为何评估智能体
In traditional software development, unit tests and integration tests provide confidence that code functions as expected and remains stable through changes. These tests provide a clear "pass/fail" signal, guiding further development. However, LLM agents introduce a level of variability that makes traditional testing approaches insufficient.
由于模型的概率特性,确定性的"通过/失败"断言通常不适合评估智能体性能。相反,我们需要对最终输出和智能体的轨迹(即达到解决方案所采取的一系列步骤)进行定性评估。这包括评估智能体的决策质量、推理过程以及最终结果。
虽然看起来需要做很多额外工作来设置,但自动化评估的投入很快就会得到回报。如果你打算超越原型阶段,这是一个强烈推荐的最佳实践。
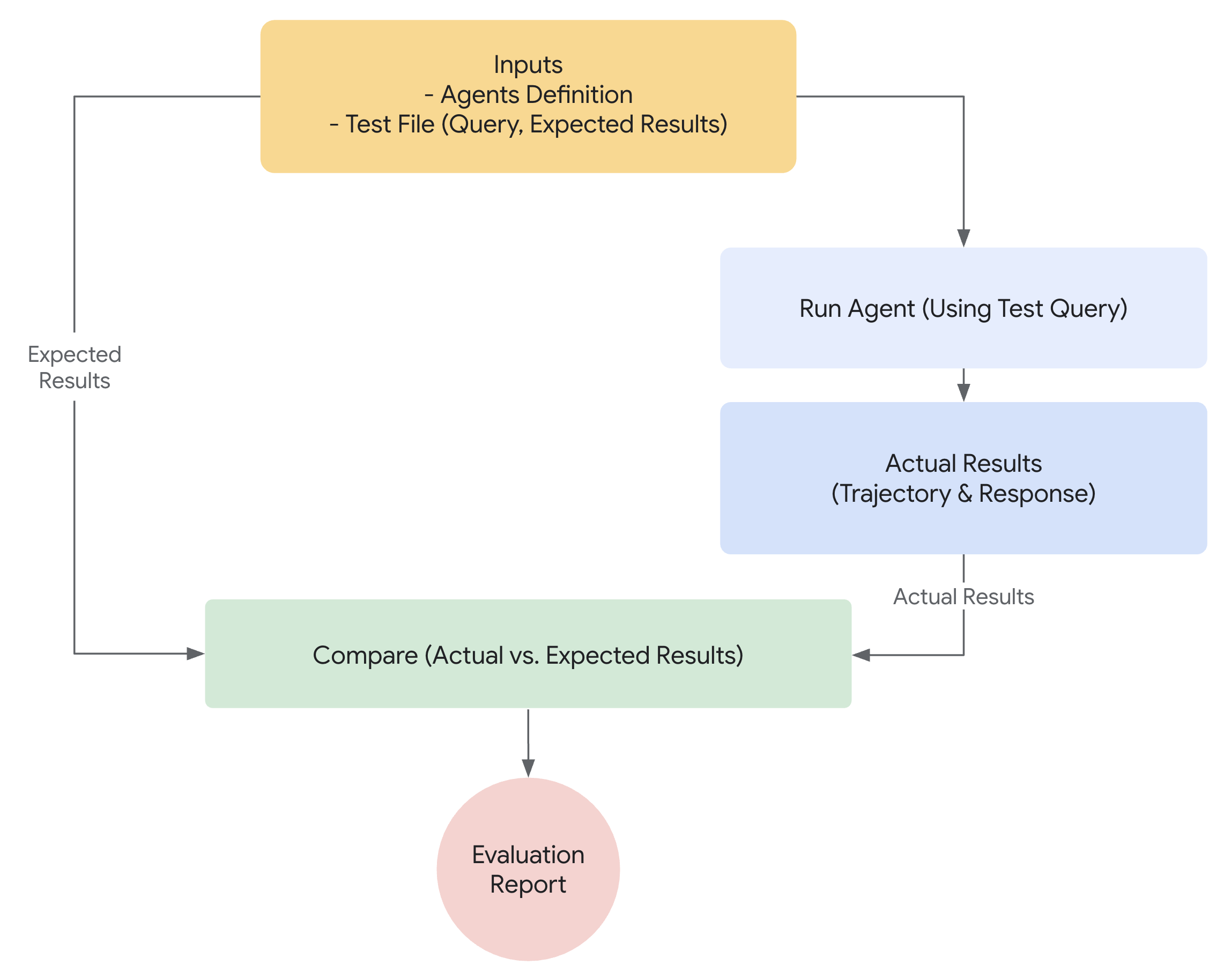
准备智能体评估
在自动化智能体评估之前,需明确目标和成功标准:
- 定义成功: 什么构成了你的智能体的成功结果?
- 识别关键任务:您的智能体必须完成哪些核心任务?
- 选择相关指标:您将跟踪哪些指标来衡量性能?
这些考虑因素将指导评估场景的创建,并实现对现实部署中智能体行为的有效监控。
评估什么?
为了弥合概念验证与生产就绪AI智能体之间的差距,一个稳健且自动化的评估框架至关重要。与评估生成模型主要关注最终输出不同,智能体评估需要更深入理解其决策过程。智能体评估可分为两个组成部分:
- 评估轨迹与工具使用:分析智能体为达成解决方案所采取的步骤,包括其工具选择、策略运用以及方法效率。
- 评估最终响应: 评估智能体最终输出的质量、相关性和正确性。
轨迹只是智能体在返回给用户之前所采取的一系列步骤。我们可以将其与预期智能体应采取的步骤列表进行对比。
评估轨迹和工具使用
在响应用户之前,智能体通常会执行一系列动作,我们称之为"轨迹"。它可能将用户输入与会话历史进行比较以消除术语歧义,或查找政策文档、搜索知识库,或调用API来保存工单。我们将这一系列动作称为"轨迹"。评估智能体的性能需要将其实际轨迹与预期或理想的轨迹进行比较。这种比较可以揭示智能体流程中的错误和低效之处。预期轨迹代表基准真相——即我们预期智能体应该采取的步骤列表。
例如:
// Trajectory evaluation will compare
expected_steps = ["determine_intent", "use_tool", "review_results", "report_generation"]
actual_steps = ["determine_intent", "use_tool", "review_results", "report_generation"]
存在多种基于真实轨迹的评估方法:
- 精确匹配:需要与理想轨迹完全匹配。
- 顺序匹配: 要求以正确的顺序执行正确的动作,允许额外的动作。
- 任意顺序匹配:要求以任意顺序执行正确的操作,允许额外的操作。
- 精确度:衡量预测动作的相关性/正确性。
- 召回率:衡量预测中捕获了多少关键动作。
- 单工具使用:检查是否包含特定操作。
选择合适的评估指标取决于智能体的具体需求和目标。例如,在高风险场景中,精确匹配可能至关重要,而在更灵活的情况下,顺序匹配或任意顺序匹配可能就足够了。
评估功能在Agent Development Kit中的工作原理
ADK提供了两种方法来根据预定义数据集和评估标准评估智能体性能。虽然概念上相似,但它们处理的数据量不同,这通常决定了每种方法的适用场景。
第一种方法:使用测试文件
这种方法涉及创建单独的测试文件,每个文件代表一个简单的人机交互会话(session)。它在智能体开发过程中最为有效,可作为单元测试的一种形式。这些测试设计用于快速执行,应专注于简单的会话复杂度。每个测试文件包含一个会话,可能由多个轮次组成。一个轮次代表用户与智能体之间的单次交互。每个轮次包括
query:这是用户的查询。expected_tool_use: 我们期望智能体为正确响应用户query而进行的工具调用。expected_intermediate_agent_responses: 该字段包含智能体在生成最终答案过程中产生的自然语言响应。这些响应在多智能体系统中很常见,其中根智能体依赖子智能体来完成任务。虽然通常与最终用户没有直接关系,但这些中间响应对开发人员很有价值。它们能帮助理解智能体的推理路径,并验证其是否遵循了正确的步骤来生成最终响应。reference: 模型预期的最终响应。
你可以为文件指定任意名称,例如evaluation.test.json。该框架仅检查.test.json后缀,文件名前面的部分不受限制。以下是一个包含几个示例的测试文件:
[
{
"query": "hi",
"expected_tool_use": [],
"expected_intermediate_agent_responses": [],
"reference": "Hello! What can I do for you?\n"
},
{
"query": "roll a die for me",
"expected_tool_use": [
{
"tool_name": "roll_die",
"tool_input": {
"sides": 6
}
}
],
"expected_intermediate_agent_responses": [],
},
{
"query": "what's the time now?",
"expected_tool_use": [],
"expected_intermediate_agent_responses": [],
"reference": "I'm sorry, I cannot access real-time information, including the current time. My capabilities are limited to rolling dice and checking prime numbers.\n"
}
]
测试文件可以组织到文件夹中。可选地,文件夹也可以包含一个test_config.json文件,用于指定评估标准。
第二种方法:使用评估集文件
评估集方法采用一个名为"evalset"的专用数据集来评估智能体与模型的交互。类似于测试文件,评估集包含示例交互。然而,评估集可以包含多个可能较长的会话,因此非常适合模拟复杂的多轮对话。由于其能够表示复杂会话的特性,评估集非常适合集成测试。由于这些测试通常涉及范围更广,因此运行频率通常低于单元测试。
一个评估集文件包含多个"评估项",每个评估项代表一个独立的会话。每个评估项由一个或多个"轮次"组成,这些轮次包括用户查询、预期工具使用、预期的智能体中间响应以及参考响应。这些字段的含义与测试文件方法中的相同。每个评估项通过唯一名称进行标识。此外,每个评估项还包含关联的初始会话状态。
手动创建评估集可能较为复杂,因此我们提供了UI工具来帮助捕获相关会话,并轻松将其转换为评估集中的评估项。以下将详细介绍如何使用网页UI进行评估。这是一个包含两个会话的评估集示例。
[
{
"name": "roll_16_sided_dice_and_then_check_if_6151953_is_prime",
"data": [
{
"query": "What can you do?",
"expected_tool_use": [],
"expected_intermediate_agent_responses": [],
"reference": "I can roll dice of different sizes and check if a number is prime. I can also use multiple tools in parallel.\n"
},
{
"query": "Roll a 16 sided dice for me",
"expected_tool_use": [
{
"tool_name": "roll_die",
"tool_input": {
"sides": 16
}
}
],
"expected_intermediate_agent_responses": [],
"reference": "I rolled a 16 sided die and got 13.\n"
},
{
"query": "Is 6151953 a prime number?",
"expected_tool_use": [
{
"tool_name": "check_prime",
"tool_input": {
"nums": [
6151953
]
}
}
],
"expected_intermediate_agent_responses": [],
"reference": "No, 6151953 is not a prime number.\n"
}
],
"initial_session": {
"state": {},
"app_name": "hello_world",
"user_id": "user"
}
},
{
"name": "roll_17_sided_dice_twice",
"data": [
{
"query": "What can you do?",
"expected_tool_use": [],
"expected_intermediate_agent_responses": [],
"reference": "I can roll dice of different sizes and check if a number is prime. I can also use multiple tools in parallel.\n"
},
{
"query": "Roll a 17 sided dice twice for me",
"expected_tool_use": [
{
"tool_name": "roll_die",
"tool_input": {
"sides": 17
}
},
{
"tool_name": "roll_die",
"tool_input": {
"sides": 17
}
}
],
"expected_intermediate_agent_responses": [],
"reference": "I have rolled a 17 sided die twice. The first roll was 13 and the second roll was 4.\n"
}
],
"initial_session": {
"state": {},
"app_name": "hello_world",
"user_id": "user"
}
}
]
评估标准
评估标准定义了如何根据评估集来衡量智能体的性能。支持以下指标:
tool_trajectory_avg_score: 该指标将智能体在评估期间的实际工具使用情况与expected_tool_use字段中定义的预期工具使用情况进行比较。每个匹配的工具使用步骤得分为1,不匹配的得分为0。最终得分是这些匹配的平均值,代表工具使用轨迹的准确性。response_match_score: 该指标将智能体的最终自然语言响应与存储在reference字段中的预期最终响应进行比较。我们使用ROUGE指标来计算两个响应之间的相似度。
如果未提供评估标准,则使用以下默认配置:
tool_trajectory_avg_score: 默认为1.0,要求工具使用轨迹100%匹配。response_match_score: 默认值为0.8,允许智能体的自然语言响应存在小范围的误差。
以下是一个指定自定义评估标准的test_config.json文件示例:
如何使用ADK运行评估
作为开发者,您可以通过以下方式使用ADK评估您的智能体:
- 基于Web的用户界面 (
adk web): 通过基于网页的界面交互式评估智能体。 - 编程方式 (
pytest): 使用pytest和测试文件将评估集成到您的测试流程中。 - 命令行界面 (
adk eval): 直接从命令行对现有评估集文件运行评估。
1. adk web - 通过网页界面运行评估
网页用户界面提供了一种交互式方法来评估智能体并生成评估数据集。
通过网页界面运行评估的步骤:
- 通过运行以下命令启动网络服务器:
bash adk web samples_for_testing - In the web interface:
- 选择一个智能体(例如:
hello_world)。 - 与智能体交互以创建一个您想保存为测试用例的会话。
- 点击界面右侧的“评估标签页”。
- 如果您已拥有现有的评估集,请选择该评估集或点击"创建新评估集"按钮新建一个。为您的评估集指定一个具有上下文意义的名称。然后选择新创建的评估集。
- 点击"添加当前会话"将当前会话保存为评估集文件中的一个评估项。系统会要求您为此评估命名,请再次为其提供一个有上下文意义的名称。
- 创建完成后,新创建的评估将出现在评估集文件的可用评估列表中。您可以运行全部或选择特定评估来执行。
- 每次评估的状态将在用户界面中显示。
- 选择一个智能体(例如:
2. pytest - 以编程方式运行测试
你也可以使用pytest来运行测试文件作为集成测试的一部分。
示例命令
示例测试代码
以下是一个运行单个测试文件的pytest测试用例示例:
def test_with_single_test_file():
"""Test the agent's basic ability via a session file."""
AgentEvaluator.evaluate(
agent_module="tests.integration.fixture.home_automation_agent",
eval_dataset="tests/integration/fixture/home_automation_agent/simple_test.test.json",
)
这种方法允许您将智能体评估集成到您的CI/CD流水线或更大的测试套件中。如果您想为测试指定初始会话状态,可以通过将会话详细信息存储在文件中并将其传递给AgentEvaluator.evaluate方法来实现。
这是一个示例会话json文件:
{
"id": "test_id",
"app_name": "trip_planner_agent",
"user_id": "test_user",
"state": {
"origin": "San Francisco",
"interests": "Moutains, Hikes",
"range": "1000 miles",
"cities": ""
},
"events": [],
"last_update_time": 1741218714.258285
}
示例代码将如下所示:
def test_with_single_test_file():
"""Test the agent's basic ability via a session file."""
AgentEvaluator.evaluate(
agent_module="tests.integration.fixture.trip_planner_agent",
eval_dataset="tests/integration/fixture/trip_planner_agent/simple_test.test.json",
initial_session_file="tests/integration/fixture/trip_planner_agent/initial.session.json"
)
3. adk eval - 通过命令行运行评估
您也可以通过命令行界面(CLI)运行评估集文件的评估。这与在UI上运行的评估相同,但有助于实现自动化,例如您可以将此命令作为常规构建生成和验证流程的一部分。
以下是命令:
adk eval \
<AGENT_MODULE_FILE_PATH> \
<EVAL_SET_FILE_PATH> \
[--config_file_path=<PATH_TO_TEST_JSON_CONFIG_FILE>] \
[--print_detailed_results]
例如:
adk eval \
samples_for_testing/hello_world \
samples_for_testing/hello_world/hello_world_eval_set_001.evalset.json
以下是每个命令行参数的详细信息:
AGENT_MODULE_FILE_PATH: 指向包含名为"agent"模块的init.py文件路径。"agent"模块包含一个root_agent。EVAL_SET_FILE_PATH: 评估文件的路径。您可以指定一个或多个评估集文件路径。对于每个文件,默认情况下会运行所有评估。如果只想运行评估集中的特定评估,首先创建一个以逗号分隔的评估名称列表,然后将其作为后缀添加到评估集文件名后,用冒号:分隔。- 例如:
sample_eval_set_file.json:eval_1,eval_2,eval_3
这将仅运行sample_eval_set_file.json中的eval_1、eval_2和eval_3 CONFIG_FILE_PATH: 配置文件的路径。PRINT_DETAILED_RESULTS: 在控制台打印详细结果。