
在modelx中使用pandas#
pandas 是一个用于数据操作和分析的热门Python包。 它提供了多功能的数据结构,例如DataFrame和Series, 用于存储表格和向量数据。
将pandas对象保存为Excel或CSV文件#
默认情况下,modelx将pandas对象与其他可pickle的数据同等对待,这意味着它们会与其他对象一起被pickled并保存在二进制数据文件中。
除了这种默认行为外, modelx还实现了一项功能,可以针对pandas的DataFrame和Series改变这种默认行为,并将它们保存为Excel和CSV文件。
让我们看看这是如何工作的。
下面的脚本创建了一个示例数据框 df:
>>> import pandas as pd
>>> index = pd.date_range("20210101", periods=3)
>>> df = pd.DataFrame(np.random.randn(3, 3), index=index, columns=list("XYZ"))
>>> df
X Y Z
2021-01-01 0.184497 0.140037 -1.599499
2021-01-02 -1.029170 0.588080 0.081129
2021-01-03 0.028450 -0.490102 0.025208
我们同样在模型中创建一个示例模型和一个示例空间,并将该空间分配给space:
>>> import modelx as mx
>>> model = mx.new_model() # Creates a new model Model1
>>> space = model.new_space() # Creates a new space Space1
要将示例DataFrame分配给空间中的x,我们通常会这样做:
>>> space.x = df
通过保存模型,df将被存储在模型目录下_data文件夹中名为data.pickle的二进制文件里。
要将DataFrame保存到Excel文件中,而不是上面的赋值操作,
new_pandas() 应该这样使用:
>>> space.new_pandas("x", "Space1/df.xlsx", data=df, file_type="excel", sheet="df1")
上述代码不仅将df赋值给space中的x,
还为df关联了元数据以便将其保存为Excel文件,
例如文件路径、文件类型和工作表名称。
以下代码将模型保存到当前目录下名为model的文件夹中:
>>> model.write("model")
我们应该在model/Space1目录下找到一个名为df.xlsx的Excel文件。
该文件在df1工作表上包含一个df表格。
元数据与df关联为PandasData对象。
我们可以通过调用模型的get_spec()方法来检查元数据:
>>> model.get_spec(df)
<PandasData path='Space1/df.xlsx' file_type='excel' sheet='df1'>
请注意,元数据是与df这个DataFrame对象关联的,
而不是与x关联,因为df可以被赋值给其他名称。
我们可以通过new_pandas()将df赋值给x后,
再将df赋值给比如y。
这次我们不需要使用new_pandas(),
而可以直接使用赋值操作,因为
元数据已经被赋给df了:
>>> space.y = df
该图展示了x、y、df与PandasData对象之间的关系。
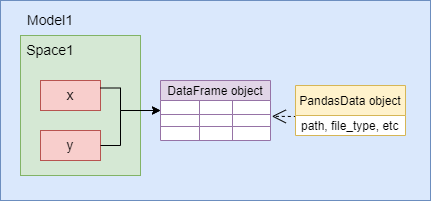
x和y都指向同一个DataFrame对象,
包含元数据的PandasData对象是与DataFrame对象相关联的,
而不是与x或y相关联。
替换pandas对象#
假设我们想用一个新对象替换DataFrame对象,这个新对象在全局命名空间中名为df2。
如果我们简单地将df2赋值给x:
>>> space.x = df2
然后发生的事情如下所示:
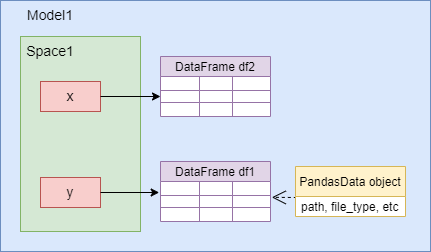
如果我们随后通过以下方式将 df2 赋值给 y:
>>> space.y = df2
那么 x 和 y 都指向 df,但 PandasData 对象将会消失。
为了保留PandasData并将其关联到df2,
我们应该使用update_pandas()
而不是赋值操作:
>>> model.update_pandas(df, df2)
然后 df 被替换为 df2,而 PandasData 对象
被保留并与 df2 关联:
>>> space.x is df2
True
>>> space.y is df2
True
>>> model.get_spec(df2)
<PandasData path='Space1/df.xlsx' file_type='excel' sheet='df1'>
df2 现在已通过 write() 保存到 Excel 文件中。
更新pandas对象#
pandas的DataFrame和Series是可变对象。
我们可以原地修改它们的值。
modelx无法检测可变对象值的变更,
因此如果我们修改了DataFrame或Series的值,需要通过调用
update_pandas()来通知modelx这一变更,
以清除依赖该对象的单元格缓存值。
让我们通过示例看看这是如何工作的:
>>> import modelx as mx
>>> import pandas as pd
>>> model = mx.new_model() # Creates a new model Model1
>>> space = model.new_space() # Creates a new space Space1
>>> df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
>>> df
col1 col2
0 1 3
1 2 4
>>> space.x = df # Use new_pandas instead to save df to a file.
>>> @mx.defcells
... def foo():
... return x['col1'][0]
>>> foo()
1
foo 从 df 返回并缓存一个值,该值被赋给 x。
现在,让我们修改 df 中的值:
>>> df['col1'][0] = 5
>>> space.x
col1 col2
0 5 3
1 2 4
>>> foo()
1
foo 不会反映变更。我们需要显式调用 update_pandas() 并传入 df:
>>> model.update_pandas(df) # Tell modelx df is updated.
>>> foo() # The value is retrieved from x again.
5