动态任务映射¶
动态任务映射允许工作流在运行时基于当前数据创建多个任务,而无需DAG作者预先知道需要多少任务。
这与在for循环中定义任务类似,但调度器可以根据前一个任务的输出完成这一操作,而不是由DAG文件获取数据并自行处理。在执行映射任务之前,调度器将创建n个任务副本,每个输入对应一个。
也可以让任务对映射任务的收集输出进行操作,通常称为map和reduce。
简单映射¶
在最简单的形式中,您可以使用expand()函数直接映射DAG文件中定义的列表,而不是直接调用任务。
如果想查看动态任务映射的简单用法,可以参考下方内容:
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
"""Example DAG demonstrating the usage of dynamic task mapping."""
from __future__ import annotations
from datetime import datetime
from airflow.decorators import task
from airflow.models.dag import DAG
with DAG(dag_id="example_dynamic_task_mapping", schedule=None, start_date=datetime(2022, 3, 4)) as dag:
@task
def add_one(x: int):
return x + 1
@task
def sum_it(values):
total = sum(values)
print(f"Total was {total}")
added_values = add_one.expand(x=[1, 2, 3])
sum_it(added_values)
执行时,这将在任务日志中显示Total was 9。
这是最终的DAG结构:
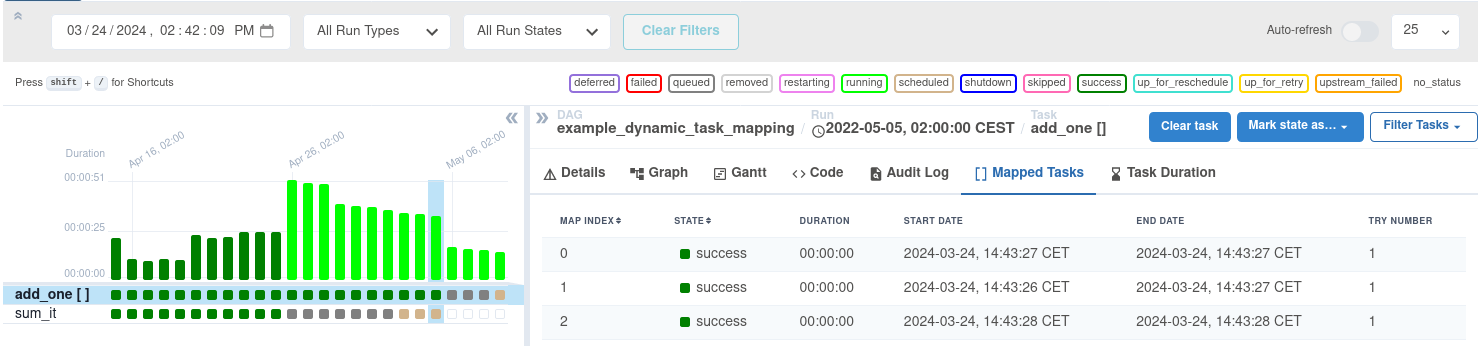
网格视图还在详情面板中提供了对您映射任务的可见性:
注意
仅允许将关键字参数传递给expand()。
注意
从映射任务传递的值是一个惰性代理
在上面的例子中,sum_it接收到的values是由每个add_one映射实例返回的所有值的聚合。然而,由于我们无法预先知道会有多少个add_one实例,values不是一个普通的列表,而是一个"惰性序列",只有在被请求时才会获取每个单独的值。因此,如果你直接运行print(values),你会得到类似这样的结果:
LazySelectSequence([15 items])
你可以对此对象使用常规序列语法(例如values[0]),或通过for循环正常遍历它。list(values)会返回一个"真正的"list,但由于这会立即从所有引用的上游映射任务加载值,如果映射数量很大,你必须注意潜在的性能影响。
请注意,当您将此代理对象推送到XCom时,同样适用。Airflow会尝试智能地自动转换值,但会发出警告以便您知晓。例如:
@task
def forward_values(values):
return values # This is a lazy proxy!
将发出类似这样的警告:
Coercing mapped lazy proxy return value from task forward_values to list, which may degrade
performance. Review resource requirements for this operation, and call list() explicitly to suppress this message. See Dynamic Task Mapping documentation for more information about lazy proxy objects.
可以通过如下方式修改任务来抑制该消息:
@task
def forward_values(values):
return list(values)
注意
不需要执行reduce任务。
虽然我们在这里展示了一个"reduce"任务(sum_it),但您并不一定要有这样一个任务,即使映射的任务没有下游任务,它们仍然会被执行。
任务生成的映射¶
我们上面展示的示例都可以通过DAG文件中的for循环来实现,但动态任务映射的真正威力在于能够让任务生成需要迭代的列表。
@task
def make_list():
# This can also be from an API call, checking a database, -- almost anything you like, as long as the
# resulting list/dictionary can be stored in the current XCom backend.
return [1, 2, {"a": "b"}, "str"]
@task
def consumer(arg):
print(arg)
with DAG(dag_id="dynamic-map", start_date=datetime(2022, 4, 2)) as dag:
consumer.expand(arg=make_list())
make_list任务作为普通任务运行,必须返回一个列表或字典(参见可扩展的数据类型有哪些?),然后consumer任务将被调用四次,每次使用make_list返回值中的一个值。
警告
任务生成的映射无法与TriggerRule.ALWAYS一起使用
在任务生成的映射中不允许分配trigger_rule=TriggerRule.ALWAYS,因为扩展参数在任务立即执行时未定义。
这在DAG解析时对任务和映射任务组强制执行,如果尝试使用会引发错误。
在最近的示例中,在consumer任务中设置trigger_rule=TriggerRule.ALWAYS会引发错误,因为make_list是一个任务生成的映射。
重复映射¶
一个映射任务的结果也可以用作下一个映射任务的输入。
with DAG(dag_id="repeated_mapping", start_date=datetime(2022, 3, 4)) as dag:
@task
def add_one(x: int):
return x + 1
first = add_one.expand(x=[1, 2, 3])
second = add_one.expand(x=first)
这将得到的结果是 [3, 4, 5]。
添加不展开的参数¶
除了传递在运行时展开的参数外,也可以传递不变的参数——为了明确区分这两种情况,我们使用不同的函数:expand()用于映射参数,而partial()用于非映射参数。
@task
def add(x: int, y: int):
return x + y
added_values = add.partial(y=10).expand(x=[1, 2, 3])
# This results in add function being expanded to
# add(x=1, y=10)
# add(x=2, y=10)
# add(x=3, y=10)
这将得到11、12和13的值。
这对于传递诸如连接ID、数据库表名或存储桶名称等参数给任务非常有用。
多参数映射¶
除了单个参数外,还可以传递多个参数进行扩展。这将产生创建"笛卡尔积"的效果,通过每个参数组合调用映射任务。
@task
def add(x: int, y: int):
return x + y
added_values = add.expand(x=[2, 4, 8], y=[5, 10])
# This results in the add function being called with
# add(x=2, y=5)
# add(x=2, y=10)
# add(x=4, y=5)
# add(x=4, y=10)
# add(x=8, y=5)
# add(x=8, y=10)
这将导致add任务被调用6次。但请注意,扩展的顺序无法保证。
命名映射¶
默认情况下,映射任务会被分配一个整数索引。在Airflow UI中,可以通过基于任务输入的命名来覆盖每个映射任务的整数索引。这需要为任务提供一个Jinja模板map_index_template。当扩展形式为.expand(时,该模板通常呈现为map_index_template="{{ task.。该模板会在每个扩展任务执行后使用任务上下文进行渲染。这意味着您可以像这样引用任务上的属性:
from airflow.providers.common.sql.operators.sql import SQLExecuteQueryOperator
# The two expanded task instances will be named "2024-01-01" and "2024-01-02".
SQLExecuteQueryOperator.partial(
...,
sql="SELECT * FROM data WHERE date = %(date)s",
map_index_template="""{{ task.parameters['date'] }}""",
).expand(
parameters=[{"date": "2024-01-01"}, {"date": "2024-01-02"}],
)
在上面的示例中,展开的任务实例将被命名为“2024-01-01”和“2024-01-02”。这些名称会分别显示在Airflow UI中,而不是“0”和“1”。
由于模板是在主执行块之后渲染的,因此还可以动态注入到渲染上下文中。这在需要通过Jinja模板语法表达复杂命名逻辑时特别有用,尤其是在taskflow函数中。例如:
from airflow.operators.python import get_current_context
@task(map_index_template="{{ my_variable }}")
def my_task(my_value: str):
context = get_current_context()
context["my_variable"] = my_value * 3
... # Normal execution...
# The task instances will be named "aaa" and "bbb".
my_task.expand(my_value=["a", "b"])
与非TaskFlow操作符的映射¶
可以将partial和expand与经典风格的运算符一起使用。某些参数不可映射,必须传递给partial(),例如task_id、queue、pool以及BaseOperator的大多数其他参数。
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
"""Example DAG demonstrating the usage of dynamic task mapping with non-TaskFlow operators."""
from __future__ import annotations
from datetime import datetime
from airflow.models.baseoperator import BaseOperator
from airflow.models.dag import DAG
class AddOneOperator(BaseOperator):
"""A custom operator that adds one to the input."""
def __init__(self, value, **kwargs):
super().__init__(**kwargs)
self.value = value
def execute(self, context):
return self.value + 1
class SumItOperator(BaseOperator):
"""A custom operator that sums the input."""
template_fields = ("values",)
def __init__(self, values, **kwargs):
super().__init__(**kwargs)
self.values = values
def execute(self, context):
total = sum(self.values)
print(f"Total was {total}")
return total
with DAG(
dag_id="example_dynamic_task_mapping_with_no_taskflow_operators",
schedule=None,
start_date=datetime(2022, 3, 4),
catchup=False,
):
# map the task to a list of values
add_one_task = AddOneOperator.partial(task_id="add_one").expand(value=[1, 2, 3])
# aggregate (reduce) the mapped tasks results
sum_it_task = SumItOperator(task_id="sum_it", values=add_one_task.output)
注意
只能将关键字参数传递给partial()。
对经典运算符结果进行映射¶
如果想对经典运算符的结果进行映射,应该明确引用输出,而不是运算符本身。
# Create a list of data inputs.
extract = ExtractOperator(task_id="extract")
# Expand the operator to transform each input.
transform = TransformOperator.partial(task_id="transform").expand(input=extract.output)
# Collect the transformed inputs, expand the operator to load each one of them to the target.
load = LoadOperator.partial(task_id="load").expand(input=transform.output)
混合使用TaskFlow和经典操作符¶
在这个示例中,您需要定期将数据传送到一个S3存储桶,并希望对每个到达的文件应用相同的处理流程,无论每次到达的文件数量有多少。
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.providers.amazon.aws.operators.s3 import S3ListOperator
with DAG(dag_id="mapped_s3", start_date=datetime(2020, 4, 7)) as dag:
list_filenames = S3ListOperator(
task_id="get_input",
bucket="example-bucket",
prefix='incoming/provider_a/{{ data_interval_start.strftime("%Y-%m-%d") }}',
)
@task
def count_lines(aws_conn_id, bucket, filename):
hook = S3Hook(aws_conn_id=aws_conn_id)
return len(hook.read_key(filename, bucket).splitlines())
@task
def total(lines):
return sum(lines)
counts = count_lines.partial(aws_conn_id="aws_default", bucket=list_filenames.bucket).expand(
filename=list_filenames.output
)
total(lines=counts)
为非TaskFlow操作符分配多个参数¶
有时上游任务需要向下游操作符传递多个参数。为此,您可以使用expand_kwargs函数,该函数接收一个映射序列进行参数映射。
BashOperator.partial(task_id="bash").expand_kwargs(
[
{"bash_command": "echo $ENV1", "env": {"ENV1": "1"}},
{"bash_command": "printf $ENV2", "env": {"ENV2": "2"}},
],
)
这会在运行时生成两个任务实例,分别打印1和2。
也可以将expand_kwargs与大多数操作符参数混合使用,例如PythonOperator的op_kwargs
def print_args(x, y):
print(x)
print(y)
return x + y
PythonOperator.partial(task_id="task-1", python_callable=print_args).expand_kwargs(
[
{"op_kwargs": {"x": 1, "y": 2}, "show_return_value_in_logs": True},
{"op_kwargs": {"x": 3, "y": 4}, "show_return_value_in_logs": False},
]
)
类似于expand,您还可以映射返回字典列表的XCom,或每个返回字典的XCom列表。复用上面的S3示例,您可以使用映射任务执行"分支"操作并将文件复制到不同的存储桶:
list_filenames = S3ListOperator(...) # Same as the above example.
@task
def create_copy_kwargs(filename):
if filename.rsplit(".", 1)[-1] not in ("json", "yml"):
dest_bucket_name = "my_text_bucket"
else:
dest_bucket_name = "my_other_bucket"
return {
"source_bucket_key": filename,
"dest_bucket_key": filename,
"dest_bucket_name": dest_bucket_name,
}
copy_kwargs = create_copy_kwargs.expand(filename=list_filenames.output)
# Copy files to another bucket, based on the file's extension.
copy_filenames = S3CopyObjectOperator.partial(
task_id="copy_files", source_bucket_name=list_filenames.bucket
).expand_kwargs(copy_kwargs)
对任务组进行映射¶
类似于TaskFlow任务,你也可以在@task_group装饰的函数上调用expand或expand_kwargs来创建一个映射任务组:
注意
为简洁起见,本节中个别任务的实现细节已省略。
@task_group
def file_transforms(filename):
return convert_to_yaml(filename)
file_transforms.expand(filename=["data1.json", "data2.json"])
在上面的示例中,任务convert_to_yaml在运行时被扩展为两个任务实例。第一个扩展实例将接收"data1.json"作为输入,第二个则接收"data2.json"。
任务组函数中的值引用¶
任务函数(@task)和任务组函数(@task_group)之间的一个重要区别是:由于任务组没有关联的工作节点,任务组函数中的代码无法解析传入的参数;实际值只有在引用被传递到任务中时才会被解析。
例如,这段代码将不会工作:
@task def my_task(value): print(value) @task_group def my_task_group(value): if not value: # DOES NOT work as you'd expect! task_a = EmptyOperator(...) else: task_a = PythonOperator(...) task_a << my_task(value) my_task_group.expand(value=[0, 1, 2])
当my_task_group中的代码被执行时,value仍然只是一个引用而非实际值,因此if not value分支不会按预期工作。然而,如果你将该引用传递给任务,它会在任务执行时被解析,因此三个my_task实例将分别接收到1、2和3。
因此,必须牢记的是,如果要对传入任务组函数的任何值执行逻辑操作,必须始终使用任务来运行该逻辑,例如使用@task.branch(或BranchPythonOperator)处理条件判断,以及使用任务映射方法处理循环。
注意
在映射任务组中不允许进行任务映射
目前不允许在映射任务组内部嵌套进行任务映射。虽然从技术层面实现这一功能并不特别困难,但我们决定有意省略此功能,因为它会显著增加用户界面的复杂性,且对于一般使用场景可能并非必需。未来可能会根据用户反馈重新评估这一限制。
深度优先执行¶
如果一个映射任务组包含多个任务,组中的所有任务都会针对相同的输入"一起"展开。例如:
@task_group
def file_transforms(filename):
converted = convert_to_yaml(filename)
return replace_defaults(converted)
file_transforms.expand(filename=["data1.json", "data2.json"])
由于组file_transforms被扩展为两个,任务convert_to_yaml和replace_defaults在运行时将各自变成两个实例。
通过分别展开这两个任务,可以实现类似的效果:
converted = convert_to_yaml.expand(filename=["data1.json", "data2.json"])
replace_defaults.expand(filename=converted)
然而,区别在于任务组允许内部每个任务仅依赖其"相关输入"。以上述例子为例,replace_defaults 将仅依赖同一扩展组中的 convert_to_yaml,而非不同组中相同任务的实例。这种被称为深度优先执行的策略(与简单的无组广度优先执行相对),能实现更合理的任务分离、细粒度的依赖规则和精确的资源分配——沿用上述例子,第一个 replace_defaults 可以在 convert_to_yaml("data2.json") 完成前运行,且无需关心后者是否成功。
依赖于映射任务组的输出¶
类似于映射任务组,依赖映射任务组的输出也会自动聚合该组的结果:
@task_group
def add_to(value):
value = add_one(value)
return double(value)
results = add_to.expand(value=[1, 2, 3])
consumer(results) # Will receive [4, 6, 8].
也可以像普通映射任务的结果一样执行任何操作。
基于映射任务组输出的分支¶
虽然无法在映射任务的结果上实现分支逻辑(例如使用@task.branch),但可以根据任务组的输入进行分支。以下示例演示了根据映射任务组的输入来执行三个任务中的一个。
inputs = ["a", "b", "c"]
@task_group(group_id="my_task_group")
def my_task_group(input):
@task.branch
def branch(element):
if "a" in element:
return "my_task_group.a"
elif "b" in element:
return "my_task_group.b"
else:
return "my_task_group.c"
@task
def a():
print("a")
@task
def b():
print("b")
@task
def c():
print("c")
branch(input) >> [a(), b(), c()]
my_task_group.expand(input=inputs)
从映射任务中筛选项目¶
映射任务可以通过返回None来阻止任何元素传递给下游任务。例如,如果我们只想将具有特定扩展名的文件从一个S3存储桶复制到另一个存储桶,我们可以这样实现create_copy_kwargs:
@task
def create_copy_kwargs(filename):
# Skip files not ending with these suffixes.
if filename.rsplit(".", 1)[-1] not in ("json", "yml"):
return None
return {
"source_bucket_key": filename,
"dest_bucket_key": filename,
"dest_bucket_name": "my_other_bucket",
}
# copy_kwargs and copy_files are implemented the same.
这使得copy_files仅针对.json和.yml文件展开,而忽略其余文件。
转换扩展数据¶
由于通常需要转换任务映射的输出数据格式,特别是对于非TaskFlow操作符,其输出格式是预先确定且不易转换的(如上例中的create_copy_kwargs),可以使用特殊的map()函数轻松执行此类转换。因此,上述示例可以修改如下:
from airflow.exceptions import AirflowSkipException
list_filenames = S3ListOperator(...) # Unchanged.
def create_copy_kwargs(filename):
if filename.rsplit(".", 1)[-1] not in ("json", "yml"):
raise AirflowSkipException(f"skipping {filename!r}; unexpected suffix")
return {
"source_bucket_key": filename,
"dest_bucket_key": filename,
"dest_bucket_name": "my_other_bucket",
}
copy_kwargs = list_filenames.output.map(create_copy_kwargs)
# Unchanged.
copy_filenames = S3CopyObjectOperator.partial(...).expand_kwargs(copy_kwargs)
有几点需要注意:
合并上游数据(又称“zipping”)¶
通常还需要将多个输入源合并为一个任务映射可迭代对象。这一过程通常称为"zip操作"(类似于Python内置的zip()函数),也是作为下游任务的预处理步骤执行的。
这在任务映射的条件逻辑中特别有用。例如,如果您想从S3下载文件,但重命名这些文件,类似这样的操作是可行的:
list_filenames_a = S3ListOperator(
task_id="list_files_in_a",
bucket="bucket",
prefix="incoming/provider_a/{{ data_interval_start|ds }}",
)
list_filenames_b = ["rename_1", "rename_2", "rename_3", ...]
filenames_a_b = list_filenames_a.output.zip(list_filenames_b)
@task
def download_filea_from_a_rename(filenames_a_b):
fn_a, fn_b = filenames_a_b
S3Hook().download_file(fn_a, local_path=fn_b)
download_filea_from_a_rename.expand(filenames_a_b=filenames_a_b)
类似于内置的zip(),您可以将任意数量的可迭代对象压缩在一起,得到一个由位置参数数量组成的元组可迭代对象。默认情况下,压缩后的可迭代对象长度与最短的可迭代对象相同,多余的项目会被丢弃。可以通过传递可选关键字参数default来切换行为以匹配Python的itertools.zip_longest()——压缩后的可迭代对象将与最长的可迭代对象长度相同,缺失的项目将填充为default提供的值。
连接多个上游任务¶
组合输入源的另一种常见模式是对多个可迭代对象运行相同的任务。当然,为每个可迭代对象单独运行相同的代码是完全有效的,例如:
list_filenames_a = S3ListOperator(
task_id="list_files_in_a",
bucket="bucket",
prefix="incoming/provider_a/{{ data_interval_start|ds }}",
)
list_filenames_b = S3ListOperator(
task_id="list_files_in_b",
bucket="bucket",
prefix="incoming/provider_b/{{ data_interval_start|ds }}",
)
@task
def download_file(filename):
S3Hook().download_file(filename)
# process file...
download_file.override(task_id="download_file_a").expand(filename=list_filenames_a.output)
download_file.override(task_id="download_file_b").expand(filename=list_filenames_b.output)
然而,如果能将任务合并为一个,DAG将更具扩展性且更易于检查。这可以通过concat实现:
# Tasks list_filenames_a and list_filenames_b, and download_file stay unchanged.
list_filenames_concat = list_filenames_a.concat(list_filenames_b)
download_file.expand(filename=list_filenames_concat)
这将创建一个单独的任务来同时扩展两个列表。你可以使用concat将任意数量的可迭代对象连接在一起(例如foo.concat(bar, rex));或者,由于返回值也是一个XCom引用,可以链式调用concat(例如foo.concat(bar).concat(rex))来达到相同的结果:一个按顺序连接所有可迭代对象的单一可迭代对象,类似于Python的itertools.chain()。
哪些数据类型可以扩展?¶
目前只能映射到字典、列表或存储在XCom中作为任务结果的那些类型之一。
如果上游任务返回不可映射的类型,映射任务在运行时将失败并抛出UnmappableXComTypePushed异常。例如,上游任务不能返回普通字符串——它必须是列表或字典。
模板字段和映射参数如何交互?¶
操作符的所有参数都可以被映射,即使那些不接受模板化参数的参数也是如此。
如果一个字段被标记为模板化且已被映射,它将不会被模板化。
例如,这将打印 {{ ds }} 而不是日期戳:
@task
def make_list():
return ["{{ ds }}"]
@task
def printer(val):
print(val)
printer.expand(val=make_list())
如果你想插入值,可以自己调用task.render_template,或者使用插值:
@task
def make_list(ds=None):
return [ds]
@task
def make_list(**context):
return [context["task"].render_template("{{ ds }}", context)]
对映射任务设置限制¶
您可以对任务设置两种限制:
可以创建的映射任务实例数量是扩展的结果。
映射任务可以同时运行的数量。
限制映射任务数量
[core]配置项
max_map_length定义了expand能创建的最大任务数 - 默认值为1024。如果源任务(前面示例中的
make_list)返回的列表长度超过此限制,将导致该任务失败。限制映射任务的并行副本数量
如果您不希望大型映射任务占用所有可用的运行槽,可以使用任务上的
max_active_tis_per_dag设置来限制同时运行的数量。但请注意,此设置适用于该任务在所有活动DagRun中的所有副本,而不仅限于此特定DagRun。
@task(max_active_tis_per_dag=16) def add_one(x: int): return x + 1 BashOperator.partial(task_id="my_task", max_active_tis_per_dag=16).expand(bash_command=commands)
自动跳过零长度映射¶
如果输入为空(长度为零),则不会创建新任务,映射任务将被标记为SKIPPED。