如何在Label Studio中使用提示生成合成数据

合成数据生成正成为构建可扩展AI系统的核心部分,尤其是在标注数据稀缺或成本高昂的情况下。这篇博客基于我们最近的网络研讨会,由ML技术推广专家Micaela Kaplan详细介绍如何利用Label Studio的Prompts功能从现有数据生成合成问答对。无论您是在构建RAG系统还是为评估增强数据,本指南都将帮助您快速入门。
合成数据对RAG和LLM评估的重要性
Synthetic data enables you to fill in gaps where your existing datasets fall short, especially useful in scenarios like:
- 构建检索增强生成(RAG)系统
- 从产品规格或技术文档中模拟问答对
- 扩展特定领域的模型训练数据
您拥有:来自公司的数据——技术解答、产品规格、用户信息
您需要:为RAG系统准备问答对
我们可以从您已有的资源中生成您所需的内容!
项目设置:所需准备
要跟随操作,您需要:
- 访问 Label Studio
- 问答任务的标注配置
- 一个与OpenAI兼容的API密钥(试用期内包含)
- 项目数据: 从Kaggle上的CMU图书摘要数据集中提取的CSV文件,截取至50行。在本教程中,我们仅使用三个字段:BookTitle(书名)、Author(作者)和Summary(摘要)
上传数据集后,您的任务将包含描述每本书的文本字段。
Label Studio 中的项目设置
以下是本项目中使用的标签配置:
<View>
<Style>
.question {font-size: 120%;
width: 800px;
margin-bottom: 0.5em;
border: 1px solid #eee;
padding: 0 1em 1em 1em;
background: #EDEDFD;}
</Style>
<Header value="Title"/>
<Text name="book_title" value="$BookTitle"/>
<Header value="Author"/>
<Text name="author" value="$Author"/>
<Header value="Summary"/>
<Text name="summary" value="$Summary"/>
<View className="question">
<Header value="What question might someone ask about this book?"/>
<TextArea name="question" toName="book_title,author,summary" editable="true" placeholder="Type a question here..."/>
<Header value="What genre(s) might this book be?"/>
<TextArea name="genre" toName="book_title,author,summary" placeholder="Type the genre(s) here" />
</View>
</View>
该设置支持人工和模型生成的输入,方便您轻松审核和编辑输出内容。
提示词正文示例
Label Studio Prompts 允许您为大型语言模型(LLM)配置结构化的输入输出任务。在本示例中,我们使用了以下提示内容:
提供以下数据:
BookTitle: 书籍标题
Author: 书籍作者
Summary: 书籍摘要。
你的任务是生成一个用户可能会提出的问题,以得到指定的书籍。
我们期望输出以下字段:
– question: 可以提出以获得给定书籍结果的问题
– genre: 最多3个类型的分类列表。
数据导出与使用
当您对输出结果满意时:
- 您可以一键将预测结果转换为标注
- 导出为JSON格式,保留原始数据和生成数据
- 将数据用作下游任务的训练输入或作为RAG管道中的文档

使用Label Studio可生成的合成数据
虽然本次网络研讨会重点讨论了为书籍摘要生成问答对,但Label Studio Prompts支持广泛的合成数据生成任务,在训练数据有限或不完整时尤其有用。
一些示例包括:
- Image Captioning: 使用Gemini或GPT-4等模型从图像生成自然语言描述。非常适合提升可访问性、搜索索引或数据集引导。
- 文档摘要:将长文本(如产品手册、支持工单、法律文件)压缩为简短摘要,以便更快检索或分类。
- 为复杂输入(如产品描述、评论或支持日志)分配分类,这在客户服务自动化中特别有用。
- 使用提示从原始文本中提取或模拟标注范围(如姓名、日期或地点),加速标注工作流程。
- 基于图像的元数据生成:虽然Label Studio不生成图像,但您可以根据视觉输入为图像数据集生成元数据、标题、标签或上下文问答。
这些提示流程可以应用于真实数据、合成输入或两者的组合,非常适合在边缘情况下进行预训练、评估或压力测试模型。
想要构建自己的用例吗?您可以在Label Studio中混合搭配图像、文本和音频输入,并使用自定义的提示模板。
如何评估合成数据的质量
生成合成数据只是挑战的一半,另一半是判断其质量如何。不准确或无关的输出可能会悄无声息地降低模型性能,因此制定结构化的评估计划至关重要。
以下是几种您可以根据使用场景采用的策略:
1. 与真实标注数据对比(如有可用数据)
如果您已经有一个标注好的数据集,可以将其作为基准来评估合成输出的质量。在Label Studio中,通过启用以下一致性指标即可自动完成此操作:
- 精确匹配
- 编辑距离
- 任务级别一致性评分
使用场景:当您需要生成额外样本来扩展现有数据集时。
2. 人机协同审核
让标注人员验证、编辑或拒绝LLM生成的输出。这有助于:
- 确保相关性(例如,生成的问题是否确实可以从输入中回答?)
- 提升流畅度与事实准确性
- 捕捉幻觉或错误分类
Label Studio 让用户只需一键即可将预测结果转换为可编辑的标注,操作非常简便。
适用场景:从零开始构建数据集并希望保持质量控制时使用。
3. 通过下游任务进行反向评估
使用您的合成数据来训练或微调模型,然后在独立的测试集上评估该模型的性能。这有助于您间接衡量合成样本是否改善了模型在现实世界中的表现。
适用场景:为特定应用(如RAG或分类)生成训练数据时使用。
4. 双LLM评估(谨慎使用)
一些团队尝试使用一个大型语言模型生成数据,再用另一个模型进行评估。虽然这不能完全替代人工审核,但有助于对大量输出结果进行初步筛选。
适用场景:当您有大量输出数据需要自动化初步处理时。
5. 统计审计与分布检查
检查以下内容的一致性:
- 标签分布(例如,某些类型或类别的过度代表)
- 输入多样性
- 生成输出的长度和复杂度
适用场景:当您希望确保合成数据不会以意外方式扭曲数据集时。
准备好亲自尝试了吗?
无论您是在构建RAG流程,还是仅需要一种更快速的方式来引导标注数据,通过提示进行合成生成都能为您提供灵活且经济高效的解决方案。最棒的部分是什么?您现在就可以立即尝试。
- 开始您的Label Studio Starter Cloud免费试用
- 加入我们的社区Slack 提问、分享反馈或从其他用户那里获取灵感
开始实验,并告诉我们你构建了什么!
相关内容
-
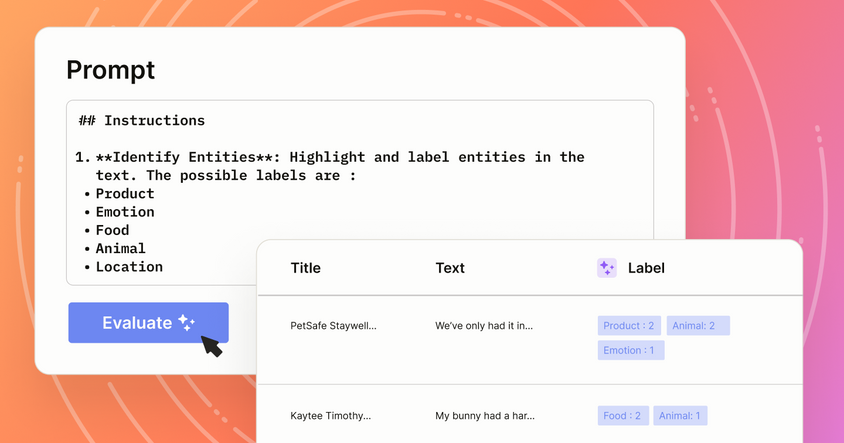
如何在Label Studio中使用提示词评估和比较大语言模型
使用大语言模型标注数据很快——但它准确吗?本文展示了在Label Studio中评估模型性能的两种方法,无论是否有真实标签数据。学习如何比较输出结果、跟踪准确率和成本,并为你的工作流程选择合适的模型。

米凯拉·卡普兰
2025年4月2日
-

在这篇文章中,我们将介绍Label Studio AI助手和提示词的一个创意用例:生成丰富的图像叙事。跟随我们的步骤,了解如何构建一个将结构化标注与故事讲述相结合的项目。

Sheree Zhang
2025年4月1日
-
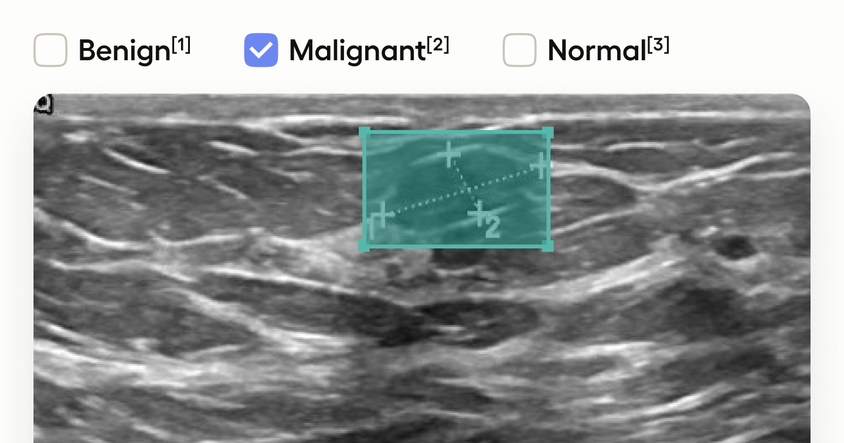
本教程将指导您如何使用Label Studio高效标注医学图像,从项目设置到绘制边界框和配置分类标签的全过程。
Micaela Kaplan
2025年1月16日