pyts.preprocessing.QuantileTransformer¶
-
class
pyts.preprocessing.QuantileTransformer(n_quantiles=1000, output_distribution='uniform', subsample=100000, random_state=None)[来源]¶ 使用分位数信息转换样本。
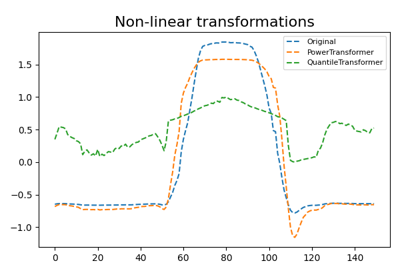
该方法将样本转换为服从均匀或正态分布。因此,对于给定样本,这种转换倾向于分散最频繁出现的数值。它还能减少(边缘)异常值的影响:因此这是一种鲁棒的预处理方案。该转换会独立应用于每个样本。
特征的累积分布函数用于映射原始值。请注意,这个转换是非线性的。
参数: - n_quantiles : int, optional (default = 1000)
要计算的分位数数量。它对应于用于离散化累积分布函数的标志点数量。
- output_distribution : ‘uniform’ or ‘normal’ (default = ‘uniform’)
转换后数据的边缘分布。可选值为'均匀分布'(默认)或'正态分布'。
- subsample : int, optional (default = 1e5)
用于估计分位数的最大时间戳数量,以提高计算效率。
- random_state : int, RandomState instance or None, optional (default=None)
如果是整数,random_state将作为随机数生成器的种子; 如果是RandomState实例,random_state将作为随机数生成器; 如果是None,则使用np.random中的RandomState实例作为随机数生成器。 注意:该参数用于子采样和平滑噪声处理。
示例
>>> from pyts.datasets import load_gunpoint >>> from pyts.preprocessing import QuantileTransformer >>> X, _, _, _ = load_gunpoint(return_X_y=True) >>> qt = QuantileTransformer(n_quantiles=10) >>> qt.transform(X) array([...])
方法
__init__([n_quantiles, output_distribution, …])Initialize self. fit([X, y])Pass. fit_transform(X[, y])Fit to data, then transform it. get_params([deep])Get parameters for this estimator. set_params(**params)Set the parameters of this estimator. transform(X)Transform the data. -
__init__(n_quantiles=1000, output_distribution='uniform', subsample=100000, random_state=None)[来源]¶ 初始化自身。查看 help(type(self)) 获取准确的签名信息。
-
fit_transform(X, y=None, **fit_params)¶ 拟合数据,然后进行转换。
使用可选参数fit_params将转换器适配到X和y,并返回转换后的X版本。
参数: - X : array-like, shape = (n_samples, n_timestamps)
单变量时间序列。
- y : None or array-like, shape = (n_samples,) (default = None)
目标值(无监督转换时为None)。
- **fit_params : dict
额外的拟合参数。
返回值: - X_new : array
转换后的数组。
-
get_params(deep=True)¶ 获取此估计器的参数。
参数: - deep : bool, default=True
如果为True,将返回此估计器及其包含的子估计器的参数。
返回值: - params : dict
参数名称映射到对应的值。