
Spark 服务
一个用于将Spark作业部署为分布式Web服务的引擎
- 分布式: 充分利用了Spark著名的Node、JVM和线程级别的并行性。
- 快速:没有单节点瓶颈,无需往返Python。请求可以通过网络交换机直接路由到工作JVM或从工作JVM路由。在几秒钟内启动一个网络服务。
- 低延迟: 使用连续服务时,可以实现低至1毫秒的延迟。
- 可部署在任何地方: 可以在任何运行Spark的地方工作,例如 Databricks、HDInsight、AZTK、DSVMs、本地或您自己的 集群。可以从Spark、PySpark和SparklyR使用。
- 轻量级:不依赖昂贵的Kafka或Kubernetes集群。
- 惯用: 使用与批处理和结构化流处理相同的API。
- 灵活:在单个Spark集群上启动和管理多个服务。同步和异步服务管理以及可扩展性。部署任何可表示为结构化流查询的Spark作业。使用服务源/汇与其他Spark数据源/汇进行更复杂的部署。
用法
Jupyter Notebook 示例
- 部署一个在成人人口普查数据集上训练的分类器
- 更多内容即将推出!
Spark Serving 你好世界
import synapse.ml
import pyspark
from pyspark.sql.functions import udf, col, length
from pyspark.sql.types import *
df = spark.readStream.server() \
.address("localhost", 8888, "my_api") \
.load() \
.parseRequest(StructType().add("foo", StringType()).add("bar", IntegerType()))
replies = df.withColumn("fooLength", length(col("foo")))\
.makeReply("fooLength")
server = replies\
.writeStream \
.server() \
.replyTo("my_api") \
.queryName("my_query") \
.option("checkpointLocation", "file:///path/to/checkpoints") \
.start()
使用CNTKModel部署深度网络
import synapse.ml
from synapse.ml.cntk import CNTKModel
import pyspark
from pyspark.sql.functions import udf, col
df = spark.readStream.server() \
.address("localhost", 8888, "my_api")
.load()
.parseRequest(<Insert your models input schema here>)
# See notebook examples for how to create and save several
# examples of CNTK models
network = CNTKModel.load("file:///path/to/my_cntkmodel.mml")
transformed_df = network.transform(df).makeReply(<Whatever column you wish to send back>)
server = transformed_df \
.writeStream \
.server() \
.replyTo("my_api") \
.queryName("my_query") \
.option("checkpointLocation", "file:///path/to/checkpoints") \
.start()
架构
Spark Serving 添加了特殊的流式源和接收器,将任何结构化流作业转变为网络服务。Spark Serving 提供了两种部署选项,这些选项根据所使用的负载均衡形式而有所不同。
简而言之,你可以使用:
spark.readStream.server():用于头节点负载均衡服务
spark.readStream.distributedServer():用于自定义负载均衡服务
spark.readStream.continuousServer():用于自定义负载均衡、亚毫秒延迟的连续服务器
创建各种不同的服务数据帧,并在df.writeStream之后使用等效语句来响应网络请求。
主节点负载均衡
您可以使用HTTPSource和HTTPSink类部署头节点负载均衡。此模式在头节点上启动一个队列,将工作分配到各个分区,然后将响应数据收集回头节点。所有HTTP请求都在头节点上保持并回复。在Python和Scala中,这些类可以通过在导入SynapseML后使用spark.readStream.server()来访问。此模式允许更复杂的窗口操作、重新分区和SQL操作。此选项也非常适合快速设置和测试,因为它不需要任何进一步的负载均衡或网络交换机。此配置的图示可以在以下图像中看到:
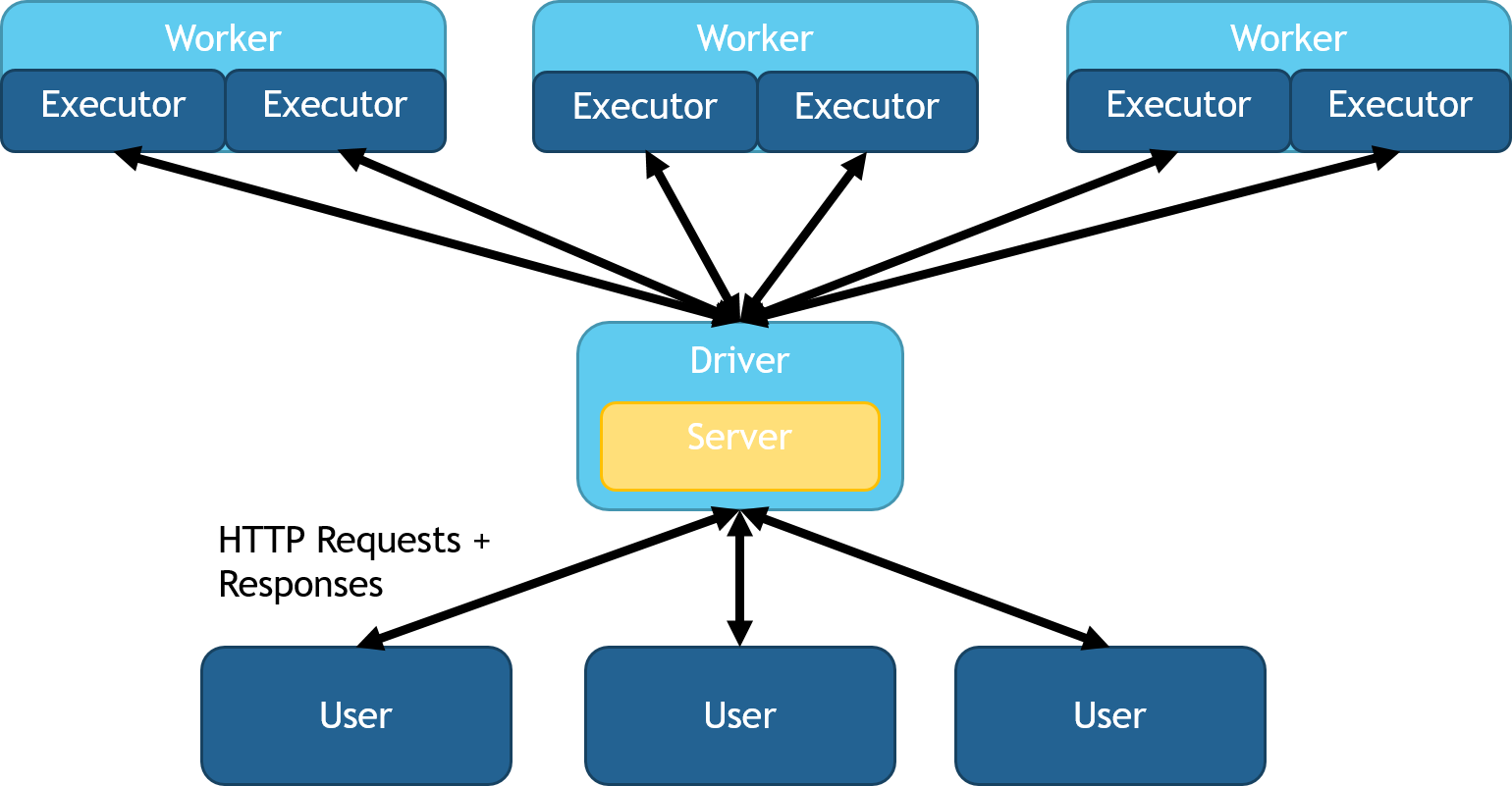
完全分布式(自定义负载均衡器)
您可以使用DistributedHTTPSource和DistributedHTTPSink类为自定义负载均衡器配置Spark Serving。此模式在每个执行器JVM上启动服务器。在Python和Scala中,这些类可以通过在导入SynapseML后使用spark.readStream.distributedServer()来访问。每个服务器将并行地提供其执行器的分区。此模式对于高吞吐量和低延迟至关重要,因为数据不需要在头节点之间传输。此部署会产生多个Web服务,这些服务都路由到相同的Spark计算中。您可以部署一个外部负载均衡器,将执行器的服务统一在一个IP地址下。对自动负载均衡器管理和部署的支持计划在SynapseML的下一个版本中提供。此配置的图示如下:
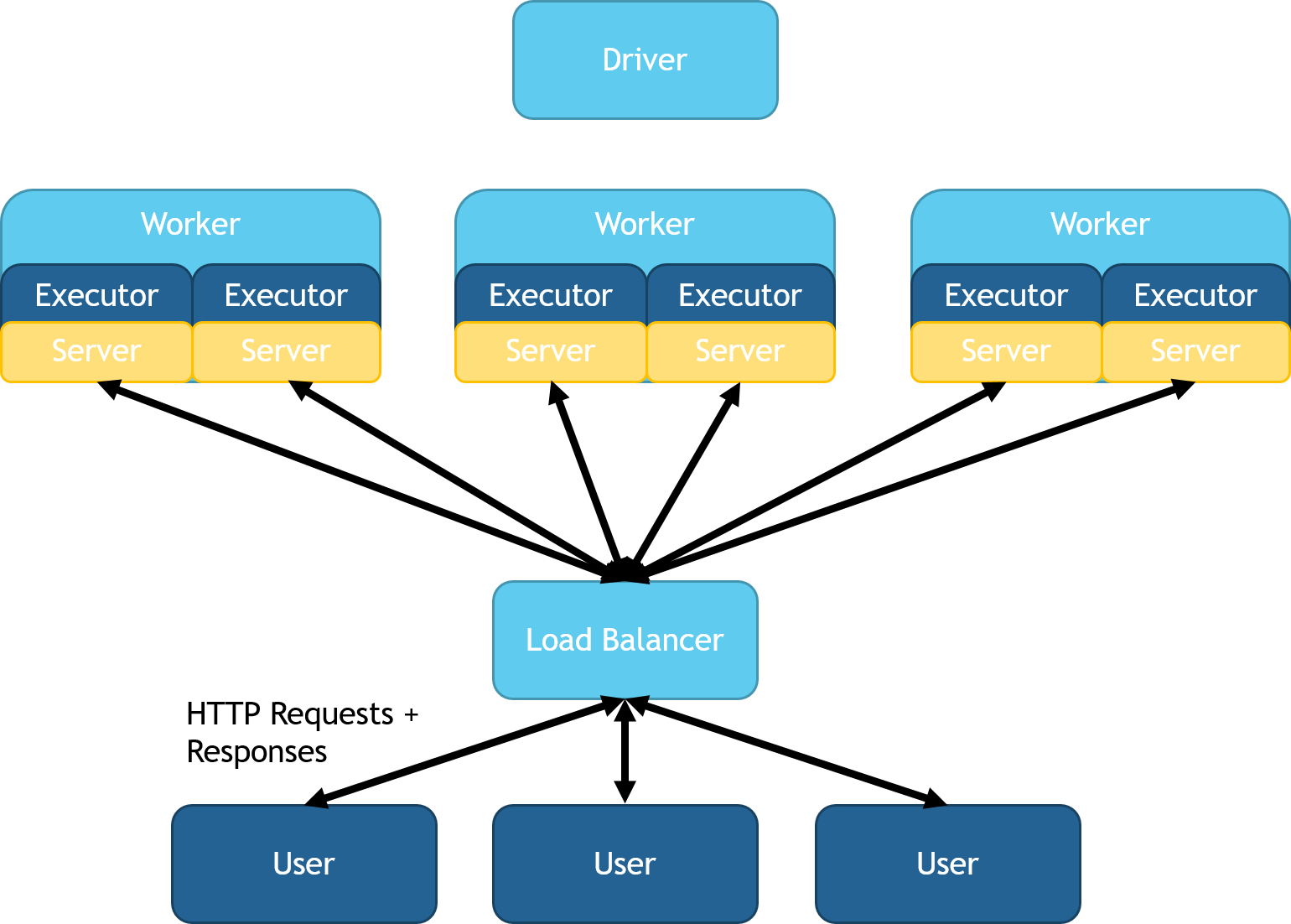
涉及跨工作节点数据移动的查询,如非平凡的SQL连接,需要特别考虑。用户必须确保每台机器都能正确响应每个请求。可以通过广播连接将数据路由回原始分区。将来,请求路由将由接收器自动处理。
亚毫秒延迟与连续处理
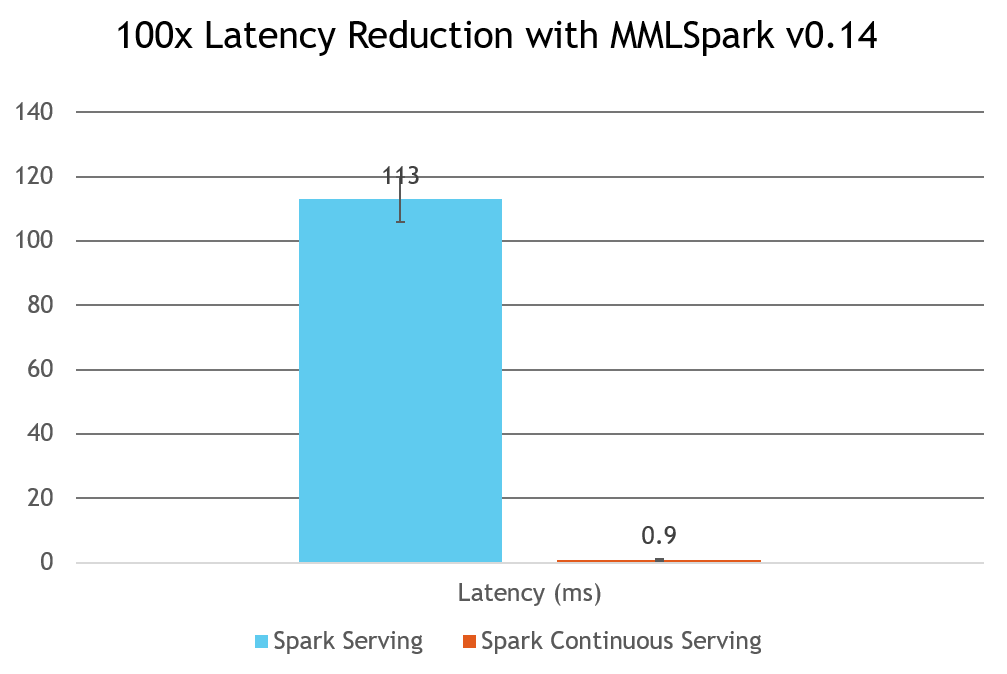
可以通过使用HTTPSourceV2类来启用连续处理:
spark.readStream.continuousServer()
...
在连续服务中,就像连续流式传输一样,您需要为写入语句添加一个触发器:
df.writeStream
.continuousServer()
.trigger(continuous="1 second")
...
该架构类似于之前描述的自定义负载均衡器设置。 更具体地说,Spark 将在每个分区上管理一个 web 服务。 这些 web 服务可以使用 Azure 负载均衡器、 Kubernetes 服务端点、Azure 应用程序网关或任何其他负载均衡分布式服务的方式统一起来。 目前,用户有责任根据需要选择性地统一这些服务。 未来,我们将提供动态启动和管理负载均衡器的选项。
Databricks 设置
Databricks 是一个托管架构,他们限制了所有进入集群节点的流量。如果您在 Databricks 集群(头节点或工作节点)中创建了一个 Web 服务,您的集群可以与该服务通信,但外部世界无法访问。然而,未来 Databricks 将支持虚拟网络注入,因此问题将不会出现。在此期间,您必须使用 SSH 隧道将服务转发到另一台机器作为网络网关。这台机器可以是任何接受 SSH 流量和请求的机器。为了方便起见,我们已经包含了自动配置此 SSH 隧道的设置。
Linux 网关设置 - Azure
- 使用SSH创建Linux虚拟机
- 从Azure门户打开端口8000-9999
- 在虚拟机上打开防火墙端口
firewall-cmd --zone=public --add-port=8000-10000/tcp --permanent
firewall-cmd --reload
echo "GatewayPorts yes" >> /etc/ssh/sshd_config
service ssh --full-restart - 将您的私钥添加到Azure Storage Blob中的私有容器中。
- 为您的密钥生成一个SAS链接并保存它。
- 在您的读取器上包含以下参数以配置SSH隧道: serving_inputs = (spark.readStream.continuousServer() .option("numPartitions", 1) .option("forwarding.enabled", True) # 启用SSH转发到网关机器 .option("forwarding.username", "username") .option("forwarding.sshHost", "ip or dns") .option("forwarding.keySas", "SAS url from the previous step") .address("localhost", 8904, "my_api") .load()
此设置将使您的服务需要额外的跳转并影响延迟。 选择一个与您的Spark集群连接良好的网关非常重要。 为了获得最佳性能和配置简便性,我们建议在开放集群环境(如Kubernetes、Mesos或Azure Batch)上使用Spark Serving。
参数
| 参数名称 | 描述 | 是否必需 | 默认值 | 适用场景 |
|---|---|---|---|---|
| host | 启动服务器的主机 | 是 | ||
| port | 创建Web服务时的起始端口。Web服务将多次递增此端口以找到一个开放的端口。未来,此参数的灵活性将得到扩展 | yes | ||
| name | 用户调用的API路径。格式为hostname:port/name | yes | ||
| forwarding.enabled | 是否将服务转发到网关机器 | no | false | 当你需要将服务转发出受保护的网络时。仅支持持续服务。 |
| forwarding.username | 远程主机上连接的用户名 | no | ||
| forwarding.sshport | 用于SSH连接的端口 | no | 22 | |
| forwarding.sshHost | 网关机器的主机 | no | ||
| forwarding.keySas | 一个安全访问链接,可用于自动下载所需的ssh私钥 | no | 有时比目录更方便 | |
| forwarding.keyDir | 存放私钥的机器上的目录 | no | "~/.ssh" | 如果您无法安全地通过网络发送密钥,这将非常有用 |