
您想在您的网站或在线应用中插入一个语义搜索功能吗?现在您可以做到这一点 - 不需要花费任何钱!在这个例子中,您将学习如何为自己的非商业目的创建一个免费的原型搜索引擎。
您可以在GitHub上找到本教程的所有资源。
成分
- A Rust 工具链
- 货物 λ(通过包管理器安装,下载二进制文件或
cargo install cargo-lambda) - 该AWS CLI
- Qdrant 实例 (免费套餐 可用)
- 您选择的嵌入提供者服务(请参见我们的 嵌入文档。您可能能够从 AI Grant 获得学分,同时 Cohere 还提供 限制速率的非商业免费层)
- AWS Lambda账户(12个月免费套餐可用)
你将要构建的内容
您将结合嵌入提供者和Qdrant实例进行简洁的语义搜索,通过一个小的Lambda函数调用这两个服务。
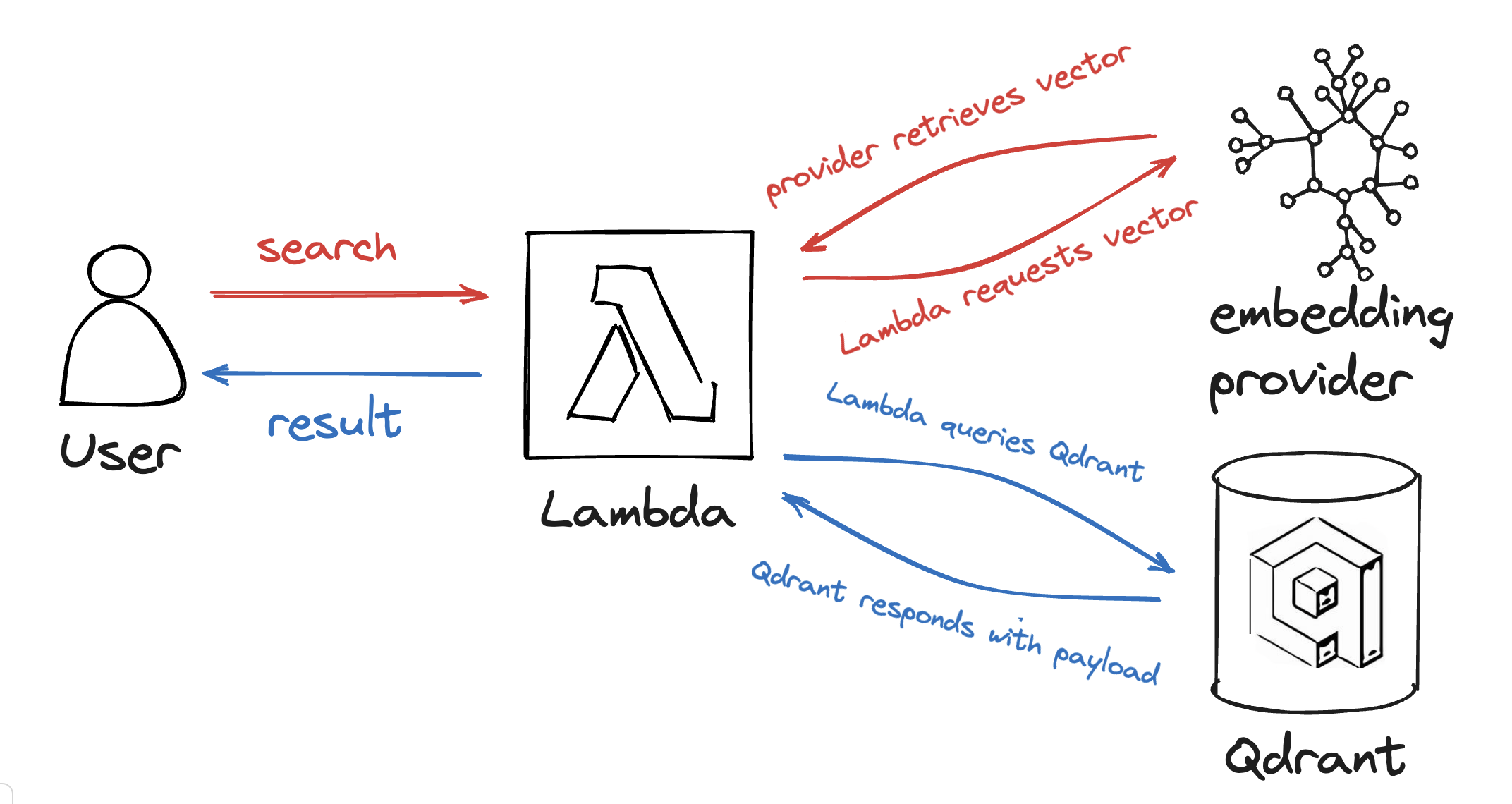
现在让我们看看如何处理每个成分,然后再将它们连接起来。
Rust 和 cargo-lambda
您希望您的函数快速、简洁且安全,因此使用Rust是明智之举。为了在Lambda函数中使用Rust代码,已构建了cargo-lambda子命令。cargo-lambda可以将您的Rust代码放入AWS Lambda可以在简单的provided.al2运行时上部署的zip文件中。
要与 AWS Lambda 进行交互,您需要一个 Rust 项目,并在您的 Cargo.toml 中包含以下依赖项:
[dependencies]
tokio = { version = "1", features = ["macros"] }
lambda_http = { version = "0.8", default-features = false, features = ["apigw_http"] }
lambda_runtime = "0.8"
这为您提供了一个接口,包括启动Lambda运行时的入口点以及注册您的处理程序以进行HTTP调用的方式。将以下代码片段放入 src/helloworld.rs:
use lambda_http::{run, service_fn, Body, Error, Request, RequestExt, Response};
/// This is your callback function for responding to requests at your URL
async fn function_handler(_req: Request) -> Result<Response<Body>, Error> {
Response::from_text("Hello, Lambda!")
}
#[tokio::main]
async fn main() {
run(service_fn(function_handler)).await
}
您还可以使用闭包将其他参数绑定到您的函数处理程序(service_fn 调用随后变为 service_fn(|req| function_handler(req, ...)))。如果您想从请求中提取参数,可以使用 请求 方法(例如 query_string_parameters 或 query_string_parameters_ref)。
将以下内容添加到您的 Cargo.toml 以定义二进制文件:
[[bin]]
name = "helloworld"
path = "src/helloworld.rs"
在AWS方面,您需要设置一个Lambda和IAM角色以供您的函数使用。
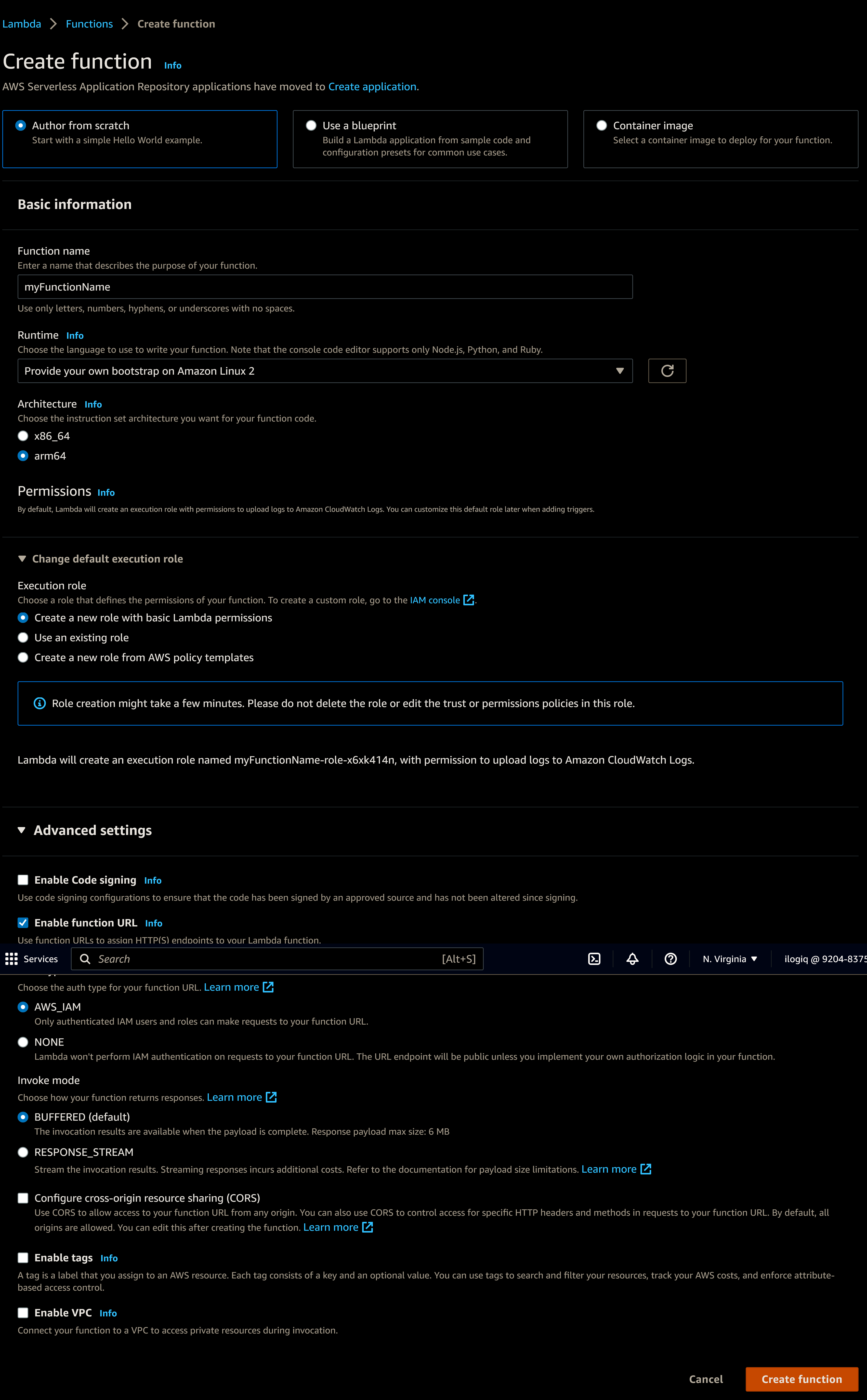
选择你的函数名称,选择“在 Amazon Linux 2 上提供自己的引导”。作为架构,使用 arm64。你还将激活一个函数 URL。这里由你决定是否通过 IAM 进行保护,或者将其开放,但要意识到开放的端点可以被任何人访问,如果流量过大,可能会产生费用。
默认情况下,这也将创建一个基本角色。要查看该角色,您可以进入函数概览:
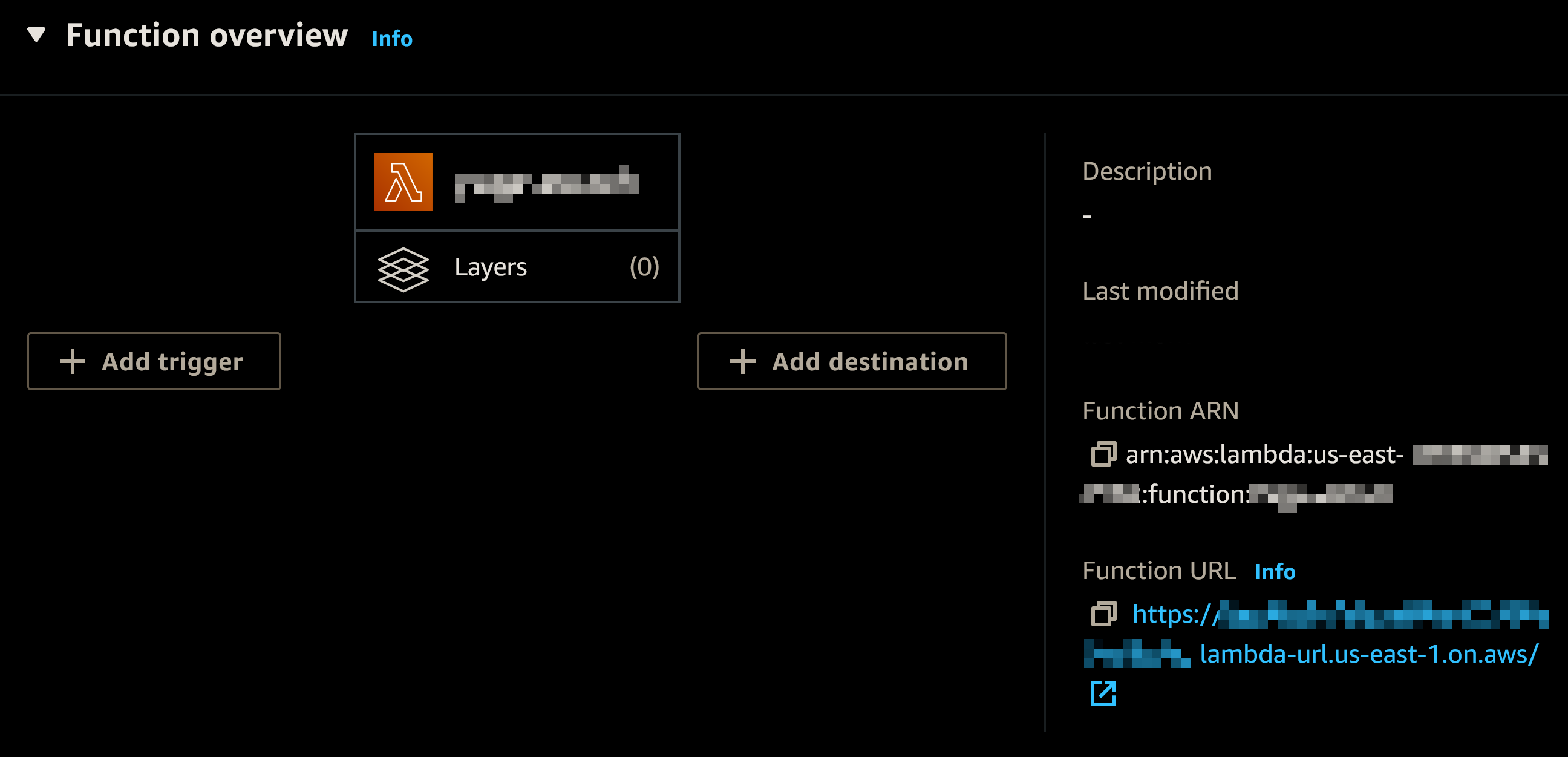
点击“信息”链接,位于“▸ 函数概述”标题附近,然后选择左侧的“权限”选项卡。
您会在执行角色下找到“角色名称”。请记下以备后用。
要测试你的“Hello, Lambda”服务是否正常工作,你可以编译并上传该函数:
$ export LAMBDA_FUNCTION_NAME=hello
$ export LAMBDA_ROLE=<role name from lambda web ui>
$ export LAMBDA_REGION=us-east-1
$ cargo lambda build --release --arm --bin helloworld --output-format zip
Downloaded libc v0.2.137
# [..] output omitted for brevity
Finished release [optimized] target(s) in 1m 27s
$ # Delete the old empty definition
$ aws lambda delete-function-url-config --region $LAMBDA_REGION --function-name $LAMBDA_FUNCTION_NAME
$ aws lambda delete-function --region $LAMBDA_REGION --function-name $LAMBDA_FUNCTION_NAME
$ # Upload the function
$ aws lambda create-function --function-name $LAMBDA_FUNCTION_NAME \
--handler bootstrap \
--architectures arm64 \
--zip-file fileb://./target/lambda/helloworld/bootstrap.zip \
--runtime provided.al2 \
--region $LAMBDA_REGION \
--role $LAMBDA_ROLE \
--tracing-config Mode=Active
$ # Add the function URL
$ aws lambda add-permission \
--function-name $LAMBDA_FUNCTION_NAME \
--action lambda:InvokeFunctionUrl \
--principal "*" \
--function-url-auth-type "NONE" \
--region $LAMBDA_REGION \
--statement-id url
$ # Here for simplicity unauthenticated URL access. Beware!
$ aws lambda create-function-url-config \
--function-name $LAMBDA_FUNCTION_NAME \
--region $LAMBDA_REGION \
--cors "AllowOrigins=*,AllowMethods=*,AllowHeaders=*" \
--auth-type NONE
现在您可以进入您的 函数概览 并点击函数 URL。您应该会看到类似这样的内容:
Hello, Lambda!
持有者!您已经在Rust中设置了一个Lambda函数。接下来是下一个组成部分:
嵌入
大多数提供者提供一个简单的 https GET 或 POST 接口,您可以使用 API 密钥,须在身份验证头中提供。如果您将其用于非商业目的,Cohere 的限量试用密钥只需几个点击即可获得。请访问 他们的欢迎页面,注册后您将能够进入仪表板,其中有一个“API 密钥”菜单项,将把您带到以下页面:共同体仪表板
{kind=link}
从那里你可以点击API密钥旁边的 ⎘ 符号将其复制到剪贴板。不要把你的API密钥放在代码里! 相反,应该从你可以在lambda环境中设置的环境变量中读取它。这避免了不小心将你的密钥放入公共仓库。现在你需要的只是一些代码来获取嵌入。首先,你需要用 reqwest 扩展你的依赖,并且还添加 anyhow 以便于错误处理:
anyhow = "1.0"
reqwest = { version = "0.11.18", default-features = false, features = ["json", "rustls-tls"] }
serde = "1.0"
现在,给定上述的API密钥,您可以进行调用以获取嵌入向量:
use anyhow::Result;
use serde::Deserialize;
use reqwest::Client;
#[derive(Deserialize)]
struct CohereResponse { outputs: Vec<Vec<f32>> }
pub async fn embed(client: &Client, text: &str, api_key: &str) -> Result<Vec<Vec<f32>>> {
let CohereResponse { outputs } = client
.post("https://api.cohere.ai/embed")
.header("Authorization", &format!("Bearer {api_key}"))
.header("Content-Type", "application/json")
.header("Cohere-Version", "2021-11-08")
.body(format!("{{\"text\":[\"{text}\"],\"model\":\"small\"}}"))
.send()
.await?
.json()
.await?;
Ok(outputs)
}
请注意,如果文本超出输入维度,这可能会返回多个向量。 Cohere的 small 模型有1024个输出维度。
其他提供商有类似的接口。有关更多信息,请参阅我们的 嵌入文档。看看获取嵌入所需的代码有多少?
同时,写一个小测试来检查嵌入是否有效,以及向量是否为预期大小,是个好主意:
#[tokio::test]
async fn check_embedding() {
// ignore this test if API_KEY isn't set
let Ok(api_key) = &std::env::var("API_KEY") else { return; }
let embedding = crate::embed("What is semantic search?", api_key).unwrap()[0];
// Cohere's `small` model has 1024 output dimensions.
assert_eq!(1024, embedding.len());
}
在将 API_KEY 环境变量设置好后运行此命令以检查嵌入是否正常工作。
Qdrant 搜索
现在你有了嵌入,接下来是将它们放入你的Qdrant。你当然可以使用 curl 或 python 来设置你的集合并上传数据点,但由于你已经有Rust,包括一些获取嵌入的代码,你可以继续使用Rust,将 qdrant-client 添加到其中。
use anyhow::Result;
use qdrant_client::prelude::*;
use qdrant_client::qdrant::{VectorsConfig, VectorParams};
use qdrant_client::qdrant::vectors_config::Config;
use std::collections::HashMap;
fn setup<'i>(
embed_client: &reqwest::Client,
embed_api_key: &str,
qdrant_url: &str,
api_key: Option<&str>,
collection_name: &str,
data: impl Iterator<Item = (&'i str, HashMap<String, Value>)>,
) -> Result<()> {
let mut config = QdrantClientConfig::from_url(qdrant_url);
config.api_key = api_key;
let client = QdrantClient::new(Some(config))?;
// create the collections
if !client.has_collection(collection_name).await? {
client
.create_collection(&CreateCollection {
collection_name: collection_name.into(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 1024, // output dimensions from above
distance: Distance::Cosine as i32,
..Default::default()
})),
}),
..Default::default()
})
.await?;
}
let mut id_counter = 0_u64;
let points = data.map(|(text, payload)| {
let id = std::mem::replace(&mut id_counter, *id_counter + 1);
let vectors = Some(embed(embed_client, text, embed_api_key).unwrap());
PointStruct { id, vectors, payload }
}).collect();
client.upsert_points(collection_name, points, None).await?;
Ok(())
}
根据您是否希望高效筛选数据,您还可以添加一些索引。我为了简洁起见没有提及这一点,但您可以查看包含此操作的示例代码。此外,这也没有实现分块处理(将数据分割为多个请求进行更新插入,以避免超时错误)。
添加一个合适的 main 方法,你可以运行这段代码来插入点(或者直接使用示例中的二进制)。确保在 qdrant_url 中包括端口。
现在您已经插入了点,您可以通过嵌入进行搜索:
use anyhow::Result;
use qdrant_client::prelude::*;
pub async fn search(
text: &str,
collection_name: String,
client: &Client,
api_key: &str,
qdrant: &QdrantClient,
) -> Result<Vec<ScoredPoint>> {
Ok(qdrant.search_points(&SearchPoints {
collection_name,
limit: 5, // use what fits your use case here
with_payload: Some(true.into()),
vector: embed(client, text, api_key)?,
..Default::default()
}).await?.result)
}
您还可以通过向 SearchPoints 添加 filter: ... 字段来进行过滤,您可能还想进一步处理结果,但示例代码已经做了这些,因此如果您需要这个功能,可以直接从那里开始。
将所有内容结合在一起
现在你拥有了所有的部分,是时候将它们连接起来了。现在复制和连接上面的代码片段留给读者作为练习。急躁的头脑可以查看示例仓库。
您需要稍微扩展一下 main 方法,以便在开始时与客户端连接,并从环境中获取 API 密钥,这样您就不需要将它们编译到代码中。为此,您可以通过 std::env::var(_) 从 Rust 代码中获取它们,并从 AWS 控制台设置环境。
$ export QDRANT_URI=<qour Qdrant instance URI including port>
$ export QDRANT_API_KEY=<your Qdrant API key>
$ export COHERE_API_KEY=<your Cohere API key>
$ export COLLECTION_NAME=site-cohere
$ aws lambda update-function-configuration \
--function-name $LAMBDA_FUNCTION_NAME \
--environment "Variables={QDRANT_URI=$QDRANT_URI,\
QDRANT_API_KEY=$QDRANT_API_KEY,COHERE_API_KEY=${COHERE_API_KEY},\
COLLECTION_NAME=${COLLECTION_NAME}"`
无论如何,您将到达一个命令行程序来插入您的数据和一个Lambda函数。前者可以直接使用 cargo run 来设置收集。对于后者,您可以再次调用 cargo lambda 和AWS控制台:
$ export LAMBDA_FUNCTION_NAME=search
$ export LAMBDA_REGION=us-east-1
$ cargo lambda build --release --arm --output-format zip
Downloaded libc v0.2.137
# [..] output omitted for brevity
Finished release [optimized] target(s) in 1m 27s
$ # Update the function
$ aws lambda update-function-code --function-name $LAMBDA_FUNCTION_NAME \
--zip-file fileb://./target/lambda/page-search/bootstrap.zip \
--region $LAMBDA_REGION
讨论
Lambda 通过在调用 URL 时启动您的函数来工作,因此它们不需要保持计算能力,除非实际使用。这意味着第一次调用会因加载函数而受到大约 1-2 秒的延迟,后续调用将更快解决。 当然,调用嵌入提供者和 Qdrant 也会有延迟。另一方面,免费套餐是免费的,因此您肯定会得到您所支付的。对于许多用例来说,一两秒内的结果是可以接受的。
Rust 最小化了函数的开销,无论是文件大小还是运行时。使用嵌入服务意味着您不需要关心细节。知道 URL、API 密钥和嵌入大小就足够了。最后,由于 Lambda 和 Qdrant 都提供免费额度,以及嵌入提供者的免费积分,唯一的成本是您设置一切的时间。谁会反对免费的呢?