使用从提示流部署的流式端点#
在提示流中,你可以将流部署为REST端点以进行实时推理。
当通过发送请求来使用端点时,默认行为是在线端点将一直等待,直到整个响应准备就绪,然后将其发送回客户端。这可能会导致客户端长时间延迟和用户体验不佳。
为了避免这种情况,您可以在使用端点时使用流式传输。一旦启用流式传输,您就不必等待整个响应准备就绪。相反,服务器将按生成的块发送响应。客户端可以逐步显示响应,减少等待时间并增加交互性。
本文将描述流式传输的范围、流式传输的工作原理以及如何消费流式传输端点。
创建一个支持流式处理的流程#
如果你想使用流模式,你需要创建一个流程,该流程有一个节点可以生成字符串生成器作为流程的输出。字符串生成器是一个对象,当被请求时可以一次返回一个字符串。你可以使用以下类型的节点来创建字符串生成器:
LLM节点:该节点使用大型语言模型根据输入生成自然语言响应。
{# LLM节点的示例提示模板 #} # 系统: 你是一个有用的助手。 # 用户: {{question}}
Python工具节点:此节点允许您编写可以生成字符串输出的自定义Python代码。您可以使用此节点调用支持流式传输的外部API或库。例如,您可以使用此代码逐字回显输入:
from promptflow.core import tool # 示例代码在Python工具节点中通过yield回显输入 @tool def my_python_tool(paragraph: str) -> str: yield "Echo: " for word in paragraph.split(): yield word + " "
在本指南中,我们将使用“与维基百科聊天”示例流程作为例子。该流程处理用户的问题,搜索维基百科以找到相关文章,并使用文章中的信息回答问题。它使用流模式来显示答案生成的进度。
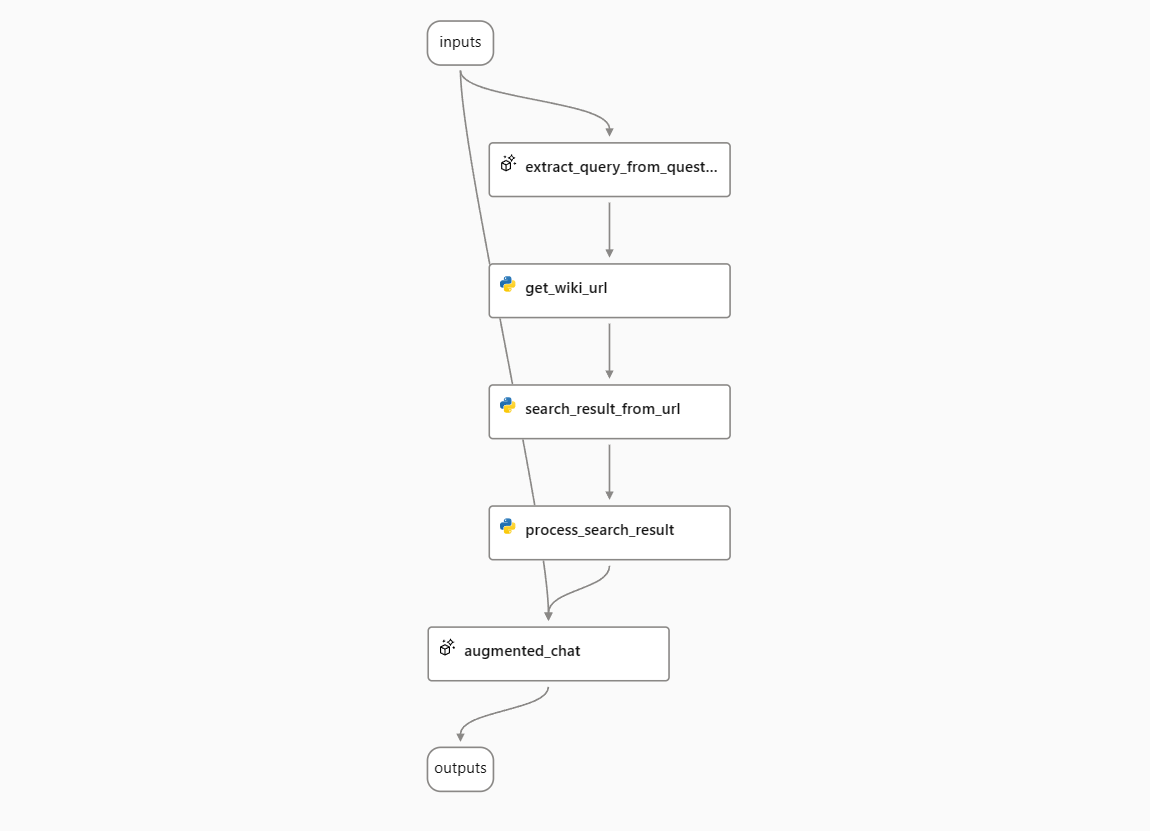
将流程部署为在线端点#
要使用流模式,您需要将您的流程部署为在线端点。这将允许您实时发送请求并从您的流程接收响应。
按照本指南将您的流程部署为在线端点。
[!注意]
您可以按照本文档部署一个在线端点。 请使用运行时环境版本高于
20230816.v10的版本进行部署。 您可以在运行时详细信息页面检查并更新您的运行时版本。
了解流处理过程#
当你有一个在线端点时,客户端和服务器需要遵循特定的原则进行内容协商以利用流模式:
内容协商就像是客户端和服务器之间关于他们想要发送和接收的数据的首选格式的对话。它确保了有效沟通并就交换数据的格式达成一致。
要理解流处理过程,请考虑以下步骤:
首先,客户端构建一个HTTP请求,其中包含在
Accept头中指定的所需媒体类型。媒体类型告诉服务器客户端期望的数据格式。这就像是客户端在说:“嘿,我正在寻找你将要发送给我的数据的特定格式。可能是JSON、文本或其他格式。”例如,application/json表示偏好JSON数据,text/event-stream表示希望获取流数据,而*/*表示客户端接受任何数据格式。[!注意]
如果请求缺少
Accept头或Accept头为空,这意味着客户端将接受任何媒体类型的响应。服务器会将其视为*/*。接下来,服务器根据
Accept头中指定的媒体类型进行响应。需要注意的是,客户端可能在Accept头中请求多种媒体类型,服务器必须考虑其能力和格式优先级来确定适当的响应。首先,服务器检查
Accept头中是否明确指定了text/event-stream:对于支持流的流程,服务器返回一个
Content-Type为text/event-stream的响应,表示数据正在流式传输。对于不支持流的流程,服务器继续检查头中指定的其他媒体类型。
如果未指定
text/event-stream,服务器则检查Accept头中是否指定了application/json或*/*:在这种情况下,服务器返回一个
Content-Type为application/json的响应,以JSON格式提供数据。
如果
Accept头指定了其他媒体类型,例如text/html:服务器返回一个
424响应,带有PromptFlow运行时错误代码UserError和运行时HTTP状态406,表示服务器无法以请求的数据格式满足请求。
注意:详情请参阅处理错误。
最后,客户端检查
Content-Type响应头。如果它被设置为text/event-stream,则表示数据正在被流式传输。
让我们更详细地看一下流式处理过程是如何工作的。流式模式下的响应数据遵循服务器发送事件(SSE)的格式。
整体流程如下:
0. 客户端向服务器发送消息。#
POST https://<your-endpoint>.inference.ml.azure.com/score
Content-Type: application/json
Authorization: Bearer <key or token of your endpoint>
Accept: text/event-stream
{
"question": "Hello",
"chat_history": []
}
[!注意]
Accept标头设置为text/event-stream以请求流响应。
1. 服务器以流模式发送回响应。#
HTTP/1.1 200 OK
Content-Type: text/event-stream; charset=utf-8
Connection: close
Transfer-Encoding: chunked
data: {"answer": ""}
data: {"answer": "Hello"}
data: {"answer": "!"}
data: {"answer": " How"}
data: {"answer": " can"}
data: {"answer": " I"}
data: {"answer": " assist"}
data: {"answer": " you"}
data: {"answer": " today"}
data: {"answer": " ?"}
data: {"answer": ""}
请注意,Content-Type 被设置为 text/event-stream; charset=utf-8,表示响应是一个事件流。
客户端应将响应数据解码为服务器发送的事件,并逐步显示它们。服务器将在所有数据发送完毕后关闭HTTP连接。
每个响应事件都是相对于前一个事件的增量。建议客户端在内存中跟踪合并的数据,并在下一个请求中将其作为聊天历史发送回服务器。
2. 客户端向服务器发送另一条聊天消息,以及完整的聊天历史记录。#
POST https://<your-endpoint>.inference.ml.azure.com/score
Content-Type: application/json
Authorization: Bearer <key or token of your endpoint>
Accept: text/event-stream
{
"question": "Glad to know you!",
"chat_history": [
{
"inputs": {
"question": "Hello"
},
"outputs": {
"answer": "Hello! How can I assist you today?"
}
}
]
}
3. 服务器以流模式发送回答案。#
HTTP/1.1 200 OK
Content-Type: text/event-stream; charset=utf-8
Connection: close
Transfer-Encoding: chunked
data: {"answer": ""}
data: {"answer": "Nice"}
data: {"answer": " to"}
data: {"answer": " know"}
data: {"answer": " you"}
data: {"answer": " too"}
data: {"answer": "!"}
data: {"answer": " Is"}
data: {"answer": " there"}
data: {"answer": " anything"}
data: {"answer": " I"}
data: {"answer": " can"}
data: {"answer": " help"}
data: {"answer": " you"}
data: {"answer": " with"}
data: {"answer": "?"}
data: {"answer": ""}
4. 聊天以类似的方式继续。#
处理错误#
客户端应首先检查HTTP响应代码。有关在线端点返回的常见错误代码,请参见此表。
如果响应代码是“424 模型错误”,这意味着错误是由模型的代码引起的。来自 PromptFlow 模型的错误响应始终遵循以下格式:
{
"error": {
"code": "UserError",
"message": "Media type text/event-stream in Accept header is not acceptable. Supported media type(s) - application/json",
}
}
它始终是一个仅定义了一个键“error”的JSON字典。
“error”的值是一个字典,包含“code”和“message”。
“code” 定义了错误类别。目前,它可能是“UserError”表示用户输入错误,以及“SystemError”表示服务内部错误。
“message” 是对错误的描述。它可以显示给最终用户。
如何使用服务器发送的事件#
使用Python消费#
在这个示例用法中,我们使用了SSEClient类。这个类不是Python内置的类,需要单独安装。你可以通过pip安装它:
pip install sseclient-py
一个示例用法如下:
import requests
from sseclient import SSEClient
from requests.exceptions import HTTPError
try:
response = requests.post(url, json=body, headers=headers, stream=stream)
response.raise_for_status()
content_type = response.headers.get('Content-Type')
if "text/event-stream" in content_type:
client = SSEClient(response)
for event in client.events():
# Handle event, i.e. print to stdout
else:
# Handle json response
except HTTPError:
# Handle exceptions
使用JavaScript消费#
在JavaScript中有几个库可以用来消费服务器发送的事件。这里有一个作为示例。
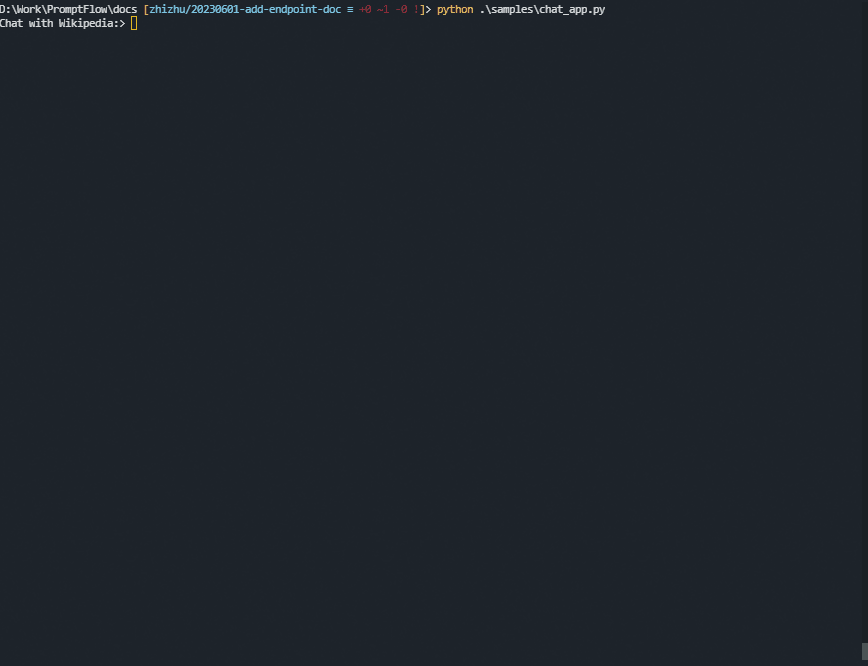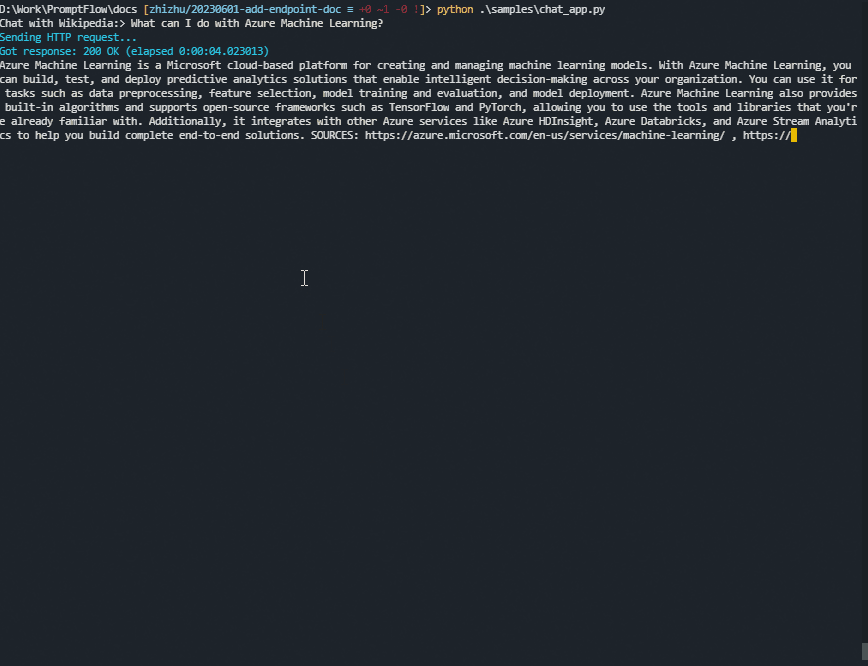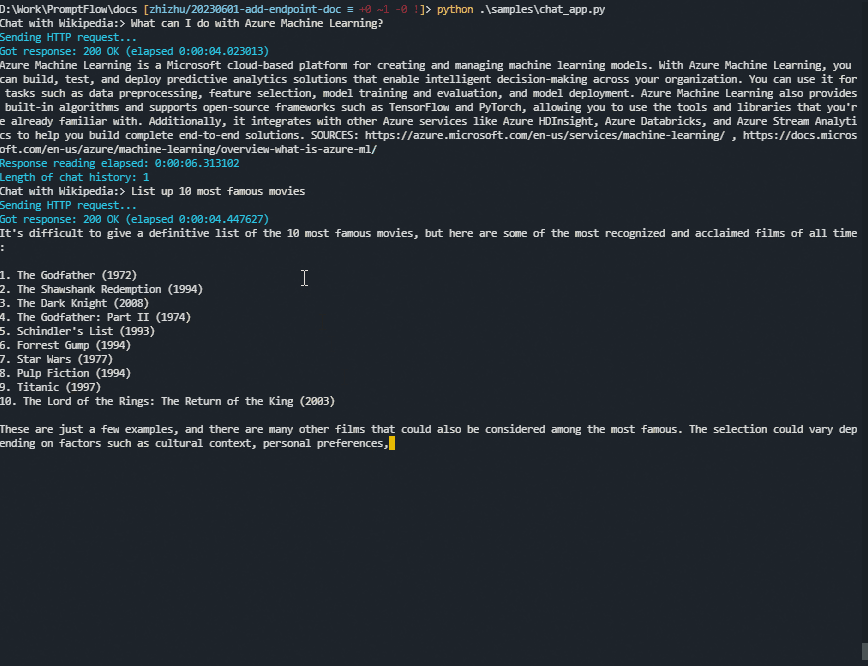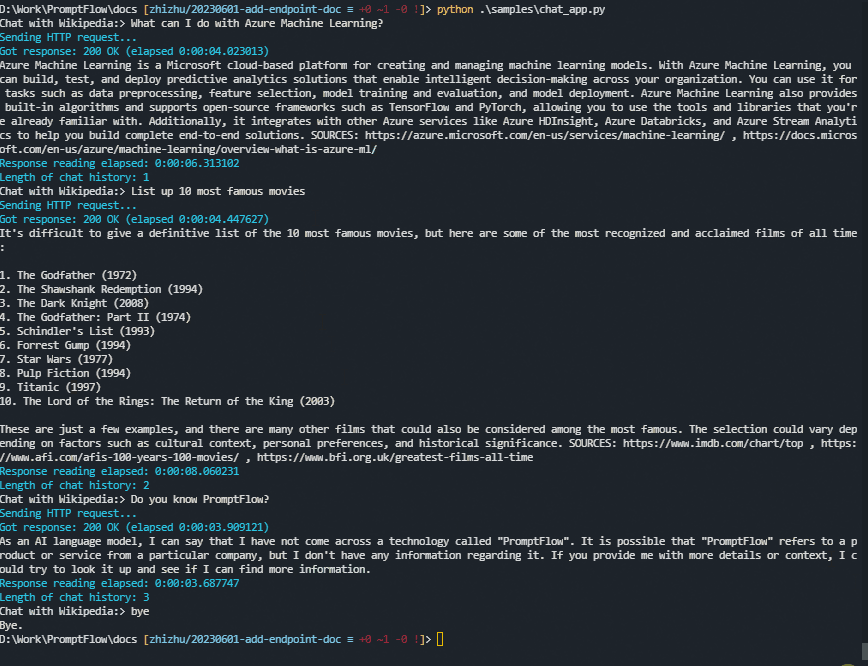
一个使用Python的示例聊天应用#
这是一个用Python编写的示例聊天应用程序。 (点击这里查看源代码。)
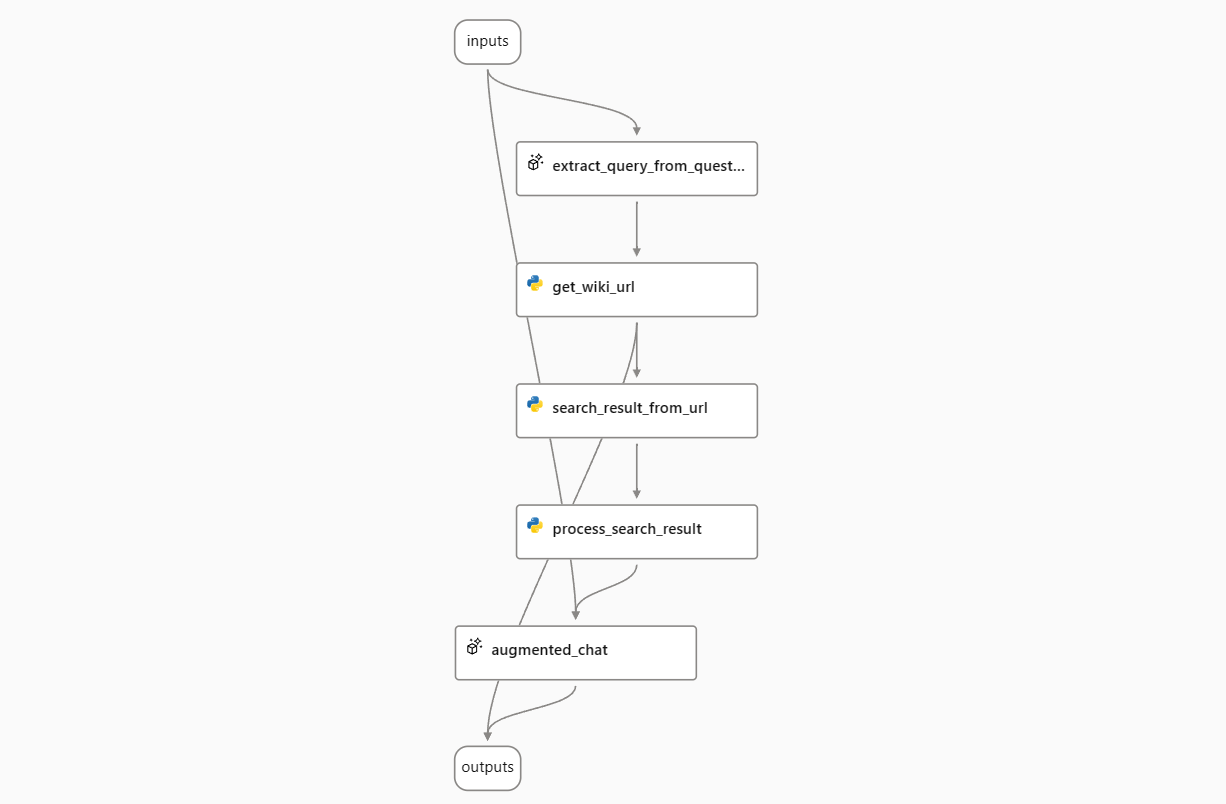
高级用法 - 混合流和非流输出#
有时,您可能希望从流程输出中获取流式和非流式结果。例如,在“与维基百科聊天”流程中,您可能不仅希望获取LLM的答案,还希望获取流程搜索的URL列表。为此,您需要修改流程以输出流式LLM答案和非流式URL列表的组合。
在示例“与维基百科聊天”流程中,输出连接到LLM节点augmented_chat。要将URL列表添加到输出中,您需要添加一个名为url的输出字段,其值为${get_wiki_url.output}。
流程的输出将是一个非流字段作为基础和一个流字段作为增量。以下是请求和响应的示例。
0. 客户端向服务器发送消息。#
POST https://<your-endpoint>.inference.ml.azure.com/score
Content-Type: application/json
Authorization: Bearer <key or token of your endpoint>
Accept: text/event-stream
{
"question": "When was ChatGPT launched?",
"chat_history": []
}
1. 服务器以流模式发送回答案。#
HTTP/1.1 200 OK
Content-Type: text/event-stream; charset=utf-8
Connection: close
Transfer-Encoding: chunked
data: {"url": ["https://en.wikipedia.org/w/index.php?search=ChatGPT", "https://en.wikipedia.org/w/index.php?search=GPT-4"]}
data: {"answer": ""}
data: {"answer": "Chat"}
data: {"answer": "G"}
data: {"answer": "PT"}
data: {"answer": " was"}
data: {"answer": " launched"}
data: {"answer": " on"}
data: {"answer": " November"}
data: {"answer": " "}
data: {"answer": "30"}
data: {"answer": ","}
data: {"answer": " "}
data: {"answer": "202"}
data: {"answer": "2"}
data: {"answer": "."}
data: {"answer": " \n\n"}
...
data: {"answer": "PT"}
data: {"answer": ""}
2. 客户端向服务器发送另一条聊天消息,以及完整的聊天历史记录。#
POST https://<your-endpoint>.inference.ml.azure.com/score
Content-Type: application/json
Authorization: Bearer <key or token of your endpoint>
Accept: text/event-stream
{
"question": "When did OpenAI announce GPT-4? How long is it between these two milestones?",
"chat_history": [
{
"inputs": {
"question": "When was ChatGPT launched?"
},
"outputs": {
"url": [
"https://en.wikipedia.org/w/index.php?search=ChatGPT",
"https://en.wikipedia.org/w/index.php?search=GPT-4"
],
"answer": "ChatGPT was launched on November 30, 2022. \n\nSOURCES: https://en.wikipedia.org/w/index.php?search=ChatGPT"
}
}
]
}
3. 服务器以流模式发送回答案。#
HTTP/1.1 200 OK
Content-Type: text/event-stream; charset=utf-8
Connection: close
Transfer-Encoding: chunked
data: {"url": ["https://en.wikipedia.org/w/index.php?search=Generative pre-trained transformer ", "https://en.wikipedia.org/w/index.php?search=Microsoft "]}
data: {"answer": ""}
data: {"answer": "Open"}
data: {"answer": "AI"}
data: {"answer": " released"}
data: {"answer": " G"}
data: {"answer": "PT"}
data: {"answer": "-"}
data: {"answer": "4"}
data: {"answer": " in"}
data: {"answer": " March"}
data: {"answer": " "}
data: {"answer": "202"}
data: {"answer": "3"}
data: {"answer": "."}
data: {"answer": " Chat"}
data: {"answer": "G"}
data: {"answer": "PT"}
data: {"answer": " was"}
data: {"answer": " launched"}
data: {"answer": " on"}
data: {"answer": " November"}
data: {"answer": " "}
data: {"answer": "30"}
data: {"answer": ","}
data: {"answer": " "}
data: {"answer": "202"}
data: {"answer": "2"}
data: {"answer": "."}
data: {"answer": " The"}
data: {"answer": " time"}
data: {"answer": " between"}
data: {"answer": " these"}
data: {"answer": " two"}
data: {"answer": " milestones"}
data: {"answer": " is"}
data: {"answer": " approximately"}
data: {"answer": " "}
data: {"answer": "3"}
data: {"answer": " months"}
data: {"answer": ".\n\n"}
...
data: {"answer": "Chat"}
data: {"answer": "G"}
data: {"answer": "PT"}
data: {"answer": ""}