lmdeploy.pytorch的架构#
lmdeploy.pytorch 是 LMDeploy 中的一个推理引擎,它为有兴趣部署自己的模型和开发新功能的用户提供了一个开发者友好的框架。
设计#
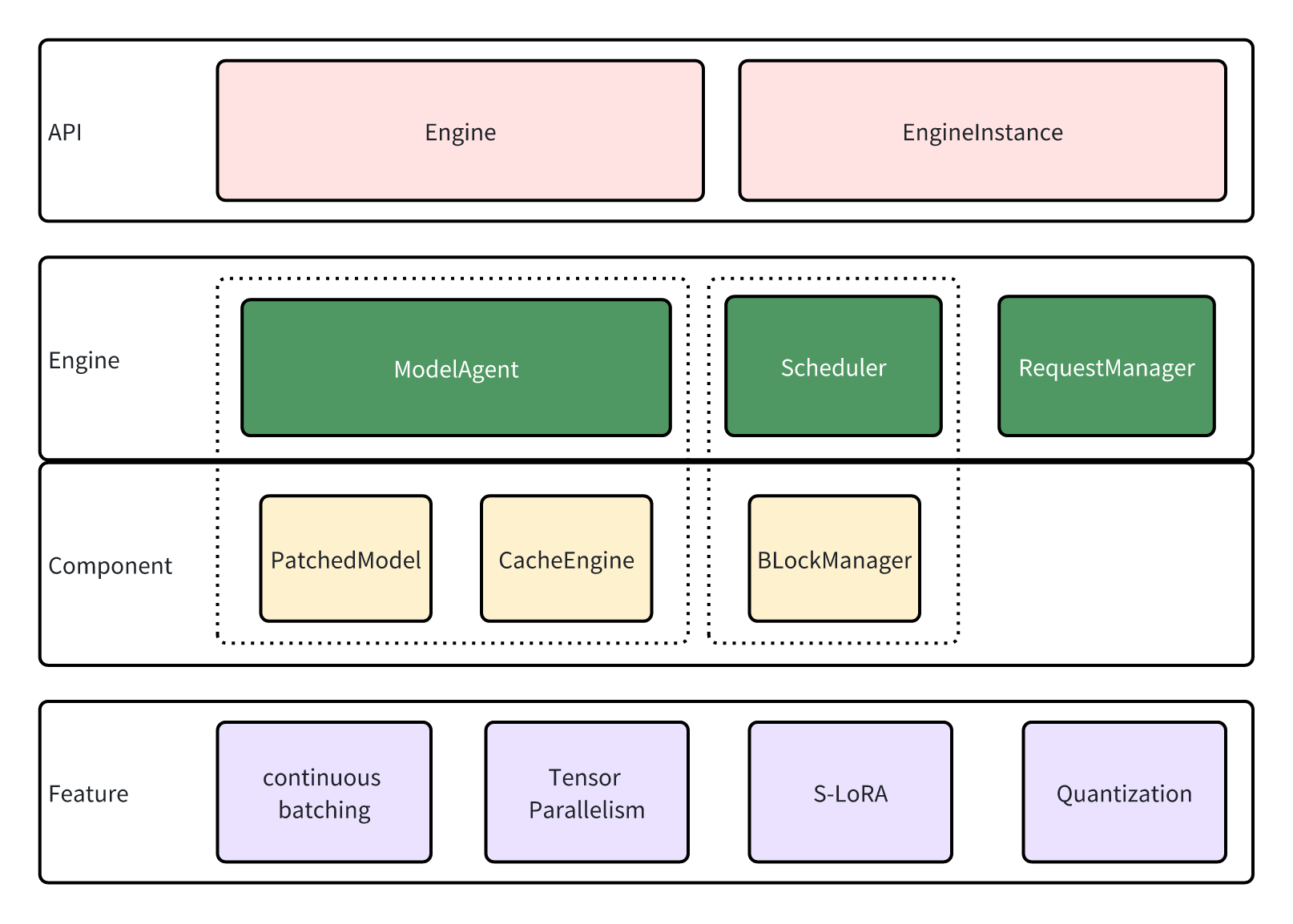
API#
lmdeploy.pytorch 与 Turbomind 共享服务接口,推理服务由 Engine 和 EngineInstance 实现。
EngineInstance 作为推理请求的发送者,封装并发送请求到 Engine 以实现流式推理。EngineInstance 的推理接口是线程安全的,允许不同线程中的实例同时发起请求。Engine 会根据当前系统资源自动进行批处理。
引擎是请求的接收者和执行者。它包含以下模块:
ModelAgent作为模型的包装器,处理诸如加载模型/适配器、管理缓存以及实现张量并行等任务。Scheduler作为序列管理器,确定参与当前步骤的序列和适配器,并随后为它们分配资源。RequestManager负责发送和接收请求,充当Engine和EngineInstance之间的桥梁。
引擎#
引擎在子线程中响应请求,遵循以下循环序列:
通过
RequestManager获取新的请求。这些请求目前已被缓存。Scheduler执行调度,决定哪些缓存的请求应该被处理,并为它们分配资源。ModelAgent根据Scheduler提供的信息交换缓存,然后使用修补后的模型进行推理。Scheduler根据ModelAgent的推理结果更新请求的状态。RequestManager响应发送者 (EngineInstance),然后流程返回到步骤1。
现在,让我们更深入地探讨参与这些步骤的模块。
调度器#
在LLM推理中,缓存历史键和值状态是一种常见的做法,以防止冗余计算。然而,由于一批序列中的历史长度不同,我们需要对缓存进行填充以实现批量推理。不幸的是,这种填充可能会导致显著的内存浪费,从而限制变压器的性能。
vLLM 采用基于分页的策略,以页面块为单位分配缓存,以最小化额外的内存使用。我们的引擎中的调度器模块采用了类似的设计,基于序列长度以块为单位分配资源,并驱逐未使用的块,以支持更大的批处理和更长的会话长度。
此外,我们支持S-LoRA,它可以在有限的内存上使用多个LoRA适配器。
模型代理#
lmdeploy.pytorch 支持张量并行,这导致了复杂的模型初始化、缓存分配和权重分区。ModelAgent 旨在抽象这些复杂性,使引擎能够专注于维护管道。
ModelAgent由两个组件组成:
`patched_model: : 这是修补后的变压器模型。与原始模型相比,修补后的模型包含了额外的功能,如张量并行、量化和高性能内核。
cache_engine: 该组件负责管理缓存。它接收来自调度器的命令并执行主机-设备页面交换。仅使用GPU块来缓存键/值对和适配器。
功能#
lmdeploy.pytorch 支持的新功能包括:
连续批处理:由于批次中的序列长度可能不同,通常需要对推理进行填充。然而,大量的填充会导致额外的内存使用和不必要的计算。为了解决这个问题,我们采用了连续批处理,将所有序列连接成一个长序列,以避免填充。
张量并行: 大型语言模型(LLM)的GPU内存使用量可能会超过单个GPU的容量。张量并行用于在多个设备上容纳此类模型。每个设备同时处理模型的一部分,并收集结果以确保正确性。
S-LoRA: LoRA适配器可以用于在内存有限的设备上训练LLM。虽然在部署前将适配器合并到模型权重中是常见的做法,但以这种方式加载多个适配器可能会消耗大量内存。我们支持S-LoRA,其中适配器在需要时分页和交换。开发了特殊的内核来支持未合并适配器的推理,从而能够高效地加载各种适配器。
量化: 模型量化涉及使用低精度进行计算。
lmdeploy.pytorch支持 w8a8 量化。更多详情,请参阅 w8a8。