概述
什么是MLflow
MLflow 是一个简化机器学习开发的平台,包括跟踪实验、将代码打包成可重复运行的包,以及共享和部署模型。MLflow 提供了一组轻量级的 API,可以与任何现有的机器学习应用程序或库一起使用,例如 TensorFlow、PyTorch、XGBoost 等。它可以在你当前运行 ML 代码的任何地方运行,例如在笔记本、独立应用程序或云端。MLflow 当前的组件包括:
- MLflow Tracking: 一个API,用于记录机器学习实验中的参数、代码和结果,并使用交互式UI进行比较。
- MLflow Projects: 一种使用Conda和Docker进行可重复运行的代码打包格式,因此您可以与他人分享您的ML代码。
- MLflow Models: 一种模型打包格式和工具,使您能够轻松地从任何机器学习库部署相同的模型,用于批处理和实时评分。它支持诸如Docker、Apache Spark、Azure ML和AWS SageMaker等平台。
- MLflow Model Registry: 一个集中的模型存储库,一组API和用户界面,用于协作管理MLflow模型的全生命周期。
安装
通过 pip install mlflow 从 PyPI 安装 MLflow
MLflow 要求 conda 在 PATH 上以便使用项目功能。
了解更多关于MLflow的信息,请访问他们的GitHub页面。
在Databricks上安装Mlflow
如果您正在使用Databricks,请使用以下命令安装Mlflow:
# run this so that Mlflow is installed on workers besides driver
%pip install mlflow
在Synapse上安装Mlflow
要使用Mlflow记录模型,您需要创建一个Azure机器学习工作区并将其与您的Synapse工作区链接。
创建 Azure 机器学习工作区
按照此文档创建AML工作区。您不需要创建计算实例和计算集群。
创建一个Azure ML链接服务
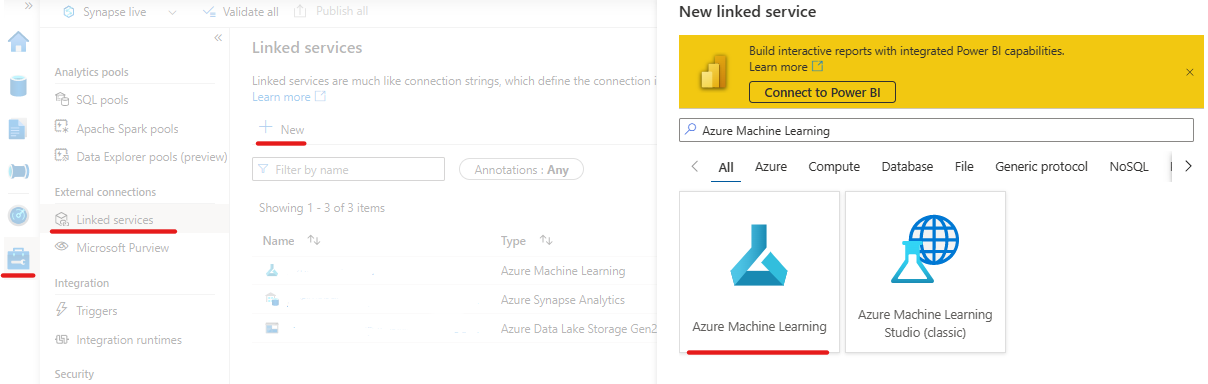
- 在 Synapse 工作区中,转到 管理 -> 外部连接 -> 链接服务,选择 + 新建
- 选择您想要记录模型的工作区并创建链接服务。您需要链接服务的名称来设置连接。
授权Synapse工作区
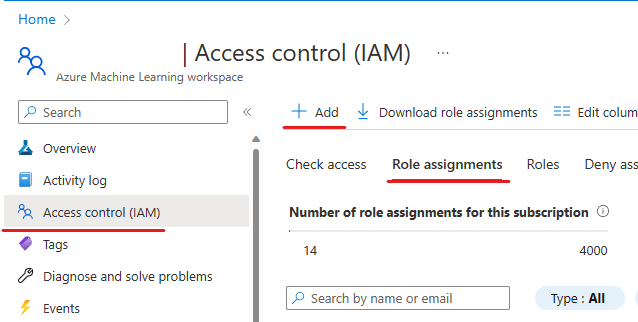
- 转到Azure Machine Learning workspace资源 -> 访问控制 (IAM) -> 角色分配,选择+ 添加,选择添加角色分配
- 选择贡献者,然后选择下一步
- 在成员页面中,选择托管身份,然后选择+ 选择成员。在托管身份下,选择Synapse工作区。在选择下,选择您运行实验的工作区。点击选择,审查 + 分配。
在Synapse中使用MLFlow与链接服务
设置连接
#AML workspace authentication using linked service
from notebookutils.mssparkutils import azureML
linked_service_name = "YourLinkedServiceName"
ws = azureML.getWorkspace(linked_service_name)
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
#Set MLflow experiment.
experiment_name = "synapse-mlflow-experiment"
mlflow.set_experiment(experiment_name)
在没有链接服务的情况下在Synapse中使用MLFlow
一旦你创建了一个AML工作区,你可以直接获取MLflow跟踪URL。AML起始页面是你找到MLflow跟踪URL的地方。
MLFlow API 参考
示例
LightGBM分类器
import mlflow
from synapse.ml.featurize import Featurize
from synapse.ml.lightgbm import *
from synapse.ml.train import ComputeModelStatistics
with mlflow.start_run():
feature_columns = ["Number of times pregnant","Plasma glucose concentration a 2 hours in an oral glucose tolerance test",
"Diastolic blood pressure (mm Hg)","Triceps skin fold thickness (mm)","2-Hour serum insulin (mu U/ml)",
"Body mass index (weight in kg/(height in m)^2)","Diabetes pedigree function","Age (years)"]
df = spark.createDataFrame([
(0,131,66,40,0,34.3,0.196,22,1),
(7,194,68,28,0,35.9,0.745,41,1),
(3,139,54,0,0,25.6,0.402,22,1),
(6,134,70,23,130,35.4,0.542,29,1),
(9,124,70,33,402,35.4,0.282,34,0),
(0,93,100,39,72,43.4,1.021,35,0),
(4,110,76,20,100,28.4,0.118,27,0),
(2,127,58,24,275,27.7,1.6,25,0),
(0,104,64,37,64,33.6,0.51,22,1),
(2,120,54,0,0,26.8,0.455,27,0),
(7,178,84,0,0,39.9,0.331,41,1),
(2,88,58,26,16,28.4,0.766,22,0),
(1,91,64,24,0,29.2,0.192,21,0),
(10,101,76,48,180,32.9,0.171,63,0),
(5,73,60,0,0,26.8,0.268,27,0),
(3,158,70,30,328,35.5,0.344,35,1),
(2,105,75,0,0,23.3,0.56,53,0),
(12,84,72,31,0,29.7,0.297,46,1),
(9,119,80,35,0,29.0,0.263,29,1),
(6,93,50,30,64,28.7,0.356,23,0),
(1,126,60,0,0,30.1,0.349,47,1)
], feature_columns+["labels"]).repartition(2)
featurize = (Featurize()
.setOutputCol("features")
.setInputCols(feature_columns)
.setOneHotEncodeCategoricals(True)
.setNumFeatures(4096))
df_trans = featurize.fit(df).transform(df)
lightgbm_classifier = (LightGBMClassifier()
.setFeaturesCol("features")
.setRawPredictionCol("rawPrediction")
.setDefaultListenPort(12402)
.setNumLeaves(5)
.setNumIterations(10)
.setObjective("binary")
.setLabelCol("labels")
.setLeafPredictionCol("leafPrediction")
.setFeaturesShapCol("featuresShap"))
lightgbm_model = lightgbm_classifier.fit(df_trans)
# Use mlflow.spark.save_model to save the model to your path
mlflow.spark.save_model(lightgbm_model, "lightgbm_model")
# Use mlflow.spark.log_model to log the model if you have a connected mlflow service
mlflow.spark.log_model(lightgbm_model, "lightgbm_model")
# Use mlflow.pyfunc.load_model to load model back as PyFuncModel and apply predict
prediction = mlflow.pyfunc.load_model("lightgbm_model").predict(df_trans.toPandas())
prediction = list(map(str, prediction))
mlflow.log_param("prediction", ",".join(prediction))
# Use mlflow.spark.load_model to load model back as PipelineModel and apply transform
predictions = mlflow.spark.load_model("lightgbm_model").transform(df_trans)
metrics = ComputeModelStatistics(evaluationMetric="classification", labelCol='labels', scoredLabelsCol='prediction').transform(predictions).collect()
mlflow.log_metric("accuracy", metrics[0]['accuracy'])
Azure AI 服务
import mlflow
from synapse.ml.services import *
with mlflow.start_run():
text_key = "YOUR_COG_SERVICE_SUBSCRIPTION_KEY"
df = spark.createDataFrame([
("I am so happy today, its sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The cognitive services on spark aint bad", "en-US"),
], ["text", "language"])
sentiment_model = (TextSentiment()
.setSubscriptionKey(text_key)
.setLocation("eastus")
.setTextCol("text")
.setOutputCol("prediction")
.setErrorCol("error")
.setLanguageCol("language"))
display(sentiment_model.transform(df))
mlflow.spark.save_model(sentiment_model, "sentiment_model")
mlflow.spark.log_model(sentiment_model, "sentiment_model")
output_df = mlflow.spark.load_model("sentiment_model").transform(df)
display(output_df)
# In order to call the predict function successfully you need to specify the
# outputCol name as `prediction`
prediction = mlflow.pyfunc.load_model("sentiment_model").predict(df.toPandas())
prediction = list(map(str, prediction))
mlflow.log_param("prediction", ",".join(prediction))