如何将Pachyderm与Label Studio集成

为什么要集成这些工具?
Label Studio 和 Pachyderm 强强联合,为数据集开发阶段以及模型再训练和主动学习阶段的用户提供了构建更优质、更强大模型所需的工具。这两款工具都以数据为核心,并高度重视所处理数据集的完整性和准确性。
Label Studio和Pachyderm在各行业和用例中广受欢迎,两者都提供灵活的社区驱动开源方案,同时也提供企业级云服务和本地部署方案。根据您组织或数据标注团队所处的阶段和规模,Pachyderm和Label Studio几乎能为任何规模层级的用户提供解决方案。
阅读本系列的第一部分,了解像Pachyderm和Label Studio这样的版本控制工具如何促进数据集开发和提升机器学习准确性点击这里。
开始使用Pachyderm与Label Studio集成
在开始使用Pachyderm和Label Studio集成之前,请确保您已运行这两个实例。您可以通过在此处注册免费试用或使用我们的入门教程来开始使用Label Studio。这还将有助于规划您现有的机器学习工作流程,以便您的数据科学和ML团队中的每个人都能保持一致。
分步操作指南
- 设置 Pachyderm 集群。 按照 Pachyderm 文档中的说明 来设置 Pachyderm 集群。这包括创建 Kubernetes 集群并安装 Pachyderm 软件。
- 创建数据仓库。 当 Pachyderm 集群设置完成后,创建数据仓库来存储您的数据。使用 Pachyderm CLI 或任一语言客户端来创建新仓库。在数据被标注后,还可以创建管道来处理数据。
- 运行Label Studio Docker容器。 接下来,使用打包好的Pachyderm挂载服务器运行Label Studio Docker容器。为容器提供您的Pachyderm配置,以便它可以访问集群。更多详情请参阅GitHub上的集成。
- 导入原始数据。 当Label Studio Docker容器启动并运行后,使用Pachyderm集成设置源存储区和目标存储区。点击"同步存储"后,存储库将被挂载,数据将出现在Label Studio中。
- 标注您的数据。导入数据后,像往常一样使用Label Studio网页界面开始标注。
- 同步目标存储。 创建标签后,同步目标存储将所有标签推送到目标Pachyderm数据仓库。
更多详情,请查看GitHub上的集成或参阅Pachyderm在Medium和YouTube上的分步教程。我们还提供了一个目标检测示例,该示例结合了Label Studio并将此集成应用到完整的机器学习工作流程中。
总结
数据标注对于改进机器学习模型至关重要,而版本控制是标注流程中不可或缺的一环。通过使用Label Studio与Pachyderm等平台集成,您可以追踪和管理数据变更,确保获得最高质量的标注数据用于模型训练,并在整个机器学习生命周期中实现可复现性。
相关内容
-
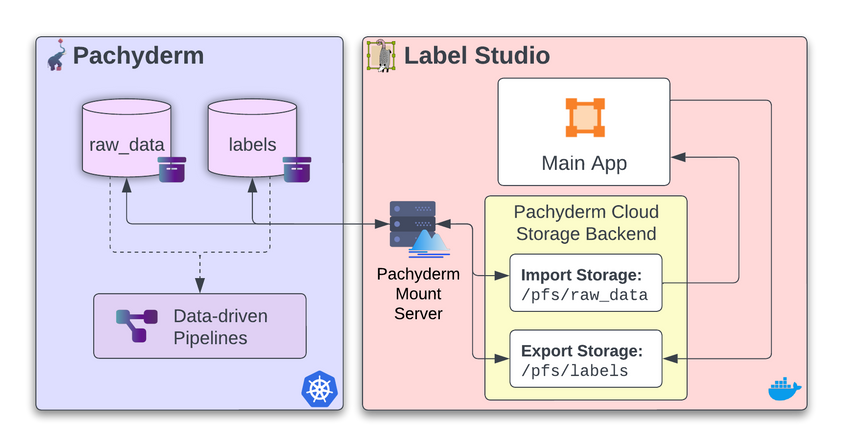
Label Studio与Pachyderm的集成使得将数据版本控制纳入任何数据团队的标注流程变得更加容易。

Jimmy Whitaker
2023年3月6日