都具有与我们第一个标签相同的属性。如果我们展开其中任何一个,我们会看到与我们第一个引用相同的结构:两个span标签和一个div标签。我们可以展开每个span标签,其中class="text"位于我们的div标签内,并查看每个引用:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
有了这些知识,我们可以优化我们的XPath:不再需要遵循路径,我们只需使用has-class-extension来选择所有带有class="text"的span标签:
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
通过一个简单而更聪明的XPath,我们能够从页面中提取所有的引用。我们本可以构造一个循环来增加第一个XPath中最后一个div的编号,但这将是不必要的复杂,而通过简单地构造一个带有has-class("text")的XPath,我们能够在一行中提取所有的引用。
Inspector 有许多其他有用的功能,例如在源代码中搜索或直接滚动到您选择的元素。让我们演示一个用例:
假设你想在页面上找到Next按钮。在Inspector的右上角搜索栏中输入Next。你应该会得到两个结果。第一个是带有class="next"的li标签,第二个是a标签的文本。右键点击a标签并选择Scroll into View。如果你将鼠标悬停在标签上,你会看到按钮被高亮显示。从这里我们可以轻松创建一个Link Extractor来跟随分页。在像这样的简单网站上,可能不需要通过视觉找到元素,但Scroll into View功能在复杂网站上非常有用。
请注意,搜索栏也可以用于搜索和测试CSS选择器。例如,您可以搜索span.text来查找所有引用文本。这不是全文搜索,而是搜索页面中具有class="text"的span标签。
网络工具¶
在抓取数据时,你可能会遇到动态网页,其中页面的某些部分是通过多个请求动态加载的。虽然这可能相当棘手,但开发者工具中的网络工具极大地简化了这一任务。为了演示网络工具,让我们看一下页面quotes.toscrape.com/scroll。
该页面与基本的quotes.toscrape.com页面非常相似,
但不同于上面提到的Next按钮,当你滚动到页面底部时,
它会自动加载新的引用。我们可以直接尝试不同的XPath,但相反,
我们将从Scrapy shell中检查另一个非常有用的命令:
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
浏览器窗口应该会打开网页,但有一个关键的区别:我们看到的不是引号,而是一个带有Loading...字样的绿色条。

view(response) 命令让我们可以查看我们的 shell 或稍后我们的爬虫从服务器接收到的响应。在这里我们看到加载了一些基本模板,包括标题、登录按钮和页脚,但引文缺失了。这告诉我们引文是从不同于 quotes.toscrape/scroll 的请求加载的。
如果您点击Network标签,您可能只会看到两个条目。我们做的第一件事是通过点击Persist Logs来启用持久日志。如果此选项被禁用,每次导航到不同页面时,日志都会自动清除。启用此选项是一个很好的默认设置,因为它让我们可以控制何时清除日志。
如果我们现在重新加载页面,你会看到日志中填充了六个新的请求。
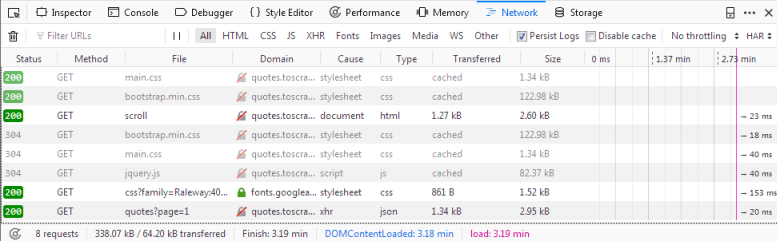
在这里,我们可以看到重新加载页面时发出的每个请求,并可以检查每个请求及其响应。那么让我们找出我们的引述来自哪里:
首先点击名称为scroll的请求。在右侧,你现在可以检查该请求。在Headers中,你可以找到关于请求头的详细信息,例如URL、方法、IP地址等。我们将忽略其他标签,直接点击Response。
你应该在Preview窗格中看到的是渲染后的HTML代码,
这正是我们在shell中调用view(response)时看到的内容。因此,日志中请求的type是html。
其他请求的类型可能是css或js,但我们感兴趣的是那个名为quotes?page=1的请求,其类型为json。
如果我们点击这个请求,我们会看到请求的URL是
https://quotes.toscrape.com/api/quotes?page=1,响应
是一个包含我们引用的JSON对象。我们还可以右键点击
请求并选择Open in new tab以获得更好的概览。
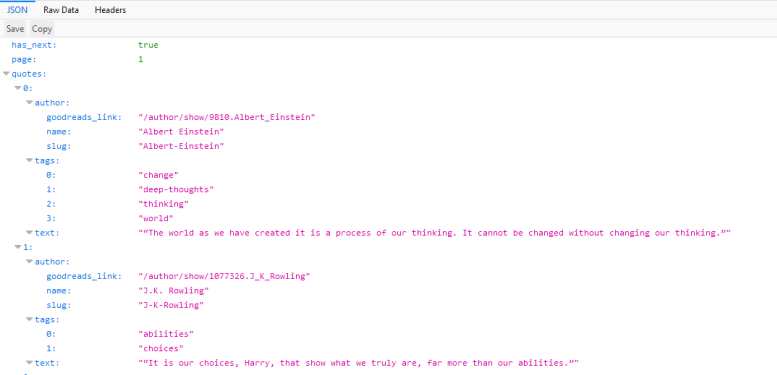
通过这个响应,我们现在可以轻松解析JSON对象,并且还可以请求每个页面以获取网站上的每个引用:
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = "quote"
allowed_domains = ["quotes.toscrape.com"]
page = 1
start_urls = ["https://quotes.toscrape.com/api/quotes?page=1"]
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"https://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse)
这个爬虫从quotes-API的第一页开始。对于每个响应,我们解析response.text并将其赋值给data。这使我们能够像操作Python字典一样操作JSON对象。我们遍历quotes并打印出quote["text"]。如果方便的has_next元素是true(尝试在浏览器中加载quotes.toscrape.com/api/quotes?page=10或大于10的页码),我们增加page属性并yield一个新的请求,将增加的页码插入到我们的url中。
在更复杂的网站中,可能很难轻松地重现请求,因为我们可能需要添加headers或cookies才能使其工作。
在这些情况下,您可以通过在网络工具中右键单击每个请求并使用from_curl()方法生成等效请求,将请求导出为cURL格式:
from scrapy import Request
request = Request.from_curl(
"curl 'https://quotes.toscrape.com/api/quotes?page=1' -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'"
)
或者,如果您想知道重新创建该请求所需的参数,您可以使用 curl_to_request_kwargs() 函数来获取包含等效参数的字典:
- scrapy.utils.curl.curl_to_request_kwargs(curl_command: str, ignore_unknown_options: bool = True) dict[str, Any][source]¶
将cURL命令语法转换为Request kwargs。
请注意,要将cURL命令转换为Scrapy请求, 你可以使用curl2scrapy。
正如你所见,通过在Network工具中进行一些检查,我们能够轻松地复制页面滚动功能的动态请求。抓取动态页面可能相当令人生畏,页面也可能非常复杂,但它(大部分)归结为识别正确的请求并在你的爬虫中复制它。