!pip install -Uqq nixtla hierarchicalforecast层次预测
# 隐藏
from nixtla.utils import in_colabIN_COLAB = in_colab()if not IN_COLAB:
from nixtla.utils import colab_badge
from itertools import product
from fastcore.test import test_eq, test_fail, test_warns
from dotenv import load_dotenv 在预测中,我们常常需要同时获得低粒度和高粒度的预测,例如产品需求预测,甚至产品类别或产品部门的预测。这些粒度可以通过层次结构来形式化。在层次预测中,我们创建与预先指定的基础时间序列层次结构一致的预测。
通过TimeGPT,我们可以为多个时间序列创建预测。随后,我们可以使用HierarchicalForecast的层次预测技术对这些预测进行后处理。
if not IN_COLAB:
load_dotenv()
colab_badge('docs/tutorials/14_hierarchical_forecasting')![]()
1. 导入包
首先,我们导入所需的包并初始化Nixtla客户端。
import pandas as pd
import numpy as np
from nixtla import NixtlaClientnixtla_client = NixtlaClient(
# defaults to os.environ.get("NIXTLA_API_KEY")
api_key = 'my_api_key_provided_by_nixtla'
)👍 使用 Azure AI 端点
要使用 Azure AI 端点,请设置
base_url参数:
nixtla_client = NixtlaClient(base_url="你的 Azure AI 端点", api_key="你的 API 密钥")
if not IN_COLAB:
nixtla_client = NixtlaClient()2. 加载数据
我们使用澳大利亚旅游数据集,来自于 Forecasting, Principles and Practices,该数据集包含澳大利亚旅游的数据。我们对澳大利亚的7个州、27个区域和76个地区的预测感兴趣。这构成了一个层级结构,其中较低层级(如悉尼、蓝山和亨特地区)的预测应与较高层级(如新南威尔士州)的预测一致。

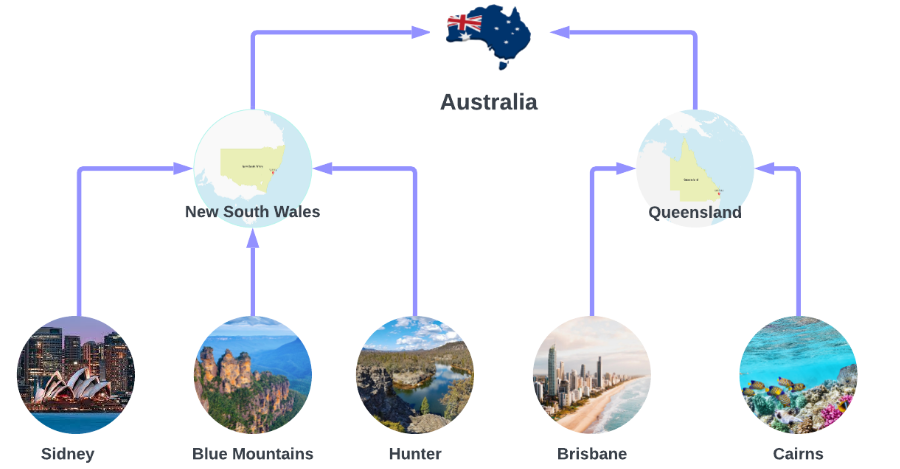
数据集仅包含最低层次的时间序列,因此我们需要为所有层次创建时间序列。
Y_df = pd.read_csv('https://raw.githubusercontent.com/Nixtla/transfer-learning-time-series/main/datasets/tourism.csv')
Y_df = Y_df.rename({'Trips': 'y', 'Quarter': 'ds'}, axis=1)
Y_df.insert(0, 'Country', 'Australia')
Y_df = Y_df[['Country', 'Region', 'State', 'Purpose', 'ds', 'y']]
Y_df['ds'] = Y_df['ds'].str.replace(r'(\d+) (Q\d)', r'\1-\2', regex=True)
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
Y_df.head(10)C:\Users\ospra\AppData\Local\Temp\ipykernel_28980\3753786659.py:6: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
Y_df['ds'] = pd.to_datetime(Y_df['ds'])| Country | Region | State | Purpose | ds | y | |
|---|---|---|---|---|---|---|
| 0 | Australia | Adelaide | South Australia | Business | 1998-01-01 | 135.077690 |
| 1 | Australia | Adelaide | South Australia | Business | 1998-04-01 | 109.987316 |
| 2 | Australia | Adelaide | South Australia | Business | 1998-07-01 | 166.034687 |
| 3 | Australia | Adelaide | South Australia | Business | 1998-10-01 | 127.160464 |
| 4 | Australia | Adelaide | South Australia | Business | 1999-01-01 | 137.448533 |
| 5 | Australia | Adelaide | South Australia | Business | 1999-04-01 | 199.912586 |
| 6 | Australia | Adelaide | South Australia | Business | 1999-07-01 | 169.355090 |
| 7 | Australia | Adelaide | South Australia | Business | 1999-10-01 | 134.357937 |
| 8 | Australia | Adelaide | South Australia | Business | 2000-01-01 | 154.034398 |
| 9 | Australia | Adelaide | South Australia | Business | 2000-04-01 | 168.776364 |
数据集可以按以下层级结构进行分组。
spec = [
['Country'],
['Country', 'State'],
['Country', 'Purpose'],
['Country', 'State', 'Region'],
['Country', 'State', 'Purpose'],
['Country', 'State', 'Region', 'Purpose']
]使用HierarchicalForecast中的aggregate函数,我们可以获得完整的时间序列集。
Note
您可以使用 pip 安装 hierarchicalforecast:
pip install hierarchicalforecastfrom hierarchicalforecast.utils import aggregateY_df, S_df, tags = aggregate(Y_df, spec)
Y_df = Y_df.reset_index()
Y_df.head(10)| unique_id | ds | y | |
|---|---|---|---|
| 0 | Australia | 1998-01-01 | 23182.197269 |
| 1 | Australia | 1998-04-01 | 20323.380067 |
| 2 | Australia | 1998-07-01 | 19826.640511 |
| 3 | Australia | 1998-10-01 | 20830.129891 |
| 4 | Australia | 1999-01-01 | 22087.353380 |
| 5 | Australia | 1999-04-01 | 21458.373285 |
| 6 | Australia | 1999-07-01 | 19914.192508 |
| 7 | Australia | 1999-10-01 | 20027.925640 |
| 8 | Australia | 2000-01-01 | 22339.294779 |
| 9 | Australia | 2000-04-01 | 19941.063482 |
我们使用最后两年(8个季度)作为测试集。
Y_test_df = Y_df.groupby('unique_id').tail(8)
Y_train_df = Y_df.drop(Y_test_df.index)3. 使用TimeGPT进行层次预测
首先,我们使用TimeGPT为所有时间序列创建基础预测。请注意,我们设置了add_history=True,因为我们需要TimeGPT的内部拟合值。
我们将从2016年01月01日开始预测2年(8个季度)。
timegpt_fcst = nixtla_client.forecast(df=Y_train_df, h=8, freq='QS', add_history=True)INFO:nixtla.nixtla_client:Validating inputs...
INFO:nixtla.nixtla_client:Preprocessing dataframes...
INFO:nixtla.nixtla_client:Calling Forecast Endpoint...
INFO:nixtla.nixtla_client:Calling Historical Forecast Endpoint...📘 Azure AI 中可用的模型
如果您使用的是 Azure AI 端点,请确保设置
model="azureai":
nixtla_client.forecast(..., model="azureai")对于公共 API,我们支持两种模型:
timegpt-1和timegpt-1-long-horizon。默认情况下,使用
timegpt-1。有关何时以及如何使用timegpt-1-long-horizon的信息,请参阅 本教程。
timegpt_fcst_insample = timegpt_fcst.query("ds < '2016-01-01'")
timegpt_fcst_outsample = timegpt_fcst.query("ds >= '2016-01-01'")让我们绘制一些预测,首先从最高的聚合水平(Australia)开始,到最低级别(Australia/Queensland/Brisbane/Holiday)。我们可以看到,在预测中仍有改进的空间。
nixtla_client.plot(
Y_df,
timegpt_fcst_outsample,
max_insample_length=4 * 12,
unique_ids=['Australia', 'Australia/Queensland','Australia/Queensland/Brisbane', 'Australia/Queensland/Brisbane/Holiday']
)
我们可以通过使用NeuralForecast中的HierarchicalReconciliation方法,使这些预测与指定的层级一致。我们将使用MinTrace方法。
from hierarchicalforecast.methods import MinTrace
from hierarchicalforecast.core import HierarchicalReconciliationreconcilers = [
MinTrace(method='ols'),
MinTrace(method='mint_shrink'),
]
hrec = HierarchicalReconciliation(reconcilers=reconcilers)
Y_df_with_insample_fcsts = Y_df.copy()
Y_df_with_insample_fcsts = timegpt_fcst_insample.merge(Y_df_with_insample_fcsts)
Y_df_with_insample_fcsts = Y_df_with_insample_fcsts.set_index('unique_id')
Y_rec_df = hrec.reconcile(Y_hat_df=timegpt_fcst_outsample.set_index('unique_id'), Y_df=Y_df_with_insample_fcsts, S=S_df, tags=tags)再次,我们绘制了一些预测图。我们可以看到预测中有一些小的差异。
nixtla_client.plot(
Y_df,
Y_rec_df.reset_index(),
max_insample_length=4 * 12,
unique_ids=['Australia', 'Australia/Queensland','Australia/Queensland/Brisbane', 'Australia/Queensland/Brisbane/Holiday']
)
让我们数值验证在不应用后处理步骤的情况下的预测情况。我们可以使用 HierarchicalEvaluation 来实现这一点。
from hierarchicalforecast.evaluation import HierarchicalEvaluationdef rmse(y, y_hat):
return np.mean(np.sqrt(np.mean((y-y_hat)**2, axis=1)))
eval_tags = {}
eval_tags['Total'] = tags['Country']
eval_tags['Purpose'] = tags['Country/Purpose']
eval_tags['State'] = tags['Country/State']
eval_tags['Regions'] = tags['Country/State/Region']
eval_tags['Bottom'] = tags['Country/State/Region/Purpose']
eval_tags['All'] = np.concatenate(list(tags.values()))
evaluator = HierarchicalEvaluation(evaluators=[rmse])
evaluation = evaluator.evaluate(
Y_hat_df=Y_rec_df.rename(columns={'y': 'TimeGPT'}), Y_test_df=Y_test_df.set_index('unique_id'),
tags=eval_tags, Y_df=Y_train_df.set_index('unique_id')
)
evaluation = evaluation.drop(labels='Overall', level='level')
evaluation.columns = ['Base', 'MinTrace(ols)', 'MinTrace(mint_shrink)']
evaluation = evaluation.map('{:.2f}'.format)evaluation| Base | MinTrace(ols) | MinTrace(mint_shrink) | ||
|---|---|---|---|---|
| level | metric | |||
| Total | rmse | 1433.14 | 1436.12 | 1639.77 |
| Purpose | rmse | 482.10 | 475.65 | 511.14 |
| State | rmse | 275.86 | 278.39 | 295.03 |
| Regions | rmse | 49.40 | 47.91 | 48.10 |
| Bottom | rmse | 19.32 | 19.11 | 18.87 |
| All | rmse | 43.00 | 42.50 | 43.54 |
通过将预测与 MinTrace(ols) 进行调和,我们在整体 RMSE 上取得了小幅改善,而使用 MinTrace(mint_shrink) 的结果却稍微变差,这表明基础预测本身已经相对强劲。
然而,我们现在也得到了连贯的预测——因此,不仅我们实现了(小幅)的准确性提升,作为调和步骤的结果,我们还实现了层次结构的一致性。
参考文献
Give us a ⭐ on Github