常见问题解答 (FAQ)#
通用#
稳定版 vs 实验版#
Prompt flow 在同一个 SDK 中提供了稳定和实验性的功能。
功能状态 |
描述 |
|---|---|
稳定功能 |
生产就绪 |
实验性功能 |
开发中 |
OpenAI 1.x 支持#
请使用以下命令升级promptflow以支持openai 1.x:
pip install promptflow>=1.1.0
pip install promptflow-tools>=1.0.0
请注意,上述命令将升级您的openai包至1.0.0之后的版本,这可能会对自定义工具代码引入破坏性更改。
请参阅OpenAI迁移指南以获取更多详细信息。
Promptflow 1.8.0 升级指南#
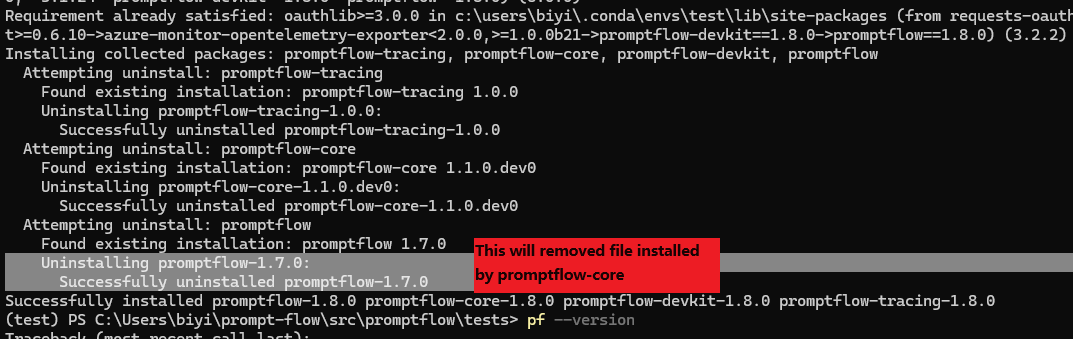
在升级到 promptflow 版本 1.8.0 或更高版本之前,首先卸载任何现有的 promptflow 及其子包的安装非常重要。 这确保了新版本的干净安装,没有任何冲突。
pip uninstall -y promptflow promptflow-core promptflow-devkit promptflow-azure # uninstall promptflow and its sub-packages
pip install 'promptflow>=1.8.0' # install promptflow version 1.8.0 or later
‘pip install promptflow>=1.8.0’ 或 ‘pf upgrade’ 直接不起作用的原因:
promptflow 包已被拆分为多个包。安装 promptflow 时,您将获得以下包:
promptflow:promptflow-tracing: promptflow的追踪功能。promptflow-core: 运行流程的核心功能。promptflow-devkit: promptflow的开发工具包。promptflow-azure: promptflow与Azure集成所需的额外依赖(promptflow[azure])。
当从现有版本升级到promptflow 1.8.0时,pip会在安装promptflow子包后移除旧的promptflow,这导致子包文件被错误地移除。
故障排除#
连接创建失败,错误为StoreConnectionEncryptionKeyError#
Connection creation failed with StoreConnectionEncryptionKeyError: System keyring backend service not found in your operating system. See https://pypi.org/project/keyring/ to install requirement for different operating system, or 'pip install keyrings.alt' to use the third-party backend.
此错误是由于keyring无法找到可用的后端来存储密钥。 例如 macOS Keychain 和 Windows Credential Locker 是有效的keyring后端。
要解决此问题,请安装第三方密钥环后端或编写您自己的密钥环后端,例如:
pip install keyrings.alt
有关keyring第三方后端的更多详细信息,请参阅keyring中的“第三方后端”。
Pf 可视化显示错误:“tcgetpgrp 失败:不是一个 tty”#
如果您正在使用WSL,这是WSL下webbrowser的一个已知问题;更多信息请参见此问题。请尝试将您的WSL升级到22.04或更高版本,此问题应该会得到解决。
如果您在使用WSL 22.04或更高版本时仍然遇到此问题,或者您甚至没有使用WSL,请向我们提交一个问题。
已安装的工具未出现在VSCode扩展工具列表中#
通过pip install [tool-package-name]安装工具包后,新工具可能不会立即出现在VSCode扩展中的工具列表中,如下所示:
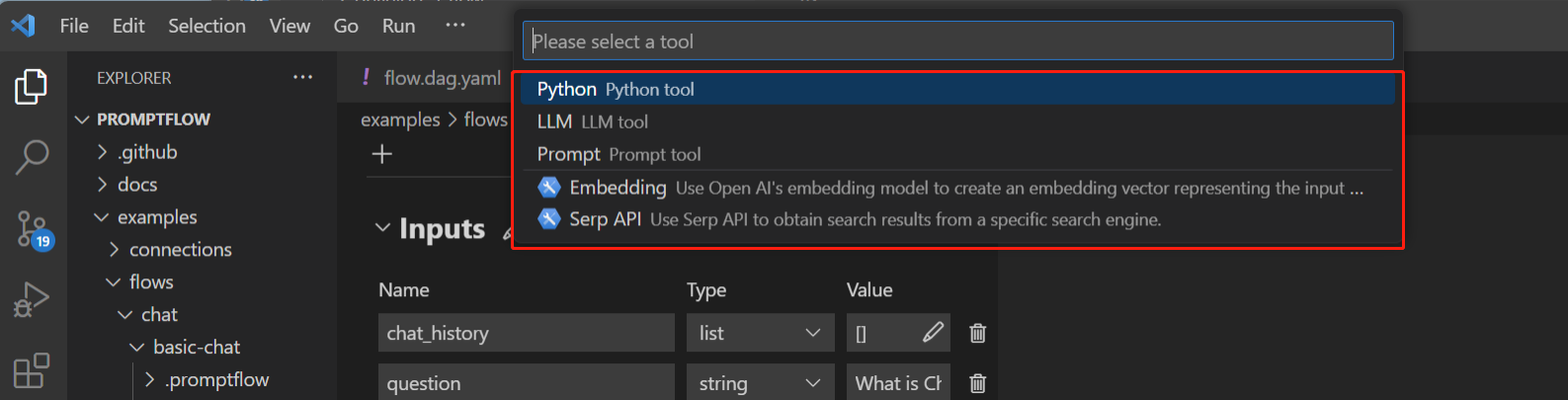
这通常是由于缓存过时。要刷新工具列表并使新安装的工具可见:
打开VSCode扩展窗口。
通过按下“Ctrl+Shift+P”来调出命令面板。
输入并选择“开发者:重新加载Web视图”命令。
请稍等,工具列表正在刷新。
重新加载会清除之前的缓存,并用任何新安装的工具填充工具列表。这样,缺失的工具现在就可以看到了。
设置日志级别#
Promptflow 使用 logging 模块来记录日志消息。您可以通过环境变量 PF_LOGGING_LEVEL 设置日志级别,有效值包括 CRITICAL, ERROR, WARNING, INFO, DEBUG,默认为 INFO。
以下是将 PF_LOGGING_LEVEL 设置为 DEBUG 后的服务日志:
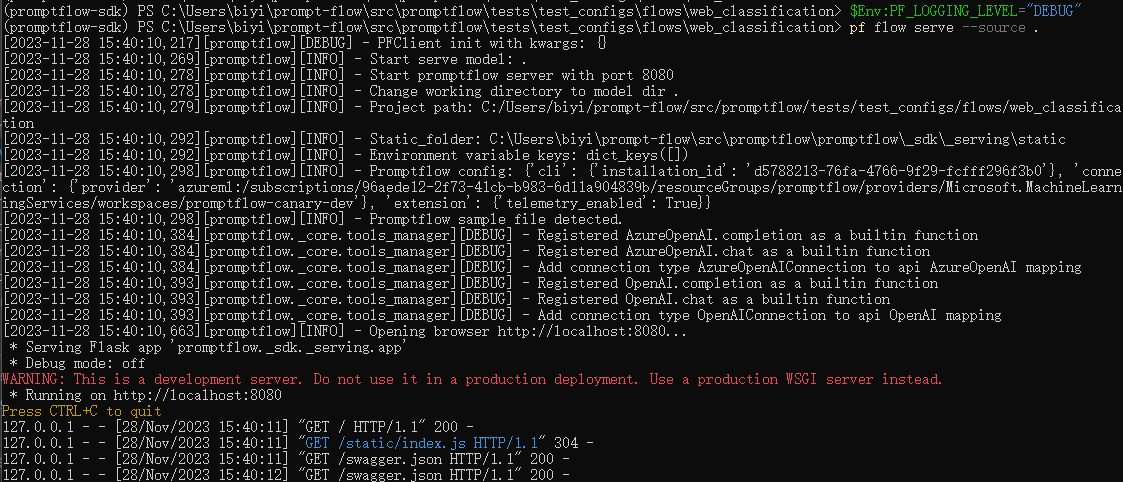
与服务日志中的WARNING级别进行比较:

设置日志格式#
Promptflow 默认使用以下日志格式和日期时间格式:
日志格式:
%(asctime)s %(process)7d %(name)-18s %(levelname)-8s %(message)s日期时间格式:
%Y-%m-%d %H:%M:%S %z
您可以使用PF_LOG_FORMAT环境变量自定义日志格式,并使用PF_LOG_DATETIME_FORMAT自定义日期时间格式。这些变量也可以在流程yaml文件中定义或直接在环境中设置。
设置环境变量#
目前,promptflow 支持以下环境变量:
PF_WORKER_COUNT
仅对批量运行有效,批量运行执行中的并行工作线程数。
默认值为4(在promptflow<1.4.0时为16)
在更改时请考虑以下几点:
并发数不应超过总数据行数。否则,由于进程启动和关闭所花费的额外时间,执行速度可能会减慢。
高并行性可能导致底层API调用达到您的LLM端点的速率限制。在这种情况下,您可以减少
PF_WORKER_COUNT或增加速率限制。请参考此文档关于配额管理。然后您可以参考此表达式来设置并发。
PF_WORKER_COUNT <= TPM * duration_seconds / token_count / 60
TPM: 每分钟令牌数,您的LLM端点的容量速率限制
duration_seconds: 单个流程运行的持续时间,以秒为单位
token_count: 单次流程运行的令牌计数
例如,如果您的端点TPM(每分钟令牌数)为50K,单个流程运行需要10k令牌并运行30秒,请不要将PF_WORKER_COUNT设置为大于2。这是一个粗略的估计。还请考虑协作(团队成员同时使用同一端点)以及部署的推理端点、playground和其他可能向您的LLM端点发送请求的情况中消耗的令牌。
PF_BATCH_METHOD
仅适用于批量运行。可选值:'spawn', 'fork'。
spawn
子进程不会继承父进程的资源,因此,每个进程需要重新初始化流程所需的资源,这可能会使用更多的系统内存。
启动一个进程是缓慢的,因为它需要一些时间来初始化必要的资源。
fork
使用写时复制机制,子进程将继承父进程的所有资源,从而使用更少的系统内存。
该过程启动更快,因为它不需要重新初始化资源。
注意:Windows 仅支持 spawn,Linux 和 macOS 同时支持 spawn 和 fork。
如何配置环境变量#
在
flow.dag.yaml中配置环境变量。示例:
inputs: []
outputs: []
nodes: []
environment_variables:
PF_WORKER_COUNT: 2
PF_BATCH_METHOD: "spawn"
MY_CUSTOM_SETTING: my_custom_value
在提交运行时指定环境变量。
使用此参数:--environment-variable 来指定环境变量。
示例:--environment-variable PF_WORKER_COUNT="2" PF_BATCH_METHOD="spawn"。
在创建运行时指定环境变量。示例:
pf = PFClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
flow = "web-classification"
data = "web-classification/data.jsonl"
environment_variables = {"PF_WORKER_COUNT": "2", "PF_BATCH_METHOD": "spawn"}
# create run
base_run = pf.run(
flow=flow,
data=data,
environment_variables=environment_variables,
)
VSCode 扩展支持仅在提交批量运行时指定环境变量。
在 batch_run_create.yaml 中指定环境变量。示例:
name: flow_name
display_name: display_name
flow: flow_folder
data: data_file
column_mapping:
customer_info: <Please select a data input>
history: <Please select a data input>
environment_variables:
PF_WORKER_COUNT: "2"
PF_BATCH_METHOD: "spawn"
优先级#
提交运行时指定的环境变量始终优先于flow.dag.yaml文件中的环境变量。