理解CUDA内存使用¶
为了调试CUDA内存使用情况,PyTorch提供了一种生成内存快照的方法,该快照记录了在任何时间点分配的CUDA内存状态,并可以选择记录导致该快照的分配事件的历史。
生成的快照可以拖放到托管在 pytorch.org/memory_viz 上的交互式查看器中,用于探索快照。
生成快照¶
记录快照的常见模式是启用内存历史记录,运行要观察的代码,然后保存一个包含序列化快照的文件:
# 启用内存历史记录,这将
# 将回溯和事件历史记录添加到快照中
torch.cuda.memory._record_memory_history()
run_your_code()
torch.cuda.memory._dump_snapshot("my_snapshot.pickle")
使用可视化工具¶
打开 pytorch.org/memory_viz 并将pickled快照文件拖放到可视化工具中。 该可视化工具是一个运行在您计算机本地的javascript应用程序。它不会上传任何快照数据。
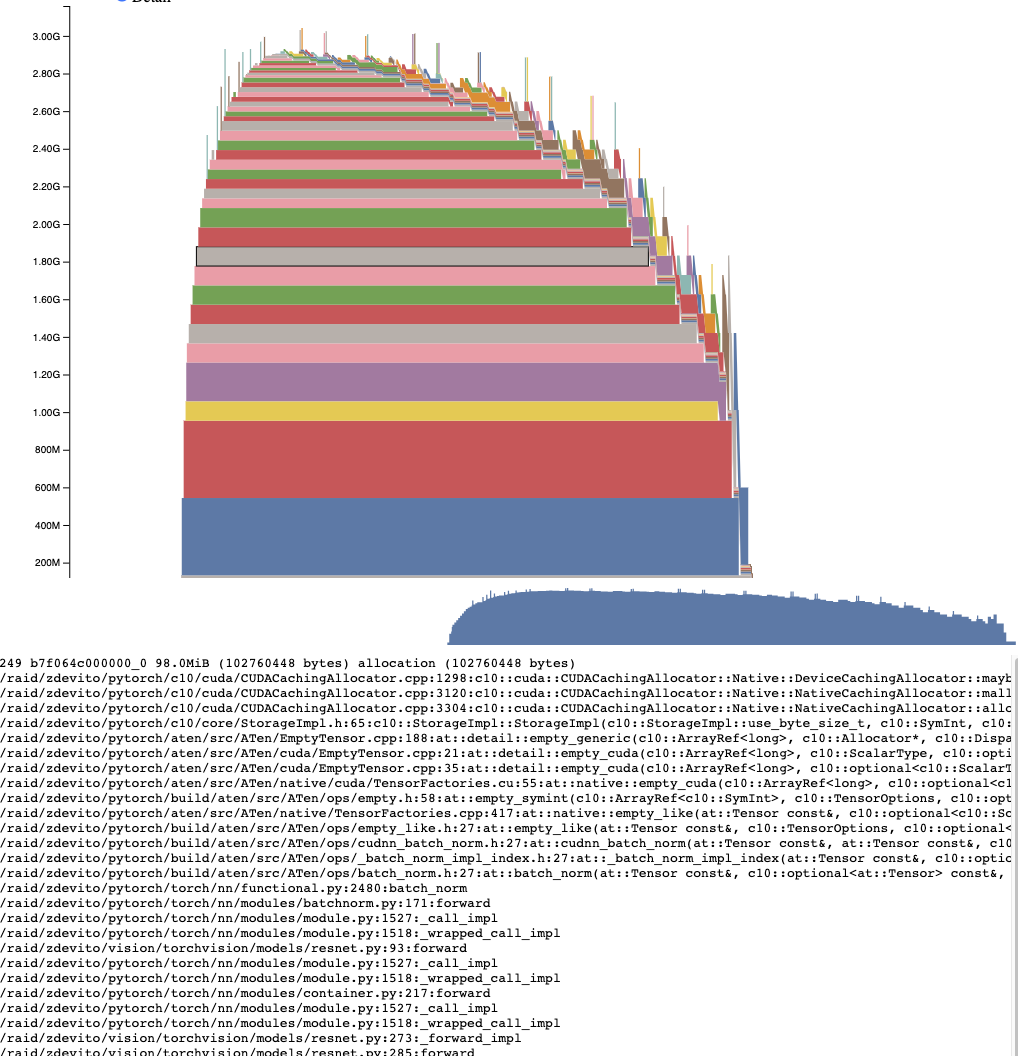
活动内存时间线¶
活动内存时间线显示了在特定GPU快照中随时间变化的所有活动张量。通过平移/缩放图表来查看较小的分配。 将鼠标悬停在分配的块上,可以查看该块分配时的堆栈跟踪及其地址等详细信息。可以通过调整详细信息滑块来减少渲染的分配数量,从而在数据量较大时提高性能。
分配器状态历史¶
分配器状态历史记录在左侧的时间轴上显示各个分配器事件。选择时间轴中的事件以查看该事件时分配器状态的可视化摘要。此摘要显示从cudaMalloc返回的每个单独段以及它如何被分割成单独分配或空闲空间的块。将鼠标悬停在段和块上以查看分配内存时的堆栈跟踪。将鼠标悬停在事件上以查看事件发生时的堆栈跟踪,例如当张量被释放时。内存不足错误报告为OOM事件。查看OOM期间的内存状态可能会提供有关为什么即使存在保留内存分配仍然失败的原因的见解。
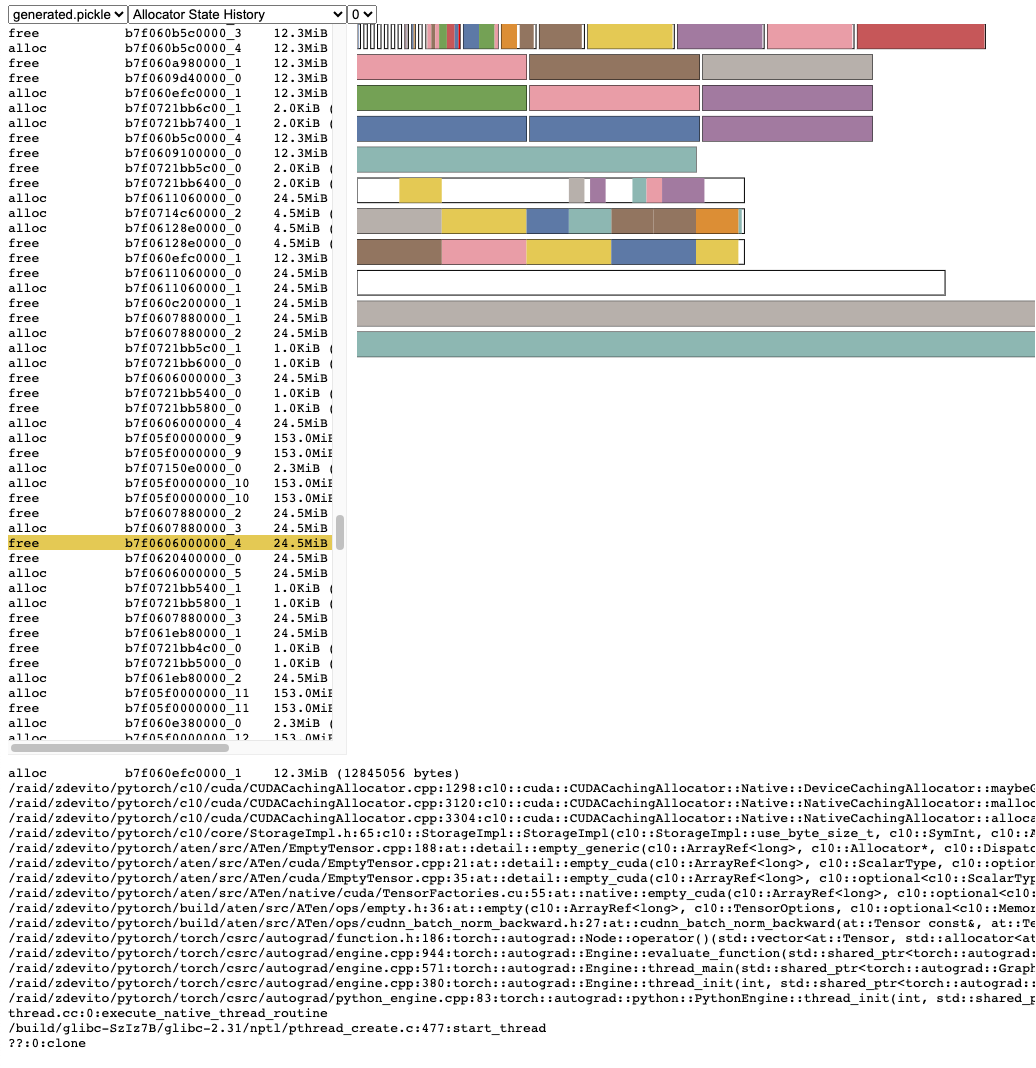
堆栈跟踪信息还会报告分配发生的地址。 地址 b7f064c000000_0 指的是地址 7f064c000000 处的 (b)lock,这是该地址第 “_0” 次分配。 这个唯一字符串可以在活动内存时间线中查找,并在活动状态历史中搜索,以检查张量分配或释放时的内存状态。
快照 API 参考¶
- torch.cuda.memory._record_memory_history(enabled='all', context='all', stacks='all', max_entries=9223372036854775807, device=None)[源代码]¶
启用与内存分配相关的堆栈跟踪记录,这样你就可以知道在
torch.cuda.memory._snapshot()中分配了任何一块内存的内容。除了在每次当前分配和释放时保留堆栈跟踪外,这还将启用记录所有分配/释放事件的历史。
使用
torch.cuda.memory._snapshot()来检索此信息, 并使用 _memory_viz.py 中的工具来可视化快照。Python 的跟踪收集速度很快(每条跟踪 2 微秒),因此如果你预计将来需要调试内存问题,可以考虑在生产作业中启用此功能。
C++ 跟踪收集也非常快(~50ns/帧),对于许多典型程序来说,每条跟踪大约需要 ~2us,但可能会根据堆栈深度而有所不同。
- Parameters
enabled (Literal[None, "state", "all"], optional) – None,禁用内存历史记录。 “state”,保留当前分配内存的信息。 “all”,额外保留所有分配/释放调用的历史记录。 默认为“all”。
context (Literal[None, "state", "alloc", "all"], optional) – None,不记录任何回溯。 “state”,记录当前分配内存的回溯。 “alloc”,另外保留分配调用的回溯。 “all”,另外保留释放调用的回溯。 默认为“all”。
堆栈(字面量["python", "all"], 可选) – “python”,包括 Python、TorchScript 和 inductor 帧在回溯中 “all”,另外包括 C++ 帧 默认为 “all”。
max_entries (int, 可选) – 在记录的历史记录中保留最多 max_entries 个分配/释放事件。
- torch.cuda.memory._snapshot(device=None)[源代码]¶
保存调用时CUDA内存状态的快照。
状态以字典的形式表示,具有以下结构。
class Snapshot(TypedDict): segments : List[Segment] device_traces: List[List[TraceEntry]] class Segment(TypedDict): # 段是从cudaMalloc调用返回的内存。 # 保留内存的大小是所有段的总和。 # 段被缓存并在未来的分配中重用。 # 如果重用小于段,则段 # 被分割成多个块。 # empty_cache()释放完全不活动的段。 address: int total_size: int # cudaMalloc分配的段大小 stream: int segment_type: Literal['small', 'large'] # 'large' (>1MB) allocated_size: int # 正在使用的内存大小 active_size: int # 正在使用或处于active_awaiting_free状态的内存大小 blocks : List[Block] class Block(TypedDict): # 从分配器返回的内存块,或 # 当前缓存但处于非活动状态。 size: int requested_size: int # 在malloc期间请求的大小,可能由于舍入而小于 # 实际大小 address: int state: Literal['active_allocated', # 由张量使用 'active_awaiting_free', # 等待另一个流完成使用 # 这个块,然后它将变为空闲 'inactive',] # 可重用 frames: List[Frame] # 分配发生时的堆栈跟踪 class Frame(TypedDict): filename: str line: int name: str class TraceEntry(TypedDict): # 当`torch.cuda.memory._record_memory_history()`启用时, # 快照将包含记录分配器每次操作的TraceEntry对象。 action: Literal[ 'alloc' # 分配的内存 'free_requested', # 分配的内存接收到释放内存的调用 'free_completed', # 请求释放的内存现在 # 可以用于未来的分配调用 'segment_alloc', # 缓存分配器请求cudaMalloc获取更多内存 # 并将其添加到其缓存中作为一个段 'segment_free', # 缓存分配器调用cudaFree以返回内存 # 给cuda,可能是为了尝试释放内存以 # 分配更多的段或因为调用了empty_caches 'oom', # 分配器抛出了OOM异常。'size'是 # 未成功请求的字节数 'snapshot' # 分配器生成了一个内存快照 # 有助于将之前拍摄的快照与 # 此跟踪相关联 ] addr: int # 对于OOM不存在 frames: List[Frame] size: int stream: int device_free: int # 仅对于OOM存在,cuda仍报告为空闲的 # 内存量
- Returns
快照字典对象