Lance格式既是一种表格格式也是一种文件格式。Lance通常将表格称为"数据集"。Lance数据集的设计旨在高效处理二级索引、快速数据摄取和修改,以及提供丰富的模式演进功能。
数据集目录
一个Lance数据集以目录形式组织。
/path/to/dataset:
data/*.lance -- Data directory
_versions/*.manifest -- Manifest file for each dataset version.
_indices/{UUID-*}/index.idx -- Secondary index, each index per directory.
_deletions/*.{arrow,bin} -- Deletion files, which contain ids of rows
that have been deleted.
一个Manifest文件包含描述数据集版本的元数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124 | // Manifest is a global section shared between all the files.
message Manifest {
// All fields of the dataset, including the nested fields.
repeated lance.file.Field fields = 1;
// Fragments of the dataset.
repeated DataFragment fragments = 2;
// Snapshot version number.
uint64 version = 3;
// The file position of the version auxiliary data.
// * It is not inheritable between versions.
// * It is not loaded by default during query.
uint64 version_aux_data = 4;
// Schema metadata.
map<string, bytes> metadata = 5;
message WriterVersion {
// The name of the library that created this file.
string library = 1;
// The version of the library that created this file. Because we cannot assume
// that the library is semantically versioned, this is a string. However, if it
// is semantically versioned, it should be a valid semver string without any 'v'
// prefix. For example: `2.0.0`, `2.0.0-rc.1`.
string version = 2;
}
// The version of the writer that created this file.
//
// This information may be used to detect whether the file may have known bugs
// associated with that writer.
WriterVersion writer_version = 13;
// If presented, the file position of the index metadata.
optional uint64 index_section = 6;
// Version creation Timestamp, UTC timezone
google.protobuf.Timestamp timestamp = 7;
// Optional version tag
string tag = 8;
// Feature flags for readers.
//
// A bitmap of flags that indicate which features are required to be able to
// read the table. If a reader does not recognize a flag that is set, it
// should not attempt to read the dataset.
//
// Known flags:
// * 1: deletion files are present
// * 2: move_stable_row_ids: row IDs are tracked and stable after move operations
// (such as compaction), but not updates.
// * 4: use v2 format (deprecated)
// * 8: table config is present
uint64 reader_feature_flags = 9;
// Feature flags for writers.
//
// A bitmap of flags that indicate which features are required to be able to
// write to the dataset. if a writer does not recognize a flag that is set, it
// should not attempt to write to the dataset.
//
// The flags are the same as for reader_feature_flags, although they will not
// always apply to both.
uint64 writer_feature_flags = 10;
// The highest fragment ID that has been used so far.
//
// This ID is not guaranteed to be present in the current version, but it may
// have been used in previous versions.
//
// For a single file, will be zero.
uint32 max_fragment_id = 11;
// Path to the transaction file, relative to `{root}/_transactions`
//
// This contains a serialized Transaction message representing the transaction
// that created this version.
//
// May be empty if no transaction file was written.
//
// The path format is "{read_version}-{uuid}.txn" where {read_version} is the
// version of the table the transaction read from, and {uuid} is a
// hyphen-separated UUID.
string transaction_file = 12;
// The next unused row id. If zero, then the table does not have any rows.
//
// This is only used if the "move_stable_row_ids" feature flag is set.
uint64 next_row_id = 14;
message DataStorageFormat {
// The format of the data files (e.g. "lance")
string file_format = 1;
// The max format version of the data files.
//
// This is the maximum version of the file format that the dataset will create.
// This may be lower than the maximum version that can be written in order to allow
// older readers to read the dataset.
string version = 2;
}
// The data storage format
//
// This specifies what format is used to store the data files.
DataStorageFormat data_format = 15;
// Table config.
//
// Keys with the prefix "lance." are reserved for the Lance library. Other
// libraries may wish to similarly prefix their configuration keys
// appropriately.
map<string, string> config = 16;
// The version of the blob dataset associated with this table. Changes to
// blob fields will modify the blob dataset and update this version in the parent
// table.
//
// If this value is 0 then there are no blob fields.
uint64 blob_dataset_version = 17;
} // Manifest
|
片段
DataFragment 表示数据集中的一个数据块。它本身包含一个或多个 DataFile,
其中每个 DataFile 可以包含该数据块中的多个列。它还可能包含一个
DeletionFile,这将在后续章节中解释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115 | // Data fragment. A fragment is a set of files which represent the
// different columns of the same rows.
// If column exists in the schema, but the related file does not exist,
// treat this column as nulls.
message DataFragment {
// Unique ID of each DataFragment
uint64 id = 1;
repeated DataFile files = 2;
// File that indicates which rows, if any, should be considered deleted.
DeletionFile deletion_file = 3;
// TODO: What's the simplest way we can allow an inline tombstone bitmap?
// A serialized RowIdSequence message (see rowids.proto).
//
// These are the row ids for the fragment, in order of the rows as they appear.
// That is, if a fragment has 3 rows, and the row ids are [1, 42, 3], then the
// first row is row 1, the second row is row 42, and the third row is row 3.
oneof row_id_sequence {
// If small (< 200KB), the row ids are stored inline.
bytes inline_row_ids = 5;
// Otherwise, stored as part of a file.
ExternalFile external_row_ids = 6;
} // row_id_sequence
// Number of original rows in the fragment, this includes rows that are
// now marked with deletion tombstones. To compute the current number of rows,
// subtract `deletion_file.num_deleted_rows` from this value.
uint64 physical_rows = 4;
}
// Lance Data File
message DataFile {
// Relative path to the root.
string path = 1;
// The ids of the fields/columns in this file.
//
// -1 is used for "unassigned" while in memory. It is not meant to be written
// to disk. -2 is used for "tombstoned", meaningful a field that is no longer
// in use. This is often because the original field id was reassigned to a
// different data file.
//
// In Lance v1 IDs are assigned based on position in the file, offset by the max
// existing field id in the table (if any already). So when a fragment is first
// created with one file of N columns, the field ids will be 1, 2, ..., N. If a
// second, fragment is created with M columns, the field ids will be N+1, N+2,
// ..., N+M.
//
// In Lance v1 there is one field for each field in the input schema, this includes
// nested fields (both struct and list). Fixed size list fields have only a single
// field id (these are not considered nested fields in Lance v1).
//
// This allows column indices to be calculated from field IDs and the input schema.
//
// In Lance v2 the field IDs generally follow the same pattern but there is no
// way to calculate the column index from the field ID. This is because a given
// field could be encoded in many different ways, some of which occupy a different
// number of columns. For example, a struct field could be encoded into N + 1 columns
// or it could be encoded into a single packed column. To determine column indices
// the column_indices property should be used instead.
//
// In Lance v1 these ids must be sorted but might not always be contiguous.
repeated int32 fields = 2;
// The top-level column indices for each field in the file.
//
// If the data file is version 1 then this property will be empty
//
// Otherwise there must be one entry for each field in `fields`.
//
// Some fields may not correspond to a top-level column in the file. In these cases
// the index will -1.
//
// For example, consider the schema:
//
// - dimension: packed-struct (0):
// - x: u32 (1)
// - y: u32 (2)
// - path: list<u32> (3)
// - embedding: fsl<768> (4)
// - fp64
// - borders: fsl<4> (5)
// - simple-struct (6)
// - margin: fp64 (7)
// - padding: fp64 (8)
//
// One possible column indices array could be:
// [0, -1, -1, 1, 3, 4, 5, 6, 7]
//
// This reflects quite a few phenomenon:
// - The packed struct is encoded into a single column and there is no top-level column
// for the x or y fields
// - The variable sized list is encoded into two columns
// - The embedding is encoded into a single column (common for FSL of primitive) and there
// is not "FSL column"
// - The borders field actually does have an "FSL column"
//
// The column indices table may not have duplicates (other than -1)
repeated int32 column_indices = 3;
// The major file version used to create the file
uint32 file_major_version = 4;
// The minor file version used to create the file
//
// If both `file_major_version` and `file_minor_version` are set to 0,
// then this is a version 0.1 or version 0.2 file.
uint32 file_minor_version = 5;
// The known size of the file on disk in bytes.
//
// This is used to quickly find the footer of the file.
//
// When this is zero, it should be interpreted as "unknown".
uint64 file_size_bytes = 6;
} // DataFile
|
片段(fragment)的整体结构如下所示。一个或多个数据文件存储着片段的各列。通过添加新的数据文件,可以向片段中添加新列。删除文件(如果存在)则存储了从该片段中删除的行记录。

每一行都有一个唯一的id,它是一个由两个u32组成的u64:片段id和本地行id。本地行id只是数据文件中该行的索引。
文件结构
每个.lance文件是实际数据的容器。
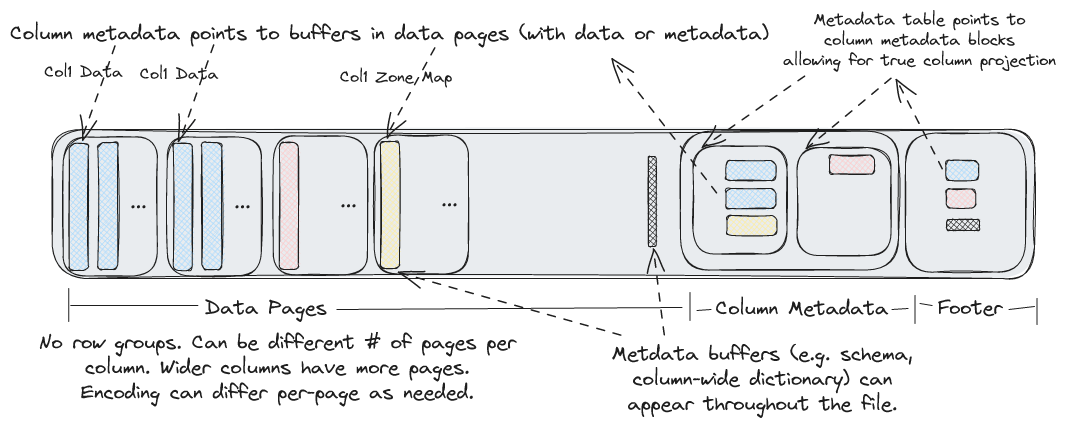
在文件末尾,ColumnMetadata protobuf块用于描述文件中列的编码方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45 | // ## Metadata
// Each column has a metadata block that is placed at the end of the file.
// These may be read individually to allow for column projection.
message ColumnMetadata {
// This describes a page of column data.
message Page {
// The file offsets for each of the page buffers
//
// The number of buffers is variable and depends on the encoding. There
// may be zero buffers (e.g. constant encoded data) in which case this
// could be empty.
repeated uint64 buffer_offsets = 1;
// The size (in bytes) of each of the page buffers
//
// This field will have the same length as `buffer_offsets` and
// may be empty.
repeated uint64 buffer_sizes = 2;
// Logical length (e.g. # rows) of the page
uint64 length = 3;
// The encoding used to encode the page
Encoding encoding = 4;
// The priority of the page
//
// For tabular data this will be the top-level row number of the first row
// in the page (and top-level rows should not split across pages).
uint64 priority = 5;
}
// Encoding information about the column itself. This typically describes
// how to interpret the column metadata buffers. For example, it could
// describe how statistics or dictionaries are stored in the column metadata.
Encoding encoding = 1;
// The pages in the column
repeated Page pages = 2;
// The file offsets of each of the column metadata buffers
//
// There may be zero buffers.
repeated uint64 buffer_offsets = 3;
// The size (in bytes) of each of the column metadata buffers
//
// This field will have the same length as `buffer_offsets` and
// may be empty.
repeated uint64 buffer_sizes = 4;
} // Metadata-End
|
Footer 描述了文件的整体布局。整个文件的布局结构如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56 | // ## File Layout
//
// Note: the number of buffers (BN) is independent of the number of columns (CN)
// and pages.
//
// Buffers often need to be aligned. 64-byte alignment is common when
// working with SIMD operations. 4096-byte alignment is common when
// working with direct I/O. In order to ensure these buffers are aligned
// writers may need to insert padding before the buffers.
//
// If direct I/O is required then most (but not all) fields described
// below must be sector aligned. We have marked these fields with an
// asterisk for clarity. Readers should assume there will be optional
// padding inserted before these fields.
//
// All footer fields are unsigned integers written with little endian
// byte order.
//
// ├──────────────────────────────────┤
// | Data Pages |
// | Data Buffer 0* |
// | ... |
// | Data Buffer BN* |
// ├──────────────────────────────────┤
// | Column Metadatas |
// | |A| Column 0 Metadata* |
// | Column 1 Metadata* |
// | ... |
// | Column CN Metadata* |
// ├──────────────────────────────────┤
// | Column Metadata Offset Table |
// | |B| Column 0 Metadata Position* |
// | Column 0 Metadata Size |
// | ... |
// | Column CN Metadata Position |
// | Column CN Metadata Size |
// ├──────────────────────────────────┤
// | Global Buffers Offset Table |
// | |C| Global Buffer 0 Position* |
// | Global Buffer 0 Size |
// | ... |
// | Global Buffer GN Position |
// | Global Buffer GN Size |
// ├──────────────────────────────────┤
// | Footer |
// | A u64: Offset to column meta 0 |
// | B u64: Offset to CMO table |
// | C u64: Offset to GBO table |
// | u32: Number of global bufs |
// | u32: Number of columns |
// | u16: Major version |
// | u16: Minor version |
// | "LANC" |
// ├──────────────────────────────────┤
//
// File Layout-End
|
文件版本
Lance文件格式经历了多次变更,其中包括从版本1到版本2的重大改动。提供多个API接口允许指定文件版本。使用较新的文件格式版本能获得更好的压缩率和/或性能表现。但请注意,旧版软件可能无法读取新版格式的文件。
此外,文件格式的最新版本(next)尚不稳定,不应在生产用例中使用。不稳定的编码可能会发生破坏性变更,这意味着使用这些编码写入的文件将无法被任何新版本的Lance读取。next版本仅应用于实验性测试和即将推出功能的基准测试。
支持以下值:
File Versions
版本 |
最低Lance版本要求 |
最高Lance版本要求 |
描述 |
|---|
0.1 |
Any |
Any |
这是最初的Lance格式。 |
2.0 |
0.16.0 |
Any |
对Lance文件格式进行了重构,移除了行组并新增了对列表、固定大小列表和基本类型的空值支持 |
2.1 (不稳定版) |
无 |
任意 |
增强整数和字符串压缩功能,增加对结构体字段中空值的支持,并提升嵌套字段的随机访问性能。 |
legacy |
N/A |
N/A |
0.1版本的别名 |
stable |
N/A |
N/A |
最新稳定版本的别名(当前为2.0) |
next |
N/A |
N/A |
最新不稳定版本的别名(当前为2.1) |
文件编码
Lance支持针对不同数据类型的多种编码方式。这些编码方案旨在兼顾随机访问和扫描性能。编码类型会随时间推移不断新增,未来也可能进一步扩展。清单中记录了一个最大格式版本号,用于控制实际采用的编码方式。这允许逐步迁移至新数据格式,确保在迁移过程中旧版读取器仍能读取新数据。
编码分为"字段编码"和"数组编码"。字段编码在整个数据字段中保持一致,而数组编码用于字段内的单个数据页。数组编码可以嵌套其他数组编码(例如字典编码可以对索引进行位压缩),但数组编码不能嵌套字段编码。因此,目前不支持像Dictionary List>这样的数据类型(因为没有字典字段编码)
Encodings Available
编码名称 |
编码类型 |
功能描述 |
支持版本 |
应用场景 |
|---|
基础结构 |
字段编码 |
编码非空结构数据 |
>= 2.0 |
结构的默认编码 |
列表 |
字段编码 |
编码列表(可为空或不可为空) |
>= 2.0 |
列表的默认编码 |
基础原始类型 |
字段编码 |
使用独立的有效性数组对原始数据类型进行编码 |
>= 2.0 |
原始数据类型的默认编码方式 |
值 |
数组编码 |
编码固定宽度值的单个向量 |
>= 2.0 |
固定宽度类型的后备编码 |
二进制 |
数组编码 |
编码单个可变宽度数据的向量 |
>= 2.0 |
可变宽度类型的后备编码方案 |
字典 |
数组编码 |
使用字典数组和索引数组对数据进行编码,适用于具有少量唯一值的大型数据类型 |
>= 2.0 |
用于唯一元素少于100个的字符串页面 |
打包结构体 |
数组编码 |
将结构体以行优先格式编码,固定宽度字段使随机访问更高效 |
>= 2.0 |
仅当字段元数据属性"packed"设置为"true"时用于结构体类型 |
Fsst |
数组编码 |
通过识别常见子串(8字节或更小)并将其编码为符号来压缩二进制数据 |
>= 2.1 |
用于未进行字典编码的字符串页面 |
位打包 |
数组编码 |
使用位打包对固定宽度值的单个向量进行编码,这对于不跨越完整值范围的整数类型非常有用 |
>= 2.1 |
用于整数类型 |
功能标志
随着文件格式和数据集的演进,新的特性标志会被添加到格式中。根据您是在尝试读取还是写入表格,有两个独立的字段用于检查特性标志。读取器应检查reader_feature_flags以查看是否存在任何它不知道的标志。写入器应检查writer_feature_flags。如果任一方发现不认识的标志,应在任何读取或写入操作时返回"不支持"错误。
字段
字段表示列的元数据。这包括名称、数据类型、ID、可空性以及编码方式。
字段按深度优先顺序列出,可以是以下类型之一:(1) 父级(结构体)、(2) 重复(列表/数组)或 (3) 叶节点(基本类型)。例如,以下模式:
a: i32
b: struct {
c: list<i32>
d: i32
}
将表示为以下字段列表:
名称 |
ID |
类型 |
父级ID |
逻辑类型 |
|---|
a
|
1 |
LEAF |
0 |
"int32"
|
b
|
2 |
父级 |
0 |
"struct"
|
b.c
|
3 |
重复 |
2 |
"list"
|
b.c
|
4 |
LEAF |
3 |
"int32"
|
b.d
|
5 |
LEAF |
2 |
"int32"
|
列级别的编码配置通过PyArrow字段元数据指定:
import pyarrow as pa
schema = pa.schema([
pa.field(
"compressible_strings",
pa.string(),
metadata={
"lance-encoding:compression": "zstd",
"lance-encoding:compression-level": "3",
"lance-encoding:structural-encoding": "miniblock",
"lance-encoding:packed": "true"
}
)
])
元数据键 |
类型 |
描述 |
示例值 |
使用示例(Python) |
|---|
lance-encoding:compression
|
压缩 |
指定压缩算法 |
zstd |
metadata={"lance-encoding:compression": "zstd"}
|
lance-encoding:compression-level
|
压缩 |
Zstd压缩级别(1-22) |
3 |
metadata={"lance-encoding:compression-level": "3"}
|
lance-encoding:blob
|
存储 |
标记二进制数据(大于4MB)用于分块存储 |
真/假 |
metadata={"lance-encoding:blob": "true"}
|
lance-encoding:packed
|
优化 |
结构体内存布局优化 |
真/假 |
metadata={"lance-encoding:packed": "true"}
|
lance-encoding:structural-encoding
|
嵌套数据 |
嵌套结构的编码策略 |
miniblock/fullzip |
metadata={"lance-encoding:structural-encoding": "miniblock"}
|
数据集更新与模式演进
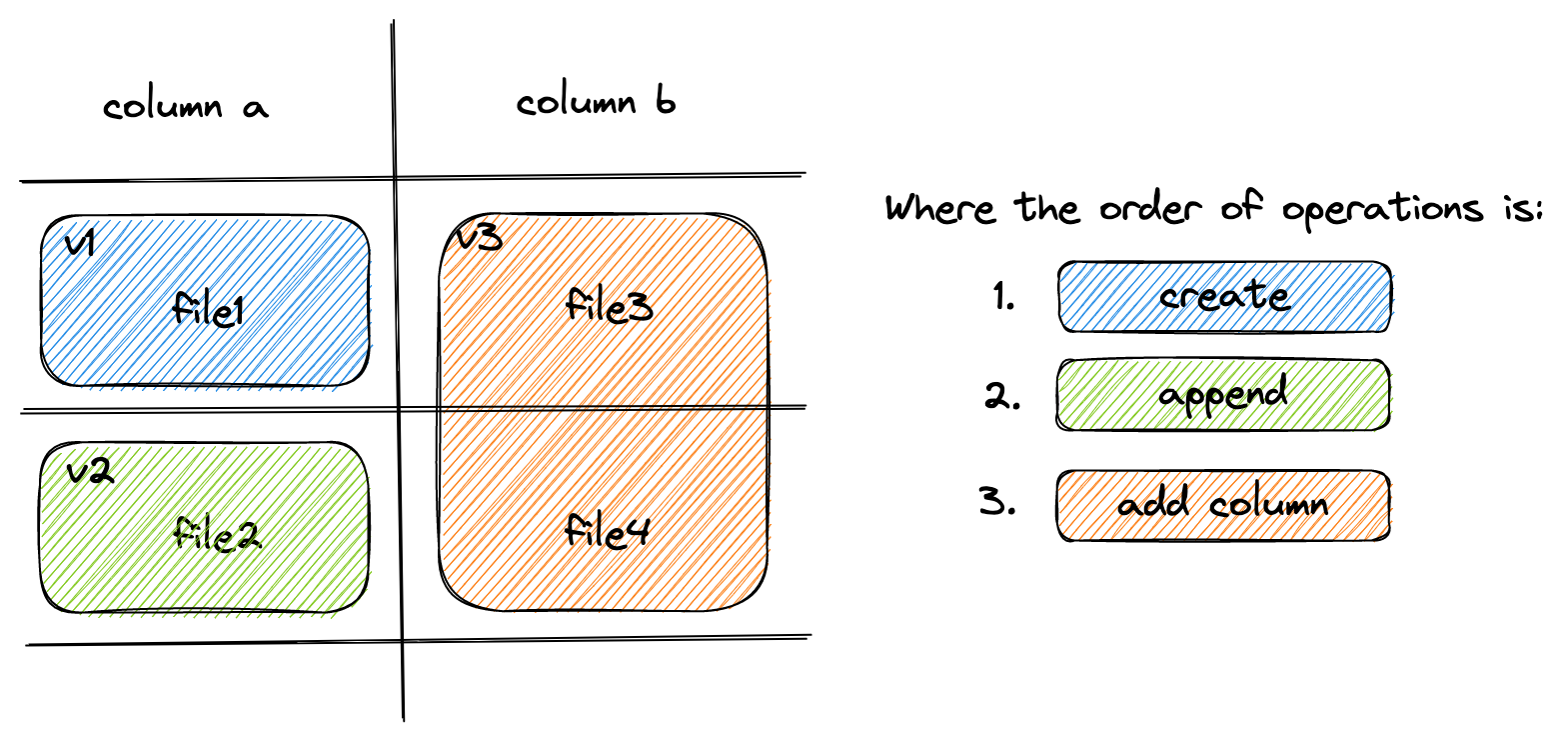
Lance 支持通过操作 Manifest 元数据实现快速数据集更新和模式演进。
Appending 是通过向数据集追加新的 Fragment 来完成的。
而添加列则是通过向每个 Fragment 添加新列的 DataFile 来实现的。
最后,可以通过重置 Manifest 的 Fragment 列表来完成对数据集的 Overwrite 操作。
删除
可以通过在数据旁边的_deletions文件夹中添加删除文件来标记行已删除。这些文件包含某些片段中已删除行的索引。对于给定版本的数据集,每个片段最多可以有一个删除文件。没有删除行的片段则没有删除文件。
读者在扫描或进行近似最近邻(ANN)搜索时,应过滤掉这些删除文件中包含的行ID。
删除文件分为两种类型:
Arrow文件:存储包含平面索引向量的列
Roaring bitmaps: 将索引存储为压缩位图。
Roaring Bitmaps用于较大的删除集,而Arrow文件用于较小的删除集。这是因为已知Roaring Bitmaps对小集合效率较低。
删除文件的文件名结构如下:
_deletions/{fragment_id}-{read_version}-{random_id}.{arrow|bin}
其中fragment_id表示文件对应的片段,read_version是
创建该文件时基于的数据集版本(通常比提交版本小一),而random_id是
用于避免冲突的随机i64值。后缀由文件类型决定(.arrow表示Arrow文件,
.bin表示roaring位图)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 | // Deletion File
//
// The path of the deletion file is constructed as:
// {root}/_deletions/{fragment_id}-{read_version}-{id}.{extension}
// where {extension} is `.arrow` or `.bin` depending on the type of deletion.
message DeletionFile {
// Type of deletion file, which varies depending on what is the most efficient
// way to store the deleted row offsets. If none, then will be unspecified. If there are
// sparsely deleted rows, then ARROW_ARRAY is the most efficient. If there are
// densely deleted rows, then BIT_MAP is the most efficient.
enum DeletionFileType {
// Deletion file is a single Int32Array of deleted row offsets. This is stored as
// an Arrow IPC file with one batch and one column. Has a .arrow extension.
ARROW_ARRAY = 0;
// Deletion file is a Roaring Bitmap of deleted row offsets. Has a .bin extension.
BITMAP = 1;
}
// Type of deletion file. If it is unspecified, then the remaining fields will be missing.
DeletionFileType file_type = 1;
// The version of the dataset this deletion file was built from.
uint64 read_version = 2;
// An opaque id used to differentiate this file from others written by concurrent
// writers.
uint64 id = 3;
// The number of rows that are marked as deleted.
uint64 num_deleted_rows = 4;
} // DeletionFile
|
删除操作可以通过重写数据文件并移除被删除的行来实现物化。然而,这会使得行索引失效,进而导致ANN索引失效,而重新计算这些索引的代价可能很高。
提交数据集
通过向_versions目录写入新的清单文件来提交数据集的新版本。
为了防止并发写入者相互覆盖,提交过程对所有写入者必须是原子性和一致性的。如果两个写入者尝试使用不同的机制提交,可能会互相覆盖对方的更改。对于任何原生支持原子性"重命名-如果不存在"或"写入-如果不存在"操作的存储系统,都应使用这些操作。本地文件系统和大多数云对象存储(包括Amazon S3、Google云存储、Microsoft Azure Blob存储)都具备此功能。对于缺乏此功能的系统,用户可以配置外部锁定机制。
清单命名方案
清单文件必须使用一致的命名方案。名称与版本对应。这样我们无需读取所有清单就能打开数据集的正确版本。同时也明确了下一个要写入的文件路径。
有两种命名方案可供使用:
V1: _versions/{version}.manifest. 这是旧的命名方案。
V2: _versions/{u64::MAX - version:020}.manifest。这是新的命名方案。版本号会补零(至20位)并从u64::MAX中减去。这样可以让版本按降序排列,从而通过单个列表调用就能在对象存储中找到最新的清单文件。
混合使用这两种命名方案是错误的。
冲突解决
如果两个写入者同时尝试提交,一个会成功而另一个会失败。失败的写入者应尝试重新提交,但前提是其更改与成功写入者所做的更改兼容。
给定提交的变更会记录为一个事务文件,存放在数据集目录下的_transactions前缀路径中。该事务文件是一个序列化的Transaction protobuf消息。具体定义请参阅transaction.proto文件。
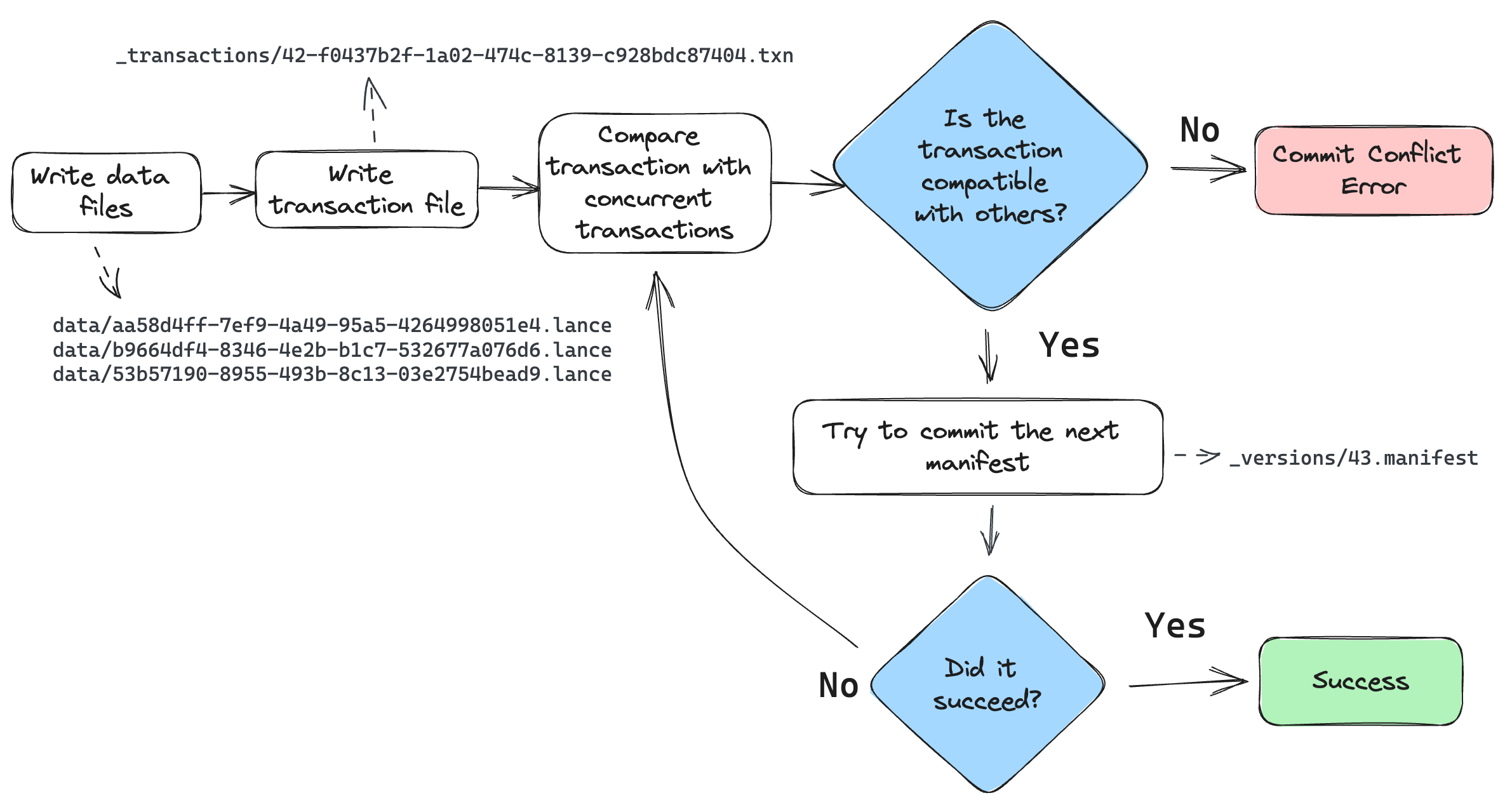
提交过程如下:
写入器完成所有数据文件的写入。
写入器会在_transactions目录中创建一个事务文件。该文件描述了执行的操作,用于两个目的:(1) 检测冲突,(2) 在重试期间重新构建清单。
检查自写入器开始写入以来的任何新提交。如果有新提交,读取其事务文件并检查是否存在冲突。如果存在冲突,则中止提交。否则继续。
构建一个清单并尝试提交到下一个版本。如果由于其他写入者已经提交而导致提交失败,则返回步骤3。
在检查两笔交易是否冲突时,应采取保守策略。若交易文件缺失,则默认存在冲突。若交易文件中包含未知操作类型,同样默认存在冲突。
外部清单存储
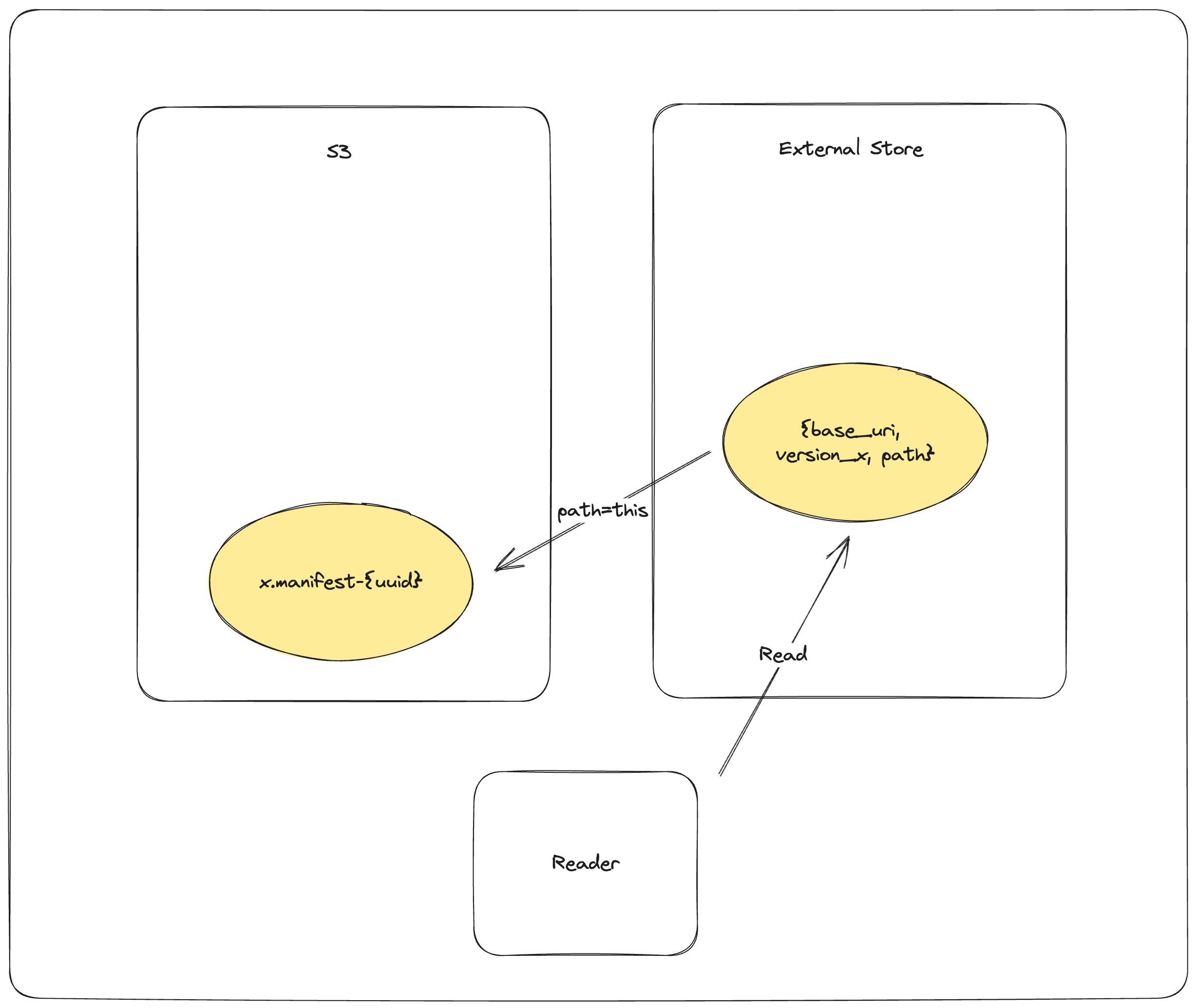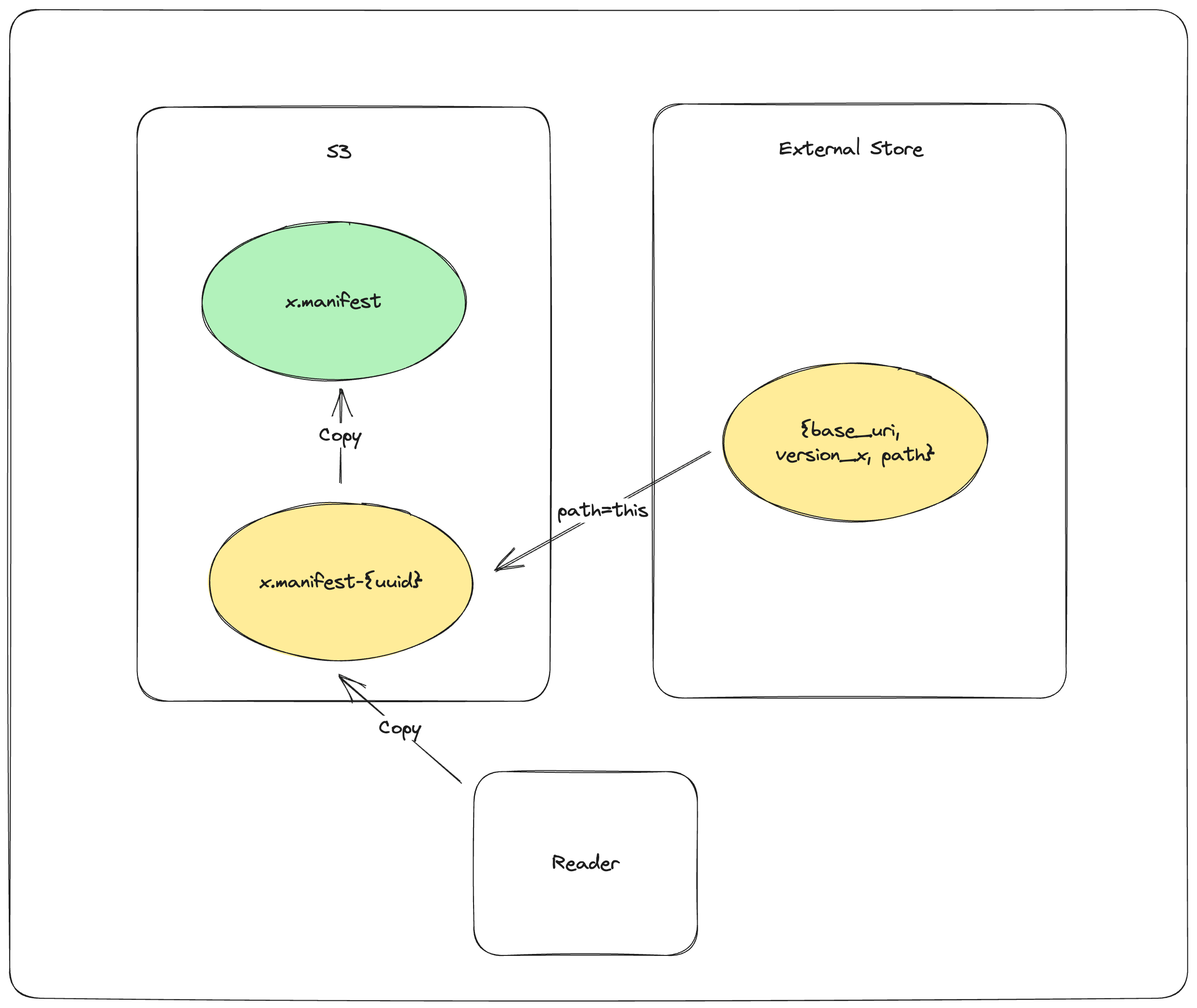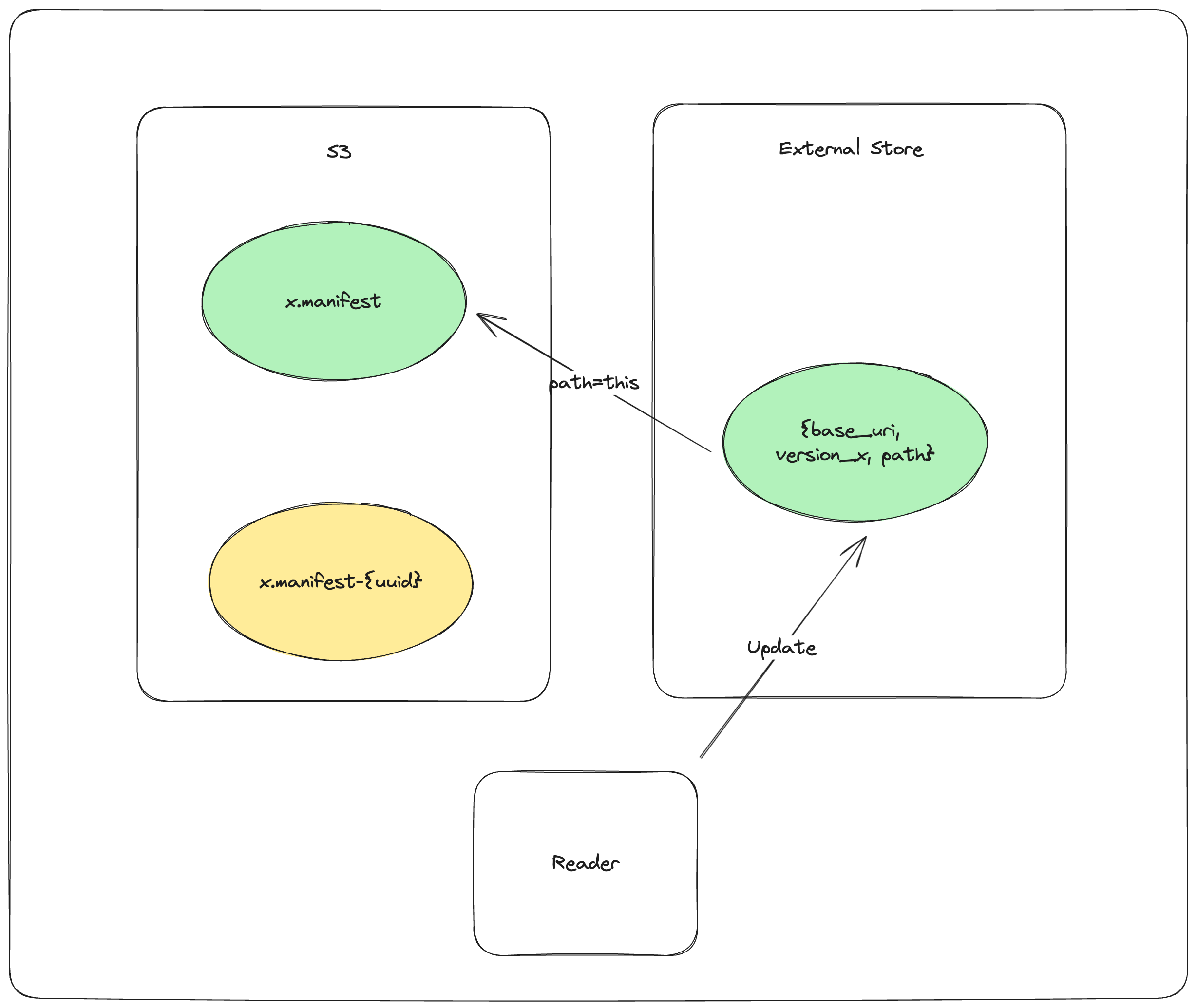
如果底层对象存储不支持*-if-not-exists操作,可以使用外部清单存储来支持并发写入。外部清单存储是一种支持put-if-not-exists操作的键值存储。外部清单存储是对对象存储中清单的补充而非替代。不了解外部清单存储的读取者仍然可以读取使用它的表,但可能会落后于表的真实最新版本最多一个版本。
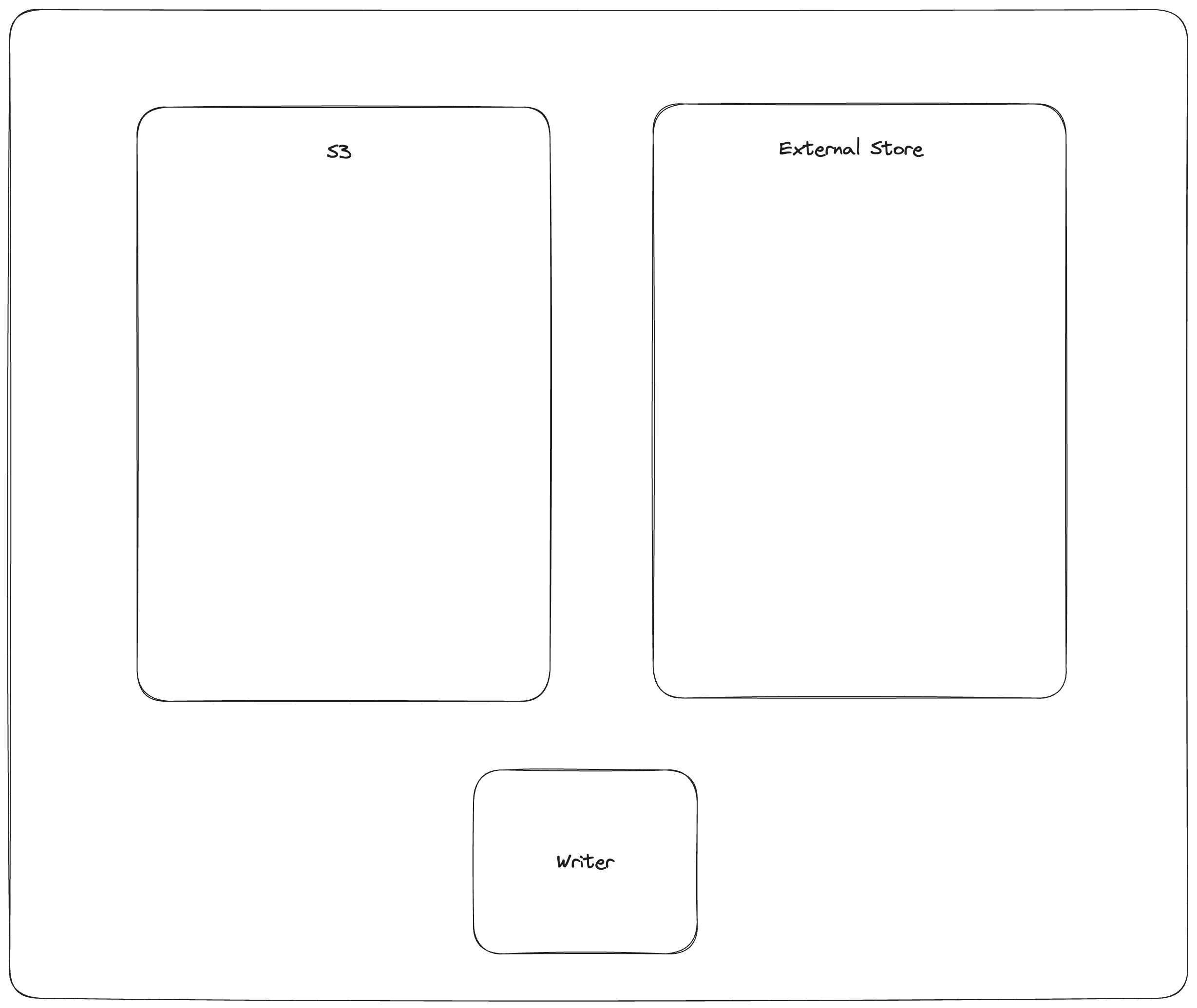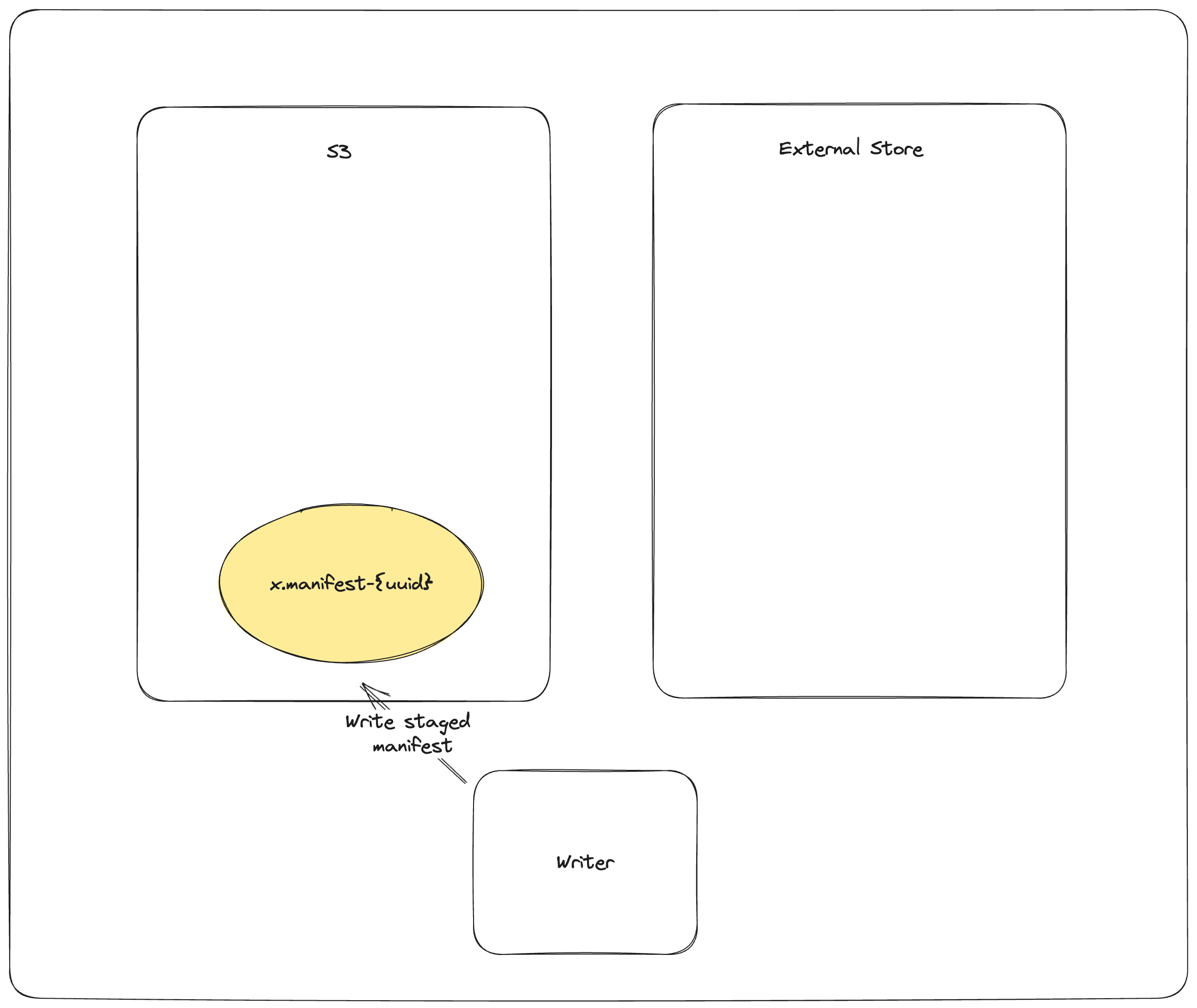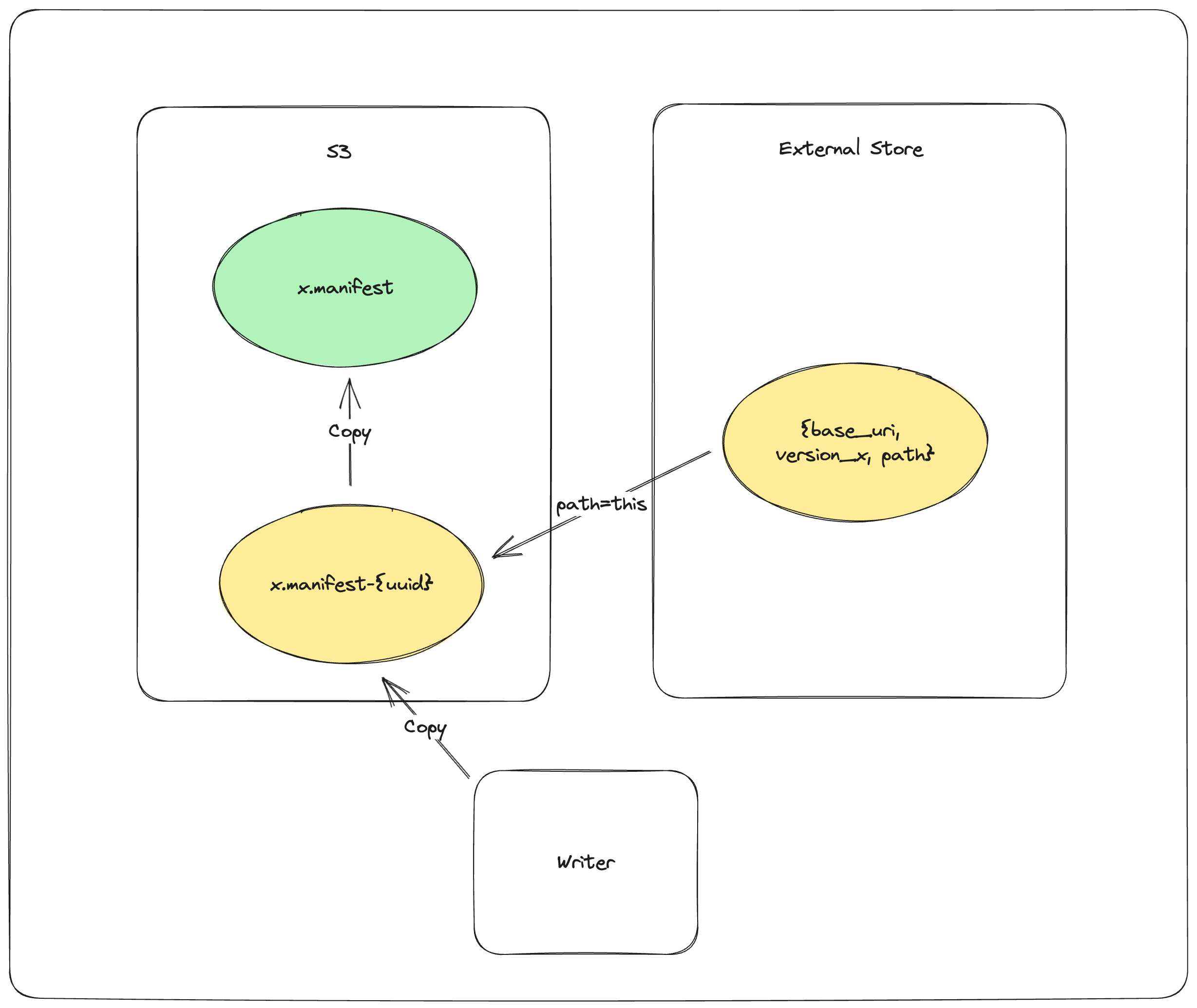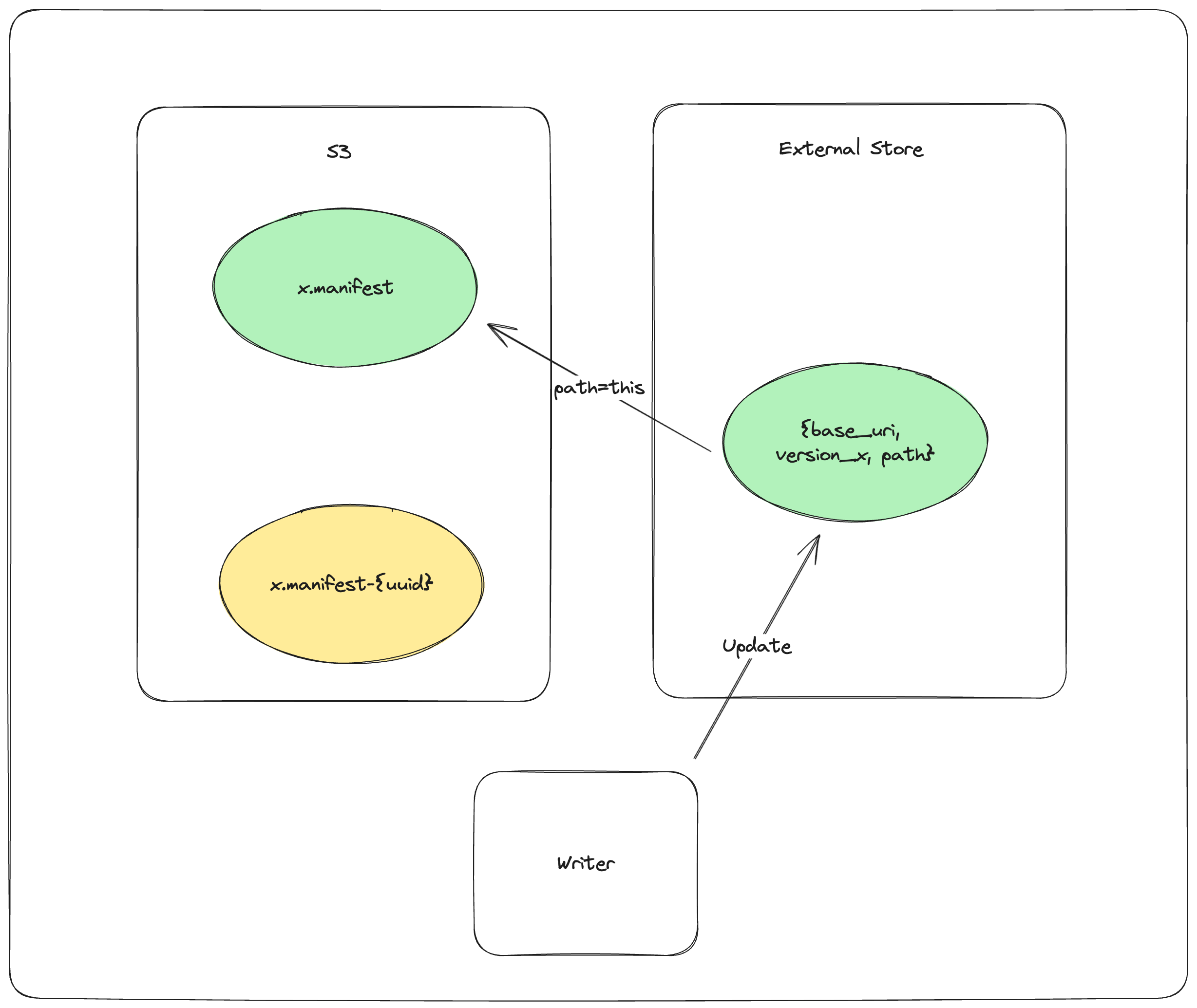
提交过程如下:
PUT_OBJECT_STORE mydataset.lance/_versions/{version}.manifest-{uuid} 在对象存储中暂存一个新的清单文件,路径由新生成的uuid唯一确定
PUT_EXTERNAL_STORE base_uri, version, mydataset.lance/_versions/{version}.manifest-{uuid} 将暂存清单的路径提交到外部存储。
COPY_OBJECT_STORE mydataset.lance/_versions/{version}.manifest-{uuid} mydataset.lance/_versions/{version}.manifest 将暂存的清单文件复制到最终路径
PUT_EXTERNAL_STORE base_uri, version, mydataset.lance/_versions/{version}.manifest 更新外部存储指向最终清单文件
请注意,提交操作实际上在第2步后就已完成。如果写入程序在第2步后失败,读取程序将能够检测到外部存储与对象存储不同步,并尝试同步这两个存储。如果同步重试失败,读取程序将拒绝加载。这是为了确保数据集始终具有可移植性,只需复制数据集目录而无需特殊工具。
读取器的加载流程如下:
GET_EXTERNAL_STORE base_uri, version, path 然后,如果路径不以UUID结尾,则返回该路径
COPY_OBJECT_STORE mydataset.lance/_versions/{version}.manifest-{uuid} mydataset.lance/_versions/{version}.manifest 重新尝试同步
PUT_EXTERNAL_STORE base_uri, version, mydataset.lance/_versions/{version}.manifest 更新外部存储指向最终清单文件
RETURN mydataset.lance/_versions/{version}.manifest 总是返回最终确定的路径,如果同步失败则返回错误
统计
统计信息存储在Lance文件中。这些统计信息可用于确定查询中可以跳过哪些页面。其中存储了空值计数、下界(最小值)和上界(最大值)。
统计信息本身以Lance的列式格式存储,这种格式允许选择性读取仅相关的统计列。
统计值
每列存储三种统计信息:空值计数、最小值、最大值。
最小值和最大值以其原生数据类型存储在数组中。
针对不同数据类型处理空值有特殊行为:
对于基于整数的数据类型(包括有符号和无符号整数、日期和时间戳),如果最小值和最大值未知(所有值均为空),则应使用可表示的最小/最大值代替。
对于浮点数据类型,如果最小值和最大值未知,则分别使用-Inf和+Inf。(如果数组中存在这些值,也可以使用-Inf和+Inf来表示最小值和最大值。)在计算最小值和最大值统计时,应忽略NaN值。如果最大值是零(负零或正零),则最大值应记录为+0.0。同样,如果最小值是零(正零或负零),则应记录为-0.0。
对于二进制数据类型,如果最小值或最大值未知或无法表示,则使用空值。二进制数据类型的边界也可以被截断。例如,一个仅包含值"abcd"的数组可以有一个截断后的最小值"abc"和最大值"abd"。如果没有比最大值更大的截断值,则改用空值作为最大值。
警告
min 和 max 值并不保证一定在数组中;它们只是上下界。有两种常见情况会导致这些值不在数组中:一是原始的最小值或最大值被删除,二是二进制数据被截断。因此,不应使用这些统计信息来计算类似 SELECT max(col) FROM table 这样的查询。
页面级统计格式
页面级统计信息以数组形式存储在Lance文件中。每个数组包含一个页面的长度,长度为num_pages。页面偏移量像数据页表一样存储在数组中。统计页表的偏移量存储在元数据中。
统计数据的模式如下:
<field_id_1>: struct
null_count: i64
min_value: <field_1_data_type>
max_value: <field_1_data_type>
...
<field_id_N>: struct
null_count: i64
min_value: <field_N_data_type>
max_value: <field_N_data_type>
任何数量的字段都可能缺失,因为某些字段或某些类型的统计信息可能会被跳过。此外,读者应预料到可能存在此模式中未包含的额外字段,这些字段应被忽略。未来对该格式的更改可能会添加更多字段,但这些更改将保持向后兼容。
然而,作者不应编写本文档中未描述的额外字段。在规范中明确定义之前,无法保证读者能够安全解析新形式的统计信息。
功能特性:稳定的行ID移动
行ID特性为表中的每一行分配一个唯一的u64 ID。该ID在移动后(例如在压缩过程中)保持稳定,但在行更新后不一定稳定。(未来功能可能会使其在更新后也保持稳定。)为了快速访问,创建了一个二级索引,将行ID映射到它们在表中的位置。这些索引的相应部分存储在各自片段的元数据中。
- row id
为表中的每一行分配的唯一自增u64 ID。
- row address
表中某行的当前位置。这是一个u64值,可以视为由两个u32值组成的对:片段ID和局部行偏移量。例如,如果行地址是(42, 9),则表示该行位于第42个片段中,并且是该片段中的第10行。
- row id sequence
片段中的行ID序列。
- row id index
一个将行ID映射到行地址的二级索引。该索引通过读取所有行ID序列构建而成。
分配行ID
行ID按单调递增的顺序分配。下一个行ID存储在清单中,字段为next_row_id,初始值为零。提交时,写入器会使用该字段为新片段分配行ID。如果提交失败,写入器将重新读取新的next_row_id,更新新的行ID,然后重试。这与使用max_fragment_id分配新片段ID的方式类似。
当一行数据被更新时,通常会分配一个新的行ID而不是重用旧的ID。这是因为该功能没有机制来更新可能引用旧行ID值的二级索引。通过删除旧行ID并创建新ID,二级索引将避免引用过时数据。
行ID序列
片段的行ID值存储在RowIdSequence protobuf消息中。这在protos/rowids.proto文件中有详细描述。行ID序列本质上只是u64值的数组,针对常见情况(当它们是有序且可能连续时)进行了优化存储。例如,一个新片段的行ID序列可能只是一个简单的范围,因此它被存储为start和end两个值。
这些序列消息要么直接存储在片段元数据中,要么写入单独的文件并通过片段元数据进行引用。这种选择通常基于序列的大小。如果序列较小,则直接内联存储;如果较大,则写入单独的文件。通过将小序列保持内联存储,我们可以避免额外IO操作的开销。
oneof row_id_sequence {
// If small (< 200KB), the row ids are stored inline.
bytes inline_row_ids = 5;
// Otherwise, stored as part of a file.
ExternalFile external_row_ids = 6;
} // row_id_sequence
行ID索引
为了确保通过行ID快速访问行数据,系统会创建一个二级索引,将行ID映射到它们在表中的位置。该索引在加载表时基于片段中的行ID序列构建。例如,如果片段42的行ID序列是[0, 63, 10],那么索引将包含条目0 -> (42, 0)、63 -> (42, 1)和10 -> (42, 2)。该索引的具体实现形式由开发者决定,但应优化以实现快速查找。