
使用Ignite进行集体通信
在本教程中,我们将了解如何使用高级分布式函数,如all_reduce()、all_gather()、broadcast()和barrier()。我们将讨论它们各自的独特用例,并以可视化的方式展示它们。
必需的依赖项
!pip install pytorch-ignite
导入
import torch
import ignite.distributed as idist
所有减少
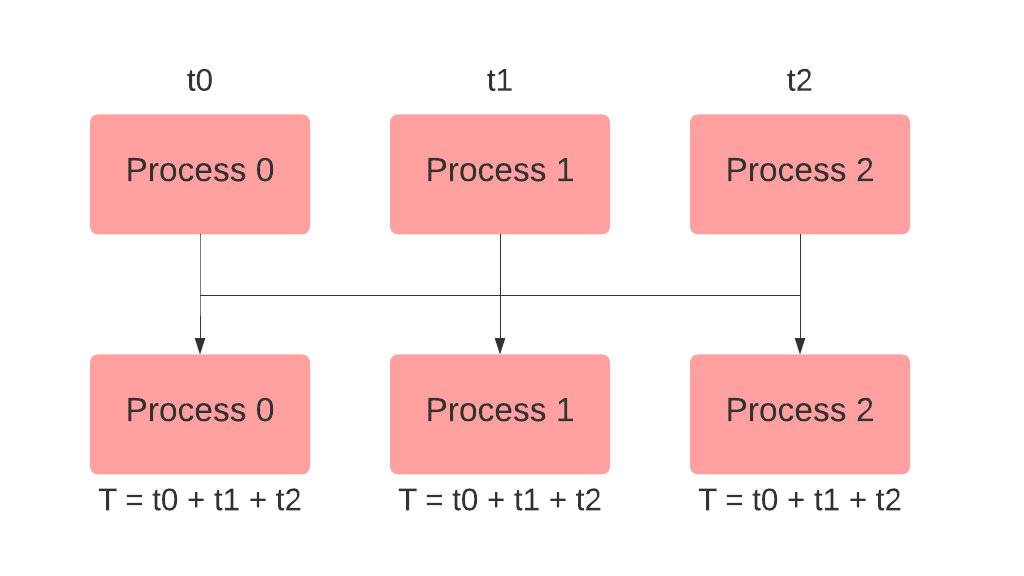
all_reduce() 方法用于从每个进程中收集指定的张量,并使它们在每个节点上可用,然后对它们执行指定的操作(求和、乘积、最小值、最大值等)。让我们生成3个进程,分别具有等级0、1和2,并在所有这些进程上定义一个tensor。如果我们对tensor执行all_reduce操作并使用SUM操作,那么所有等级上的tensor将被收集、相加并存储在tensor中,如下所示:
def all_reduce_example(local_rank):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * local_rank
print(f"Rank {local_rank}, Initial value: {tensor}")
idist.all_reduce(tensor, op="SUM")
print(f"Rank {local_rank}, After performing all_reduce: {tensor}")
我们可以使用
idist.spawn 来生成3个进程(nproc_per_node)并执行上述函数。
idist.spawn(backend="gloo", fn=all_reduce_example, args=(), nproc_per_node=3)
Rank 0, Initial value: tensor([1, 2])
Rank 2, Initial value: tensor([5, 6])
Rank 1, Initial value: tensor([3, 4])
Rank 0, After performing all_reduce: tensor([ 9, 12])
Rank 1, After performing all_reduce: tensor([ 9, 12])
Rank 2, After performing all_reduce: tensor([ 9, 12])
现在让我们假设一个更现实的场景 - 您需要找到不同进程中所有可用梯度的平均值。
首先,我们使用get_world_size方法获取可用的GPU数量。然后,对于每个模型参数,我们执行以下操作:
- 在每个进程上收集梯度
- 对梯度应用求和操作
- 除以世界大小以进行平均
最后,我们可以继续使用平均梯度来更新模型参数!
你可以使用另一个辅助方法idist.get_world_size()来获取可用的GPU数量(进程),然后使用all_reduce()来收集梯度并应用SUM操作。
def average_gradients(model):
num_processes = idist.get_world_size()
for param in model.parameters():
idist.all_reduce(param.grad.data, op="SUM")
param.grad.data = param.grad.data / num_processes
所有收集
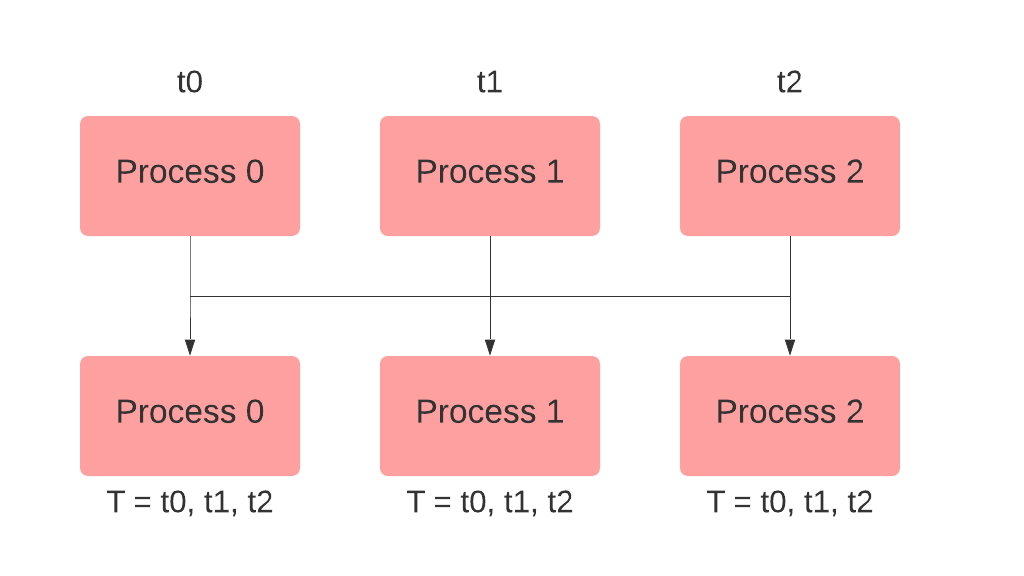
当您只想在所有参与的进程中收集一个张量、数字或字符串时,可以使用all_gather()方法。作为一个基本示例,假设您必须收集所有等级上存储在num中的不同值。您可以通过如下方式使用all_gather来实现这一点:
def all_gather_example(local_rank):
num = 2.0 * idist.get_rank()
print(f"Rank {local_rank}, Initial value: {num}")
all_nums = idist.all_gather(num)
print(f"Rank {local_rank}, After performing all_gather: {all_nums}")
idist.spawn(backend="gloo", fn=all_gather_example, args=(), nproc_per_node=3)
Rank 0, Initial value: 0.0
Rank 2, Initial value: 4.0
Rank 1, Initial value: 2.0
Rank 2, After performing all_gather: [0.0, 2.0, 4.0]
Rank 0, After performing all_gather: [0.0, 2.0, 4.0]
Rank 1, After performing all_gather: [0.0, 2.0, 4.0]
现在假设你需要收集分布在所有进程上的预测值到主进程上,以便你可以将它们存储到文件中。以下是你可以如何做到这一点:
def write_preds_to_file(predictions, filename):
prediction_tensor = torch.tensor(predictions)
prediction_tensor = idist.all_gather(prediction_tensor)
if idist.get_rank() == 0:
torch.save(prediction_tensor, filename)
注意: 在上面的例子中,只有主进程需要收集的值,而不是所有进程。这也可以通过gather()方法来完成。
广播
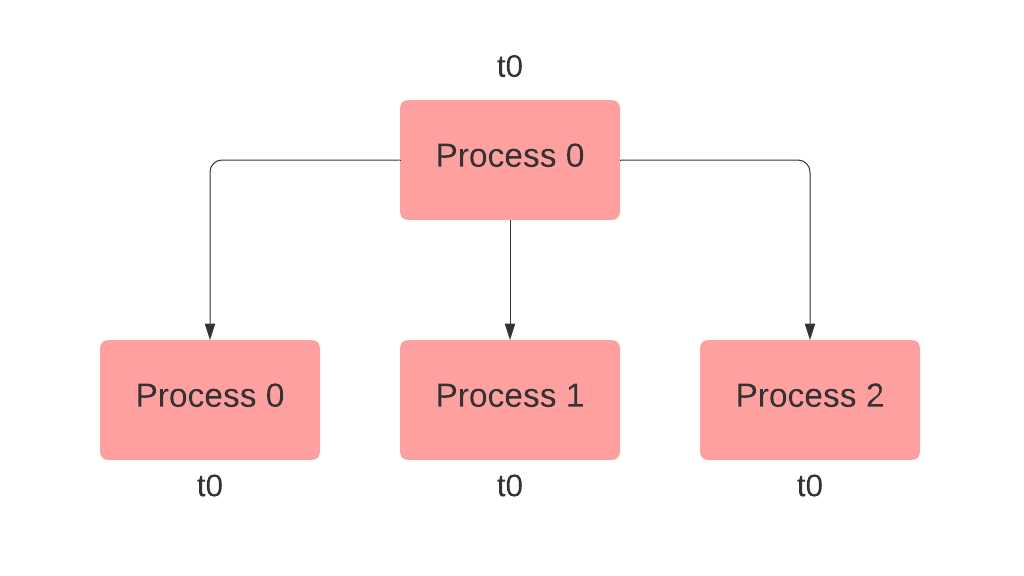
方法broadcast()将张量、浮点数或字符串从源进程复制到所有其他进程。例如,您需要从等级0发送消息到所有其他等级。您可以通过在等级0上创建实际消息并在所有其他等级上创建占位符,然后广播消息并指定源等级来实现这一点。如果占位符未在所有等级上定义,您还可以使用safe_mode=True。
def broadcast_example(local_rank):
message = f"hello from rank {idist.get_rank()}"
print(f"Rank {local_rank}, Initial value: {message}")
message = idist.broadcast(message, src=0)
print(f"Rank {local_rank}, After performing broadcast: {message}")
idist.spawn(backend="gloo", fn=broadcast_example, args=(), nproc_per_node=3)
Rank 1, Initial value: hello from rank 1
Rank 2, Initial value: hello from rank 2
Rank 0, Initial value: hello from rank 0
Rank 2, After performing broadcast: hello from rank 0
Rank 0, After performing broadcast: hello from rank 0
Rank 1, After performing broadcast: hello from rank 0
对于一个实际的使用案例,假设您需要从所有进程的排名0中收集预测值和实际值,以计算指标并避免内存错误。您可以通过首先使用all_gather(),然后计算指标,最后使用broadcast()与所有进程共享结果来实现这一点。src下面指的是源进程的排名。
def compute_metric(prediction_tensor, target_tensor):
prediction_tensor = idist.all_gather(prediction_tensor)
target_tensor = idist.all_gather(target_tensor)
result = 0.0
if idist.get_rank() == 0:
result = compute_fn(prediction_tensor, target_tensor)
result = idist.broadcast(result, src=0)
return result
屏障
barrier() 方法有助于同步所有进程。例如 - 在训练期间下载数据时,我们必须确保只有主进程(rank = 0)下载数据集,以防止子进程(rank > 0)同时将相同文件下载到相同路径。这样,所有子进程都会获得已下载数据集的副本。这时我们可以利用 barrier() 让子进程等待,直到主进程下载完数据集。完成后,所有子进程实例化数据集,而主进程等待。最后,所有进程同步完成。
def get_datasets(config):
if idist.get_local_rank() > 0:
idist.barrier()
train_dataset, test_dataset = get_train_test_datasets(config["data_path"])
if idist.get_local_rank() == 0:
idist.barrier()
return train_dataset, test_dataset