使用LoRA微调Llama2¶
本指南将教你关于LoRA,一种参数高效的微调技术,并展示如何使用torchtune对Llama2模型进行LoRA微调。如果你已经了解LoRA是什么,并想直接开始在torchtune中运行你自己的LoRA微调,你可以跳转到torchtune中的LoRA微调配方。
什么是LoRA以及它在微调过程中如何节省内存
torchtune中LoRA组件的概述
如何使用 torchtune 运行 LoRA 微调
如何尝试不同的LoRA配置
熟悉 torchtune
请确保您已下载Llama2-7B模型权重
什么是LoRA?¶
LoRA 是一种基于适配器的方法,用于参数高效的微调,它将可训练的低秩分解矩阵添加到神经网络的不同层,然后冻结网络的其余参数。LoRA 最常用于 transformer 模型,在这种情况下,通常将低秩矩阵添加到每个 transformer 层自注意力中的一些线性投影中。
通过使用LoRA进行微调(而不是微调所有模型参数),由于梯度参数数量的大幅减少,您可以预期看到内存节省。当使用带有动量的优化器时,如AdamW,您可以预期从优化器状态中看到进一步的内存节省。
注意
LoRA 的内存节省主要来自于梯度和优化器状态,
所以如果你的模型的峰值内存出现在其 forward() 方法中,那么 LoRA
可能不会减少峰值内存。
LoRA 是如何工作的?¶
LoRA 使用低秩近似替换权重更新矩阵。通常,对于任意的 nn.Linear(in_dim,out_dim) 层,权重更新的秩可能高达 min(in_dim,out_dim)。LoRA(以及其他相关论文,如 Aghajanyan et al.)假设在 LLM 微调期间,这些更新的内在维度实际上可以低得多。为了利用这一特性,LoRA 微调会冻结原始模型,然后从低秩投影中添加可训练的权重更新。更明确地说,LoRA 训练两个矩阵 A 和 B。A 将输入投影到一个更小的秩(在实践中通常为四或八),而 B 则投影回原始线性层输出的维度。
下图给出了完整微调(左侧)与使用LoRA(右侧)的权重更新步骤的简化表示。LoRA矩阵A和B作为蓝色全秩权重更新的近似。
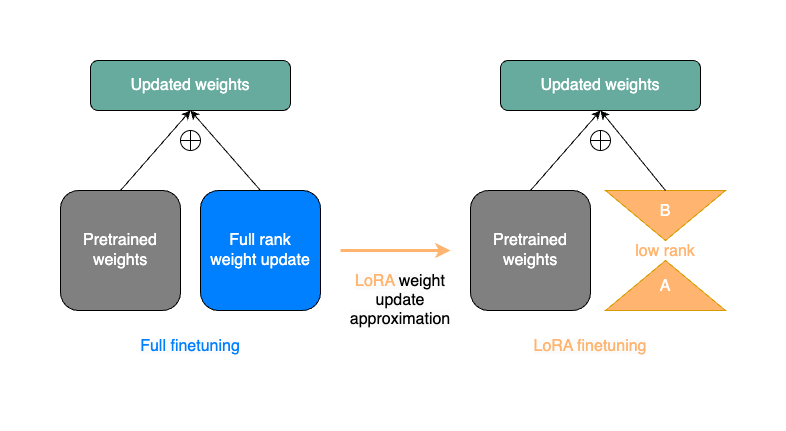
尽管LoRA在模型forward()中引入了一些额外的参数,但只有A和B矩阵是可训练的。
这意味着在秩为r的LoRA分解中,我们需要存储的梯度数量从in_dim*out_dim减少到r*(in_dim+out_dim)。(记住,通常r比in_dim和out_dim小得多。)
例如,在7B Llama2的自注意力机制中,in_dim=out_dim=4096 用于Q、K和V的投影。这意味着一个秩为r=8的LoRA分解将把给定投影的可训练参数数量从\(4096 * 4096 \approx 15M\)减少到\(8 * 8192 \approx 65K\),减少了超过99%。
让我们来看一下在原生PyTorch中LoRA的最小实现。
import torch
from torch import nn
class LoRALinear(nn.Module):
def __init__(
self,
in_dim: int,
out_dim: int,
rank: int,
alpha: float,
dropout: float
):
# These are the weights from the original pretrained model
self.linear = nn.Linear(in_dim, out_dim, bias=False)
# These are the new LoRA params. In general rank << in_dim, out_dim
self.lora_a = nn.Linear(in_dim, rank, bias=False)
self.lora_b = nn.Linear(rank, out_dim, bias=False)
# Rank and alpha are commonly-tuned hyperparameters
self.rank = rank
self.alpha = alpha
# Most implementations also include some dropout
self.dropout = nn.Dropout(p=dropout)
# The original params are frozen, and only LoRA params are trainable.
self.linear.weight.requires_grad = False
self.lora_a.weight.requires_grad = True
self.lora_b.weight.requires_grad = True
def forward(self, x: torch.Tensor) -> torch.Tensor:
# This would be the output of the original model
frozen_out = self.linear(x)
# lora_a projects inputs down to the much smaller self.rank,
# then lora_b projects back up to the output dimension
lora_out = self.lora_b(self.lora_a(self.dropout(x)))
# Finally, scale by the alpha parameter (normalized by rank)
# and add to the original model's outputs
return frozen_out + (self.alpha / self.rank) * lora_out
这里我们省略了一些关于初始化的其他细节,但如果您想了解更多,可以查看我们在LoRALinear中的实现。现在我们已经了解了LoRA的作用,让我们看看如何将其应用到我们最喜欢的模型中。
将LoRA应用于Llama2模型¶
使用torchtune,我们可以轻松地将LoRA应用于Llama2,并采用各种不同的配置。 让我们来看看如何在torchtune中构建带有和不带有LoRA的Llama2模型。
from torchtune.models.llama2 import llama2_7b, lora_llama2_7b
# Build Llama2 without any LoRA layers
base_model = llama2_7b()
# The default settings for lora_llama2_7b will match those for llama2_7b
# We just need to define which layers we want LoRA applied to.
# Within each self-attention, we can choose from ["q_proj", "k_proj", "v_proj", and "output_proj"].
# We can also set apply_lora_to_mlp=True or apply_lora_to_output=True to apply LoRA to other linear
# layers outside of the self-attention.
lora_model = lora_llama2_7b(lora_attn_modules=["q_proj", "v_proj"])
注意
单独调用 lora_llama_2_7b 不会处理哪些参数是可训练的定义。
请参阅 下方 了解如何执行此操作。
让我们更仔细地检查这些模型中的每一个。
# Print the first layer's self-attention in the usual Llama2 model
>>> print(base_model.layers[0].attn)
MultiHeadAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(output_proj): Linear(in_features=4096, out_features=4096, bias=False)
(pos_embeddings): RotaryPositionalEmbeddings()
)
# Print the same for Llama2 with LoRA weights
>>> print(lora_model.layers[0].attn)
MultiHeadAttention(
(q_proj): LoRALinear(
(dropout): Dropout(p=0.0, inplace=False)
(lora_a): Linear(in_features=4096, out_features=8, bias=False)
(lora_b): Linear(in_features=8, out_features=4096, bias=False)
)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): LoRALinear(
(dropout): Dropout(p=0.0, inplace=False)
(lora_a): Linear(in_features=4096, out_features=8, bias=False)
(lora_b): Linear(in_features=8, out_features=4096, bias=False)
)
(output_proj): Linear(in_features=4096, out_features=4096, bias=False)
(pos_embeddings): RotaryPositionalEmbeddings()
)
请注意,我们的LoRA模型的层在Q和V投影中包含额外的权重,这是预期的。此外,检查lora_model和base_model的类型,会发现它们都是同一个TransformerDecoder的实例。(您可以自行验证这一点。)
为什么这很重要?torchtune 使得直接从我们的 Llama2 模型加载 LoRA 的检查点变得容易,无需任何包装器或自定义检查点转换逻辑。
# Assuming that base_model already has the pretrained Llama2 weights,
# this will directly load them into your LoRA model without any conversion necessary.
lora_model.load_state_dict(base_model.state_dict(), strict=False)
注意
每当使用strict=False加载权重时,您应该验证加载的state_dict中任何缺失或多余的键是否符合预期。torchtune的LoRA配方默认通过validate_missing_and_unexpected_for_lora()来完成此操作。
一旦我们加载了基础模型的权重,我们也希望仅将LoRA参数设置为可训练的。
from torchtune.modules.peft.peft_utils import get_adapter_params, set_trainable_params
# Fetch all params from the model that are associated with LoRA.
lora_params = get_adapter_params(lora_model)
# Set requires_grad=True on lora_params, and requires_grad=False on all others.
set_trainable_params(lora_model, lora_params)
# Print the total number of parameters
total_params = sum([p.numel() for p in lora_model.parameters()])
trainable_params = sum([p.numel() for p in lora_model.parameters() if p.requires_grad])
print(
f"""
{total_params} total params,
{trainable_params}" trainable params,
{(100.0 * trainable_params / total_params):.2f}% of all params are trainable.
"""
)
6742609920 total params,
4194304 trainable params,
0.06% of all params are trainable.
注意
如果您直接使用LoRA配方(如此处所述),您只需传递相关的检查点路径。加载模型权重和设置可训练参数将在配方中处理。
LoRA 微调配方在 torchtune 中¶
最后,我们可以将所有内容整合在一起,并使用torchtune的LoRA配方微调模型。 确保您已按照这些说明下载了Llama2的权重和分词器。 然后,您可以运行以下命令,使用两个GPU(每个GPU的VRAM至少为16GB)对Llama2-7B进行LoRA微调:
tune run --nnodes 1 --nproc_per_node 2 lora_finetune_distributed --config llama2/7B_lora
注意
请确保指向您的Llama2权重和分词器的位置。这可以通过添加checkpointer.checkpoint_files=[my_model_checkpoint_path] tokenizer_checkpoint=my_tokenizer_checkpoint_path
或直接修改7B_lora.yaml文件来完成。有关如何轻松克隆和修改torchtune配置的更多详细信息,请参阅我们的“”关于配置的一切”配方。
注意
你可以根据(a)你拥有的GPU数量,以及(b)你硬件的内存限制来修改nproc_per_node的值。
前面的命令将使用torchtune的默认设置运行LoRA微调,但我们可能想进行一些实验。
让我们更详细地看一下lora_finetune_distributed配置。
# Model Arguments
model:
_component_: lora_llama2_7b
lora_attn_modules: ['q_proj', 'v_proj']
lora_rank: 8
lora_alpha: 16
...
我们看到默认情况下是将LoRA应用于Q和V投影,秩为8。
一些使用LoRA的实验发现,将其应用于自注意力中的所有线性层,并将秩增加到16或32可能是有益的。请注意,这可能会增加我们的最大内存,
但只要我们保持rank<,影响应该相对较小。
让我们运行这个实验。我们也可以增加alpha(通常来说,同时缩放alpha和rank是一个好的做法)。
tune run --nnodes 1 --nproc_per_node 2 lora_finetune_distributed --config llama2/7B_lora \
lora_attn_modules=['q_proj','k_proj','v_proj','output_proj'] \
lora_rank=32 lora_alpha=64 output_dir=./lora_experiment_1
下面可以看到本次运行与基线在前500步的(平滑)损失曲线的比较。

注意
上图是使用W&B生成的。你可以使用torchtune的WandBLogger来生成类似的损失曲线,但你需要单独安装W&B并设置一个账户。有关在torchtune中使用W&B的更多详细信息,请参阅我们的“记录到Weights & Biases”教程。
使用LoRA在内存和模型性能之间进行权衡¶
在前面的例子中,我们在两个设备上运行了LoRA。但考虑到LoRA的低内存占用,我们可以在支持bfloat16浮点格式的大多数商用GPU上使用单个设备进行微调。这可以通过以下命令完成:
tune run lora_finetune_single_device --config llama2/7B_lora_single_device
在单个设备上,我们可能需要更加注意我们的峰值内存。让我们运行一些实验来查看在微调期间的峰值内存。我们将沿着两个轴进行实验:首先,哪些模型层应用了LoRA,其次,每个LoRA层的秩。(如上所述,我们将按比例调整alpha与LoRA秩。)
为了比较我们实验的结果,我们可以在truthfulqa_mc2上评估我们的模型,这是来自TruthfulQA基准测试的一个任务,用于语言模型。有关如何使用torchtune的EleutherAI评估工具集成运行此任务及其他评估任务的更多详细信息,请参阅我们的端到端工作流程教程。
之前,我们只在每个自注意力模块的线性层中启用了LoRA,但实际上我们还可以在其他线性层中应用LoRA:MLP层和模型的最终输出投影。请注意,对于Llama-2-7B,最终输出投影映射到词汇维度(32000,而不是其他线性层中的4096),因此在此层启用LoRA会比在其他层中稍微增加我们的峰值内存。我们可以对配置进行以下更改:
# Model Arguments
model:
_component_: lora_llama2_7b
lora_attn_modules: ['q_proj', 'k_proj', 'v_proj', 'output_proj']
apply_lora_to_mlp: True
apply_lora_to_output: True
...
注意
以下所有的微调运行都使用了llama2/7B_lora_single_device配置,该配置的默认批量大小为2。修改批量大小(或其他超参数,例如优化器)将影响峰值内存和最终评估结果。
LoRA 层 |
排名 |
阿尔法 |
峰值内存 |
准确率 (truthfulqa_mc2) |
|---|---|---|---|---|
仅限Q和V |
8 |
16 |
15.57 GB |
0.475 |
所有层 |
8 |
16 |
15.87 GB |
0.508 |
仅限Q和V |
64 |
128 |
15.86 GB |
0.504 |
所有层 |
64 |
128 |
17.04 GB |
0.514 |
我们可以看到,我们的基线设置提供了最低的峰值内存,但我们的评估性能相对较低。 通过为所有线性层启用LoRA并将秩增加到64,我们在这个任务上的准确率几乎提高了4%,但我们的峰值内存也增加了约1.4GB。这些只是几个简单的实验;我们鼓励您运行自己的微调,以找到适合您特定设置的权衡。
此外,如果您想进一步减少模型的峰值内存(并且仍然可能获得相似的模型质量结果),您可以查看我们的QLoRA教程。
