
估算作业资源需求对企业集群来说仍然是一个重要且具有挑战性的问题。随着工作负载日益复杂化(从传统的批处理作业到交互式查询,再到流处理以及最近的机器学习作业),这一问题变得更加突出。这导致作业需要依赖多种计算框架(如Tez、MapReduce、Spark等),而集群的共享特性进一步加剧了问题的复杂性。当前最先进的解决方案依赖于用户专业知识来估算作业资源需求(例如reducer数量或容器内存大小等),这种方式既繁琐又低效。
通过对集群工作负载的分析,我们观察到大部分作业(超过60%)是重复性作业,这使我们有机会基于作业历史运行记录自动估算资源需求。值得注意的是,这些作业通常来自不同的计算框架,且每次运行的版本也可能发生变化。因此,我们希望开发一个与框架无关的黑盒解决方案,为重复性作业自动进行资源需求估算。
下图展示了资源估算器的实现架构。

Hadoop-resourceestimator主要由三个模块组成:Translator、SkylineStore和Estimator。
ResourceSkyline 用于描述作业在其生命周期内的资源利用率。具体来说,它使用 RLESparseResourceAllocation (https://github.com/apache/hadoop/blob/b6e7d1369690eaf50ce9ea7968f91a72ecb74de0/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-resourcemanager/src/main/java/org/apache/hadoop/yarn/server/resourcemanager/reservation/RLESparseResourceAllocation.java) 来记录容器分配信息。RecurrenceId 用于标识周期性流水线的特定运行实例。一个流水线可能包含多个作业,每个作业都有一个 ResourceSkyline 来描述其资源利用率。Translator解析作业日志,提取其中的ResourceSkylines并将其存储到SkylineStore中。SingleLineParser解析日志流中的单行并提取ResourceSkyline。LogParser使用SingleLineParser递归解析日志流中的每一行。请注意,日志可能具有不同的存储格式,因此LogParser接收字符串流作为输入,而不是文件或其他格式。由于作业日志可能有多种格式,因此需要不同的SingleLineParser实现,LogParser会根据用户配置初始化SingleLineParser。目前Hadoop-resourceestimator为SingleLineParser提供了两种实现:NativeSingleLineParser支持优化的原生格式,而RMSingleLineParser解析Hadoop系统中生成的YARN ResourceManager日志(因为RM日志在生产部署中广泛可用)。SkylineStore 作为Hadoop资源估算器的存储层,包含两个部分。HistorySkylineStore 存储由Translator提取的ResourceSkylines。它支持四种操作:addHistory(添加历史记录)、deleteHistory(删除历史记录)、updateHistory(更新历史记录)和getHistory(获取历史记录)。addHistory将新的ResourceSkylines追加到循环管道中,而updateHistory会删除特定循环管道的所有ResourceSkylines,并重新插入新的ResourceSkylines。PredictionSkylineStore存储由估算器生成的预测RLESparseResourceAllocation。它支持两种操作:addEstimation(添加估算)和getEstimation(获取估算)。
目前Hadoop资源估算器为SkylineStore提供了内存实现。
Estimator 根据历史运行记录预测周期性流水线的资源需求,将预测结果存储到SkylineStore中,并向YARN提交周期性资源预留(YARN-5326)。Solver读取特定周期性流水线的所有历史ResourceSkylines记录,预测其新的资源需求并封装为RLESparseResourceAllocation。当前Hadoop-resourceestimator提供LPSOLVER进行预测(线性规划模型细节可查阅论文)。另提供BaseSolver将预测的资源需求转换为ReservationSubmissionRequest,供不同求解器实现用于在YARN上创建周期性资源预留。ResourceEstimationService 将Hadoop-resourceestimator封装为微服务,可轻松部署在集群中。它提供一组REST API,允许用户解析指定的作业日志、查询流水线的历史ResourceSkylines、查询流水线的预测资源需求,并在预测不存在时运行SOLVER,以及删除SkylineStore中的ResourceSkylines。本节将指导您如何使用资源估算服务。
这里用$HADOOP_ROOT表示Hadoop的安装目录。如果您自行构建Hadoop,$HADOOP_ROOT就是hadoop-dist/target/hadoop-$VERSION。资源估算器服务的路径$ResourceEstimatorServiceHome位于$HADOOP_ROOT/share/hadoop/tools/resourceestimator,包含3个文件夹:bin、conf和data。请注意用户可以使用资源估算器服务的默认配置。
bin 目录包含资源估算器服务的运行脚本。
conf: 包含资源估算器服务的配置文件。
data 包含用于运行资源估算器服务示例的样本日志。
首先,将配置文件(位于$ResourceEstimatorServiceHome/conf/)复制到$HADOOP_ROOT/etc/hadoop目录下。
启动估算器的脚本是start-estimator.sh。
$ cd $ResourceEstimatorServiceHome $ bin/start-estimator.sh
启动了一个Web服务器,用户可以通过REST API使用资源估算服务。
资源估算器服务的URI为http://0.0.0.0,默认服务端口为9998(配置在$ResourceEstimatorServiceHome/conf/resourceestimator-config.xml中)。在$ResourceEstimatorServiceHome/data目录下有一个示例日志文件resourceEstimatorService.txt,其中包含tpch_q12查询作业运行2次的日志记录。
parse job logs: POST http://URI:port/resourceestimator/translator/LOG_FILE_DIRECTORY发送 POST http://0.0.0.0:9998/resourceestimator/translator/data/resourceEstimatorService.txt。底层估算器将从日志文件中提取ResourceSkylines,并将其存储在jobHistory SkylineStore中。
查询作业历史资源轮廓: GET http://URI:port/resourceestimator/skylinestore/history/{pipelineId}/{runId}发送 GET http://0.0.0.0:9998/resourceestimator/skylinestore/history/*/*,底层估算器将返回历史SkylineStore中的所有记录。您应该能看到两次运行tpch_q12的资源轮廓:tpch_q12_0和tpch_q12_1。请注意,pipelineId和runId字段都支持通配符操作。
预测作业的资源需求轮廓: GET http://URI:port/resourceestimator/estimator/{pipelineId}发送 http://0.0.0.0:9998/resourceestimator/estimator/tpch_q12,底层估算器将根据历史资源天际线预测新作业运行的资源需求,并将预测的资源需求存储到 jobEstimation SkylineStore。
查询作业的预估资源天际线: GET http://URI:port/resourceestimator/skylinestore/estimation/{pipelineId}发送 http://0.0.0.0:9998/resourceestimator/skylinestore/estimation/tpch_q12,底层估算器将返回tpch_q12作业的历史资源需求估算。请注意,对于jobEstimation SkylineStore,它不支持通配符操作。
删除作业的历史资源天际线: DELETE http://URI:port/resourceestimator/skylinestore/history/{pipelineId}/{runId}发送 http://0.0.0.0:9998/resourceestimator/skylinestore/history/tpch_q12/tpch_q12_0,底层估算器将删除tpch_q12_0的ResourceSkyline记录。重新发送 GET http://0.0.0.0:9998/resourceestimator/skylinestore/history/*/*,底层估算器将仅返回tpch_q12_1的ResourceSkyline。
停止估计器的脚本是stop-estimator.sh。
$ cd $ResourceEstimatorServiceHome $ bin/stop-estimator.sh
这里我们展示一个使用Resource Estimator服务的示例。
首先,我们运行tpch_q12作业9次,并在每次运行中收集作业的资源使用情况(注意:在本示例中,我们仅收集"分配的容器数量"信息)。
然后,我们在资源估算服务中运行日志解析器,从日志中提取ResourceSkylines并将其存储在SkylineStore中。下方展示了作业的ResourceSkylines图表以供演示。
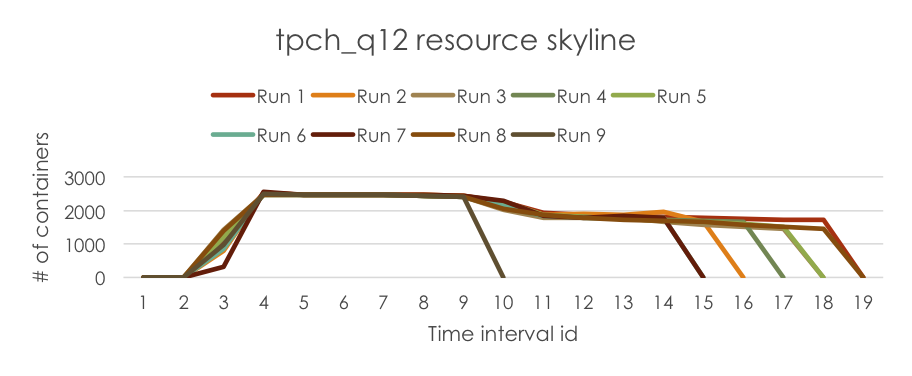
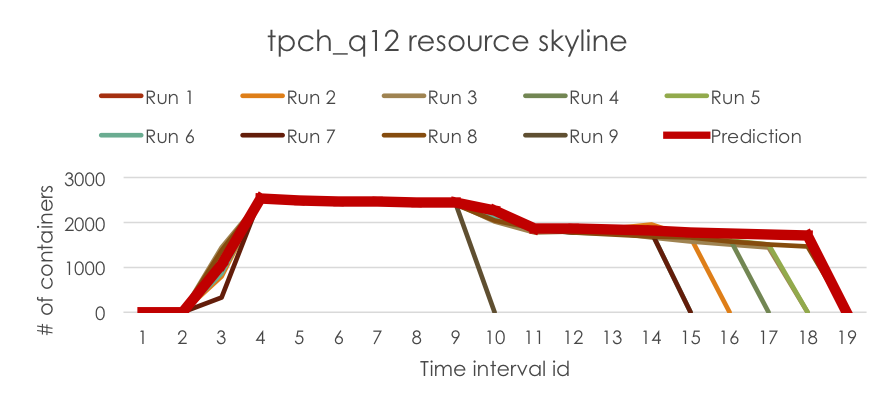
最后,我们在Resource Estimator Service中运行估算器来预测新运行任务的资源需求,该需求被封装在RLESparseResourceAllocation中(https://github.com/apache/hadoop/blob/b6e7d1369690eaf50ce9ea7968f91a72ecb74de0/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-resourcemanager/src/main/java/org/apache/hadoop/yarn/server/resourcemanager/reservation/RLESparseResourceAllocation.java)。下方展示了预测的资源需求示意图。
本节将指导您完成资源估算器服务的配置。配置文件位于$ResourceEstimatorServiceHome/conf/resourceestimator-config.xml。
resourceestimator.solver.lp.alphaThe resource estimator has an integrated Linear Programming solver to make the prediction (refer to https://www.microsoft.com/en-us/research/wp-content/uploads/2016/10/osdi16-final107.pdf for more details), and this parameter tunes the tradeoff between resource over-allocation and under-allocation in the Linear Programming model. This parameter varies from 0 to 1, and a larger alpha value means the model minimizes over-allocation better. Default value is 0.1.
resourceestimator.solver.lp.beta该参数控制线性规划模型的泛化能力。参数取值范围为0到1,默认值为0.1。
resourceestimator.solver.lp.minJobRuns进行预测所需的最小作业运行次数。默认值为2。
resourceestimator.timeInterval用于将作业执行离散化为时间间隔的时间长度。请注意,估算器会为每个间隔进行资源分配预测。较小的时间间隔能提供更细粒度的预测,但也会占用更长的预测时间和更多空间。默认值为5(秒)。
resourceestimator.skylinestore.providerskylinestore提供者的类名。默认值为org.apache.hadoop.resourceestimator.skylinestore.impl.InMemoryStore,这是skylinestore的内存实现。如果用户想要使用自己的skylinestore实现,需要相应地修改此值。
resourceestimator.translator.providerThe class name of the translator provider. Default value is org.apache.hadoop.resourceestimator.translator.impl.BaseLogParser, which extracts resourceskylines from log streams. If users want to use their own translator implementation, they need to change this value accordingly.
resourceestimator.translator.line-parserThe class name of the translator single-line parser, which parses a single line in the log. Default value is org.apache.hadoop.resourceestimator.translator.impl.NativeSingleLineParser, which can parse one line in the sample log. Note that if users want to parse Hadoop Resource Manager (https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html) logs, they need to set the value to be org.apache.hadoop.resourceestimator.translator.impl.RmSingleLineParser. If they want to implement single-line parser to parse their customized log file, they need to change this value accordingly.
resourceestimator.solver.provider求解器提供者的类名。默认值为org.apache.hadoop.resourceestimator.solver.impl.LpSolver,该值采用线性规划模型进行预测。如果用户希望实现自己的模型,需要相应地修改此值。
resourceestimator.service-portResourceEstimatorService监听的端口号。默认值为9998。
对于SkylineStore,我们计划提供一个持久化存储实现。考虑到未来的扩展需求,我们正在评估采用HBase方案。
For Translator module, we want to support Timeline Service v2 as the primary source as we want to rely on a stable API and logs are flaky at best.
由于数据倾斜、资源争用、输入数据或代码变更等原因,作业的资源需求在不同运行中可能有所不同。我们希望设计一个重新配置模块(Reprovisioner),该模块能够在运行时动态监控作业进度,当进度低于预期时识别性能瓶颈,并通过ReservationUpdateRequest动态调整作业的资源分配。
When Estimator predicts job’s resource requirements, we want to provide the confidence level associated with the prediction according to the estimation error (combination of over-allocation and under-allocation), etc.
对于Estimator模块,我们可以集成强化学习等机器学习工具来提升预测效果。同时还能整合PerfOrator等特定领域求解器来优化预测质量。
对于Estimator模块,我们希望设计增量求解器,它能够仅基于新日志增量更新作业的资源需求。