性能基准测试
集成基准测试
DGL 持续评估其核心 API、内核以及最先进的 GNN 模型的训练速度。基准测试代码可在 主仓库 中找到。它们会在每个夜间构建版本中触发,并将结果发布到 https://asv.dgl.ai/。
v0.6 基准测试
为了理解DGL v0.6的性能提升,我们在v0.5的基准测试上重新评估了它,并针对更新的基线添加了一些新的图分类任务。结果可在一个独立的仓库中找到。
v0.5 基准测试
v0.4.3 基准测试
速度和内存使用的微基准测试: 虽然将张量和自动梯度函数留给后端框架(例如PyTorch、MXNet和TensorFlow),DGL积极优化存储和计算,使用自己的内核。这里是与另一个流行包——PyTorch Geometric(PyG)的比较。简而言之,原始速度相似,但DGL的内存管理要好得多。
数据集 |
模型 |
准确率 |
时间 |
内存 |
||
|---|---|---|---|---|---|---|
PyG |
DGL |
PyG |
DGL |
|||
Cora |
图卷积网络 |
81.31 ± 0.88 |
0.478 |
0.666 |
1.1 |
1.1 |
GAT |
83.98 ± 0.52 |
1.608 |
1.399 |
1.2 |
1.1 |
|
CiteSeer |
图卷积网络 |
70.98 ± 0.68 |
0.490 |
0.674 |
1.1 |
1.1 |
GAT |
69.96 ± 0.53 |
1.606 |
1.399 |
1.3 |
1.1 |
|
PubMed |
图卷积网络 |
79.00 ± 0.41 |
0.491 |
0.690 |
1.1 |
1.1 |
GAT |
77.65 ± 0.32 |
1.946 |
1.393 |
1.6 |
1.1 |
|
图卷积网络 |
93.46 ± 0.06 |
内存溢出 |
28.6 |
内存溢出 |
11.7 |
|
Reddit-S |
图卷积网络 |
不适用 |
29.12 |
9.44 |
15.7 |
3.6 |
表:200个周期的训练时间(以秒为单位)和内存消耗(GB)
以下是DGL在TensorFlow后端与其他基于TF的GNN工具的比较(一个周期的训练时间,单位为秒):
数据集 |
模型 |
DGL |
GraphNet |
tf_geometric |
|---|---|---|---|---|
核心 |
图卷积网络 |
0.0148 |
0.0152 |
0.0192 |
图卷积网络 |
0.1095 |
内存溢出 |
内存溢出 |
|
PubMed |
图卷积网络 |
0.0156 |
0.0553 |
0.0185 |
PPI |
图卷积网络 |
0.09 |
0.16 |
0.21 |
Cora |
GAT |
0.0442 |
不适用 |
0.058 |
PPI |
GAT |
0.398 |
不适用 |
0.752 |
高内存利用率使DGL能够突破单GPU性能的极限,如下图所示。


可扩展性: DGL 充分利用了单台机器和集群中的多个 GPU 来提高训练速度,并且比替代方案具有更好的性能,如下面的图像所示。


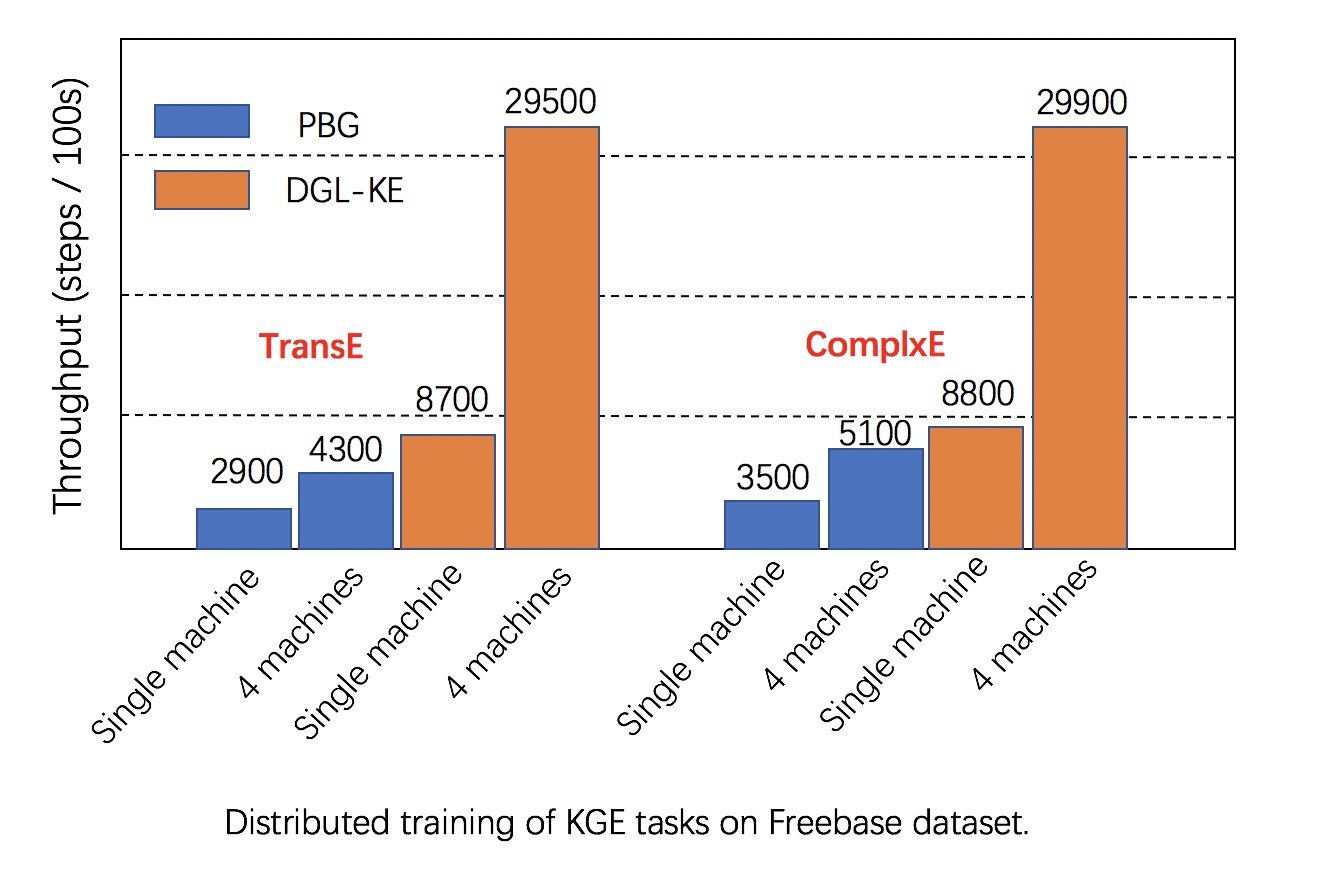
进一步阅读: DGL与其他替代方案的详细比较可以在 [这里](https://arxiv.org/abs/1909.01315)找到。