表流式读写
Delta Lake与Spark Structured Streaming通过readStream和writeStream深度集成。Delta Lake克服了通常与流式系统和文件相关的许多限制,包括:
在多个流(或并发批处理作业)中保持"恰好一次"处理
高效发现哪些文件是新的,当使用文件作为流的数据源时
对于Delta Lake表上的许多操作,您可以通过在创建新的SparkSession时设置配置来启用与Apache Spark DataSourceV2和Catalog API(自3.0起)的集成。请参阅Configure SparkSession。
在本文中:
Delta表作为数据源
当您将Delta表作为流数据源加载并在流式查询中使用时,该查询会处理表中现有的所有数据以及流启动后到达的任何新数据。
spark.readStream.format("delta")
.load("/tmp/delta/events")
import io.delta.implicits._
spark.readStream.delta("/tmp/delta/events")
限制输入速率
以下选项可用于控制微批次:
maxFilesPerTrigger: 每个微批次中要考虑的新文件数量。默认值为1000。maxBytesPerTrigger: 每个微批次处理的数据量。该选项设置了一个"软性上限",意味着一个批次大约会处理这么多数据,但在最小输入单元超过此限制的情况下,可能会处理更多数据以使流查询继续推进。如果在流处理中使用Trigger.Once,则会忽略此选项。默认情况下未设置此值。
如果同时使用maxBytesPerTrigger和maxFilesPerTrigger,微批处理会在达到maxFilesPerTrigger或maxBytesPerTrigger任一限制时停止处理数据。
注意
当源表事务由于logRetentionDuration configuration配置被清理且流处理滞后时,Delta Lake会处理与源表最新可用事务历史记录对应的数据,但不会使流处理失败。这可能导致数据被丢弃。
忽略更新和删除
结构化流处理(Structured Streaming)无法处理非追加类型的输入,如果作为数据源的表格发生任何修改,系统会抛出异常。对于无法自动向下游传播的变更,主要有两种处理策略:
您可以删除输出和检查点,然后从头开始重新启动流。
您可以设置以下两个选项中的任意一个:
ignoreDeletes: 忽略在分区边界删除数据的事务。ignoreChanges: 如果源表中的文件由于数据变更操作(如UPDATE、MERGE INTO、DELETE(分区内)或OVERWRITE)需要重写,则重新处理更新。未更改的行可能仍会被发出,因此您的下游消费者应能够处理重复项。删除操作不会传播到下游。ignoreChanges包含了ignoreDeletes的功能。因此,如果您使用ignoreChanges,您的流将不会因源表的删除或更新操作而中断。
示例
例如,假设您有一个表user_events,其中包含date、user_email和action列,并按date进行分区。您从user_events表中流式读取数据,并且由于GDPR要求需要从中删除数据。
当您在分区边界删除数据时(即WHERE条件作用于分区列),文件已经按值进行了分段,因此删除操作只需从元数据中移除这些文件。因此,如果您只想删除某些分区的数据,可以使用:
spark.readStream.format("delta")
.option("ignoreDeletes", "true")
.load("/tmp/delta/user_events")
然而,如果您必须基于user_email删除数据,那么您需要使用:
spark.readStream.format("delta")
.option("ignoreChanges", "true")
.load("/tmp/delta/user_events")
如果您使用UPDATE语句更新user_email,则包含该user_email的文件将被重写。当您使用ignoreChanges时,新记录会与同一文件中所有未更改的记录一起传播到下游。您的逻辑应该能够处理这些传入的重复记录。
指定初始位置
您可以使用以下选项来指定Delta Lake流式数据源的起始点,而无需处理整个表。
startingVersion: 指定从哪个Delta Lake版本开始读取。流数据源将读取从该版本(包含)开始的所有表变更。您可以通过DESCRIBE HISTORY命令输出中的version列获取提交版本号。要仅返回最新更改,请指定
latest。startingTimestamp: 起始时间戳。流式数据源将读取该时间戳或之后提交的所有表变更(包含该时间戳)。可选参数之一:一个时间戳字符串。例如,
"2019-01-01T00:00:00.000Z"。日期字符串。例如,
"2019-01-01"。
不能同时设置这两个选项;只能使用其中之一。它们仅在启动新的流式查询时生效。如果流式查询已启动且进度已记录在其检查点中,这些选项将被忽略。
重要
虽然您可以从指定版本或时间戳启动流式数据源,但流式数据源的架构始终是Delta表的最新架构。您必须确保在指定版本或时间戳之后,Delta表没有发生不兼容的架构变更。否则,当使用错误的架构读取数据时,流式数据源可能会返回不正确的结果。
处理初始快照而不丢失数据
当将Delta表用作流数据源时,查询首先会处理表中存在的所有数据。该版本的Delta表称为初始快照。默认情况下,Delta表的数据文件是基于最后修改时间进行处理的。然而,最后修改时间并不一定代表记录事件的时间顺序。
在定义了水印的有状态流查询中,按修改时间处理文件可能导致记录以错误顺序被处理。这可能会使记录因水印机制而被视为迟到事件而丢弃。
您可以通过启用以下选项来避免数据丢失问题:
withEventTimeOrder: 初始快照是否应按事件时间顺序处理。
启用事件时间排序后,初始快照数据的事件时间范围会被划分为时间桶。每个微批次通过筛选时间范围内的数据来处理一个桶。maxFilesPerTrigger和maxBytesPerTrigger配置选项仍适用于控制微批次大小,但由于处理特性,这种方式只是近似控制。
下图展示了这一过程:
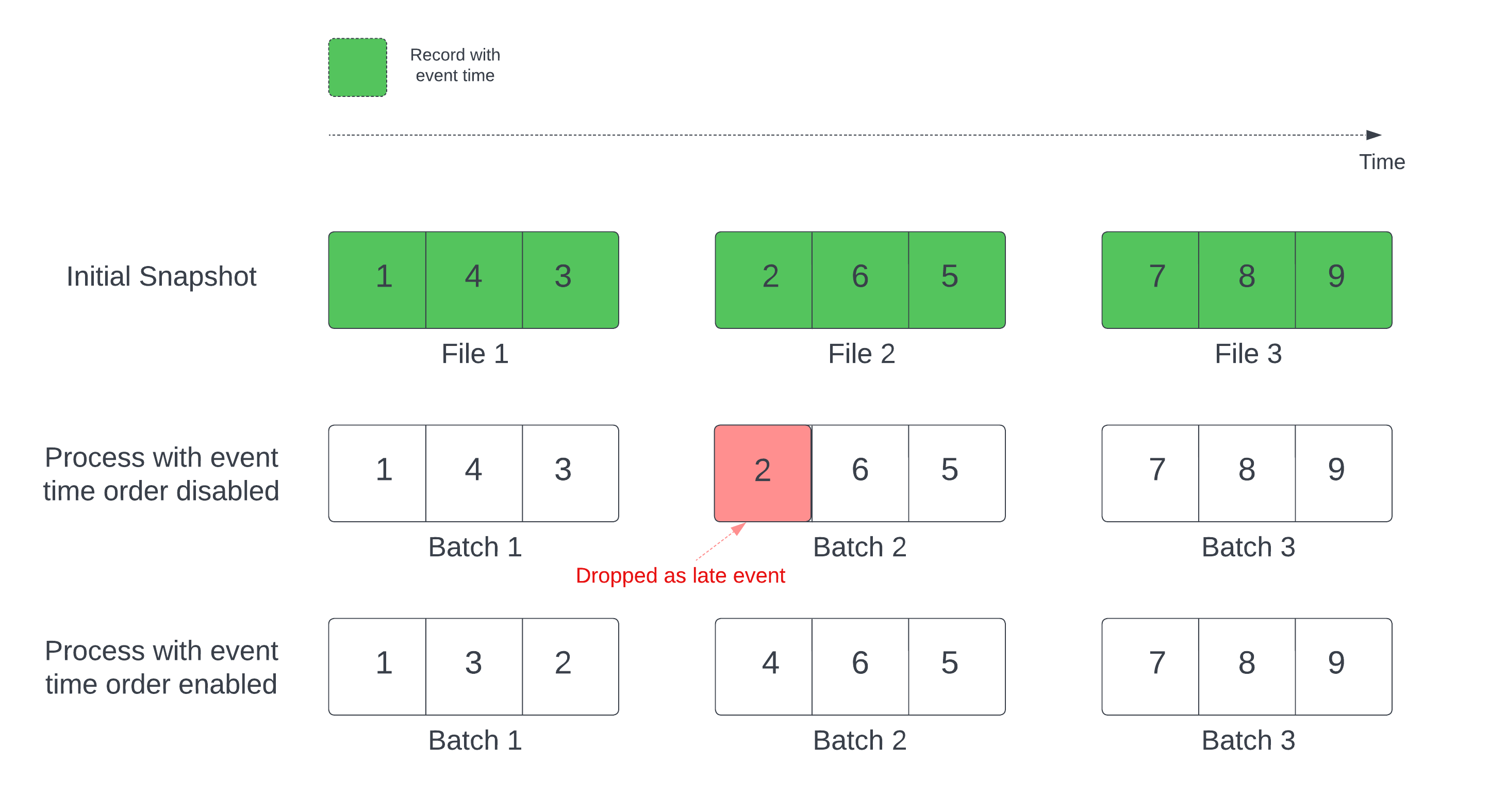
关于此功能的注意事项:
数据丢失问题仅在以默认顺序处理有状态流查询的初始Delta快照时发生。
一旦流查询启动且初始快照仍在处理中,您无法更改
withEventTimeOrder。若要更改withEventTimeOrder后重新启动,需要删除检查点。如果在启用withEventTimeOrder的情况下运行流查询,在初始快照处理完成之前,无法将其降级到不支持此功能的Delta版本。如果需要降级,可以等待初始快照完成,或者删除检查点并重新启动查询。
以下不常见场景不支持此功能:
事件时间列是一个生成列,在Delta源和水印之间存在非投影转换。
流查询中存在一个水印,该水印有多个Delta源。
启用事件时间排序后,Delta初始快照处理的性能可能会变慢。
每个微批次会扫描初始快照以筛选对应事件时间范围内的数据。为了加快筛选操作,建议使用Delta源列作为事件时间,这样可以应用数据跳过功能(请查看_了解适用条件)。此外,沿事件时间列进行表分区可以进一步加速处理。您可以通过Spark UI查看特定微批次扫描了多少个delta文件。
示例
假设您有一个包含event_time列的表user_events。您的流式查询是一个聚合查询。如果想确保初始快照处理期间不会丢失数据,可以使用:
spark.readStream.format("delta")
.option("withEventTimeOrder", "true")
.load("/tmp/delta/user_events")
.withWatermark("event_time", "10 seconds")
..注意:您也可以通过集群上的Spark配置启用此功能,这将适用于所有流式查询: spark.databricks.delta.withEventTimeOrder.enabled true
追踪非累加式模式变更
您可以提供一个模式跟踪位置,以便从启用了列映射的Delta表中启用流式传输。这通过允许流以精确模式读取过去的表数据(就像表进行了时间旅行一样),克服了非增量模式变更可能导致流中断的问题。
每次对数据源的流式读取都必须指定自己的schemaTrackingLocation。指定的schemaTrackingLocation必须包含在目标表流式写入的checkpointLocation目录内。
注意
对于需要合并多个源Delta表数据的流式工作负载,您需要在每个源表的checkpointLocation中指定唯一目录。
Delta表作为接收端
您还可以使用结构化流(Structured Streaming)将数据写入Delta表。事务日志使Delta Lake能够确保精确一次(exactly-once)处理,即使有其他流或批处理查询同时对该表进行操作。
注意
Delta Lake的VACUUM函数会移除所有未被Delta Lake管理的文件,但会跳过任何以_开头的目录。您可以安全地将检查点与其他数据和元数据一起存储在Delta表中,使用类似
在本节中:
追加模式
默认情况下,流以追加模式运行,该模式会将新记录添加到表中。
你可以使用路径方法:
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/_checkpoints/")
.start("/delta/events")
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.start("/tmp/delta/events")
import io.delta.implicits._
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.delta("/tmp/delta/events")
或者使用toTable方法(在Spark 3.1及更高版本中)如下:
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Complete mode
你也可以使用结构化流式处理(Structured Streaming)来用每个批次替换整个表。一个示例用例是通过聚合计算摘要:
(spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
)
spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
前面的示例持续更新一个包含按客户分组的事件聚合数量的表。
对于延迟要求较为宽松的应用程序,您可以使用一次性触发器来节省计算资源。通过设定特定计划来更新汇总聚合表,仅处理自上次更新以来到达的新数据。
在foreachBatch中实现幂等的表写入
注意
适用于 Delta Lake 2.0.0 及以上版本。
命令 foreachBatch 允许您指定一个函数,该函数在流查询中任意转换后的每个微批次输出上执行。这使得可以实现一个 foreachBatch 函数,将微批次输出写入一个或多个目标 Delta 表。然而,foreachBatch 并不能保证这些写入是幂等的,因为这些写入尝试缺乏批次是否正在重新执行的信息。例如,重新运行失败的批次可能导致数据重复写入。
为了解决这个问题,Delta表支持以下DataFrameWriter选项以使写入操作具有幂等性:
txnAppId: 一个唯一的字符串,你可以在每次DataFrame写入时传递。例如,你可以使用StreamingQuery ID作为txnAppId。txnVersion: 一个单调递增的数字,用作事务版本号。
Delta表使用txnAppId和txnVersion的组合来识别重复写入并忽略它们。
如果批量写入因故障中断,重新运行该批次会使用相同的应用程序和批次ID,这将有助于运行时正确识别重复写入并忽略它们。应用程序ID(txnAppId)可以是任何用户生成的唯一字符串,不需要与流ID相关联。
警告
如果删除流式检查点并使用新的检查点重新启动查询,必须提供一个不同的appId;否则,重新启动的查询中的写入操作将被忽略,因为它将包含相同的txnAppId,且批次ID将从0开始。
同样的DataFrameWriter选项可用于在非流式作业中实现幂等写入。详情请参阅Idempotent writes。
示例
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}