文档 API
edit文档API
edit本节首先简要介绍了Elasticsearch的数据复制模型,随后详细描述了以下CRUD API:
读取和写入文档
edit介绍
editElasticsearch中的每个索引都被划分为多个分片,每个分片可以有多个副本。这些副本被称为复制组,当文档被添加或删除时,必须保持同步。如果我们未能做到这一点,从一个副本读取将导致与从另一个副本读取非常不同的结果。保持分片副本同步并从中提供读取的过程,我们称之为数据复制模型。
Elasticsearch的数据复制模型基于主备模型,并在微软研究院的PacificA论文中有很好的描述。该模型基于从复制组中选择一个副本作为主分片。其他副本被称为副本分片。主分片作为所有索引操作的主要入口点。它负责验证操作并确保其正确性。一旦主分片接受了索引操作,主分片还负责将该操作复制到其他副本。
本节的目的在于提供Elasticsearch复制模型的高层次概述,并讨论其对写入和读取操作之间各种交互的影响。
基本写入模型
edit在Elasticsearch中的每个索引操作首先通过路由解析到一个复制组,通常基于文档ID。一旦确定了复制组,操作就会在内部转发到该组的当前主分片。这一阶段的索引被称为协调阶段。
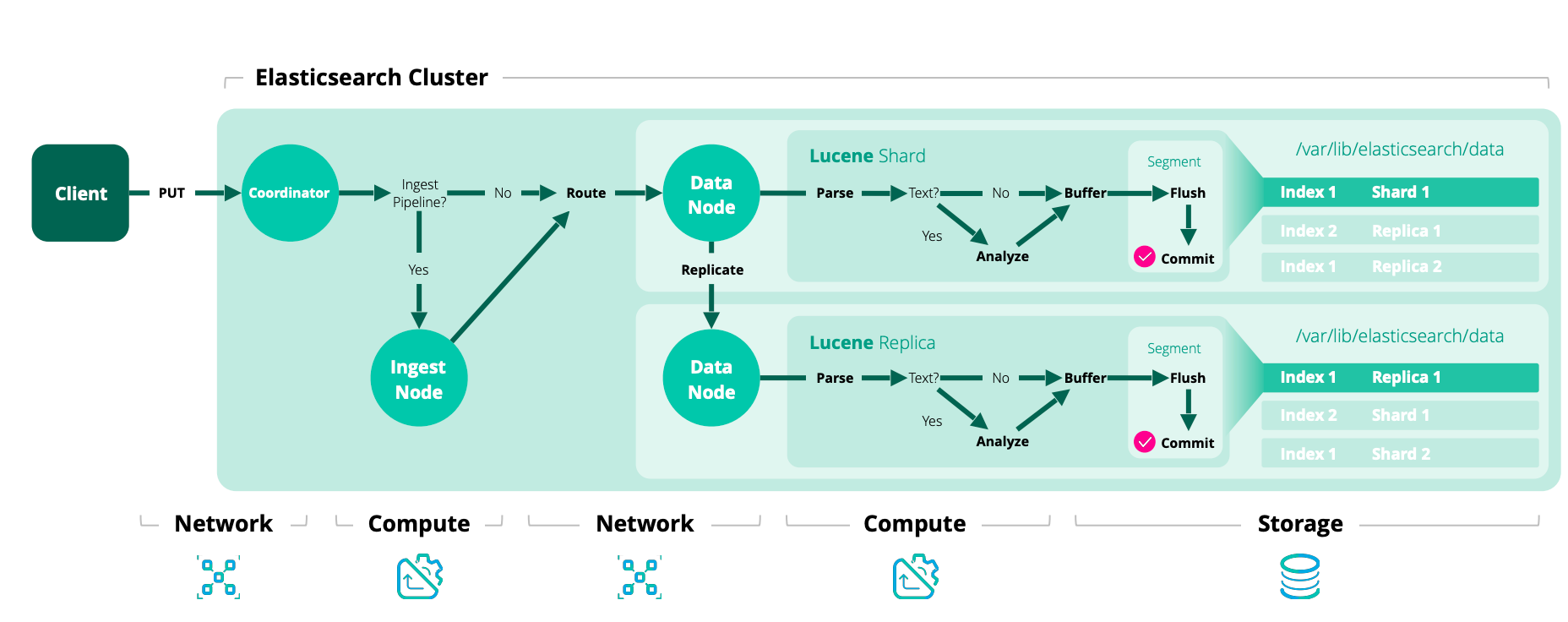
索引的下一个阶段是主阶段,在主分片上执行。主分片负责验证操作并将其转发给其他副本。由于副本可能处于离线状态,主分片不需要将操作复制到所有副本。相反,Elasticsearch维护一个应该接收操作的分片副本列表。这个列表称为同步副本,由主节点维护。顾名思义,这些是保证已经处理了所有已确认给用户的索引和删除操作的“良好”分片副本集。主分片负责维护这一不变性,因此必须将所有操作复制到该集合中的每个副本。
主分片遵循以下基本流程:
- 验证传入的操作并在结构无效时拒绝它(例如:在期望数字的地方有一个对象字段)
- 在本地执行操作,即索引或删除相关文档。这还将验证字段内容并在需要时拒绝(例如:关键字值对于Lucene中的索引来说太长)。
- 将操作转发到当前同步副本集中的每个副本。如果有多个副本,则并行执行此操作。
- 一旦所有同步副本都成功执行了操作并向主节点作出响应,主节点就会向客户端确认请求的成功完成。
每个同步副本在本地执行索引操作,以便拥有一份副本。这个索引阶段是副本阶段。
这些索引阶段(协调、主分片和副本)是顺序进行的。为了启用内部重试,每个阶段的生存期包括每个后续阶段的生存期。例如,协调阶段在每个主分片阶段完成之前不会完成,这些主分片可能分布在不同的主分片上。每个主分片阶段在同步副本完成本地索引文档并响应副本请求之前不会完成。
失败处理
edit在索引过程中可能会出现许多问题——磁盘可能会损坏,节点可能会彼此断开连接,或者某些配置错误可能会导致操作在副本上失败,尽管它在主节点上成功了。这些情况虽然不常见,但主节点必须对它们做出响应。
如果主节点本身发生故障,托管主节点的节点将向主节点发送消息。索引操作将等待(默认情况下最多1分钟,通过默认)主节点将其中一个副本提升为新的主节点。然后,操作将被转发到新的主节点进行处理。请注意,主节点还会监控节点的健康状况,并可能决定主动降级主节点。这通常发生在持有主节点的节点因网络问题与集群隔离时。有关更多详细信息,请参见此处。
一旦操作在主分片上成功执行,主分片在将其执行到副本分片时必须处理潜在的失败。这可能是由于副本上的实际故障或由于网络问题阻止了操作到达副本(或阻止副本响应)。所有这些都共享相同的结果:同步副本集中的一个副本错过了即将被确认的操作。为了避免违反不变性,主分片向主节点发送消息,请求将出现问题的分片从同步副本集中移除。只有当主节点确认分片已被移除后,主分片才会确认该操作。请注意,主节点还会指示另一个节点开始构建新的分片副本,以使系统恢复到健康状态。
在将操作转发给副本时,主节点将使用副本来验证它仍然是活动的主节点。如果主节点由于网络分区(或长时间GC)而被隔离,它可能会在意识到自己已被降级之前继续处理传入的索引操作。来自陈旧主节点的操作将被副本拒绝。当主节点收到副本拒绝其请求的响应,因为它不再是主节点时,它将联系主节点并得知自己已被替换。然后,操作将被路由到新的主节点。
基本读取模型
editElasticsearch 的读取操作可以是轻量级的通过 ID 查找,也可以是带有复杂聚合的重型搜索请求,这些请求会消耗大量的 CPU 资源。主备模型的一个优点是它保持所有分片副本相同(正在进行中的操作除外)。因此,一个同步的副本就足以处理读取请求。
当一个读取请求被节点接收时,该节点负责将其转发给持有相关分片的节点,整理响应,并向客户端作出响应。我们称该节点为该请求的协调节点。基本流程如下:
- 解析读取请求到相关的分片。请注意,由于大多数搜索将发送到一个或多个索引,它们通常需要从多个分片中读取数据,每个分片代表数据的不同子集。
- 从分片复制组中选择每个相关分片的活动副本。这可以是主分片或副本。默认情况下,Elasticsearch使用自适应副本选择来选择分片副本。
- 将分片级别的读取请求发送到选定的副本。
- 合并结果并响应。请注意,在通过ID查找的情况下,只有一个分片是相关的,因此可以跳过此步骤。
分片失败
edit当一个分片未能响应读取请求时,协调节点会将请求发送到同一复制组中的另一个分片副本。重复的失败可能导致没有可用的分片副本。
为了确保快速响应,以下API在有一个或多个分片失败时将返回部分结果:
包含部分结果的响应仍然提供 200 OK HTTP 状态码。
分片失败由响应头中的 timed_out 和 _shards 字段指示。
一些简单的含义
edit这些基本流程中的每一个都决定了 Elasticsearch 在读取和写入时的系统行为。此外,由于读取和写入请求可以并发执行,这两个基本流程相互交互。这有一些固有的含义:
- Efficient reads
- 在正常操作下,每个读操作都会在每个相关的复制组上执行一次。 只有在故障条件下,同一分片的多个副本才会执行相同的搜索。
- Read unacknowledged
- 由于主节点首先在本地索引,然后复制请求,因此在请求被确认之前,并发读取可能已经看到了更改。
- Two copies by default
- 该模型在仅维护两个数据副本的情况下可以实现容错。这与基于仲裁的系统形成对比,在基于仲裁的系统中,实现容错所需的最小副本数为3。
失败
edit在失败情况下,以下是可能的:
- A single shard can slow down indexing
- 因为主节点在每次操作中都会等待同步副本集中的所有副本, 一个慢速的分片可能会拖慢整个复制组。这是我们为上述提到的读取效率所付出的代价。 当然,一个慢速的分片也会拖慢那些不幸被路由到它的搜索请求。
- Dirty reads
- 一个孤立的主节点可能会暴露出未被确认的写操作。这是因为孤立的主节点只有在向其副本发送请求或联系主节点时,才会意识到自己被孤立。此时,操作已经索引到主节点中,并且可以被并发读取。Elasticsearch通过每秒(默认情况下)ping主节点并拒绝未知主节点的索引操作来减轻这种风险。
冰山一角
edit本文档提供了Elasticsearch如何处理数据的高层次概述。当然,在幕后还有更多的事情在进行。诸如主项、集群状态发布和主节点选举等都在保持系统正确运行中发挥作用。本文档也不涵盖已知且重要的错误(包括已关闭和开放的)。我们认识到GitHub很难跟上。为了帮助人们掌握这些信息,我们在我们的网站上维护了一个专门的弹性页面。我们强烈建议阅读它。
索引 API
edit参见移除映射类型。
将JSON文档添加到指定的数据流或索引中,并使其可搜索。如果目标是索引且文档已存在,请求将更新文档并增加其版本。
您不能使用索引 API 向数据流发送现有文档的更新请求。请参阅 通过查询更新数据流中的文档 和 更新或删除支持索引中的文档。
请求
editPUT /
POST /
PUT /
POST /
您不能使用PUT /请求格式向数据流添加新文档。要指定文档ID,请改用PUT /格式。请参阅向数据流添加文档。
先决条件
edit-
如果启用了Elasticsearch的安全功能,您必须对目标数据流、索引或索引别名具有以下 索引权限:
-
要使用
PUT /请求格式添加或覆盖文档,您必须具有/_doc/<_id> create、index或write索引权限。 -
要使用
POST /、/_doc/ PUT /或/_create/<_id> POST /请求格式添加文档,您必须具有/_create/<_id> create_doc、create、index或write索引权限。 -
要使用索引API请求自动创建数据流或索引,您必须具有
auto_configure、create_index或manage索引权限。
-
要使用
- 自动数据流创建需要启用数据流的匹配索引模板。请参阅设置数据流。
路径参数
edit-
<target> -
(必需,字符串) 目标数据流或索引的名称。
如果目标不存在且与名称或通配符(
*)模式匹配的 具有data_stream定义的索引模板,此请求将创建数据流。请参阅 设置数据流。如果目标不存在且不匹配数据流模板,此请求将创建索引。
您可以使用解析索引 API 检查现有目标。
-
<_id> -
(可选,字符串)文档的唯一标识符。
以下请求格式需要此参数:
-
PUT //_doc/<_id> -
PUT //_create/<_id> -
POST //_create/<_id>
要自动生成文档ID,请使用
POST /请求格式并省略此参数。/_doc/ -
查询参数
edit-
op_type -
(可选, 枚举) 设置为
create以仅在文档不存在时索引文档(如果不存在则放置)。如果已存在具有指定_id的文档,则索引操作将失败。与使用/_create index,create。如果指定了文档 ID,则默认为index。否则,默认为create。如果请求针对的是数据流,则需要使用
op_type为create。请参阅 向数据流添加文档。 -
pipeline -
(Optional, string) ID of the pipeline to use to preprocess incoming documents. If the index has a
default ingest pipeline specified, then setting the value to
_nonedisables the default ingest pipeline for this request. If a final pipeline is configured it will always run, regardless of the value of this parameter. -
refresh -
(可选,枚举) 如果
true,Elasticsearch 会刷新受影响的 shards 以使此操作对搜索可见,如果wait_for则等待刷新以使此操作对搜索可见,如果false则不对刷新做任何操作。 有效值:true、false、wait_for。默认值:false。 -
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
timeout -
(可选, 时间单位) 请求等待以下操作的时间段:
默认为
1m(一分钟)。这保证了 Elasticsearch 在失败前至少等待超时时间。实际等待时间可能会更长,特别是在多次等待发生时。 -
version - (可选,整数)用于并发控制的显式版本号。 指定的版本必须与文档的当前版本匹配,请求才能成功。
-
version_type -
(可选, 枚举) 特定版本类型:
external,external_gte. -
wait_for_active_shards -
(可选,字符串) 在继续操作之前,必须处于活动状态的每个分片的副本数量。设置为
all或任何非负整数,最大不超过索引中每个分片的副本总数(number_of_replicas+1)。默认为1,表示仅等待每个主分片处于活动状态。请参阅Active shards。
-
require_alias -
(可选,布尔值) 如果为
true,目标必须是一个 索引别名。 默认为false。
请求体
edit-
<field> - (必需,字符串) 请求体包含文档数据的JSON源。
响应体
edit-
_shards - 提供有关索引操作复制过程的信息。
-
_shards.total - 指示索引操作应在多少个分片副本(主分片和副本分片)上执行。
-
_shards.successful -
指示索引操作成功的分片副本数量。 当索引操作成功时,
successful至少为 1。当索引操作成功返回时,副本分片可能并非全部都已启动——默认情况下,只需要主分片。设置
wait_for_active_shards以更改此默认行为。请参阅活动分片。 -
_shards.failed - 一个包含在副本分片上索引操作失败时与复制相关的错误的数组。0 表示没有失败。
-
_index - 文档被添加到的索引的名称。
-
_type -
文档类型。Elasticsearch 索引现在支持单一文档类型,
_doc。 -
_id - 添加的文档的唯一标识符。
-
_version - 文档版本。每次更新文档时递增。
-
_seq_no - 为索引操作分配给文档的序列号。序列号用于确保旧版本的文档不会覆盖新版本。参见乐观并发控制。
-
_primary_term - 为索引操作分配给文档的主要术语。 参见乐观并发控制。
-
result -
索引操作的结果,
created或updated。
描述
edit您可以使用_doc或_create资源索引一个新的JSON文档。使用_create可以保证只有在文档不存在的情况下才会被索引。要更新现有文档,您必须使用_doc资源。
自动创建数据流和索引
edit如果请求的目标不存在且匹配一个带有data_stream定义的索引模板,索引操作将自动创建数据流。请参阅设置数据流。
如果目标不存在且不匹配数据流模板,操作将自动创建索引并应用任何匹配的索引模板。
Elasticsearch 包含多个内置的索引模板。为了避免与这些模板发生命名冲突,请参阅 避免索引模式冲突。
如果不存在映射,索引操作会创建一个动态映射。默认情况下,如果需要,新字段和对象会自动添加到映射中。有关字段映射的更多信息,请参阅映射和更新映射 API。
自动索引创建由action.auto_create_index设置控制。此设置默认为true,允许自动创建任何索引。您可以修改此设置以明确允许或阻止与指定模式匹配的索引的自动创建,或将其设置为false以完全禁用自动索引创建。指定一个逗号分隔的模式列表,您希望允许的模式,或使用+或-作为前缀来指示是否应允许或阻止该模式。当指定列表时,默认行为是禁止。
设置 action.auto_create_index 仅影响索引的自动创建。它不影响数据流的创建。
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "my-index-000001,index10,-index1*,+ind*"
}
}
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "false"
}
}
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "true"
}
}
|
允许自动创建名为 |
|
|
完全禁用自动索引创建。 |
|
|
允许自动创建任何索引。这是默认设置。 |
不存在时放置
edit您可以通过使用_create资源或设置op_type参数为create来强制执行创建操作。在这种情况下,如果索引中已经存在具有指定ID的文档,则索引操作将失败。
自动创建文档ID
edit当使用 POST / 请求格式时,op_type 会自动设置为 create,并且索引操作会为文档生成一个唯一的ID。
POST my-index-000001/_doc/
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
API返回以下结果:
{
"_shards": {
"total": 2,
"failed": 0,
"successful": 2
},
"_index": "my-index-000001",
"_id": "W0tpsmIBdwcYyG50zbta",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"result": "created"
}
乐观并发控制
edit索引操作可以是有条件的,并且只有在文档的最后一次修改被分配了由if_seq_no和if_primary_term参数指定的序列号和主项时才会执行。如果检测到不匹配,操作将导致VersionConflictException并返回409状态码。有关更多详细信息,请参阅乐观并发控制。
路由
edit默认情况下,分片分配——或路由——是通过使用文档id值的哈希值来控制的。为了更明确地控制,可以在每次操作的基础上直接指定路由器使用的哈希函数的值,使用路由参数。例如:
POST my-index-000001/_doc?routing=kimchy
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
在这个例子中,文档根据提供的routing参数:"kimchy"被路由到一个分片。
在设置显式映射时,您还可以使用 _routing 字段
来指示索引操作从文档本身提取路由值。这确实会带来(非常小的)额外文档解析开销。如果定义了 _routing 映射
并设置为 required,则在未提供或提取路由值的情况下,索引操作将失败。
数据流不支持自定义路由,除非它们是在模板中启用了allow_custom_routing设置的情况下创建的。
分布式
edit索引操作根据其路由定向到主分片(参见上面的路由部分),并在包含该分片的实际节点上执行。主分片完成操作后,如果需要,更新将分发到适用的副本。
活跃分片
edit为了提高系统写入的弹性,可以配置索引操作在继续操作之前等待一定数量的活动分片副本。如果所需数量的活动分片副本不可用,则写操作必须等待并重试,直到所需的分片副本启动或发生超时。默认情况下,写操作仅等待主分片处于活动状态后再继续(即 wait_for_active_shards=1)。可以通过动态设置索引设置中的 index.write.wait_for_active_shards 来覆盖此默认值。要按操作更改此行为,可以使用 wait_for_active_shards 请求参数。
有效值为 all 或任何正整数,最大不超过索引中每个分片配置的副本总数(即 number_of_replicas+1)。指定负值或大于分片副本数的数字将抛出错误。
例如,假设我们有一个由三个节点组成的集群,A、B 和 C,
我们创建了一个索引 index,并将副本数量设置为 3(结果是
4 个分片副本,比节点数量多一个副本)。如果我们
尝试进行索引操作,默认情况下,操作只会在确保
每个分片的主副本可用后继续进行。这意味着
即使 B 和 C 宕机,而 A 托管了主分片副本,
索引操作仍然会继续进行,只使用一个数据副本。
如果 wait_for_active_shards 在请求中设置为 3(并且所有 3 个节点
都正常运行),那么索引操作将需要 3 个活跃的分片副本
才能继续进行,这个要求应该会满足,因为集群中有 3 个
活跃的节点,每个节点都持有一个分片副本。然而,
如果我们设置 wait_for_active_shards 为 all(或者设置为 4,这是相同的),
索引操作将不会继续进行,因为我们没有在索引中激活所有 4 个副本。
操作将会超时,
除非在集群中启动了一个新节点来托管分片的第四个副本。
需要注意的是,此设置大大减少了写操作未写入所需数量的分片副本的可能性,但它并不能完全消除这种可能性,因为此检查是在写操作开始之前进行的。一旦写操作开始,仍然有可能在任意数量的分片副本上复制失败,但在主分片上成功。写操作响应中的_shards部分揭示了复制成功/失败的分片副本数量。
{
"_shards": {
"total": 2,
"failed": 0,
"successful": 2
}
}
刷新
edit控制此请求所做的更改何时对搜索可见。请参阅 refresh。
无操作更新
edit当使用索引 API 更新文档时,即使文档没有变化,也会创建文档的新版本。如果不接受这种情况,请使用 _update API 并将 detect_noop 设置为 true。此选项在索引 API 中不可用,因为索引 API 不会获取旧的源数据,也无法将其与新的源数据进行比较。
关于何时noop更新不可接受,并没有严格的规定。这涉及到许多因素,比如数据源发送实际noop更新的频率,以及Elasticsearch在接收更新的分片上每秒运行的查询数量。
超时
edit执行索引操作时,分配来执行该操作的主分片可能不可用。造成这种情况的一些原因可能是主分片当前正在从网关恢复或正在进行重新定位。默认情况下,索引操作将等待主分片变为可用状态,最多等待1分钟,然后失败并返回错误。可以使用timeout参数显式指定等待时间。以下是将等待时间设置为5分钟的示例:
PUT my-index-000001/_doc/1?timeout=5m
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
版本控制
edit每个索引文档都被赋予一个版本号。默认情况下,使用内部版本控制,从1开始,每次更新(包括删除)时递增。可选地,版本号可以设置为外部值(例如,如果维护在数据库中)。要启用此功能,version_type 应设置为 external。提供的值必须是一个大于或等于0的数值,长整型值,并且小于大约9.2e+18。
当使用外部版本类型时,系统会检查传递给索引请求的版本号是否大于当前存储文档的版本号。如果为真,文档将被索引并使用新的版本号。如果提供的值小于或等于存储文档的版本号,将发生版本冲突,索引操作将失败。例如:
PUT my-index-000001/_doc/1?version=2&version_type=external
{
"user": {
"id": "elkbee"
}
}
版本控制是完全实时的,并且不受搜索操作的近实时方面的影响。如果没有提供版本,则操作将在没有任何版本检查的情况下执行。
在之前的示例中,操作将会成功,因为提供的版本2高于当前文档版本1。如果文档已经更新并且其版本被设置为2或更高,索引命令将会失败并导致冲突(409 http状态码)。
一个很好的副作用是,只要使用源数据库的版本号,就不需要严格维护异步索引操作的顺序,这些操作是由于源数据库的更改而执行的。即使是从数据库更新Elasticsearch索引的简单情况,如果使用外部版本控制,也会简化,因为无论出于何种原因,如果索引操作的顺序不正确,只会使用最新版本。
版本类型
edit除了external版本类型外,Elasticsearch还支持其他类型用于特定用例:
-
externalorexternal_gt - 仅在给定版本严格高于存储文档的版本或如果文档不存在时,才对文档进行索引。给定的版本将作为新版本使用,并随新文档一起存储。提供的版本必须是一个非负的长整数。
-
external_gte - 仅在给定版本等于或高于存储文档的版本时索引文档。如果没有现有文档,操作也会成功。给定版本将用作新版本,并随新文档一起存储。提供的版本必须是一个非负的长整数。
版本类型 external_gte 适用于特殊用例,应谨慎使用。如果使用不当,可能会导致数据丢失。
还有另一个选项 force,由于可能导致主分片和副本分片不一致,因此已被弃用。
示例
edit将一个JSON文档插入到索引my-index-000001中,其_id为1:
PUT my-index-000001/_doc/1
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
API返回以下结果:
{
"_shards": {
"total": 2,
"failed": 0,
"successful": 2
},
"_index": "my-index-000001",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"result": "created"
}
使用 _create 资源将文档索引到 my-index-000001 索引中,如果该ID不存在文档:
PUT my-index-000001/_create/1
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
将 op_type 参数设置为 create,以在 my-index-000001 索引中索引一个文档,前提是该ID不存在任何文档:
PUT my-index-000001/_doc/1?op_type=create
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
获取 API
edit从索引中检索指定的JSON文档。
GET my-index-000001/_doc/0
描述
edit您可以使用 GET 从特定索引中检索文档及其源字段或存储字段。使用 HEAD 验证文档是否存在。您可以使用 _source 资源仅检索文档源或验证其是否存在。
实时
edit默认情况下,get API 是实时的,并且不受索引刷新率的影响(数据何时对搜索可见)。如果请求了存储字段(参见 stored_fields 参数)并且文档已更新但尚未刷新,get API 将不得不解析和分析源数据以提取存储字段。为了禁用实时 GET,可以将 realtime 参数设置为 false。
源过滤
edit默认情况下,get操作返回_source字段的内容,除非您使用了stored_fields参数或_source字段被禁用。您可以通过使用_source参数来关闭_source的检索:
GET my-index-000001/_doc/0?_source=false
如果你只需要从_source中获取一个或两个字段,可以使用_source_includes或_source_excludes参数来包含或过滤特定的字段。这对于处理大型文档时,部分检索可以节省网络开销特别有帮助。这两个参数都接受以逗号分隔的字段列表或通配符表达式。例如:
GET my-index-000001/_doc/0?_source_includes=*.id&_source_excludes=entities
如果你只想指定包含的内容,可以使用更简短的表示法:
GET my-index-000001/_doc/0?_source=*.id
路由
edit如果在索引期间使用了路由,则还需要指定路由值以检索文档。例如:
GET my-index-000001/_doc/2?routing=user1
此请求获取ID为2的文档,但它是基于用户进行路由的。如果未指定正确的路由,则不会获取该文档。
偏好设置
edit控制选择哪个分片副本来执行获取请求的偏好。默认情况下,操作在分片副本之间是随机选择的。
可以将preference设置为:
-
_local - 如果可能,操作将优先在本地分配的分片上执行。
- Custom (string) value
- 自定义值将用于确保相同的分片将用于相同的自定义值。这可以帮助在不同的刷新状态下命中不同的分片时避免“跳跃值”。示例值可以是Web会话ID或用户名。
刷新
edit可以将 refresh 参数设置为 true,以便在获取操作之前刷新相关分片并使其可搜索。设置为 true 时应经过仔细考虑和验证,以确保不会对系统造成过重负载(并减慢索引速度)。
分布式
editget操作被哈希到特定的分片ID。然后它被重定向到该分片ID内的一个副本,并返回结果。副本是该分片ID组中的主分片及其副本。这意味着我们拥有的副本越多,我们的GET扩展性就越好。
版本控制支持
edit您可以使用version参数来检索文档,仅当其当前版本等于指定版本时。
在内部,Elasticsearch 已经将旧文档标记为删除,并添加了一个全新的文档。旧版本的文档不会立即消失,尽管您将无法访问它。随着您继续索引更多数据,Elasticsearch 会在后台清理已删除的文档。
路径参数
edit-
<index> - (必需,字符串) 包含文档的索引名称。
-
<_id> - (必需, 字符串) 文档的唯一标识符。
查询参数
edit-
preference - (可选,字符串) 指定操作应在其上执行的节点或分片。默认情况下是随机的。
-
realtime -
(可选,布尔值) 如果为
true,则请求是实时的,而不是近实时的。 默认为true。请参阅Realtime。 -
refresh -
(可选,布尔值) 如果为
true,请求会在获取文档之前刷新相关的分片。默认为false。 -
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
stored_fields -
(可选,字符串)
一个以逗号分隔的
存储字段列表,包含在响应中。 -
_source -
(可选,字符串) 返回
_source字段与否,或者返回的字段列表。 -
_source_excludes -
(可选,字符串) 一个逗号分隔的列表,用于从响应中排除源字段。
您也可以使用此参数从
_source_includes查询参数中指定的子集中排除字段。如果
_source参数为false,则忽略此参数。 -
_source_includes -
(可选,字符串) 一个逗号分隔的源字段列表,用于包含在响应中。
如果指定了此参数,则仅返回这些源字段。您可以使用
_source_excludes查询参数从此子集中排除字段。如果
_source参数为false,则忽略此参数。 -
version - (可选,整数)用于并发控制的显式版本号。 指定的版本必须与文档的当前版本匹配,请求才能成功。
-
version_type -
(可选, 枚举) 特定版本类型:
external,external_gte.
响应体
edit-
_index - 文档所属索引的名称。
-
_id - 文档的唯一标识符。
-
_version - 文档版本。每次更新文档时递增。
-
_seq_no - 为索引操作分配给文档的序列号。序列号用于确保旧版本的文档不会覆盖新版本。请参阅乐观并发控制。
-
_primary_term - 为索引操作分配给文档的主要术语。 参见乐观并发控制。
-
found -
指示文档是否存在:
true或false。 -
_routing - 显式路由,如果已设置。
- _source
-
如果
found为true,则包含以JSON格式化的文档数据。 如果_source参数设置为false或stored_fields参数设置为true,则不包含此内容。 - _fields
-
如果
stored_fields参数设置为true并且found为true,则包含存储在索引中的文档字段。
示例
edit从索引 my-index-000001 中检索带有 _id 0 的 JSON 文档:
GET my-index-000001/_doc/0
API返回以下结果:
{
"_index": "my-index-000001",
"_id": "0",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"@timestamp": "2099-11-15T14:12:12",
"http": {
"request": {
"method": "get"
},
"response": {
"status_code": 200,
"bytes": 1070000
},
"version": "1.1"
},
"source": {
"ip": "127.0.0.1"
},
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
}
检查是否存在一个_id为0的文档:
HEAD my-index-000001/_doc/0
如果文档存在,Elasticsearch 返回的状态码为 200 - OK,如果不存在,则返回 404 - Not Found。
仅获取源字段
edit使用 _source 字段。例如:
GET my-index-000001/_source/1
您可以使用源过滤参数来控制返回_source的哪些部分:
GET my-index-000001/_source/1/?_source_includes=*.id&_source_excludes=entities
您可以使用 HEAD 与 _source 端点来高效地测试文档的 _source 是否存在。如果文档的源在 mapping 中被禁用,则该文档的源将不可用。
HEAD my-index-000001/_source/1
获取存储字段
edit使用 stored_fields 参数来指定您想要检索的存储字段集。任何未存储的请求字段都将被忽略。
例如,考虑以下映射:
PUT my-index-000001
{
"mappings": {
"properties": {
"counter": {
"type": "integer",
"store": false
},
"tags": {
"type": "keyword",
"store": true
}
}
}
}
现在我们可以添加一个文档:
PUT my-index-000001/_doc/1
{
"counter": 1,
"tags": [ "production" ]
}
然后尝试检索它:
GET my-index-000001/_doc/1?stored_fields=tags,counter
API返回以下结果:
{
"_index": "my-index-000001",
"_id": "1",
"_version": 1,
"_seq_no" : 22,
"_primary_term" : 1,
"found": true,
"fields": {
"tags": [
"production"
]
}
}
从文档本身获取的字段值总是以数组形式返回。
由于counter字段未存储,获取请求会忽略它。
您还可以检索元数据字段,如_routing字段:
PUT my-index-000001/_doc/2?routing=user1
{
"counter" : 1,
"tags" : ["env2"]
}
GET my-index-000001/_doc/2?routing=user1&stored_fields=tags,counter
API返回以下结果:
{
"_index": "my-index-000001",
"_id": "2",
"_version": 1,
"_seq_no" : 13,
"_primary_term" : 1,
"_routing": "user1",
"found": true,
"fields": {
"tags": [
"env2"
]
}
}
只有叶子字段可以使用 stored_field 选项进行检索。对象字段不能返回——如果指定,请求将失败。
删除 API
edit从指定索引中删除JSON文档。
请求
editDELETE /
描述
edit您可以使用 DELETE 从索引中删除文档。您必须指定索引名称和文档 ID。
您不能直接向数据流发送删除请求。要删除数据流中的文档,您必须定位包含该文档的备份索引。请参阅更新或删除备份索引中的文档。
乐观并发控制
edit删除操作可以是有条件的,并且只有在文档的最后一次修改被分配了由if_seq_no和if_primary_term参数指定的序列号和主项时才会执行。如果检测到不匹配,操作将导致VersionConflictException并返回409状态码。有关更多详细信息,请参阅乐观并发控制。
版本控制
edit每个被索引的文档都有版本控制。当删除文档时,可以指定version以确保我们尝试删除的相关文档实际上正在被删除,并且在此期间它没有发生变化。对文档执行的每次写操作(包括删除)都会导致其版本号递增。删除文档的版本号在删除后的一段时间内仍然可用,以允许控制并发操作。删除文档的版本号保持可用的时间长度由index.gc_deletes索引设置决定,默认值为60秒。
路由
edit如果在索引期间使用了路由,删除文档时也需要指定路由值。
如果_routing映射设置为required且未指定路由值,删除API会抛出RoutingMissingException并拒绝请求。
例如:
DELETE /my-index-000001/_doc/1?routing=shard-1
此请求删除ID为1的文档,但它是基于用户进行路由的。如果未指定正确的路由,则不会删除该文档。
自动索引创建
edit如果使用了外部版本控制变体, 删除操作会自动创建指定的索引(如果该索引不存在)。有关手动创建索引的信息,请参阅 创建索引 API。
分布式
edit删除操作会被哈希到特定的分片ID。然后它会被重定向到该ID组内的主分片,并在需要时复制到该ID组内的分片副本。
等待活动分片
edit在进行删除请求时,您可以将 wait_for_active_shards 参数设置为在开始处理删除请求之前,要求最小数量的分片副本处于活动状态。有关更多详细信息和使用示例,请参见 这里。
刷新
edit控制此请求所做的更改何时对搜索可见。请参阅
?refresh。
超时
edit执行删除操作时,分配执行删除操作的主分片可能不可用。造成这种情况的一些原因可能是主分片当前正在从存储中恢复或正在进行重新定位。默认情况下,删除操作将等待主分片变为可用状态,最长等待时间为1分钟,然后失败并返回错误。可以使用timeout参数显式指定等待时间。以下是将等待时间设置为5分钟的示例:
DELETE /my-index-000001/_doc/1?timeout=5m
路径参数
edit-
<index> - (必需,字符串)目标索引的名称。
-
<_id> - (必需,字符串) 文档的唯一标识符。
查询参数
edit-
if_seq_no - (可选,整数) 仅在文档具有此序列号时执行操作。请参阅乐观并发控制。
-
if_primary_term - (可选,整数) 仅在文档具有此主项时执行操作。请参阅乐观并发控制。
-
refresh -
(可选,枚举) 如果
true,Elasticsearch 会刷新受影响的 shards 以使此操作对搜索可见,如果wait_for则等待刷新以使此操作对搜索可见,如果false则不对刷新做任何操作。 有效值:true、false、wait_for。默认值:false。 -
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
timeout -
(可选,时间单位)
等待活跃分片的时间段。默认为
1m(一分钟)。 -
version - (可选,整数)用于并发控制的显式版本号。 指定的版本必须与文档的当前版本匹配,请求才能成功。
-
version_type -
(可选, 枚举) 特定版本类型:
external,external_gte. -
wait_for_active_shards -
(可选,字符串) 在继续操作之前,必须处于活动状态的每个分片的副本数量。设置为
all或任何非负整数,最大不超过索引中每个分片的副本总数(number_of_replicas+1)。默认为1,表示仅等待每个主分片处于活动状态。请参阅Active shards。
示例
edit从索引 my-index-000001 中删除 JSON 文档 1:
DELETE /my-index-000001/_doc/1
API返回以下结果:
{
"_shards": {
"total": 2,
"failed": 0,
"successful": 2
},
"_index": "my-index-000001",
"_id": "1",
"_version": 2,
"_primary_term": 1,
"_seq_no": 5,
"result": "deleted"
}
按查询删除 API
edit删除与指定查询匹配的文档。
POST /my-index-000001/_delete_by_query
{
"query": {
"match": {
"user.id": "elkbee"
}
}
}
请求
editPOST /
描述
edit您可以在请求URI或请求体中指定查询条件,使用与Search API相同的语法。
当您提交一个按查询删除请求时,Elasticsearch会在开始处理请求时获取数据流或索引的快照,并使用internal版本控制删除匹配的文档。如果在拍摄快照和删除操作处理之间文档发生了变化,则会导致版本冲突,删除操作将失败。
版本等于 0 的文档不能使用 delete by query 删除,因为 internal 版本控制不支持 0 作为有效的版本号。
在处理按查询删除请求时,Elasticsearch 会依次执行多个搜索请求,以找到所有需要删除的匹配文档。对于每一批匹配的文档,会执行一个批量删除请求。如果搜索或批量请求被拒绝,请求将最多重试 10 次,并采用指数退避策略。如果达到最大重试限制,处理将停止,所有失败的请求将在响应中返回。任何成功完成的删除请求仍然有效,它们不会被回滚。
您可以选择计算版本冲突,而不是停止并返回,通过将conflicts设置为proceed。请注意,如果您选择计算版本冲突,操作可能会尝试从源中删除比max_docs更多的文档,直到它成功删除了max_docs个文档,或者它已经遍历了源查询中的每个文档。
刷新分片
edit指定refresh参数会在请求完成后刷新所有参与删除查询的分片。这与删除API的refresh参数不同,后者只会刷新接收到删除请求的分片。与删除API不同,它不支持wait_for。
异步运行按查询删除
edit如果请求包含 wait_for_completion=false,Elasticsearch
会执行一些预检操作,启动请求,并返回一个
任务,您可以使用它来取消或获取任务的状态。Elasticsearch 会创建一个
记录此任务的文档,路径为 .tasks/task/${taskId}。当您完成任务后,应删除任务文档,以便 Elasticsearch 可以回收空间。
等待活动分片
editwait_for_active_shards 控制在进行请求之前必须处于活动状态的分片副本数量。详情请参阅 活动分片。timeout 控制每个写请求等待不可用分片变为可用的时间。两者的作用方式与 批量 API 中的工作方式完全相同。按查询删除使用滚动搜索,因此您还可以指定 scroll 参数来控制它保持搜索上下文活动的时间,例如 ?scroll=10m。默认值为 5 分钟。
限制删除请求
edit要控制按查询删除发出批量删除操作的速率,您可以将requests_per_second设置为任何正的小数。这会在每个批次中加入等待时间以限制速率。将requests_per_second设置为-1以禁用限制。
节流使用批处理之间的等待时间,以便内部滚动请求可以有一个超时时间,该超时时间考虑了请求填充。填充时间是批处理大小除以requests_per_second与写入时间之差。默认情况下,批处理大小为1000,因此如果requests_per_second设置为500:
target_time = 1000 / 500 per second = 2 seconds wait_time = target_time - write_time = 2 seconds - .5 seconds = 1.5 seconds
由于批处理是以单个 _bulk 请求发出的,较大的批处理大小会导致 Elasticsearch 创建许多请求并在开始下一组之前等待。
这种方式是“突发性”的,而不是“平滑”的。
路径参数
edit-
<target> -
(可选,字符串) 要搜索的数据流、索引和别名的逗号分隔列表。支持通配符 (
*)。要搜索所有数据流或索引,请省略此参数或使用* 或 `_all。
查询参数
edit-
allow_no_indices -
(可选, 布尔值) 如果为
false,当任何通配符表达式、 索引别名或_all值仅针对缺失或关闭的索引时,请求将返回错误。 即使请求针对其他打开的索引,此行为也适用。例如,如果一个请求针对foo*,bar*,但没有任何索引以bar开头,即使存在以foo开头的索引,请求也会返回错误。默认为
true。 -
analyzer -
(可选, 字符串) 用于查询字符串的分析器。
此参数只能在指定了
q查询字符串参数时使用。 -
analyze_wildcard -
(可选,布尔值) 如果为
true,通配符和前缀查询会被分析。 默认为false。此参数只能在指定了
q查询字符串参数时使用。 -
conflicts -
(可选,字符串) 如果按查询删除遇到版本冲突时该怎么办:
中止或继续。默认为中止。 -
default_operator -
(可选,字符串) 查询字符串查询的默认操作符:AND 或 OR。 默认为
OR。此参数只能在指定了
q查询字符串参数时使用。 -
df -
(可选,字符串) 在查询字符串中没有给出字段前缀时,用作默认字段的字段。
此参数只能在指定了
q查询字符串参数时使用。 -
expand_wildcards -
(可选,字符串) 通配符模式可以匹配的索引类型。如果请求可以针对数据流,此参数确定通配符表达式是否匹配隐藏的数据流。支持逗号分隔的值,例如
open,hidden。有效值为:-
all - 匹配任何数据流或索引,包括 隐藏的 数据流和索引。
-
open - 匹配开放的、非隐藏的索引。同时也匹配任何非隐藏的数据流。
-
closed - 匹配关闭的、非隐藏的索引。同时也匹配任何非隐藏的数据流。数据流不能被关闭。
-
hidden -
匹配隐藏的数据流和隐藏的索引。必须与
open、closed或两者结合使用。 -
none - 不接受通配符模式。
默认为
open。 -
-
ignore_unavailable -
(可选,布尔值) 如果为
false,则当请求目标是一个缺失或关闭的索引时,请求将返回错误。默认为false。 -
lenient -
(可选,布尔值) 如果为
true,查询字符串中基于格式的查询失败(例如向数值字段提供文本)将被忽略。默认为false。此参数只能在指定了
q查询字符串参数时使用。 -
max_docs -
(可选,整数) 要处理的文档的最大数量。默认为所有文档。当设置为小于或等于
scroll_size的值时,操作将不会使用滚动来检索结果。 -
preference - (可选,字符串) 指定操作应在其上执行的节点或分片。默认情况下是随机的。
-
q - (可选,字符串) 使用Lucene查询字符串语法的查询。
-
request_cache -
(可选,布尔值) 如果为
true,则为此请求使用请求缓存。 默认为索引级别的设置。 -
refresh -
(可选,布尔值) 如果为
true,Elasticsearch 会在请求完成后刷新涉及到的所有分片。默认为false。 -
requests_per_second -
(可选, 整数) 每秒的子请求限制。
默认为
-1(无限制)。 -
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
scroll - (可选, 时间值) 保留搜索上下文的时间段。请参阅 滚动搜索结果。
-
scroll_size - (可选, 整数) 滚动请求的大小,用于驱动操作。 默认为 1000。
-
search_type -
(可选,字符串)搜索操作的类型。可用选项:
-
query_then_fetch -
dfs_query_then_fetch
-
-
search_timeout - (可选,时间单位) 每个搜索请求的显式超时时间。 默认为无超时。
-
slices - (Optional, integer) The number of slices this task should be divided into. Defaults to 1 meaning the task isn’t sliced into subtasks.
-
sort - (可选,字符串) 以逗号分隔的 <字段>:<方向> 对列表。
-
stats -
(可选,字符串) 用于日志记录和统计目的的请求的特定
tag。 -
terminate_after -
(可选,整数) 每个分片收集的最大文档数。如果查询达到此限制,Elasticsearch 会提前终止查询。Elasticsearch 在排序之前收集文档。
谨慎使用。Elasticsearch将此参数应用于处理请求的每个分片。如果可能,让Elasticsearch自动执行早期终止。避免为针对具有跨多个数据层的后备索引的数据流请求指定此参数。
-
timeout -
(可选,时间单位)
每个删除请求等待活动分片的时间段。默认为
1m(一分钟)。 -
version -
(可选,布尔值) 如果
true,则在命中结果中返回文档版本。 -
wait_for_active_shards -
(可选,字符串) 在继续操作之前,必须处于活动状态的每个分片的副本数量。设置为
all或任何非负整数,最大不超过索引中每个分片的副本总数(number_of_replicas+1)。默认为1,表示仅等待每个主分片处于活动状态。请参阅Active shards。
响应体
editJSON响应看起来像这样:
{
"took" : 147,
"timed_out": false,
"total": 119,
"deleted": 119,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures" : [ ]
}
-
took - The number of milliseconds from start to end of the whole operation.
-
timed_out -
如果在按查询删除执行期间执行的任何请求超时,则此标志设置为
true。 -
total - The number of documents that were successfully processed.
-
deleted - The number of documents that were successfully deleted.
-
batches - 删除查询拉回的滚动响应数量。
-
version_conflicts - The number of version conflicts that the delete by query hit.
-
noops - 此字段对于按查询删除始终等于零。它仅存在,以便按查询删除、按查询更新和重新索引API返回具有相同结构的响应。
-
retries -
delete by query 尝试的重试次数。
bulk是重试的批量操作次数,search是重试的搜索操作次数。 -
throttled_millis -
请求为了符合
requests_per_second而休眠的毫秒数。 -
requests_per_second - 每秒在删除查询期间有效执行的请求数。
-
throttled_until_millis -
此字段在
_delete_by_query响应中应始终为零。它仅在使用 任务管理 API 时才有意义,其中它指示下一次(自纪元以来的毫秒数)将再次执行限流请求,以符合requests_per_second。 -
failures -
如果在处理过程中出现任何不可恢复的错误,则会返回失败数组。如果此数组非空,则请求因这些失败而中止。按查询删除是使用批处理实现的,任何失败都会导致整个过程中止,但当前批处理中的所有失败都会被收集到数组中。您可以使用
conflicts选项来防止重新索引在版本冲突时中止。
示例
edit从 my-index-000001 数据流或索引中删除所有文档:
POST my-index-000001/_delete_by_query?conflicts=proceed
{
"query": {
"match_all": {}
}
}
从多个数据流或索引中删除文档:
POST /my-index-000001,my-index-000002/_delete_by_query
{
"query": {
"match_all": {}
}
}
将按查询删除操作限制为具有特定路由值的分片:
POST my-index-000001/_delete_by_query?routing=1
{
"query": {
"range" : {
"age" : {
"gte" : 10
}
}
}
}
默认情况下,_delete_by_query 使用 1000 的滚动批次。您可以使用 scroll_size URL 参数更改批次大小:
POST my-index-000001/_delete_by_query?scroll_size=5000
{
"query": {
"term": {
"user.id": "kimchy"
}
}
}
使用唯一属性删除文档:
POST my-index-000001/_delete_by_query
{
"query": {
"term": {
"user.id": "kimchy"
}
},
"max_docs": 1
}
手动切片
edit通过提供切片ID和切片总数,手动切片删除查询:
POST my-index-000001/_delete_by_query
{
"slice": {
"id": 0,
"max": 2
},
"query": {
"range": {
"http.response.bytes": {
"lt": 2000000
}
}
}
}
POST my-index-000001/_delete_by_query
{
"slice": {
"id": 1,
"max": 2
},
"query": {
"range": {
"http.response.bytes": {
"lt": 2000000
}
}
}
}
你可以通过以下方式验证其有效性:
GET _refresh
POST my-index-000001/_search?size=0&filter_path=hits.total
{
"query": {
"range": {
"http.response.bytes": {
"lt": 2000000
}
}
}
}
这会得到一个合理的总计,如下所示:
{
"hits": {
"total" : {
"value": 0,
"relation": "eq"
}
}
}
使用自动分片
edit您还可以让 delete-by-query 自动并行化,使用 sliced scroll 在 _id 上进行切片。使用 slices 来指定要使用的切片数量:
POST my-index-000001/_delete_by_query?refresh&slices=5
{
"query": {
"range": {
"http.response.bytes": {
"lt": 2000000
}
}
}
}
你也可以验证以下内容是否有效:
POST my-index-000001/_search?size=0&filter_path=hits.total
{
"query": {
"range": {
"http.response.bytes": {
"lt": 2000000
}
}
}
}
结果会得到一个合理的 total,如下所示:
{
"hits": {
"total" : {
"value": 0,
"relation": "eq"
}
}
}
将 slices 设置为 auto 将让 Elasticsearch 选择要使用的切片数量。此设置将每个分片使用一个切片,直到达到某个限制。如果有多个源数据流或索引,它将根据分片数量最少的索引或后备索引选择切片数量。
将slices添加到_delete_by_query只是自动化了上述部分中使用的手动过程,创建了子请求,这意味着它有一些特殊之处:
-
您可以在
任务 API 中看到这些请求。这些子请求是带有
slices的请求的“子”任务。 -
获取带有
slices的请求的任务状态仅包含已完成切片的状态。 - 这些子请求可以单独处理,例如取消和重新限流。
-
重新限流带有
slices的请求将按比例重新限流未完成的子请求。 -
取消带有
slices的请求将取消每个子请求。 -
由于
slices的性质,每个子请求不会获得完全均匀的文档部分。所有文档都将被处理,但某些切片可能比其他切片大。预计较大的切片会有更均匀的分布。 -
带有
slices的请求上的参数(如requests_per_second和max_docs)会按比例分配给每个子请求。结合上述关于分布不均匀的点,您应该得出结论,使用max_docs和slices可能不会导致恰好删除max_docs个文档。 - 每个子请求都会获得源数据流或索引的略有不同的快照,尽管这些都是在几乎相同的时间获取的。
更改请求的限流
edit可以通过使用_rethrottle API在运行的删除查询中更改requests_per_second的值。加快查询速度的重新调整会立即生效,但减慢查询速度的重新调整会在完成当前批次后生效,以防止滚动超时。
POST _delete_by_query/r1A2WoRbTwKZ516z6NEs5A:36619/_rethrottle?requests_per_second=-1
使用任务管理 API获取任务 ID。将requests_per_second设置为任何正的小数值或-1以禁用限流。
获取按查询删除操作的状态
edit使用任务管理 API来获取按查询删除操作的状态:
GET _tasks?detailed=true&actions=*/delete/byquery
响应看起来像:
{
"nodes" : {
"r1A2WoRbTwKZ516z6NEs5A" : {
"name" : "r1A2WoR",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"attributes" : {
"testattr" : "test",
"portsfile" : "true"
},
"tasks" : {
"r1A2WoRbTwKZ516z6NEs5A:36619" : {
"node" : "r1A2WoRbTwKZ516z6NEs5A",
"id" : 36619,
"type" : "transport",
"action" : "indices:data/write/delete/byquery",
"status" : {
"total" : 6154,
"updated" : 0,
"created" : 0,
"deleted" : 3500,
"batches" : 36,
"version_conflicts" : 0,
"noops" : 0,
"retries": 0,
"throttled_millis": 0
},
"description" : ""
}
}
}
}
}
|
此对象包含实际状态。它就像响应的JSON,但增加了一个重要的字段 |
通过任务ID,您可以直接查找任务:
GET /_tasks/r1A2WoRbTwKZ516z6NEs5A:36619
这个API的优点是它与wait_for_completion=false集成,可以透明地返回已完成任务的状态。如果任务已完成并且在该任务上设置了wait_for_completion=false,那么它将返回results或error字段。这个功能的代价是wait_for_completion=false在.tasks/task/${taskId}处创建的文档。是否删除该文档由您决定。
取消按查询删除操作
edit任何通过查询进行的删除操作都可以使用任务取消 API来取消:
POST _tasks/r1A2WoRbTwKZ516z6NEs5A:36619/_cancel
任务ID可以通过任务管理API找到。
取消操作应快速进行,但可能需要几秒钟。上述任务状态API将继续列出删除查询任务,直到该任务检查到它已被取消并终止自身。
更新 API
edit使用指定的脚本更新文档。
请求
editPOST /
描述
edit使您能够编写脚本来更新文档。脚本可以更新、删除或跳过修改文档。更新API还支持传递部分文档,该部分文档将与现有文档合并。要完全替换现有文档,请使用index API。
此操作:
- 从索引中获取文档(与分片共存)。
- 运行指定的脚本。
- 索引结果。
文档仍然需要重新索引,但使用 update 可以减少一些网络往返并降低在 GET 和索引操作之间发生版本冲突的可能性。
必须启用 _source 字段才能使用 update。除了 _source 之外,
您还可以通过 ctx 映射访问以下变量:_index、
_type、_id、_version、_routing 和 _now(当前时间戳)。
路径参数
edit-
<index> - (必需,字符串) 目标索引的名称。默认情况下,如果索引不存在,则会自动创建。有关更多信息,请参阅 自动创建数据流和索引。
-
<_id> - (必需, 字符串) 用于更新文档的唯一标识符。
查询参数
edit-
if_seq_no - (可选,整数) 仅在文档具有此序列号时执行操作。请参阅乐观并发控制。
-
if_primary_term - (可选,整数) 仅在文档具有此主项时执行操作。请参阅乐观并发控制。
-
lang -
(可选,字符串) 脚本语言。默认:
painless。 -
require_alias -
(可选,布尔值) 如果为
true,目标必须是一个 索引别名。 默认为false。 -
refresh -
(可选,枚举) 如果
true,Elasticsearch 会刷新受影响的 shards 以使此操作对搜索可见,如果wait_for则等待刷新以使此操作对搜索可见,如果false则不对刷新做任何操作。 有效值:true、false、wait_for。默认值:false。 -
retry_on_conflict - (可选,整数) 指定当发生冲突时,操作应重试的次数。默认值:0。
-
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
_source -
(可选,列表) 设置为
false以禁用源检索(默认:true)。 你也可以指定一个逗号分隔的字段列表,以检索你想要的字段。 -
_source_excludes - (可选,列表)指定您想要排除的源字段。
-
_source_includes - (可选,列表)指定您要检索的源字段。
-
timeout -
(可选,时间单位) 等待以下操作的时间段:
默认为
1m(一分钟)。这保证了 Elasticsearch 在失败前至少等待超时时间。实际等待时间可能会更长,特别是在多次等待发生时。 -
wait_for_active_shards -
(可选,字符串) 在继续操作之前,必须处于活动状态的每个分片的副本数量。设置为
all或任何非负整数,最大不超过索引中每个分片的副本总数(number_of_replicas+1)。默认为1,表示仅等待每个主分片处于活动状态。请参阅Active shards。
示例
edit首先,让我们索引一个简单的文档:
PUT test/_doc/1
{
"counter" : 1,
"tags" : ["red"]
}
要增加计数器,您可以使用以下脚本提交更新请求:
POST test/_update/1
{
"script" : {
"source": "ctx._source.counter += params.count",
"lang": "painless",
"params" : {
"count" : 4
}
}
}
同样地,你可以使用并更新脚本来向标签列表中添加一个标签(这只是一个列表,所以即使标签已经存在,也会被添加):
POST test/_update/1
{
"script": {
"source": "ctx._source.tags.add(params.tag)",
"lang": "painless",
"params": {
"tag": "blue"
}
}
}
您也可以从标签列表中移除一个标签。Painless 函数 remove 接受您想要移除的元素的数组索引。为了避免可能的运行时错误,您首先需要确保该标签存在。如果列表中包含该标签的重复项,此脚本只会移除一个出现项。
POST test/_update/1
{
"script": {
"source": "if (ctx._source.tags.contains(params.tag)) { ctx._source.tags.remove(ctx._source.tags.indexOf(params.tag)) }",
"lang": "painless",
"params": {
"tag": "blue"
}
}
}
您还可以从文档中添加和删除字段。例如,此脚本添加了字段 new_field:
POST test/_update/1
{
"script" : "ctx._source.new_field = 'value_of_new_field'"
}
相反,此脚本移除字段 new_field:
POST test/_update/1
{
"script" : "ctx._source.remove('new_field')"
}
以下脚本从对象字段中移除一个子字段:
POST test/_update/1
{
"script": "ctx._source['my-object'].remove('my-subfield')"
}
除了更新文档,您还可以从脚本内部更改执行的操作。例如,如果 tags 字段包含 green,此请求将删除文档,否则它将不执行任何操作(noop):
POST test/_update/1
{
"script": {
"source": "if (ctx._source.tags.contains(params.tag)) { ctx.op = 'delete' } else { ctx.op = 'noop' }",
"lang": "painless",
"params": {
"tag": "green"
}
}
}
更新文档的一部分
edit以下部分更新向现有文档添加了一个新字段:
POST test/_update/1
{
"doc": {
"name": "new_name"
}
}
如果同时指定了doc和script,那么doc将被忽略。如果你指定了一个脚本更新,请在脚本中包含你想要更新的字段。
检测无操作更新
edit默认情况下,不改变任何内容的更新会检测到它们没有改变任何内容,并返回 "result": "noop":
POST test/_update/1
{
"doc": {
"name": "new_name"
}
}
如果 name 的值已经是 new_name,则更新请求将被忽略,响应中的 result 元素将返回 noop:
{
"_shards": {
"total": 0,
"successful": 0,
"failed": 0
},
"_index": "test",
"_id": "1",
"_version": 2,
"_primary_term": 1,
"_seq_no": 1,
"result": "noop"
}
您可以通过设置 "detect_noop": false 来禁用此行为:
POST test/_update/1
{
"doc": {
"name": "new_name"
},
"detect_noop": false
}
插入或更新
edit如果文档不存在,则将 upsert 元素的内容插入为新文档。如果文档存在,则执行 script:
POST test/_update/1
{
"script": {
"source": "ctx._source.counter += params.count",
"lang": "painless",
"params": {
"count": 4
}
},
"upsert": {
"counter": 1
}
}
脚本化更新插入
edit无论文档是否存在,要运行脚本,请将 scripted_upsert 设置为 true:
POST test/_update/1
{
"scripted_upsert": true,
"script": {
"source": """
if ( ctx.op == 'create' ) {
ctx._source.counter = params.count
} else {
ctx._source.counter += params.count
}
""",
"params": {
"count": 4
}
},
"upsert": {}
}
文档作为更新插入
edit与其发送一个部分的 doc 加上一个 upsert 文档,你可以将 doc_as_upsert 设置为 true,以使用 doc 的内容作为 upsert 的值:
POST test/_update/1
{
"doc": {
"name": "new_name"
},
"doc_as_upsert": true
}
使用 ingest pipelines 与 doc_as_upsert 是不被支持的。
按查询更新 API
edit更新与指定查询匹配的文档。 如果没有指定查询,则对数据流或索引中的每个文档执行更新,而不修改源,这对于获取映射更改非常有用。
POST my-index-000001/_update_by_query?conflicts=proceed
请求
editPOST /
描述
edit您可以在请求URI或请求体中指定查询条件,使用与Search API相同的语法。
当您通过查询请求提交更新时,Elasticsearch会在开始处理请求时获取数据流或索引的快照,并使用internal版本控制更新匹配的文档。当版本匹配时,文档会被更新,并且版本号会递增。如果在快照拍摄和更新操作处理之间文档发生了变化,这将导致版本冲突,并且操作会失败。您可以选择通过将conflicts设置为proceed来计算版本冲突,而不是停止并返回。请注意,如果您选择计算版本冲突,操作可能会尝试从源中更新比max_docs更多的文档,直到它成功更新了max_docs个文档,或者它已经遍历了源查询中的每个文档。
版本等于 0 的文档不能使用更新查询进行更新,因为 internal 版本控制不支持 0 作为有效的版本号。
在处理通过查询请求进行更新的过程中,Elasticsearch会依次执行多个搜索请求以找到所有匹配的文档。 对于每一批匹配的文档,都会执行批量更新请求。 任何查询或更新失败都会导致通过查询请求的更新失败,并且这些失败会在响应中显示。 任何成功完成的更新请求仍然有效,它们不会被回滚。
刷新分片
edit指定refresh参数会在请求完成后刷新所有分片。
这与更新API的refresh参数不同,后者仅导致接收请求的分片被刷新。与更新API不同,它不支持
wait_for。
异步运行按查询更新
edit如果请求包含 wait_for_completion=false,Elasticsearch
会执行一些预检操作,启动请求,并返回一个
任务,您可以使用它来取消或获取任务的状态。
Elasticsearch 会在 .tasks/task/${taskId} 处为此任务创建一个文档记录。
等待活动分片
editwait_for_active_shards 控制在进行请求之前必须有多少个分片的副本处于活动状态。详情请参阅 活动分片。timeout 控制每个写请求等待不可用分片变为可用的时间。两者的作用方式与 批量 API 中的工作方式完全相同。按查询更新使用滚动搜索,因此您还可以指定 scroll 参数来控制它保持搜索上下文活动的时间,例如 ?scroll=10m。默认值为 5 分钟。
限制更新请求
edit要控制通过查询更新发出批量更新操作的速率,您可以将requests_per_second设置为任何正的小数。这会在每个批次中添加等待时间以限制速率。将requests_per_second设置为-1以禁用限制。
节流使用批处理之间的等待时间,以便内部滚动请求可以有一个超时时间,该超时时间考虑了请求填充。填充时间是批处理大小除以requests_per_second与写入时间之差。默认情况下,批处理大小为1000,因此如果requests_per_second设置为500:
target_time = 1000 / 500 per second = 2 seconds wait_time = target_time - write_time = 2 seconds - .5 seconds = 1.5 seconds
由于批处理是以单个 _bulk 请求发出的,较大的批处理大小会导致 Elasticsearch 创建许多请求并在开始下一组之前等待。
这种方式是“突发性”的,而不是“平滑”的。
路径参数
edit-
<target> -
(可选,字符串) 要搜索的数据流、索引和别名的逗号分隔列表。支持通配符 (
*)。要搜索所有数据流或索引,请省略此参数或使用*或_all。
查询参数
edit-
allow_no_indices -
(可选, 布尔值) 如果为
false,当任何通配符表达式、 索引别名或_all值仅针对缺失或关闭的索引时,请求将返回错误。 即使请求针对其他打开的索引,此行为也适用。例如,如果一个请求针对foo*,bar*,但没有任何索引以bar开头,即使存在以foo开头的索引,请求也会返回错误。默认为
true。 -
analyzer -
(可选, 字符串) 用于查询字符串的分析器。
此参数只能在指定了
q查询字符串参数时使用。 -
analyze_wildcard -
(可选,布尔值) 如果为
true,通配符和前缀查询会被分析。 默认为false。此参数只能在指定了
q查询字符串参数时使用。 -
conflicts -
(可选,字符串) 如果在按查询更新时遇到版本冲突,应采取的操作:
中止或继续。默认为中止。 -
default_operator -
(可选,字符串) 查询字符串查询的默认操作符:AND 或 OR。 默认为
OR。此参数只能在指定了
q查询字符串参数时使用。 -
df -
(可选,字符串) 在查询字符串中没有给出字段前缀时,用作默认字段的字段。
此参数只能在指定了
q查询字符串参数时使用。 -
expand_wildcards -
(可选,字符串) 通配符模式可以匹配的索引类型。如果请求可以针对数据流,此参数确定通配符表达式是否匹配隐藏的数据流。支持逗号分隔的值,例如
open,hidden。有效值为:-
all - 匹配任何数据流或索引,包括 隐藏的 数据流和索引。
-
open - 匹配开放的、非隐藏的索引。同时也匹配任何非隐藏的数据流。
-
closed - 匹配关闭的、非隐藏的索引。同时也匹配任何非隐藏的数据流。数据流不能被关闭。
-
hidden -
匹配隐藏的数据流和隐藏的索引。必须与
open、closed或两者结合使用。 -
none - 不接受通配符模式。
默认为
open。 -
-
ignore_unavailable -
(可选,布尔值) 如果为
false,则当请求目标是一个缺失或关闭的索引时,请求将返回错误。默认为false。 -
lenient -
(可选,布尔值) 如果为
true,查询字符串中基于格式的查询失败(例如向数值字段提供文本)将被忽略。默认为false。此参数只能在指定了
q查询字符串参数时使用。 -
max_docs -
(可选,整数) 要处理的文档的最大数量。默认为所有文档。当设置为小于或等于
scroll_size的值时,操作将不会使用滚动来检索结果。 -
pipeline -
(可选,字符串) 用于预处理传入文档的管道 ID。如果索引指定了默认的摄取管道,则将值设置为
_none将禁用此请求的默认摄取管道。如果配置了最终管道,它将始终运行,无论此参数的值如何。 -
preference - (可选,字符串) 指定操作应在其上执行的节点或分片。默认情况下是随机的。
-
q - (可选,字符串) 使用Lucene查询字符串语法的查询。
-
request_cache -
(可选,布尔值) 如果为
true,则为此请求使用请求缓存。 默认为索引级别的设置。 -
refresh -
(可选,布尔值)
如果设置为
true,Elasticsearch会刷新受影响的 shards,以使操作对搜索可见。默认为false。 -
requests_per_second -
(可选, 整数) 每秒的子请求限制。
默认为
-1(无限制)。 -
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
scroll - (可选, 时间值) 保留搜索上下文的时间段。请参阅 滚动搜索结果。
-
scroll_size - (可选, 整数) 滚动请求的大小,用于驱动操作。 默认为 1000。
-
search_type -
(可选,字符串)搜索操作的类型。可用选项:
-
query_then_fetch -
dfs_query_then_fetch
-
-
search_timeout - (可选,时间单位) 每个搜索请求的显式超时时间。 默认为无超时。
-
slices - (可选, 整数) 此任务应被划分的切片数量。 默认为1,表示任务不会被划分为子任务。
-
sort - (可选,字符串) 以逗号分隔的 <字段>:<方向> 对列表。
-
stats -
(可选,字符串) 用于日志记录和统计目的的请求的特定
tag。 -
terminate_after -
(可选,整数) 每个分片收集的最大文档数。如果查询达到此限制,Elasticsearch 会提前终止查询。Elasticsearch 在排序之前收集文档。
谨慎使用。Elasticsearch将此参数应用于处理请求的每个分片。如果可能,让Elasticsearch自动执行早期终止。避免为针对具有跨多个数据层的后备索引的数据流请求指定此参数。
-
timeout -
(可选, 时间单位) 每个更新请求等待以下操作的时间段:
- 动态映射更新
- 等待活动分片
默认为
1m(一分钟)。这保证了 Elasticsearch 在失败前至少等待超时时间。实际等待时间可能会更长,特别是在多次等待发生时。 -
version -
(可选,布尔值) 如果
true,则在命中结果中返回文档版本。 -
wait_for_active_shards -
(可选,字符串) 在继续操作之前,必须处于活动状态的每个分片的副本数量。设置为
all或任何非负整数,最大不超过索引中每个分片的副本总数(number_of_replicas+1)。默认为1,表示仅等待每个主分片处于活动状态。请参阅Active shards。
响应体
edit-
took - 整个操作从开始到结束的毫秒数。
-
timed_out -
如果在查询执行期间执行的任何请求超时,则此标志设置为
true。 -
total - 成功处理的文档数量。
-
updated - 成功更新的文档数量。
-
deleted - 成功删除的文档数量。
-
batches - 通过查询更新拉回的滚动响应数量。
-
version_conflicts - 更新查询遇到的版本冲突数量。
-
noops -
由于用于更新查询的脚本返回了
ctx.op的noop值,因此被忽略的文档数量。 -
retries -
update by query 尝试的重试次数。
bulk是重试的批量操作次数,search是重试的搜索操作次数。 -
throttled_millis -
请求为了符合
requests_per_second而休眠的毫秒数。 -
requests_per_second - 每次查询更新期间有效执行的每秒请求数。
-
throttled_until_millis -
此字段在
_update_by_query响应中应始终为零。它仅在使用 Task API 时才有意义,其中它指示下一次(自纪元以来的毫秒数)将再次执行限流请求,以便符合requests_per_second。 -
failures -
如果在处理过程中出现任何不可恢复的错误,则返回失败数组。如果此数组非空,则请求因这些失败而中止。
按查询更新是通过批处理实现的。任何失败都会导致整个过程中止,但当前批次中的所有失败都会被收集到数组中。您可以使用
conflicts选项来防止在版本冲突时中止重新索引。
示例
edit最简单的 _update_by_query 用法是对数据流或索引中的每个文档执行更新,而不更改源文档。这对于 获取新属性 或进行其他在线映射更改非常有用。
要更新选定的文档,请在请求体中指定查询:
POST my-index-000001/_update_by_query?conflicts=proceed
{
"query": {
"term": {
"user.id": "kimchy"
}
}
}
|
查询必须作为值传递给 |
更新多个数据流或索引中的文档:
POST my-index-000001,my-index-000002/_update_by_query
限制更新查询操作到具有特定路由值的分片:
POST my-index-000001/_update_by_query?routing=1
默认情况下,更新查询使用1000的滚动批次。
您可以使用scroll_size参数更改批次大小:
POST my-index-000001/_update_by_query?scroll_size=100
使用唯一属性更新文档:
POST my-index-000001/_update_by_query
{
"query": {
"term": {
"user.id": "kimchy"
}
},
"max_docs": 1
}
更新文档源
edit通过查询更新支持使用脚本来更新文档源。
例如,以下请求将my-index-000001中所有user.id为kimchy的文档的count字段增加:
POST my-index-000001/_update_by_query
{
"script": {
"source": "ctx._source.count++",
"lang": "painless"
},
"query": {
"term": {
"user.id": "kimchy"
}
}
}
请注意,此示例中未指定 conflicts=proceed。在这种情况下,版本冲突应停止进程,以便您可以处理失败。
与Update API一样,您可以设置ctx.op来更改执行的操作:
|
|
如果您的脚本决定不需要进行任何更改,请设置 |
|
|
如果您的脚本决定应删除文档,请设置 |
按查询更新仅支持 index、noop 和 delete。
将 ctx.op 设置为其他任何值都是错误。将任何其他字段设置在 ctx 中都是错误。
此 API 仅允许您修改匹配文档的源,您无法移动它们。
使用摄取管道更新文档
edit通过查询更新可以使用Ingest pipelines功能,通过指定pipeline:
PUT _ingest/pipeline/set-foo
{
"description" : "sets foo",
"processors" : [ {
"set" : {
"field": "foo",
"value": "bar"
}
} ]
}
POST my-index-000001/_update_by_query?pipeline=set-foo
获取按查询更新操作的状态
edit您可以通过任务 API获取所有正在运行的更新查询请求的状态:
GET _tasks?detailed=true&actions=*byquery
响应看起来像:
{
"nodes" : {
"r1A2WoRbTwKZ516z6NEs5A" : {
"name" : "r1A2WoR",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"attributes" : {
"testattr" : "test",
"portsfile" : "true"
},
"tasks" : {
"r1A2WoRbTwKZ516z6NEs5A:36619" : {
"node" : "r1A2WoRbTwKZ516z6NEs5A",
"id" : 36619,
"type" : "transport",
"action" : "indices:data/write/update/byquery",
"status" : {
"total" : 6154,
"updated" : 3500,
"created" : 0,
"deleted" : 0,
"batches" : 4,
"version_conflicts" : 0,
"noops" : 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0
},
"description" : ""
}
}
}
}
}
|
此对象包含实际状态。它就像响应的JSON,但增加了一个重要的字段 |
通过任务ID,您可以直接查找任务。以下示例检索有关任务 r1A2WoRbTwKZ516z6NEs5A:36619 的信息:
GET /_tasks/r1A2WoRbTwKZ516z6NEs5A:36619
这个API的优势在于它与wait_for_completion=false集成,能够透明地返回已完成任务的状态。如果任务已完成并且设置了wait_for_completion=false,那么它将返回一个results或一个error字段。这个功能的代价是wait_for_completion=false在.tasks/task/${taskId}处创建的文档。是否删除该文档由您决定。
取消按查询更新操作
edit任何通过查询进行的更新都可以使用任务取消 API来取消:
POST _tasks/r1A2WoRbTwKZ516z6NEs5A:36619/_cancel
任务ID可以通过任务管理API找到。
取消操作应快速进行,但可能需要几秒钟。上述任务状态API将继续列出查询更新任务,直到该任务检查到已被取消并终止自身。
更改请求的限流
edit可以通过使用 _rethrottle API 在运行的更新查询中更改 requests_per_second 的值:
POST _update_by_query/r1A2WoRbTwKZ516z6NEs5A:36619/_rethrottle?requests_per_second=-1
任务ID可以通过任务管理API找到。
就像在 _update_by_query API 上设置它一样,requests_per_second 可以是 -1 以禁用限流,或者是任何小数,如 1.7 或 12 以限制到该水平。加快查询速度的重新限流会立即生效,但减慢查询速度的重新限流将在完成当前批次后生效。这可以防止滚动超时。
手动切片
edit通过为每个请求提供切片ID和切片总数,手动按查询进行切片更新:
POST my-index-000001/_update_by_query
{
"slice": {
"id": 0,
"max": 2
},
"script": {
"source": "ctx._source['extra'] = 'test'"
}
}
POST my-index-000001/_update_by_query
{
"slice": {
"id": 1,
"max": 2
},
"script": {
"source": "ctx._source['extra'] = 'test'"
}
}
你可以通过以下方式验证其有效性:
GET _refresh POST my-index-000001/_search?size=0&q=extra:test&filter_path=hits.total
这会得到一个合理的总计,如下所示:
{
"hits": {
"total": {
"value": 120,
"relation": "eq"
}
}
}
使用自动切片
edit您还可以通过使用切片滚动在_id上进行切片,让查询更新自动并行化。使用slices来指定要使用的切片数量:
POST my-index-000001/_update_by_query?refresh&slices=5
{
"script": {
"source": "ctx._source['extra'] = 'test'"
}
}
你也可以验证以下内容是否有效:
POST my-index-000001/_search?size=0&q=extra:test&filter_path=hits.total
这会得到一个合理的总计,如下所示:
{
"hits": {
"total": {
"value": 120,
"relation": "eq"
}
}
}
将 slices 设置为 auto 将让 Elasticsearch 选择要使用的切片数量。此设置将每个分片使用一个切片,直到达到某个限制。如果有多个源数据流或索引,它将根据分片数量最少的索引或后备索引选择切片数量。
将slices添加到_update_by_query只是自动化了上述部分中使用的手动过程,创建了子请求,这意味着它有一些特殊之处:
-
您可以在
任务API中看到这些请求。这些子请求是带有
slices的请求任务的“子”任务。 -
获取带有
slices的请求任务的状态仅包含已完成切片的状态。 - 这些子请求可以单独寻址,用于取消和重新限流等操作。
-
重新限流带有
slices的请求将按比例重新限流未完成的子请求。 -
取消带有
slices的请求将取消每个子请求。 -
由于
slices的性质,每个子请求不会获得完全均匀的文档部分。所有文档都将被处理,但某些切片可能比其他切片大。预计较大的切片会有更均匀的分布。 -
带有
slices的请求中的参数,如requests_per_second和max_docs,会按比例分配给每个子请求。结合上述关于分布不均匀的点,您应该得出结论,使用max_docs和slices可能不会导致恰好max_docs个文档被更新。 - 每个子请求都会获得源数据流或索引的略有不同的快照,尽管这些都是在几乎相同的时间获取的。
选择一个新属性
edit假设你创建了一个没有动态映射的索引,填充了数据,然后添加了一个映射值以从数据中提取更多字段:
PUT test
{
"mappings": {
"dynamic": false,
"properties": {
"text": {"type": "text"}
}
}
}
POST test/_doc?refresh
{
"text": "words words",
"flag": "bar"
}
POST test/_doc?refresh
{
"text": "words words",
"flag": "foo"
}
PUT test/_mapping
{
"properties": {
"text": {"type": "text"},
"flag": {"type": "text", "analyzer": "keyword"}
}
}
搜索数据将不会找到任何内容:
POST test/_search?filter_path=hits.total
{
"query": {
"match": {
"flag": "foo"
}
}
}
{
"hits" : {
"total": {
"value": 0,
"relation": "eq"
}
}
}
但您可以发出一个_update_by_query请求来获取新的映射:
POST test/_update_by_query?refresh&conflicts=proceed
POST test/_search?filter_path=hits.total
{
"query": {
"match": {
"flag": "foo"
}
}
}
{
"hits" : {
"total": {
"value": 1,
"relation": "eq"
}
}
}
在向多字段添加字段时,您可以执行完全相同的操作。
多获取 (mget) API
edit通过ID检索多个JSON文档。
GET /_mget
{
"docs": [
{
"_index": "my-index-000001",
"_id": "1"
},
{
"_index": "my-index-000001",
"_id": "2"
}
]
}
路径参数
edit-
<index> -
(可选,字符串) 当指定
ids时,用于检索文档的索引名称,或者当docs数组中的文档未指定索引时使用的索引名称。
查询参数
edit-
preference - (可选,字符串) 指定操作应在其上执行的节点或分片。默认情况下是随机的。
-
realtime -
(可选,布尔值) 如果为
true,则请求是实时的,而不是近实时的。 默认为true。请参阅Realtime。 -
refresh -
(可选,布尔值) 如果为
true,请求会在检索文档之前刷新相关的分片。默认为false。 -
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
stored_fields -
(可选,字符串)
一个以逗号分隔的
存储字段列表,包含在响应中。 -
_source -
(可选,字符串) 返回
_source字段与否,或者返回的字段列表。 -
_source_excludes -
(可选,字符串) 一个逗号分隔的列表,用于从响应中排除源字段。
您也可以使用此参数从
_source_includes查询参数中指定的子集中排除字段。如果
_source参数为false,则忽略此参数。 -
_source_includes -
(可选,字符串) 一个逗号分隔的源字段列表,用于包含在响应中。
如果指定了此参数,则仅返回这些源字段。您可以使用
_source_excludes查询参数从此子集中排除字段。如果
_source参数为false,则忽略此参数。
请求体
edit-
docs -
(可选,数组) 您想要检索的文档。 如果请求 URI 中未指定索引,则此项为必填项。 您可以为每个文档指定以下属性:
-
_id - (必填,字符串) 唯一的文档 ID。
-
_index - (可选,字符串) 包含文档的索引。 如果请求 URI 中未指定索引,则此项为必填项。
-
routing - (可选,字符串) 文档所在主分片的键。 如果在索引期间使用了路由,则此项为必填项。
-
_source -
(可选,布尔值) 如果为
false,则排除所有_source字段。默认为true。-
source_include -
(可选,数组) 要从
_source字段中提取并返回的字段。 -
source_exclude -
(可选,数组) 要从返回的
_source字段中排除的字段。
-
-
_stored_fields - (可选,数组) 您想要检索的存储字段。
-
-
ids - (可选, 数组) 您想要检索的文档的ID。 当请求URI中指定了索引时允许使用。
示例
edit通过ID获取文档
edit如果在请求URI中指定了一个索引,则请求体中只需要文档ID:
GET /my-index-000001/_mget
{
"docs": [
{
"_id": "1"
},
{
"_id": "2"
}
]
}
您可以使用ids元素来简化请求:
GET /my-index-000001/_mget
{
"ids" : ["1", "2"]
}
过滤源字段
edit默认情况下,每个文档都会返回_source字段(如果已存储)。
使用_source、_source_include或source_exclude属性来
过滤为特定文档返回的字段。
您可以在请求URI中包含_source、_source_includes和_source_excludes查询参数,以指定在没有每个文档指令时使用的默认值。
例如,以下请求将文档1的_source设置为false以完全排除源,检索文档2的field3和field4,并检索文档3的user字段但过滤掉user.location字段。
GET /_mget
{
"docs": [
{
"_index": "test",
"_id": "1",
"_source": false
},
{
"_index": "test",
"_id": "2",
"_source": [ "field3", "field4" ]
},
{
"_index": "test",
"_id": "3",
"_source": {
"include": [ "user" ],
"exclude": [ "user.location" ]
}
}
]
}
获取存储的字段
edit使用 stored_fields 属性来指定您想要检索的存储字段集。任何请求的未存储字段都将被忽略。
您可以在请求 URI 中包含 stored_fields 查询参数,以指定在没有每文档指令时使用的默认值。
例如,以下请求从文档1中检索field1和field2,并从文档2中检索field3和field4:
GET /_mget
{
"docs": [
{
"_index": "test",
"_id": "1",
"stored_fields": [ "field1", "field2" ]
},
{
"_index": "test",
"_id": "2",
"stored_fields": [ "field3", "field4" ]
}
]
}
以下请求默认从所有文档中检索field1和field2。
这些默认字段会返回给文档1,但对于文档2,它们被覆盖以返回field3和field4。
GET /test/_mget?stored_fields=field1,field2
{
"docs": [
{
"_id": "1"
},
{
"_id": "2",
"stored_fields": [ "field3", "field4" ]
}
]
}
指定文档路由
edit如果在索引期间使用了路由,您需要指定路由值来检索文档。
例如,以下请求从对应于路由键 key1 的分片中获取 test/_doc/2,
并从对应于路由键 key2 的分片中获取 test/_doc/1。
GET /_mget?routing=key1
{
"docs": [
{
"_index": "test",
"_id": "1",
"routing": "key2"
},
{
"_index": "test",
"_id": "2"
}
]
}
批量 API
edit在一个API调用中执行多个索引或删除操作。 这减少了开销,并可以大大提高索引速度。
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
先决条件
edit-
如果启用了Elasticsearch的安全功能,您必须对目标数据流、索引或索引别名具有以下 索引权限:
-
要使用
create操作,您必须具有create_doc、create、index或write索引权限。数据流仅支持create操作。 -
要使用
index操作,您必须具有create、index或write索引权限。 -
要使用
delete操作,您必须具有delete或write索引权限。 -
要使用
update操作,您必须具有index或write索引权限。 -
要使用批量API请求自动创建数据流或索引,您必须具有
auto_configure、create_index或manage索引权限。 -
要使用
refresh参数使批量操作的结果对搜索可见,您必须具有maintenance或manage索引权限。
-
要使用
- 自动数据流创建需要启用数据流的匹配索引模板。请参阅设置数据流。
描述
edit提供了一种在单个请求中执行多个索引、创建、删除和更新操作的方法。
操作在请求体中使用换行符分隔的JSON(NDJSON)结构指定:
action_and_meta_data\n optional_source\n action_and_meta_data\n optional_source\n .... action_and_meta_data\n optional_source\n
The index 和 create 操作期望在下一行有一个源,
并且与标准索引 API 中的 op_type 参数具有相同的语义:
create 如果目标中已存在具有相同 ID 的文档,则会失败,
index 会根据需要添加或替换文档。
数据流仅支持创建操作。要更新或删除数据流中的文档,您必须定位包含该文档的底层索引。请参阅在底层索引中更新或删除文档。
update 期望在下一行指定部分文档、upsert、脚本及其选项。
delete 不期望在下一行有源,并且具有与标准删除 API 相同的语义。
数据的最后一行必须以换行符 \n 结束。
每个换行符前面可以有一个回车符 \r。
当将NDJSON数据发送到 _bulk 端点时,使用 Content-Type 头为
application/json 或 application/x-ndjson。
因为此格式使用字面量 \n 作为分隔符,请确保 JSON 操作和源未进行美化打印。
如果你在请求路径中提供了一个_index参数的操作。
关于格式的说明:这里的想法是使处理速度尽可能快。由于某些操作被重定向到其他节点上的其他分片,因此在接收节点端仅解析action_meta_data。
使用此协议的客户端库应尽量在客户端上实现类似的功能,并尽可能减少缓冲。
在单个批量请求中执行的操作数量没有“正确”的数字。
通过不同的设置进行实验,以找到适合您特定工作负载的最佳大小。
请注意,Elasticsearch 默认将 HTTP 请求的最大大小限制为 100mb,因此客户端必须确保没有请求超过此大小。
不可能索引超过大小限制的单个文档,因此您必须将任何此类文档预处理为较小的部分,然后再将它们发送到 Elasticsearch。
例如,在索引之前将文档拆分为页面或章节,或者将原始二进制数据存储在 Elasticsearch 之外的系统中,并在发送到 Elasticsearch 的文档中用指向外部系统的链接替换原始数据。
客户端支持批量请求
edit一些官方支持的客户端提供了辅助工具,以帮助处理批量请求和重新索引:
- Go
- 参见 esutil.BulkIndexer
- Perl
- 参见 Search::Elasticsearch::Client::5_0::Bulk 和 Search::Elasticsearch::Client::5_0::Scroll
- Python
- 请参阅 elasticsearch.helpers.*
- JavaScript
- 请参阅 client.helpers.*
- .NET
-
参见
BulkAllObservable - PHP
- 请参阅 批量索引
使用cURL提交批量请求
edit如果你正在向 curl 提供文本文件输入,你必须使用 --data-binary 标志,而不是普通的 -d。后者不会保留换行符。示例:
$ cat requests
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
$ curl -s -H "Content-Type: application/x-ndjson" -XPOST localhost:9200/_bulk --data-binary "@requests"; echo
{"took":7, "errors": false, "items":[{"index":{"_index":"test","_id":"1","_version":1,"result":"created","forced_refresh":false}}]}
乐观并发控制
edit每个批量 API 调用中的 index 和 delete 操作都可以在其各自的 action 和 meta data 行中包含 if_seq_no 和 if_primary_term 参数。if_seq_no 和 if_primary_term 参数控制操作如何基于现有文档的最后修改执行。有关更多详细信息,请参阅 乐观并发控制。
版本控制
edit每个批量项都可以使用version字段包含版本值。它自动遵循基于_version映射的索引/删除操作的行为。它还支持version_type(参见版本控制)。
路由
edit每个批量项都可以使用routing字段包含路由值。它自动遵循基于_routing映射的索引/删除操作的行为。
数据流不支持自定义路由,除非它们是在模板中启用了allow_custom_routing设置的情况下创建的。
等待活动分片
edit在进行批量调用时,您可以将 wait_for_active_shards 参数设置为在开始处理批量请求之前,要求最小数量的分片副本处于活动状态。有关更多详细信息和使用示例,请参见 这里。
刷新
edit控制此请求所做的更改何时对搜索可见。请参阅 refresh。
只有接收到批量请求的分片会受到refresh的影响。想象一下,一个包含三个文档的_bulk?refresh=wait_for请求恰好被路由到具有五个分片的索引中的不同分片。该请求只会等待这三个分片刷新。构成索引的其他两个分片根本不参与_bulk请求。
安全性
edit请参阅基于URL的访问控制。
路径参数
edit-
<target> - (可选, 字符串) 要执行批量操作的数据流、索引或索引别名的名称。
查询参数
edit-
list_executed_pipelines -
(可选, 布尔值) 如果为
true, 响应将包括为每个index或create执行的摄取管道。 默认为false。 -
pipeline -
(可选,字符串) 用于预处理传入文档的管道 ID。如果索引指定了默认的摄取管道,则将值设置为
_none将禁用此请求的默认摄取管道。如果配置了最终管道,它将始终运行,无论此参数的值如何。 -
refresh -
(可选,枚举) 如果
true,Elasticsearch 会刷新受影响的 shards 以使此操作对搜索可见,如果wait_for则等待刷新以使此操作对搜索可见,如果false则不对刷新做任何操作。 有效值:true、false、wait_for。默认值:false。 -
require_alias -
(可选,布尔值) 如果
true,请求的操作必须针对索引别名。 默认为false。 -
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
_source -
(可选,字符串) 返回
_source字段与否,或者返回的字段列表。 -
_source_excludes -
(可选,字符串) 一个逗号分隔的列表,用于从响应中排除源字段。
您也可以使用此参数从
_source_includes查询参数中指定的子集中排除字段。如果
_source参数为false,则忽略此参数。 -
_source_includes -
(可选,字符串) 一个逗号分隔的源字段列表,用于包含在响应中。
如果指定了此参数,则仅返回这些源字段。您可以使用
_source_excludes查询参数从此子集中排除字段。如果
_source参数为false,则忽略此参数。 -
timeout -
(可选,时间单位) 每个操作等待以下操作的时间段:
默认为
1m(一分钟)。这保证了 Elasticsearch 在失败前至少等待超时时间。实际等待时间可能会更长,特别是在多次等待发生时。 -
wait_for_active_shards -
(可选,字符串) 在继续操作之前,必须处于活动状态的每个分片的副本数量。设置为
all或任何非负整数,最大不超过索引中每个分片的副本总数(number_of_replicas+1)。默认为1,表示仅等待每个主分片处于活动状态。请参阅Active shards。
请求体
edit请求体包含一个换行符分隔的列表,其中包括创建、删除、索引和更新操作及其相关的源数据。
-
create -
(可选, 字符串) 如果指定的文档不存在,则对其进行索引。 以下行必须包含要索引的源数据。
-
_index -
(可选, 字符串)
数据流、索引或索引别名的名称,以执行操作。如果请求路径中未指定
-
_id - (可选, 字符串) 文档ID。 如果未指定ID,则会自动生成文档ID。
-
list_executed_pipelines -
(可选, 布尔值) 如果为
true,响应将包括已执行的摄取管道。默认为false。 -
require_alias -
(可选, 布尔值)
如果为
true,操作必须针对索引别名。默认为false。 -
dynamic_templates - (可选, 映射) 从字段全名到动态模板名称的映射。 默认为空映射。如果名称匹配动态模板,则无论模板中定义的其他匹配谓词如何,都将应用该模板。如果字段已在映射中定义,则不会使用此参数。
-
-
delete -
(可选, 字符串) 从索引中移除指定的文档。
-
_index -
(可选, 字符串)
要执行操作的索引或索引别名的名称。如果请求路径中未指定
-
_id - (必需, 字符串) 文档ID。
-
require_alias -
(可选, 布尔值)
如果为
true,则操作必须针对索引别名。默认为false。
-
-
index -
(可选, 字符串) 索引指定的文档。 如果文档存在,替换文档并增加版本号。 以下行必须包含要索引的源数据。
-
_index -
(可选, 字符串)
要执行操作的索引或索引别名的名称。如果请求路径中未指定
-
_id - (可选, 字符串) 文档ID。 如果未指定ID,则会自动生成文档ID。
-
list_executed_pipelines -
(可选, 布尔值) 如果为
true,响应将包括已执行的摄取管道。默认为false。 -
require_alias -
(可选, 布尔值)
如果为
true,操作必须针对一个索引别名。默认为false。 -
dynamic_templates - (可选, 映射) 从字段全名到动态模板名称的映射。 默认为空映射。如果名称匹配动态模板,则无论模板中定义的其他匹配谓词如何,都将应用该模板。如果字段已在映射中定义,则不会使用此参数。
-
-
update -
(可选, 字符串) 执行部分文档更新。 以下行必须包含部分文档和更新选项。
-
_index -
(可选, 字符串)
要执行操作的索引或索引别名的名称。如果请求路径中未指定
-
_id - (必需, 字符串) 文档ID。
-
require_alias -
(可选, 布尔值)
如果为
true,则操作必须针对索引别名。默认为false。
-
-
doc -
(可选, 对象)
要索引的部分文档。
对于
update操作是必需的。 -
<fields> -
(可选, 对象)
要索引的文档源。
对于
create和index操作是必需的。
响应体
edit批量API的响应包含了请求中每个操作的单独结果,按提交顺序返回。单个操作的成功或失败不会影响请求中的其他操作。
-
took - (整数) 处理批量请求所花费的时间,单位为毫秒。
-
errors -
(布尔值)
如果
true,批量请求中的一个或多个操作未成功完成。 -
items -
(对象数组) 包含批量请求中每个操作的结果,按提交顺序排列。
Properties of
itemsobjects-
-
(对象) 参数名称是与操作相关联的动作。可能的值有
创建、删除、索引和更新。参数值是一个包含与关联操作相关信息的对象。
Properties of
-
_index - (字符串) 与操作关联的索引名称。如果操作针对的是数据流,这是文档被写入的后备索引。
-
_id - (整数) 与操作关联的文档ID。
-
_version -
(整数) 与操作关联的文档版本。每次更新文档时,文档版本都会递增。
此参数仅在操作成功时返回。
-
result -
(字符串)
操作的结果。成功的值有
created、deleted和updated。其他有效值有noop和not_found。 -
_shards -
(对象) 包含操作的分片信息。
此参数仅在操作成功时返回。
Properties of
_shards-
total - (整数) 操作尝试执行的分片数量。
-
successful - (整数) 操作成功的分片数量。
-
failed - (整数) 操作尝试执行但失败的分片数量。
-
-
_seq_no -
(整数) 为操作分配给文档的序列号。 序列号用于确保旧版本的文档不会覆盖新版本。请参阅乐观并发控制。
此参数仅在操作成功时返回。
-
_primary_term -
(整数) 分配给文档的主要术语,用于操作。 参见乐观并发控制。
此参数仅在操作成功时返回。
-
status - (整数) 操作返回的HTTP状态码。
-
error -
(对象) 包含有关失败操作的附加信息。
该参数仅在操作失败时返回。
Properties of
error-
type - (字符串) 操作的错误类型。
-
reason - (字符串) 操作失败的原因。
-
index_uuid - (字符串) 与失败操作关联的索引的通用唯一标识符(UUID)。
-
shard - (字符串) 与失败操作关联的分片ID。
-
index - (字符串) 与失败操作关联的索引名称。如果操作针对的是数据流,这是尝试写入文档的后备索引。
-
-
-
示例
editPOST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
API返回以下结果:
{
"took": 30,
"errors": false,
"items": [
{
"index": {
"_index": "test",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 201,
"_seq_no" : 0,
"_primary_term": 1
}
},
{
"delete": {
"_index": "test",
"_id": "2",
"_version": 1,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 404,
"_seq_no" : 1,
"_primary_term" : 2
}
},
{
"create": {
"_index": "test",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 201,
"_seq_no" : 2,
"_primary_term" : 3
}
},
{
"update": {
"_index": "test",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 200,
"_seq_no" : 3,
"_primary_term" : 4
}
}
]
}
批量更新示例
edit在使用 update 操作时,retry_on_conflict 可以作为操作本身的一个字段(而不是在额外的负载行中),用于指定在版本冲突的情况下更新应重试的次数。
The update 操作的有效载荷支持以下选项:doc(部分文档)、upsert、doc_as_upsert、script、params(用于脚本)、lang(用于脚本)和_source。有关选项的详细信息,请参阅更新文档。带有更新操作的示例:
POST _bulk
{ "update" : {"_id" : "1", "_index" : "index1", "retry_on_conflict" : 3} }
{ "doc" : {"field" : "value"} }
{ "update" : { "_id" : "0", "_index" : "index1", "retry_on_conflict" : 3} }
{ "script" : { "source": "ctx._source.counter += params.param1", "lang" : "painless", "params" : {"param1" : 1}}, "upsert" : {"counter" : 1}}
{ "update" : {"_id" : "2", "_index" : "index1", "retry_on_conflict" : 3} }
{ "doc" : {"field" : "value"}, "doc_as_upsert" : true }
{ "update" : {"_id" : "3", "_index" : "index1", "_source" : true} }
{ "doc" : {"field" : "value"} }
{ "update" : {"_id" : "4", "_index" : "index1"} }
{ "doc" : {"field" : "value"}, "_source": true}
包含失败操作的示例
edit以下批量API请求包括更新不存在的文档的操作。
POST /_bulk
{ "update": {"_id": "5", "_index": "index1"} }
{ "doc": {"my_field": "foo"} }
{ "update": {"_id": "6", "_index": "index1"} }
{ "doc": {"my_field": "foo"} }
{ "create": {"_id": "7", "_index": "index1"} }
{ "my_field": "foo" }
因为这些操作无法成功完成,API返回一个errors标志为true的响应。
响应还包括一个用于任何失败操作的error对象。error对象包含有关失败的附加信息,例如错误类型和原因。
{
"took": 486,
"errors": true,
"items": [
{
"update": {
"_index": "index1",
"_id": "5",
"status": 404,
"error": {
"type": "document_missing_exception",
"reason": "[5]: document missing",
"index_uuid": "aAsFqTI0Tc2W0LCWgPNrOA",
"shard": "0",
"index": "index1"
}
}
},
{
"update": {
"_index": "index1",
"_id": "6",
"status": 404,
"error": {
"type": "document_missing_exception",
"reason": "[6]: document missing",
"index_uuid": "aAsFqTI0Tc2W0LCWgPNrOA",
"shard": "0",
"index": "index1"
}
}
},
{
"create": {
"_index": "index1",
"_id": "7",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1,
"status": 201
}
}
]
}
要仅返回有关失败操作的信息,请使用带有参数 items.*.error 的查询参数 filter_path。
POST /_bulk?filter_path=items.*.error
{ "update": {"_id": "5", "_index": "index1"} }
{ "doc": {"my_field": "baz"} }
{ "update": {"_id": "6", "_index": "index1"} }
{ "doc": {"my_field": "baz"} }
{ "update": {"_id": "7", "_index": "index1"} }
{ "doc": {"my_field": "baz"} }
API返回以下结果。
{
"items": [
{
"update": {
"error": {
"type": "document_missing_exception",
"reason": "[5]: document missing",
"index_uuid": "aAsFqTI0Tc2W0LCWgPNrOA",
"shard": "0",
"index": "index1"
}
}
},
{
"update": {
"error": {
"type": "document_missing_exception",
"reason": "[6]: document missing",
"index_uuid": "aAsFqTI0Tc2W0LCWgPNrOA",
"shard": "0",
"index": "index1"
}
}
}
]
}
带有动态模板参数的示例
edit下面的示例创建了一个动态模板,然后执行了一个包含索引/创建请求的批量请求,使用了dynamic_templates参数。
PUT my-index/
{
"mappings": {
"dynamic_templates": [
{
"geo_point": {
"mapping": {
"type" : "geo_point"
}
}
}
]
}
}
POST /_bulk
{ "index" : { "_index" : "my_index", "_id" : "1", "dynamic_templates": {"work_location": "geo_point"}} }
{ "field" : "value1", "work_location": "41.12,-71.34", "raw_location": "41.12,-71.34"}
{ "create" : { "_index" : "my_index", "_id" : "2", "dynamic_templates": {"home_location": "geo_point"}} }
{ "field" : "value2", "home_location": "41.12,-71.34"}
批量请求创建了两个新字段 work_location 和 home_location,类型为 geo_point,根据 dynamic_templates 参数;然而,raw_location 字段是使用默认的动态映射规则创建的,在这种情况下,它被创建为 text 字段,因为它在 JSON 文档中是以字符串形式提供的。
重新索引 API
edit将文档从源复制到目标。
源可以是任何现有的索引、别名或数据流。目标必须与源不同。例如,您不能将数据流重新索引到其自身中。
POST _reindex
{
"source": {
"index": "my-index-000001"
},
"dest": {
"index": "my-new-index-000001"
}
}
请求
editPOST /_reindex
先决条件
edit-
如果启用了Elasticsearch安全功能,您必须拥有以下安全权限:
-
The
readindex privilege for the source data stream, index, or alias. -
The
writeindex privilege for the destination data stream, index, or index alias. -
To automatically create a data stream or index with an reindex API request,
you must have the
auto_configure,create_index, ormanageindex privilege for the destination data stream, index, or alias. -
If reindexing from a remote cluster, the
source.remote.usermust have themonitorcluster privilege and thereadindex privilege for the source data stream, index, or alias.
-
The
-
如果从远程集群重新索引,您必须在
elasticsearch.yml的reindex.remote.whitelist设置中显式允许远程主机。请参阅 从远程重新索引。 - 自动数据流创建需要启用数据流的匹配索引模板。请参阅设置数据流。
描述
edit从源索引中提取文档源,并将文档索引到目标索引中。 您可以将所有文档复制到目标索引,或重新索引文档的子集。
就像_update_by_query一样,_reindex获取源的快照,但其目标必须是不同的,以避免版本冲突。dest元素可以像索引API一样配置,以控制乐观并发控制。省略version_type或将其设置为internal会导致Elasticsearch盲目地将文档转储到目标中,覆盖任何碰巧具有相同ID的文档。
将 version_type 设置为 external 会导致 Elasticsearch 保留来自源的 version,创建任何缺失的文档,并更新目标中版本比源中旧的任何文档。
将 op_type 设置为 create 会导致 _reindex 仅在目标位置创建缺失的文档。所有现有文档都会导致版本冲突。
因为数据流是仅追加的,
任何对目标数据流的重新索引请求都必须具有op_type
为create。重新索引只能向目标数据流添加新文档。
它不能更新目标数据流中的现有文档。
默认情况下,版本冲突会中止_reindex过程。
要继续重新索引,如果存在冲突,请将"conflicts"请求体参数设置为proceed。
在这种情况下,响应中包含遇到的版本冲突的数量。
请注意,"conflicts"参数不影响其他错误类型的处理。
此外,如果您选择计算版本冲突,操作可能会尝试从源中重新索引比max_docs更多的文档,直到它成功地将max_docs文档索引到目标中,或者它已经遍历了源查询中的每个文档。
异步运行重新索引
edit如果请求包含 wait_for_completion=false,Elasticsearch
会执行一些预检操作,启动请求,并返回一个
任务,您可以使用它来取消或获取任务的状态。
Elasticsearch 会在 _tasks/ 处创建此任务的记录文档。
从多个来源重新索引
edit如果你有许多源需要重新索引,通常更好的做法是逐个重新索引,而不是使用通配符模式来选取多个源。这样,如果出现任何错误,你可以通过移除部分完成的源并重新开始来恢复进程。这也使得并行化处理变得相当简单:将需要重新索引的源列表拆分,并在每个列表上并行运行。
一次性bash脚本似乎非常适合这种情况:
for index in i1 i2 i3 i4 i5; do
curl -HContent-Type:application/json -XPOST localhost:9200/_reindex?pretty -d'{
"source": {
"index": "'$index'"
},
"dest": {
"index": "'$index'-reindexed"
}
}'
done
限流
edit将 requests_per_second 设置为任何正的小数(1.4、6、1000 等)以限制 _reindex 发出索引操作批次的速率。请求通过在每个批次中添加等待时间来限制。要禁用限制,请将 requests_per_second 设置为 -1。
节流是通过在批次之间等待来实现的,这样 _reindex 内部使用的 scroll 可以被赋予一个考虑到填充的超时时间。填充时间是批次大小除以 requests_per_second 与写入时间之间的差值。默认情况下,批次大小为 1000,因此如果 requests_per_second 设置为 500:
target_time = 1000 / 500 per second = 2 seconds wait_time = target_time - write_time = 2 seconds - .5 seconds = 1.5 seconds
由于批处理是以单个 _bulk 请求发出的,较大的批处理大小会导致 Elasticsearch 创建许多请求,然后在开始下一组之前等待一段时间。这种方式是“突发性”的,而不是“平滑”的。
重新限流
edit可以使用 _rethrottle API 在正在运行的重新索引过程中更改 requests_per_second 的值:
POST _reindex/r1A2WoRbTwKZ516z6NEs5A:36619/_rethrottle?requests_per_second=-1
任务ID可以通过任务管理API找到。
就像在Reindex API上设置它一样,requests_per_second
可以是-1来禁用限流,或者是任何小数,
比如1.7或12来限制到该水平。加快查询速度的重新限流会立即生效,但减慢查询速度的重新限流会在完成当前批次后生效。这可以防止滚动超时。
切片
edit重新索引支持切片滚动以并行化重新索引过程。 这种并行化可以提高效率,并提供一种方便的方式将请求分解为更小的部分。
手动分片
edit通过为每个请求提供切片ID和切片总数,手动对重新索引请求进行切片:
POST _reindex
{
"source": {
"index": "my-index-000001",
"slice": {
"id": 0,
"max": 2
}
},
"dest": {
"index": "my-new-index-000001"
}
}
POST _reindex
{
"source": {
"index": "my-index-000001",
"slice": {
"id": 1,
"max": 2
}
},
"dest": {
"index": "my-new-index-000001"
}
}
您可以通过以下方式验证其有效性:
GET _refresh POST my-new-index-000001/_search?size=0&filter_path=hits.total
这会得到一个合理的总计,如下所示:
{
"hits": {
"total" : {
"value": 120,
"relation": "eq"
}
}
}
自动分片
edit您还可以让 _reindex 自动并行化使用 Sliced scroll 在 _id 上进行切片。使用 slices 来指定要使用的切片数量:
POST _reindex?slices=5&refresh
{
"source": {
"index": "my-index-000001"
},
"dest": {
"index": "my-new-index-000001"
}
}
您也可以通过以下方式验证这一点:
POST my-new-index-000001/_search?size=0&filter_path=hits.total
这会得到一个合理的总计,如下所示:
{
"hits": {
"total" : {
"value": 120,
"relation": "eq"
}
}
}
将 slices 设置为 auto 将让 Elasticsearch 选择要使用的切片数量。此设置将每个分片使用一个切片,直到达到某个限制。如果有多个源,它将根据分片数量最少的索引或 后备索引 来选择切片的数量。
将slices添加到_reindex只是自动化了上述部分中使用的手动过程,创建了子请求,这意味着它有一些特殊之处:
-
您可以在任务API中看到这些请求。这些子请求是带有
slices的请求任务的“子”任务。 -
获取带有
slices的请求任务的状态仅包含已完成分片的状态。 - 这些子请求可以单独处理,例如取消和重新调整速率。
-
重新调整带有
slices的请求的速率将按比例重新调整未完成的子请求的速率。 -
取消带有
slices的请求将取消每个子请求。 -
由于
slices的性质,每个子请求不会获得完全均匀的文档部分。所有文档都将被处理,但某些分片可能比其他分片大。预计较大的分片会有更均匀的分布。 -
带有
slices的请求中的参数,如requests_per_second和max_docs,会按比例分配给每个子请求。结合上述关于分布不均匀的点,您应该得出结论,使用max_docs和slices可能不会导致正好max_docs个文档被重新索引。 - 每个子请求都会获得源数据的略有不同的快照,尽管这些快照都是在几乎相同的时间点获取的。
选择切片数量
edit如果自动切片,将 slices 设置为 auto 会为大多数索引选择一个合理的数量。如果手动切片或调整自动切片,请使用这些指南。
当slices的数量等于索引中的分片数量时,查询性能最为高效。如果该数量较大(例如500),请选择一个较低的数字,因为过多的slices会损害性能。将slices设置得高于分片数量通常不会提高效率,反而会增加开销。
索引性能随着切片的数量线性扩展,充分利用可用资源。
查询或索引性能是否主导运行时间取决于正在重新索引的文档和集群资源。
重新索引路由
edit默认情况下,如果 _reindex 看到带有路由的文档,则除非被脚本更改,否则路由将被保留。您可以在 dest 请求上设置 routing 来更改此行为:
-
keep - 将为每个匹配项发送的批量请求的路由设置为匹配项的路由。这是默认值。
-
discard -
设置为每个匹配发送的批量请求的路由为
null。 -
=<some text> -
设置批量请求中每个匹配项的路由为
=之后的所有文本。
例如,您可以使用以下请求将公司名称为cat的所有文档从source复制到dest,并将路由设置为cat。
POST _reindex
{
"source": {
"index": "source",
"query": {
"match": {
"company": "cat"
}
}
},
"dest": {
"index": "dest",
"routing": "=cat"
}
}
默认情况下,_reindex 使用 1000 的滚动批次。您可以通过 source 元素中的 size 字段更改批次大小:
POST _reindex
{
"source": {
"index": "source",
"size": 100
},
"dest": {
"index": "dest",
"routing": "=cat"
}
}
使用摄取管道重新索引
edit重新索引也可以通过指定一个pipeline来使用Ingest pipelines功能,如下所示:
POST _reindex
{
"source": {
"index": "source"
},
"dest": {
"index": "dest",
"pipeline": "some_ingest_pipeline"
}
}
查询参数
edit-
refresh -
(可选,布尔值) 如果
true,请求将刷新受影响的分片以使此操作对搜索可见。默认为false。 -
timeout -
(可选, 时间单位) 每个索引操作等待的时间段:
默认为
1m(一分钟)。这保证了 Elasticsearch 在失败前至少等待超时时间。实际等待时间可能会更长,特别是在多次等待发生时。 -
wait_for_active_shards -
(可选,字符串) 在继续操作之前,必须处于活动状态的每个分片的副本数量。设置为
all或任何非负整数,最大不超过索引中每个分片的副本总数(number_of_replicas+1)。默认为1,表示仅等待每个主分片处于活动状态。请参阅Active shards。
-
wait_for_completion -
(可选,布尔值) 如果
true,请求会阻塞直到操作完成。 默认为true。 -
requests_per_second -
(可选, 整数) 每秒的子请求限制。
默认为
-1(无限制)。 -
require_alias -
(可选,布尔值) 如果为
true,目标必须是一个 索引别名。 默认为false。 -
scroll - (可选,时间单位) 指定为滚动搜索维护索引一致视图的时间长度。
-
slices - (可选, 整数) 此任务应被划分的切片数量。 默认为1,表示任务不会被划分为子任务。
-
max_docs -
(可选,整数) 要处理的文档的最大数量。默认为所有文档。当设置为小于或等于
scroll_size的值时,操作将不会使用滚动来检索结果。
请求体
edit-
conflicts -
(可选,枚举) 设置为
proceed以在存在冲突时继续重新索引。 默认为abort。 -
max_docs -
(可选,整数) 要重新索引的最大文档数。如果 冲突 等于
proceed,重新索引可能会尝试从源索引中重新索引比max_docs更多的文档,直到它成功地将max_docs文档索引到目标索引中,或者它已经遍历了源查询中的每个文档。 -
source -
-
index - (必需, 字符串) 要从中复制的数据流、索引或别名的名称。还接受以逗号分隔的列表,以从多个源重新索引。
-
query - (可选, 查询对象) 使用查询DSL指定要重新索引的文档。
-
remote -
size - (可选, 整数) 每批次索引的文档数量。从远程索引时使用,以确保批次适合堆内缓冲区,默认最大大小为100 MB。
-
slice -
-
id - (可选, 整数) 手动切片的切片ID。
-
max - (可选, 整数) 切片的总数。
-
-
sort -
(可选, 列表) 一个以逗号分隔的
<字段>:<方向>对列表,用于在索引之前进行排序。 与max_docs一起使用,以控制哪些文档被重新索引。在7.6版本中已弃用。
在重新索引中排序已被弃用。在重新索引中排序从未保证按顺序索引文档,并且阻碍了重新索引的进一步开发,如弹性和性能改进。如果与
max_docs一起使用,请考虑使用查询过滤器代替。 -
_source -
(可选, 字符串) 如果
true重新索引所有源字段。 设置为列表以重新索引选定字段。 默认为true。
-
-
dest -
script -
-
source - (可选,字符串)在重新索引时运行以更新文档源或元数据的脚本。
-
lang -
(可选,枚举)脚本语言:
painless、expression、mustache、java。 有关更多信息,请参阅脚本。
-
响应体
edit-
took - (整数) 整个操作所花费的总毫秒数。
-
timed_out -
{Boolean) 如果在重新索引期间执行的任何请求超时,则此标志设置为
true。 -
total - (整数) 成功处理的文档数量。
-
updated - (整数) 成功更新的文档数量, 即在重新索引更新之前已经存在相同ID的文档。
-
created - (整数) 成功创建的文档数量。
-
deleted - (整数) 成功删除的文档数量。
-
batches - (整数) reindex 操作拉回的滚动响应数量。
-
noops -
(整数) 由于用于重新索引的脚本为
ctx.op返回了noop值而被忽略的文档数量。 -
version_conflicts - (整数) 重新索引时遇到的版本冲突数量。
-
retries -
(整数) reindex 尝试的重试次数。
bulk是重试的批量操作次数,search是重试的搜索操作次数。 -
throttled_millis -
(整数) 请求为了符合
requests_per_second而休眠的毫秒数。 -
requests_per_second - (整数) 在重新索引期间每秒有效执行的请求数。
-
throttled_until_millis -
(整数) 在
_reindex响应中,此字段应始终为零。它仅在使用 Task API 时才有意义,其中它指示下一次(自纪元以来的毫秒数)将再次执行限流请求,以符合requests_per_second。 -
failures -
(数组) 如果在过程中有任何不可恢复的错误,则返回失败数组。如果此数组非空,则请求因这些失败而中止。重新索引是使用批处理实现的,任何失败都会导致整个过程中止,但当前批处理中的所有失败都会被收集到数组中。您可以使用
conflicts选项来防止重新索引在版本冲突时中止。
示例
edit使用查询重新索引选定的文档
edit您可以通过向source添加查询来限制文档。例如,以下请求仅将user.id为kimchy的文档复制到my-new-index-000001中:
POST _reindex
{
"source": {
"index": "my-index-000001",
"query": {
"term": {
"user.id": "kimchy"
}
}
},
"dest": {
"index": "my-new-index-000001"
}
}
使用max_docs重新索引选定文档
edit您可以通过设置max_docs来限制处理的文档数量。
例如,此请求将单个文档从my-index-000001复制到
my-new-index-000001:
POST _reindex
{
"max_docs": 1,
"source": {
"index": "my-index-000001"
},
"dest": {
"index": "my-new-index-000001"
}
}
从多个来源重新索引
edit在 source 中的 index 属性可以是一个列表,允许您在一个请求中从多个源复制数据。这将复制来自 my-index-000001 和 my-index-000002 索引的文档:
POST _reindex
{
"source": {
"index": ["my-index-000001", "my-index-000002"]
},
"dest": {
"index": "my-new-index-000002"
}
}
Reindex API 不会处理ID冲突,因此最后写入的文档将“获胜”,但顺序通常是不可预测的,因此不建议依赖这种行为。相反,请确保使用脚本来保证ID的唯一性。
使用源过滤器重新索引选定字段
edit您可以使用源过滤来重新索引原始文档中的字段子集。
例如,以下请求仅重新索引每个文档的 user.id 和 _doc 字段:
POST _reindex
{
"source": {
"index": "my-index-000001",
"_source": ["user.id", "_doc"]
},
"dest": {
"index": "my-new-index-000001"
}
}
重新索引以更改字段名称
edit_reindex 可以用于构建一个带有重命名字段的索引副本。假设你创建了一个包含如下文档的索引:
POST my-index-000001/_doc/1?refresh
{
"text": "words words",
"flag": "foo"
}
但您不喜欢名称 flag,并希望将其替换为 tag。
_reindex 可以为您创建另一个索引:
POST _reindex
{
"source": {
"index": "my-index-000001"
},
"dest": {
"index": "my-new-index-000001"
},
"script": {
"source": "ctx._source.tag = ctx._source.remove(\"flag\")"
}
}
现在你可以获取新文档:
GET my-new-index-000001/_doc/1
这将返回:
{
"found": true,
"_id": "1",
"_index": "my-new-index-000001",
"_version": 1,
"_seq_no": 44,
"_primary_term": 1,
"_source": {
"text": "words words",
"tag": "foo"
}
}
重新索引每日索引
edit您可以使用 _reindex 结合 Painless 来重新索引每日索引,以将新模板应用于现有文档。
假设你有包含以下文档的索引:
PUT metricbeat-2016.05.30/_doc/1?refresh
{"system.cpu.idle.pct": 0.908}
PUT metricbeat-2016.05.31/_doc/1?refresh
{"system.cpu.idle.pct": 0.105}
新的 metricbeat-* 索引模板已经加载到 Elasticsearch 中,但它仅适用于新创建的索引。可以使用 Painless 重新索引现有文档并应用新模板。
下面的脚本从索引名称中提取日期,并创建一个附加了-1的新索引。所有来自metricbeat-2016.05.31的数据将被重新索引到metricbeat-2016.05.31-1。
POST _reindex
{
"source": {
"index": "metricbeat-*"
},
"dest": {
"index": "metricbeat"
},
"script": {
"lang": "painless",
"source": "ctx._index = 'metricbeat-' + (ctx._index.substring('metricbeat-'.length(), ctx._index.length())) + '-1'"
}
}
所有来自之前metricbeat索引的文档现在都可以在*-1索引中找到。
GET metricbeat-2016.05.30-1/_doc/1 GET metricbeat-2016.05.31-1/_doc/1
之前的方法也可以与更改字段名称结合使用,以仅将现有数据加载到新索引中,并在需要时重命名字段。
提取源的随机子集
edit_reindex 可以用于提取源数据的随机子集以进行测试:
在重新索引期间修改文档
edit与 _update_by_query 类似,_reindex 支持一个可以修改文档的脚本。与 _update_by_query 不同,该脚本允许修改文档的元数据。这个示例增加了源文档的版本号:
POST _reindex
{
"source": {
"index": "my-index-000001"
},
"dest": {
"index": "my-new-index-000001",
"version_type": "external"
},
"script": {
"source": "if (ctx._source.foo == 'bar') {ctx._version++; ctx._source.remove('foo')}",
"lang": "painless"
}
}
正如在 _update_by_query 中一样,您可以设置 ctx.op 来更改在目标上执行的操作:
将 ctx.op 设置为其他任何值将返回错误,同样,设置 ctx 中的任何其他字段也会返回错误。
想象一下可能性!但要小心;你可以改变:
-
_id -
_index -
_version -
_routing
将 _version 设置为 null 或从 ctx 映射中清除它,就像在索引请求中不发送版本一样;它将导致文档在目标中被覆盖,无论目标上的版本或您在 _reindex 请求中使用的版本类型如何。
从远程重新索引
edit重新索引支持从远程Elasticsearch集群进行重新索引:
POST _reindex
{
"source": {
"remote": {
"host": "http://otherhost:9200",
"username": "user",
"password": "pass"
},
"index": "my-index-000001",
"query": {
"match": {
"test": "data"
}
}
},
"dest": {
"index": "my-new-index-000001"
}
}
参数 host 必须包含一个方案、主机、端口(例如 https://otherhost:9200),以及可选的路径(例如 https://otherhost:9200/proxy)。
参数 username 和 password 是可选的,当它们存在时,_reindex 将使用基本认证连接到远程 Elasticsearch 节点。请确保在使用基本认证时使用 https,否则密码将以明文发送。
有一系列 设置 可用于配置 https 连接的行为。
当使用 Elastic Cloud 时,也可以通过使用有效的 API 密钥来对远程集群进行身份验证:
POST _reindex
{
"source": {
"remote": {
"host": "http://otherhost:9200",
"headers": {
"Authorization": "ApiKey API_KEY_VALUE"
}
},
"index": "my-index-000001",
"query": {
"match": {
"test": "data"
}
}
},
"dest": {
"index": "my-new-index-000001"
}
}
远程主机必须在 elasticsearch.yml 中使用 reindex.remote.whitelist 属性显式允许。它可以设置为允许的远程 host 和 port 组合的逗号分隔列表。方案被忽略,仅使用主机和端口。例如:
reindex.remote.whitelist: [otherhost:9200, another:9200, 127.0.10.*:9200, localhost:*"]
允许的主机列表必须在任何将协调重新索引的节点上进行配置。
此功能应适用于您可能遇到的任何版本的Elasticsearch远程集群。这应该允许您通过从旧版本的集群重新索引来升级到当前版本的Elasticsearch。
Elasticsearch 不支持跨主要版本的前向兼容性。例如,您不能将数据从 7.x 集群重新索引到 6.x 集群。
为了使发送到较旧版本的 Elasticsearch 的查询生效,query 参数会直接发送到远程主机,而不会进行验证或修改。
从远程服务器重新索引使用了一个默认最大大小为100mb的堆上缓冲区。如果远程索引包含非常大的文档,您需要使用较小的批处理大小。下面的示例将批处理大小设置为10,这是一个非常非常小的值。
POST _reindex
{
"source": {
"remote": {
"host": "http://otherhost:9200",
...
},
"index": "source",
"size": 10,
"query": {
"match": {
"test": "data"
}
}
},
"dest": {
"index": "dest"
}
}
也可以在远程连接上设置套接字读取超时,使用socket_timeout字段和连接超时使用connect_timeout字段。两者默认均为30秒。此示例将套接字读取超时设置为一分钟,将连接超时设置为10秒:
POST _reindex
{
"source": {
"remote": {
"host": "http://otherhost:9200",
...,
"socket_timeout": "1m",
"connect_timeout": "10s"
},
"index": "source",
"query": {
"match": {
"test": "data"
}
}
},
"dest": {
"index": "dest"
}
}
配置SSL参数
edit从远程重新索引支持可配置的SSL设置。这些必须在elasticsearch.yml文件中指定,除了安全设置,这些设置需要在Elasticsearch密钥库中添加。
无法在_reindex请求的主体中配置SSL。
支持以下设置:
-
reindex.ssl.certificate_authorities -
应信任的PEM编码证书文件的路径列表。
您不能同时指定
reindex.ssl.certificate_authorities和reindex.ssl.truststore.path。 -
reindex.ssl.truststore.path -
包含要信任的证书的Java Keystore文件的路径。
此keystore可以是"JKS"或"PKCS#12"格式。
您不能同时指定
reindex.ssl.certificate_authorities和reindex.ssl.truststore.path。 -
reindex.ssl.truststore.password -
信任库的密码(
reindex.ssl.truststore.path)。 [7.17.0] 在7.17.0中已弃用。 建议使用reindex.ssl.truststore.secure_password代替。 此设置不能与reindex.ssl.truststore.secure_password一起使用。 -
reindex.ssl.truststore.secure_password(Secure) -
信任库的密码(
reindex.ssl.truststore.path)。 此设置不能与reindex.ssl.truststore.password一起使用。 -
reindex.ssl.truststore.type -
信任库的类型(
reindex.ssl.truststore.path)。 必须是jks或PKCS12。如果信任库路径以 ".p12"、".pfx" 或 "pkcs12" 结尾,此设置默认为PKCS12。否则,它默认为jks。 -
reindex.ssl.verification_mode -
指示用于防止中间人攻击和证书伪造的验证类型。
可以是
full(验证主机名和证书路径)、certificate(验证证书路径,但不验证主机名)或none(不进行验证——这在生产环境中强烈不推荐)。 默认为full。 -
reindex.ssl.certificate -
指定用于HTTP客户端身份验证的PEM编码证书(或证书链)的路径(如果远程集群要求)。此设置要求同时设置
reindex.ssl.key。您不能同时指定reindex.ssl.certificate和reindex.ssl.keystore.path。 -
reindex.ssl.key -
指定与用于客户端身份验证的证书关联的PEM编码私钥的路径(
reindex.ssl.certificate)。 您不能同时指定reindex.ssl.key和reindex.ssl.keystore.path。 -
reindex.ssl.key_passphrase -
指定用于解密PEM编码的私钥(
reindex.ssl.key)的密码短语(如果它已加密)。 [7.17.0] 在7.17.0中已弃用。 建议改用reindex.ssl.secure_key_passphrase。 不能与reindex.ssl.secure_key_passphrase一起使用。 -
reindex.ssl.secure_key_passphrase(Secure) -
指定用于解密PEM编码的私钥(
reindex.ssl.key)的密码短语(passphrase),如果该私钥已加密。 不能与reindex.ssl.key_passphrase一起使用。 -
reindex.ssl.keystore.path -
指定包含用于HTTP客户端身份验证的私钥和证书的密钥库的路径(如果远程集群要求)。
此密钥库可以是“JKS”或“PKCS#12”格式。
您不能同时指定
reindex.ssl.key和reindex.ssl.keystore.path。 -
reindex.ssl.keystore.type -
密钥库的类型(
reindex.ssl.keystore.path)。必须是jks或PKCS12。 如果密钥库路径以 ".p12"、".pfx" 或 "pkcs12" 结尾,此设置默认为PKCS12。否则,它默认为jks。 -
reindex.ssl.keystore.password -
密钥库的密码(
reindex.ssl.keystore.path)。 [7.17.0] 在7.17.0中已弃用。 建议改用reindex.ssl.keystore.secure_password。 此设置不能与reindex.ssl.keystore.secure_password一起使用。 -
reindex.ssl.keystore.secure_password(Secure) -
密钥库的密码(
reindex.ssl.keystore.path)。 此设置不能与reindex.ssl.keystore.password一起使用。 -
reindex.ssl.keystore.key_password -
密钥库中密钥的密码(
reindex.ssl.keystore.path)。 默认为密钥库密码。 [7.17.0] 在7.17.0中已弃用。 建议改用reindex.ssl.keystore.secure_key_password。 此设置不能与reindex.ssl.keystore.secure_key_password一起使用。 -
reindex.ssl.keystore.secure_key_password(Secure) -
密钥库中密钥的密码(
reindex.ssl.keystore.path)。 默认为密钥库密码。此设置不能与reindex.ssl.keystore.key_password一起使用。
词向量 API
edit检索特定文档字段中术语的信息和统计数据。
GET /my-index-000001/_termvectors/1
请求
editGET /
描述
edit您可以检索存储在索引中的文档的词向量,或检索请求体中传递的人工文档的词向量。
您可以通过fields参数指定您感兴趣的字段,或者将字段添加到请求体中。
GET /my-index-000001/_termvectors/1?fields=message
可以使用通配符指定字段,类似于多匹配查询。
词向量默认是实时的,而不是近实时。
这可以通过将realtime参数设置为false来改变。
您可以请求三种类型的值:术语信息、术语统计和字段统计。默认情况下,所有字段的术语信息和字段统计信息都会返回,但术语统计信息除外。
术语信息
edit- 字段中的词频(始终返回)
-
词位置(
positions: true) -
开始和结束偏移量(
offsets: true) -
词载荷(
payloads: true),以base64编码的字节形式
如果请求的信息未存储在索引中,如果可能的话,它将会被实时计算。此外,术语向量可以为甚至不存在于索引中的文档计算,而是由用户提供的。
起始和结束偏移量假设正在使用UTF-16编码。如果你想使用这些偏移量来获取产生此标记的原始文本,你应该确保你正在截取子字符串的字符串也使用UTF-16编码。
术语统计
edit将 term_statistics 设置为 true(默认值为 false)将返回
-
总词频(一个词在所有文档中出现的频率)
- 文档频率(包含当前词的文档数量)
默认情况下,这些值不会返回,因为词项统计可能会对性能产生严重影响。
字段统计
edit将 field_statistics 设置为 false(默认值为 true)将省略:
- 文档计数(包含此字段的文档数量)
- 文档频率总和(此字段中所有术语的文档频率总和)
- 总词频总和(此字段中每个术语的总词频总和)
术语过滤
edit通过参数 filter,返回的术语也可以根据其 tf-idf 分数进行过滤。这对于找到文档的良好特征向量非常有用。此功能的工作方式与 第二阶段 的 更多类似此查询 类似。请参阅 示例 5 以了解用法。
支持以下子参数:
|
|
每个字段必须返回的最大术语数。默认为 |
|
|
忽略源文档中频率低于此值的单词。默认为 |
|
|
忽略源文档中频率超过此值的词语。默认为无限制。 |
|
|
忽略不在至少这么多文档中出现的术语。默认为 |
|
|
忽略在超过此数量文档中出现的词语。默认为无限制。 |
|
|
低于此最小字长阈值的单词将被忽略。默认为 |
|
|
超过此长度的单词将被忽略。默认为无限制( |
行为
edit术语和字段统计数据并不准确。已删除的文档未被考虑在内。信息仅从请求文档所在的分片中检索。因此,术语和字段统计数据仅作为相对度量有用,而绝对数字在此上下文中没有意义。默认情况下,当请求人工文档的词向量时,会随机选择一个分片来获取统计数据。仅使用routing来命中特定分片。
路径参数
edit-
<index> - (必需,字符串) 包含文档的索引名称。
-
<_id> - (可选, 字符串) 文档的唯一标识符。
查询参数
edit-
fields -
(可选,字符串) 逗号分隔的字段列表或通配符表达式,用于包含在统计信息中。
用作默认列表,除非在
completion_fields或fielddata_fields参数中提供了特定的字段列表。 -
field_statistics -
(可选,布尔值) 如果
true,响应将包括文档计数、文档频率的总和以及总词频的总和。 默认为true。 -
<offsets> -
(可选,布尔值) 如果
true,响应将包含术语偏移量。 默认为true。 -
payloads -
(可选,布尔值) 如果
true,响应中将包含术语的有效载荷。 默认为true。 -
positions -
(可选,布尔值) 如果为
true,响应将包含术语位置。 默认为true。 -
preference - (可选,字符串) 指定操作应在其上执行的节点或分片。默认情况下是随机的。
-
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
realtime -
(可选,布尔值) 如果为
true,则请求是实时的,而不是近实时的。 默认为true。请参阅Realtime。 -
term_statistics -
(可选,布尔值) 如果
true,响应将包含词频和文档频率。 默认为false。 -
version -
(可选,布尔值) 如果
true,则在命中结果中返回文档版本。 -
version_type -
(可选, 枚举) 特定版本类型:
external,external_gte.
示例
edit返回存储的词向量
edit首先,我们创建一个存储术语向量、有效载荷等的索引:
PUT /my-index-000001
{ "mappings": {
"properties": {
"text": {
"type": "text",
"term_vector": "with_positions_offsets_payloads",
"store" : true,
"analyzer" : "fulltext_analyzer"
},
"fullname": {
"type": "text",
"term_vector": "with_positions_offsets_payloads",
"analyzer" : "fulltext_analyzer"
}
}
},
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0
},
"analysis": {
"analyzer": {
"fulltext_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"type_as_payload"
]
}
}
}
}
}
其次,我们添加一些文档:
PUT /my-index-000001/_doc/1
{
"fullname" : "John Doe",
"text" : "test test test "
}
PUT /my-index-000001/_doc/2?refresh=wait_for
{
"fullname" : "Jane Doe",
"text" : "Another test ..."
}
以下请求返回文档1(John Doe)中字段text的所有信息和统计数据:
GET /my-index-000001/_termvectors/1
{
"fields" : ["text"],
"offsets" : true,
"payloads" : true,
"positions" : true,
"term_statistics" : true,
"field_statistics" : true
}
响应:
{
"_index": "my-index-000001",
"_id": "1",
"_version": 1,
"found": true,
"took": 6,
"term_vectors": {
"text": {
"field_statistics": {
"sum_doc_freq": 4,
"doc_count": 2,
"sum_ttf": 6
},
"terms": {
"test": {
"doc_freq": 2,
"ttf": 4,
"term_freq": 3,
"tokens": [
{
"position": 0,
"start_offset": 0,
"end_offset": 4,
"payload": "d29yZA=="
},
{
"position": 1,
"start_offset": 5,
"end_offset": 9,
"payload": "d29yZA=="
},
{
"position": 2,
"start_offset": 10,
"end_offset": 14,
"payload": "d29yZA=="
}
]
}
}
}
}
}
即时生成词向量
edit未显式存储在索引中的词向量会自动即时计算。以下请求返回文档 1 中所有字段的信息和统计数据,即使这些词未在索引中显式存储。请注意,对于字段 text,不会重新生成词。
GET /my-index-000001/_termvectors/1
{
"fields" : ["text", "some_field_without_term_vectors"],
"offsets" : true,
"positions" : true,
"term_statistics" : true,
"field_statistics" : true
}
人工文档
edit术语向量也可以为人工文档生成,即不为索引中存在的文档生成。例如,以下请求将返回与示例1相同的结果。使用的映射由index决定。
如果动态映射已开启(默认),文档中不在原始映射中的字段将被动态创建。
GET /my-index-000001/_termvectors
{
"doc" : {
"fullname" : "John Doe",
"text" : "test test test"
}
}
每个字段的分析器
edit此外,可以通过使用per_field_analyzer参数提供与字段不同的分析器。这在以任何方式生成词向量时非常有用,特别是在使用人工文档时。当为已经存储词向量的字段提供分析器时,词向量将被重新生成。
GET /my-index-000001/_termvectors
{
"doc" : {
"fullname" : "John Doe",
"text" : "test test test"
},
"fields": ["fullname"],
"per_field_analyzer" : {
"fullname": "keyword"
}
}
响应:
{
"_index": "my-index-000001",
"_version": 0,
"found": true,
"took": 6,
"term_vectors": {
"fullname": {
"field_statistics": {
"sum_doc_freq": 2,
"doc_count": 4,
"sum_ttf": 4
},
"terms": {
"John Doe": {
"term_freq": 1,
"tokens": [
{
"position": 0,
"start_offset": 0,
"end_offset": 8
}
]
}
}
}
}
}
术语过滤
edit最后,可以根据tf-idf分数对返回的术语进行过滤。在下面的示例中,我们从具有给定“plot”字段值的人工文档中获取了三个“最有趣”的关键词。请注意,关键词“Tony”或任何停用词都不在响应中,因为它们的tf-idf分数必须太低。
GET /imdb/_termvectors
{
"doc": {
"plot": "When wealthy industrialist Tony Stark is forced to build an armored suit after a life-threatening incident, he ultimately decides to use its technology to fight against evil."
},
"term_statistics": true,
"field_statistics": true,
"positions": false,
"offsets": false,
"filter": {
"max_num_terms": 3,
"min_term_freq": 1,
"min_doc_freq": 1
}
}
响应:
{
"_index": "imdb",
"_version": 0,
"found": true,
"term_vectors": {
"plot": {
"field_statistics": {
"sum_doc_freq": 3384269,
"doc_count": 176214,
"sum_ttf": 3753460
},
"terms": {
"armored": {
"doc_freq": 27,
"ttf": 27,
"term_freq": 1,
"score": 9.74725
},
"industrialist": {
"doc_freq": 88,
"ttf": 88,
"term_freq": 1,
"score": 8.590818
},
"stark": {
"doc_freq": 44,
"ttf": 47,
"term_freq": 1,
"score": 9.272792
}
}
}
}
}
多词向量 API
edit通过单个请求检索多个术语向量。
POST /_mtermvectors
{
"docs": [
{
"_index": "my-index-000001",
"_id": "2",
"term_statistics": true
},
{
"_index": "my-index-000001",
"_id": "1",
"fields": [
"message"
]
}
]
}
描述
edit您可以通过索引和ID指定现有文档,或者在请求体中提供人工文档。您可以在请求体或请求URI中指定索引。
响应包含一个docs数组,其中包含所有获取的词向量。
每个元素的结构由词向量
API提供。
有关可以在响应中包含的信息的更多信息,请参阅termvectors API。
路径参数
edit-
<index> - (可选,字符串) 包含文档的索引名称。
查询参数
edit-
fields -
(可选,字符串) 逗号分隔的字段列表或通配符表达式,用于包含在统计信息中。
用作默认列表,除非在
completion_fields或fielddata_fields参数中提供了特定的字段列表。 -
field_statistics -
(可选,布尔值) 如果为
true,响应将包括文档计数、文档频率的总和以及总词频的总和。 默认为true。 -
<offsets> -
(可选,布尔值) 如果
true,响应将包含术语偏移量。 默认为true。 -
payloads -
(可选,布尔值) 如果
true,响应中将包含术语的有效载荷。 默认为true。 -
positions -
(可选,布尔值) 如果
true,响应将包含术语位置。 默认为true。 -
preference - (可选,字符串) 指定操作应在其上执行的节点或分片。默认情况下是随机的。
-
routing - (可选, 字符串) 自定义值,用于将操作路由到特定分片。
-
realtime -
(可选,布尔值) 如果为
true,则请求是实时的,而不是近实时的。 默认为true。请参阅Realtime。 -
term_statistics -
(可选,布尔值) 如果为
true,响应将包含词频和文档频率。 默认为false。 -
version -
(可选,布尔值) 如果
true,则在命中结果中返回文档版本。 -
version_type -
(可选, 枚举) 特定版本类型:
external,external_gte.
示例
edit如果在请求URI中指定了索引,则不需要在请求体中的每个文档中指定索引:
POST /my-index-000001/_mtermvectors
{
"docs": [
{
"_id": "2",
"fields": [
"message"
],
"term_statistics": true
},
{
"_id": "1"
}
]
}
如果所有请求的文档都在同一个索引中且参数相同,您可以使用以下简化的语法:
POST /my-index-000001/_mtermvectors
{
"ids": [ "1", "2" ],
"parameters": {
"fields": [
"message"
],
"term_statistics": true
}
}
人工文档
edit您还可以使用 mtermvectors 为请求体中提供的人工文档生成词向量。使用的映射由指定的 _index 决定。
POST /_mtermvectors
{
"docs": [
{
"_index": "my-index-000001",
"doc" : {
"message" : "test test test"
}
},
{
"_index": "my-index-000001",
"doc" : {
"message" : "Another test ..."
}
}
]
}
?refresh
editThe Index, Update, Delete, and
Bulk APIs 支持设置 refresh 以控制此请求所做的更改何时对搜索可见。这些是允许的值:
-
Empty string or
true - 在操作发生后立即刷新相关的主分片和副本分片(而不是整个索引),以便更新的文档立即出现在搜索结果中。这应该仅在经过仔细考虑和验证不会导致性能下降(无论是从索引还是搜索的角度)后才进行。
-
wait_for -
等待请求所做的更改在刷新后变得可见后再进行回复。这并不会强制立即刷新,而是等待刷新发生。Elasticsearch 会自动刷新已更改的分片,每隔
index.refresh_interval,默认值为一秒。该设置是 动态的。调用 刷新 API 或在支持该功能的 API 上将refresh设置为true也会导致刷新,进而导致已经运行的带有refresh=wait_for的请求返回。 -
false(the default) - 不采取任何与刷新相关的操作。此请求所做的更改将在请求返回后的某个时间点变得可见。
选择使用哪个设置
edit除非你有充分的理由等待更改变为可见,否则请始终使用 refresh=false(默认设置)。最简单和最快的选择是从 URL 中省略 refresh 参数。
如果你绝对需要请求所做的更改在请求时同步可见,你必须在增加Elasticsearch的负载(true)和等待更长的响应时间(wait_for)之间做出选择。以下是一些应该帮助你做出决定的几点:
-
对索引的更改越多,
wait_for相比true节省的工作量就越多。如果索引仅在每次index.refresh_interval时更改一次,则不会节省任何工作量。 -
true创建的索引结构(小段)效率较低,必须稍后合并为更高效的索引结构(大段)。这意味着true的成本在索引时创建小段、在搜索时搜索小段以及在合并时创建大段时都会支付。 -
不要连续启动多个
refresh=wait_for请求。而是将它们批量处理为一个带有refresh=wait_for的批量请求,Elasticsearch 将并行启动它们,并且仅在它们全部完成后返回。 -
如果将刷新间隔设置为
-1,禁用自动刷新,则带有refresh=wait_for的请求将无限期等待,直到某些操作导致刷新。相反,将index.refresh_interval设置为比默认值更短的时间(如200ms)将使refresh=wait_for更快返回,但它仍会生成效率低下的段。 -
refresh=wait_for仅影响其所在的请求,但通过立即强制刷新,refresh=true将影响其他正在进行的请求。通常,如果您有一个正在运行的系统不希望被打扰,那么refresh=wait_for是一个较小的修改。
refresh=wait_for 可以强制刷新
edit如果当已经有index.max_refresh_listeners(默认为1000)个请求在该分片上等待刷新时,传入一个refresh=wait_for请求,那么该请求的行为将如同其refresh设置为true一样:它将强制刷新。这保持了当refresh=wait_for请求返回时,其更改对搜索可见的承诺,同时防止了被阻塞请求的无限制资源使用。如果一个请求因用尽监听器槽位而强制刷新,那么其响应将包含"forced_refresh": true。
批量请求无论修改分片多少次,都只占用每个分片上的一个槽位。
示例
edit这些操作将创建一个文档并立即刷新索引,使其可见:
PUT /test/_doc/1?refresh
{"test": "test"}
PUT /test/_doc/2?refresh=true
{"test": "test"}
这些将创建一个文档,但不会进行任何操作使其对搜索可见:
PUT /test/_doc/3
{"test": "test"}
PUT /test/_doc/4?refresh=false
{"test": "test"}
这将创建一个文档并等待它变得对搜索可见:
PUT /test/_doc/4?refresh=wait_for
{"test": "test"}
乐观并发控制
editElasticsearch 是分布式的。当文档被创建、更新或删除时,文档的新版本必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求是并行发送的,并且可能以乱序到达目的地。Elasticsearch 需要一种方法来确保旧版本的文档永远不会覆盖新版本的文档。
为了确保旧版本的文档不会覆盖新版本的文档,每个对文档执行的操作都会由协调该更改的主分片分配一个序列号。序列号随着每个操作的进行而增加,因此可以保证较新的操作具有比旧操作更高的序列号。Elasticsearch 然后可以使用操作的序列号来确保新版本的文档永远不会被分配了较小序列号的更改所覆盖。
例如,以下索引命令将创建一个文档并为其分配初始序列号和主项:
PUT products/_doc/1567
{
"product" : "r2d2",
"details" : "A resourceful astromech droid"
}
您可以在响应的 _seq_no 和 _primary_term 字段中看到分配的序列号和主项:
{
"_shards": {
"total": 2,
"failed": 0,
"successful": 1
},
"_index": "products",
"_id": "1567",
"_version": 1,
"_seq_no": 362,
"_primary_term": 2,
"result": "created"
}
Elasticsearch 跟踪每个存储文档的最后操作的序列号和主项。序列号和主项在 GET API 的响应中的 _seq_no 和 _primary_term 字段中返回:
GET products/_doc/1567
返回:
{
"_index": "products",
"_id": "1567",
"_version": 1,
"_seq_no": 362,
"_primary_term": 2,
"found": true,
"_source": {
"product": "r2d2",
"details": "A resourceful astromech droid"
}
}
注意:Search API 可以通过设置 seq_no_primary_term 参数 返回每个搜索命中的 _seq_no 和 _primary_term。
序列号和主项唯一标识一个更改。通过记录返回的序列号和主项,您可以确保只有在没有其他更改的情况下才更改文档。这是通过设置if_seq_no和if_primary_term参数来完成的,这些参数属于索引API、更新API或删除API。
例如,以下索引调用将确保在不丢失对描述的任何潜在更改或由另一个API添加的另一个标签的情况下,向文档添加一个标签:
PUT products/_doc/1567?if_seq_no=362&if_primary_term=2
{
"product": "r2d2",
"details": "A resourceful astromech droid",
"tags": [ "droid" ]
}