分布式写入¶
概述¶
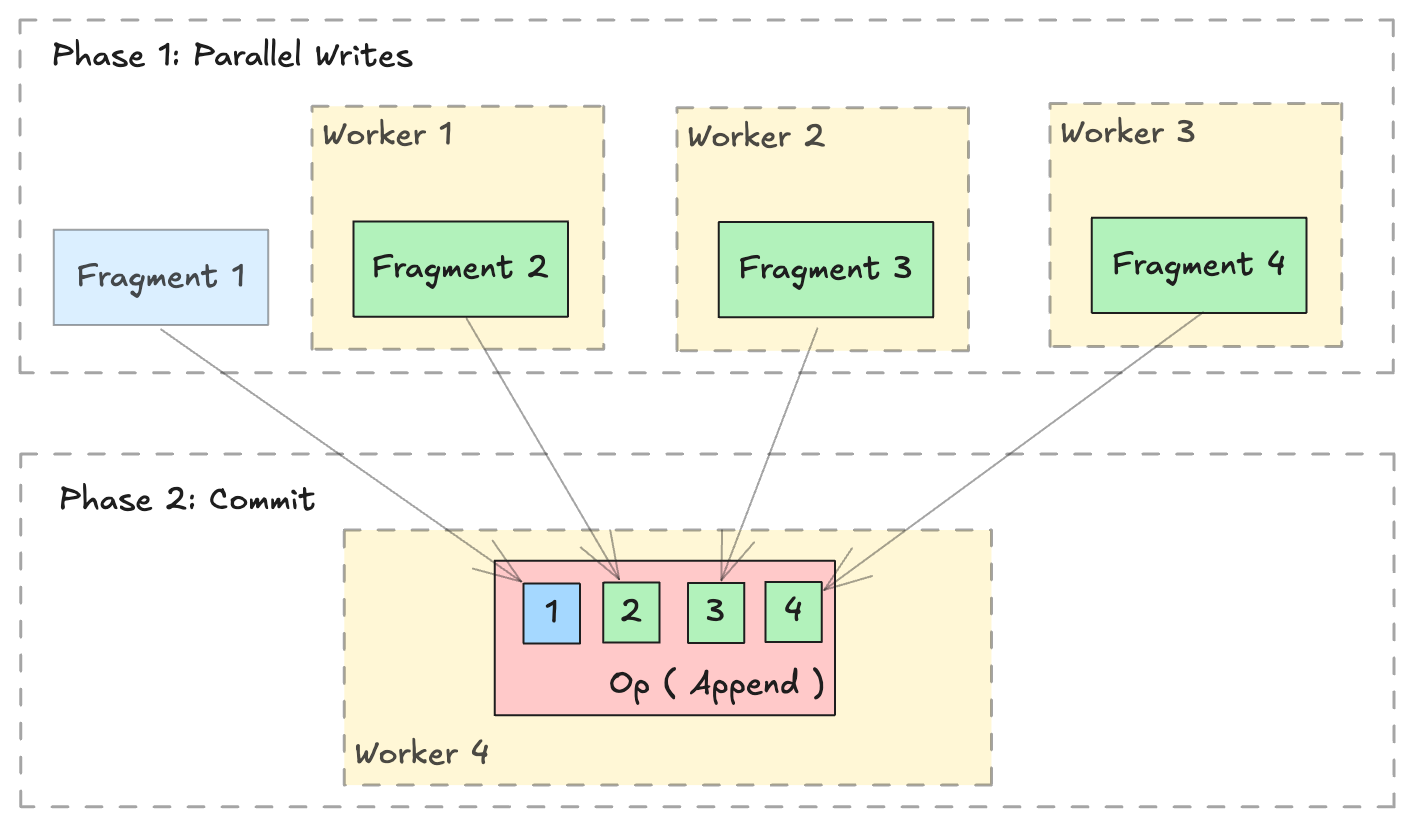
Lance格式旨在支持多个分布式工作器之间的并行写入。分布式写入操作可以通过两个阶段执行:
并行写入: 在多个工作节点上并行生成新的
LanceFragment。提交: 收集所有
FragmentMetadata并通过单个LanceOperation提交到一个数据集中。
写入新数据¶
使用write_fragments()可以轻松写入或追加新数据。
import json
from lance.fragment import write_fragments
# Run on each worker
data_uri = "./dist_write"
schema = pa.schema([
("a", pa.int32()),
("b", pa.string()),
])
# Run on worker 1
data1 = {
"a": [1, 2, 3],
"b": ["x", "y", "z"],
}
fragments_1 = write_fragments(data1, data_uri, schema=schema)
print("Worker 1: ", fragments_1)
# Run on worker 2
data2 = {
"a": [4, 5, 6],
"b": ["u", "v", "w"],
}
fragments_2 = write_fragments(data2, data_uri, schema=schema)
print("Worker 2: ", fragments_2)
Worker 1: [FragmentMetadata(id=0, files=...)]
Worker 2: [FragmentMetadata(id=0, files=...)]
现在,使用lance.fragment.FragmentMetadata.to_json()来序列化片段元数据,
并将所有序列化的元数据收集到单个工作节点上以执行最终的提交操作。
import json
from lance import FragmentMetadata, LanceOperation
# Serialize Fragments into JSON data
fragments_json1 = [json.dumps(fragment.to_json()) for fragment in fragments_1]
fragments_json2 = [json.dumps(fragment.to_json()) for fragment in fragments_2]
# On one worker, collect all fragments
all_fragments = [FragmentMetadata.from_json(f) for f in \
fragments_json1 + fragments_json2]
# Commit the fragments into a single dataset
# Use LanceOperation.Overwrite to overwrite the dataset or create new dataset.
op = lance.LanceOperation.Overwrite(schema, all_fragments)
read_version = 0 # Because it is empty at the time.
lance.LanceDataset.commit(
data_uri,
op,
read_version=read_version,
)
# We can read the dataset using the Lance API:
dataset = lance.dataset(data_uri)
assert len(dataset.get_fragments()) == 2
assert dataset.version == 1
print(dataset.to_table().to_pandas())
a b
0 1 x
1 2 y
2 3 z
3 4 u
4 5 v
5 6 w
追加数据¶
追加额外数据的过程类似。使用lance.LanceOperation.Append提交新片段时,需确保read_version设置为当前数据集的版本。
ds = lance.dataset(data_uri)
read_version = ds.version
op = lance.LanceOperation.Append(schema, all_fragments)
lance.LanceDataset.commit(
data_uri,
op,
read_version=read_version,
)
添加新列¶
Lance Format 在添加列等操作方面表现出色。 得益于其二维布局 (参见这篇博客文章), 添加新列非常高效,因为它避免了复制现有数据文件。 相反,该过程只需创建新的数据文件,并通过仅涉及元数据的操作将它们链接到现有数据集。
from pyarrow import RecordBatch
import pyarrow.compute as pc
from lance import LanceFragment, LanceOperation
dataset = lance.dataset("./add_columns_example")
assert len(dataset.get_fragments()) == 2
assert dataset.to_table().combine_chunks() == pa.Table.from_pydict({
"name": ["alice", "bob", "charlie", "craig", "dave", "eve"],
"age": [25, 33, 44, 55, 66, 77],
}, schema=schema)
def name_len(names: RecordBatch) -> RecordBatch:
return RecordBatch.from_arrays(
[pc.utf8_length(names["name"])],
["name_len"],
)
# On Worker 1
frag1 = dataset.get_fragments()[0]
new_fragment1, new_schema = frag1.merge_columns(name_len, ["name"])
# On Worker 2
frag2 = dataset.get_fragments()[1]
new_fragment2, _ = frag2.merge_columns(name_len, ["name"])
# On Worker 3 - Commit
all_fragments = [new_fragment1, new_fragment2]
op = lance.LanceOperation.Merge(all_fragments, schema=new_schema)
lance.LanceDataset.commit(
"./add_columns_example",
op,
read_version=dataset.version,
)
# Verify dataset
dataset = lance.dataset("./add_columns_example")
print(dataset.to_table().to_pandas())
name age name_len
0 alice 25 5
1 bob 33 3
2 charlie 44 7
3 craig 55 5
4 dave 66 4
5 eve 77 3